
Meta 公司發布了一個新的開源人工智慧模型 ImageBind,該模型能夠將多種資料流,包括文字、音訊、視覺資料、溫度和運動讀數等整合在一起。該模型目前只是一個研究項目,還沒有直接的消費者或實際應用,但它展示了未來生成式人工智慧系統的可能性,這些系統能夠創造出沉浸式、多感官的體驗。同時,該模型也顯示了 Meta 公司在人工智慧研究領域的開放態度,而其競爭對手如 OpenAI 和Google則變得越來越封閉。
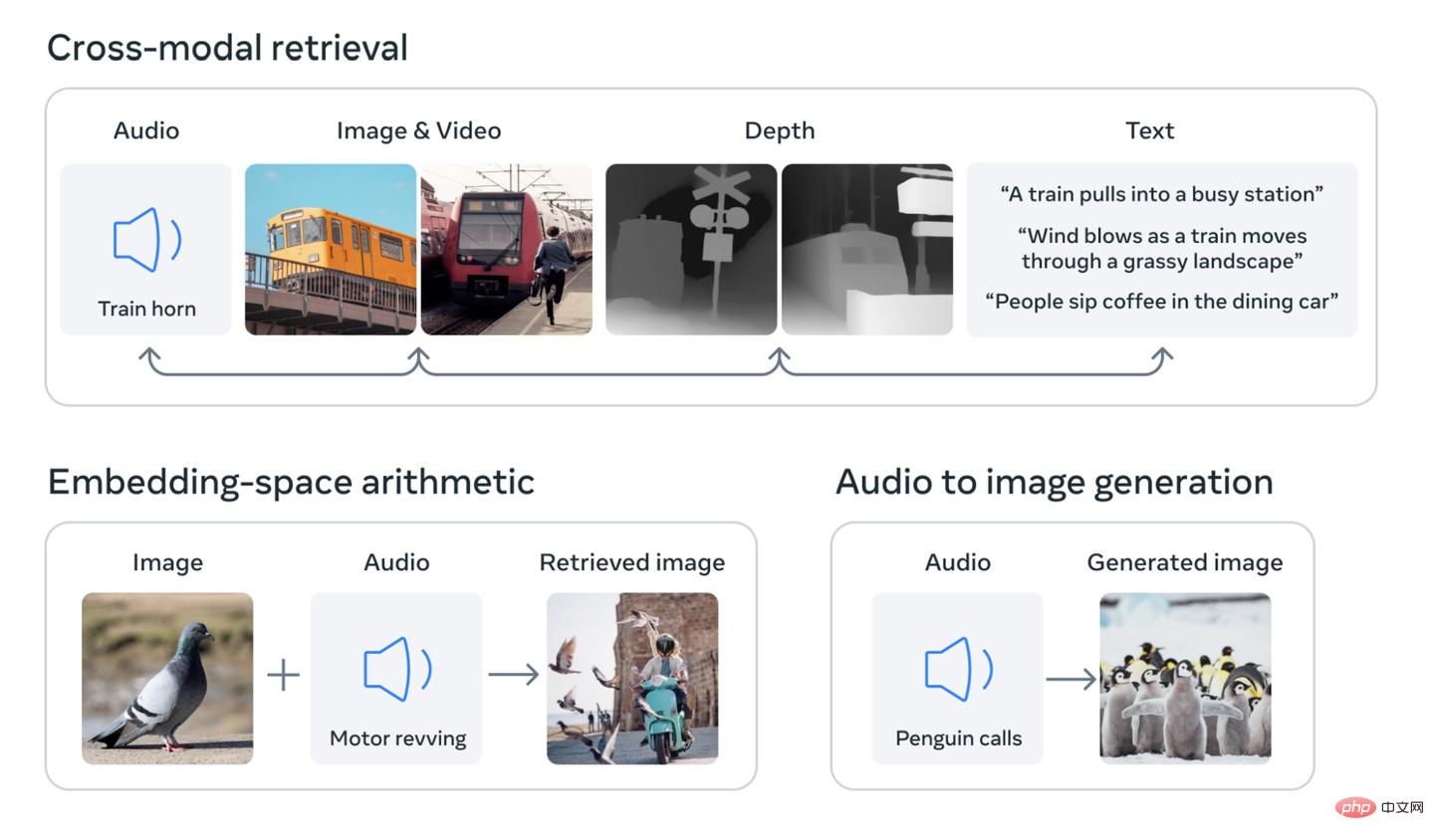
該研究的核心概念是將多種類型的資料整合到多維索引(或用人工智慧術語來說,「嵌入空間」)。這個概念可能有些抽象,但它正是近期生成式人工智慧熱潮的基礎。例如,人工智慧圖像產生器,如 DALL-E、Stable Diffusion 和 Midjourney 等,都依賴在訓練階段將文字和圖像連結在一起的系統。它們在尋找視覺數據中的模式的同時,將這些資訊與圖像的描述連結起來。這就是為什麼這些系統能夠根據使用者的文字輸入來產生圖片。同樣的道理也適用於許多能夠以同樣方式產生視訊或音訊的人工智慧工具。
Meta 公司稱,其模型 ImageBind 是第一個將六種類型的資料整合到一個嵌入空間中的模型。這六種類型的數據包括:視覺(包括圖像和視訊);熱力(紅外線圖像);文字;音訊;深度資訊;以及最有趣的一種 —— 由慣性測量單元(IMU)產生的運動讀數。 (IMU 存在於手機和智慧手錶中,用於執行各種任務,從手機從橫屏切換到豎屏,到區分不同類型的運動。)
未來的人工智慧系統將能夠像當前針對文字輸入的系統一樣,交叉引用這些資料。例如,想像一下未來的虛擬實境設備,它不僅能夠產生音訊和視覺輸入,還能夠產生你所處的環境和實體月台的運動。你可以要求它模擬一次漫長的海上旅行,它不僅會讓你置身於一艘船上,並且有海浪的聲音作為背景,還會讓你感受到甲板在腳下搖晃和海風吹拂。
Meta 公司在部落格文章中指出,未來的模型還可以添加其他感官輸入流,包括「觸覺、語音、氣味和大腦功能磁振造影訊號」。該公司還聲稱,這項研究「讓機器更接近人類同時、全面、直接地從多種不同的資訊形式中學習的能力。」
當然,這很多都是基於預測的,而且很可能這項研究的直接應用會非常有限。例如,去年,Meta 公司展示了一個人工智慧模型,能夠根據文字描述產生短而模糊的影片。像 ImageBind 這樣的研究顯示了未來版本的系統如何整合其他資料流,例如產生與視訊輸出相符的音訊。
對於產業觀察者來說,這項研究也很有趣,因為IT之家注意到 Meta 公司是開源了底層模型的,這在人工智慧領域是一個越來越受到關注的做法。
以上是Meta 開源多感官人工智慧模型,整合文字、音訊、視覺等六類數據的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















