

上科大等發表DreamFace:只需文字即可產生「超寫實3D數位人」

隨著大型語言模型(LLM)、擴散(Diffusion)等技術的發展,ChatGPT、Midjourney等產品的誕生掀起了新一波的AI熱潮,生成式AI也成為備受關注的話題。
與文字和圖像不同,3D生成仍處於技術探索階段。
2022年底,Google、NVIDIA和微軟相繼推出了自己的3D生成工作,但大多基於先進的神經輻射場(NeRF)隱式表達,與工業界3D軟體如Unity、Unreal Engine和Maya等的渲染管線不相容。
即使透過傳統方案將其轉換為Mesh表達的幾何和色彩貼圖,也會造成精確度不足和視覺品質下降,不能直接應用於影視製作和遊戲生產。

計畫網站:https://sites.google.com/view/dreamface
#論文網址:https://arxiv.org/abs/2304.03117
Web Demo:https ://hyperhuman.top
HuggingFace Space:https://huggingface.co/spaces/DEEMOSTECH/ChatAvatar
#為了解決這些問題,來自影眼科技與上海科技大學的研發團隊提出了一種文本指導的漸進式3D生成框架。
此框架引入符合CG製作標準的外部資料集(包含幾何和PBR材質),可根據文字直接產生符合該標準的3D資產,是首個支援Production-Ready 3D資產生成的框架。
為了實現文字產生可驅動的3D超寫實數位人,該團隊將這個框架與產品級3D數位人資料集結合。這項工作已經被電腦圖形領域國際頂尖期刊Transactions on Graphics接收,並將在國際電腦圖形頂級會議SIGGRAPH 2023上展示。
DreamFace主要包括三個模組,幾何體生成,基於物理的材質擴散和動畫能力生成。
比起先前的3D生成工作,這項工作的主要貢獻包括:
· 提出了DreamFace這個新穎的生成方案,將最近的視覺-語言模型與可動畫和物理材質的臉部資產結合,透過漸進式學習來分離幾何、外觀和動畫能力。
· 引入了雙通道外觀生成的設計,將一種新穎的材質擴散模型與預訓練模型相結合,同時在潛在空間和圖像空間進行兩階段優化。
· 使用BlendShapes或產生的Personalized BlendShapes的臉部資產具備動畫能力,並進一步展示了DreamFace在自然人物設計方面的應用。
幾何產生
幾何體產生模組可以根據文字提示產生與之一致的幾何模型。然而,在人臉生成方面,這可能難以監督和收斂。
因此,DreamFace提出了一個基於CLIP(Contrastive Language-Image Pre-Training)的選擇框架,首先從對人臉幾何參數空間內隨機採樣的候選項中選擇最佳的粗略幾何模型,然後雕刻幾何細節,使頭部模型更符合文字提示。
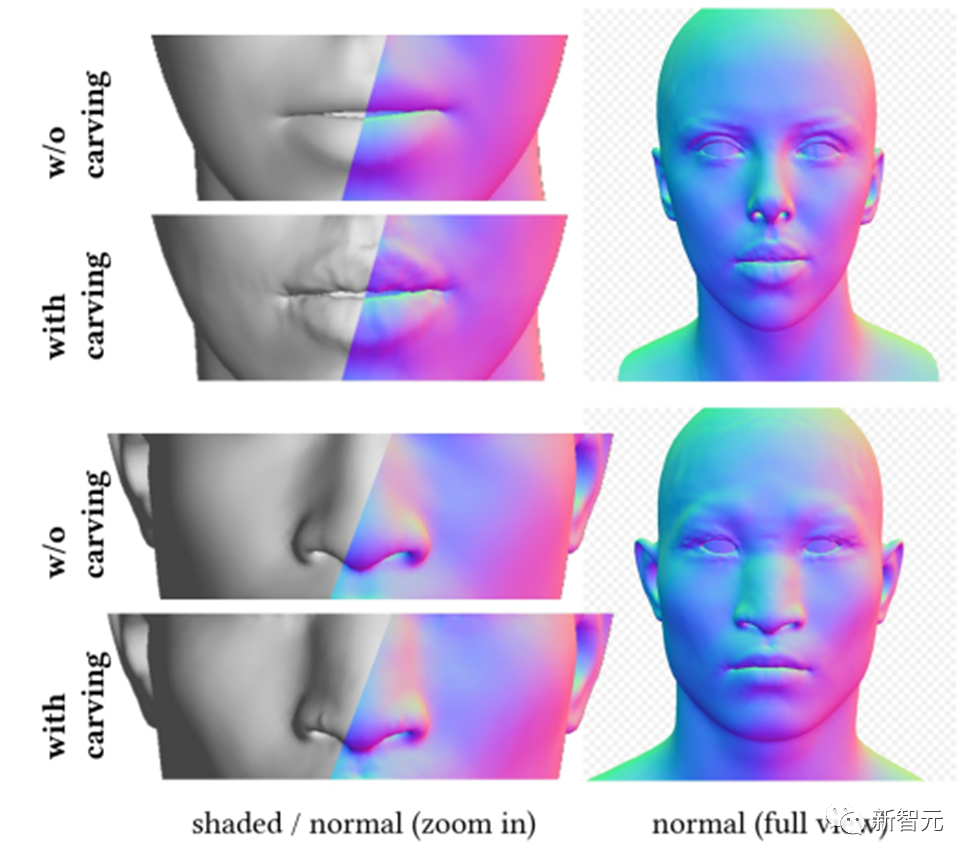
根據輸入提示,DreamFace利用CLIP模型選擇符合得分最高的粗略幾何候選項。接下來,DreamFace使用隱式擴散模型(LDM)在隨機視角和光照條件下對渲染影像進行得分蒸餾採樣(SDS)處理。
這使得DreamFace可以透過頂點位移和詳細的法線貼圖向粗略幾何模型添加臉部細節,從而得到高度精細的幾何體。
與頭部模型類似,DreamFace也基於該框架進行髮型和顏色的選擇。
基於物理的材質擴散產生
基於物理的材質擴散模組旨在預測與預測幾何體和文字提示一致的臉部紋理。
首先,DreamFace將預先訓練的LDM在收集的大規模UV材質資料集上微調,得到兩個LDM擴散模型。

DreamFace採用了一個聯合訓練方案,協調兩個擴散過程,一個用於直接去噪UV紋理貼圖,另一個用於監督渲染圖像,以確保臉部UV貼圖和渲染圖像的正確形成與文字提示一致。
為了減少生成時間,DreamFace採用了一個粗糙紋理潛在擴散階段,為細節紋理生成提供先驗潛在。
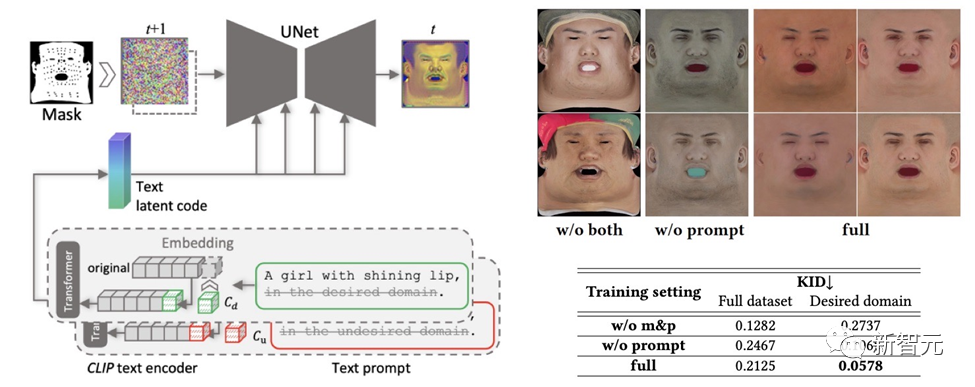
為了確保所創建的紋理地圖不含有不良特徵或照明情況,同時仍保持多樣性,設計了一種提示學習策略。
團隊利用兩種方法產生高品質的漫反射貼圖:
#(1)Prompt Tuning。與手工製作的特定領域文本提示不同,DreamFace將兩個特定領域的連續文本提示Cd 和Cu 與相應的文本提示結合起來,這將在U-Net去噪器訓練期間進行優化,以避免不穩定和耗時的手作提示。
(2)非臉部區域遮罩。 LDM去噪過程將額外受到非臉部區域遮罩的限制,以確保產生的漫反射貼圖不含有任何不必要的元素。
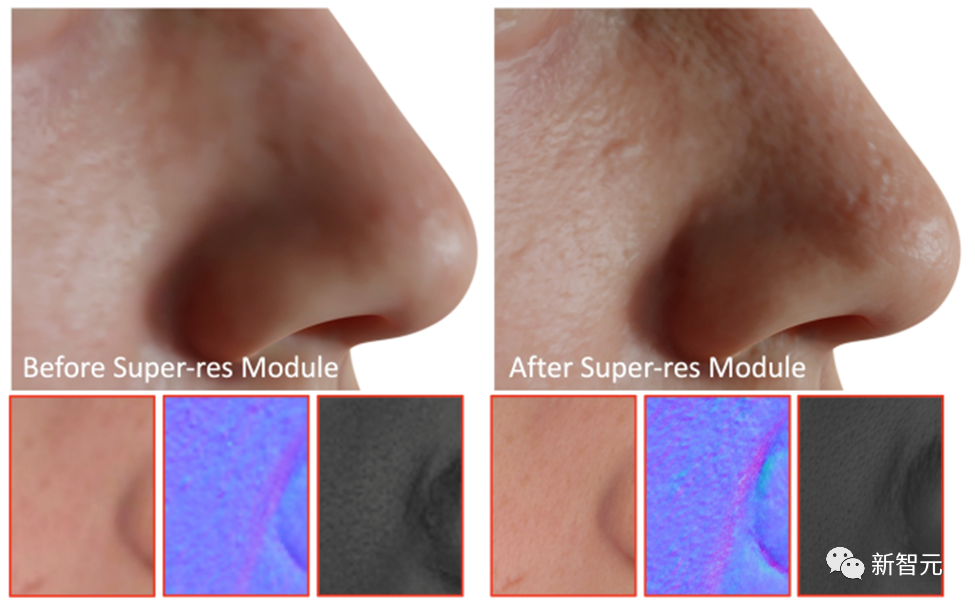
作為最後一步,DreamFace應用超解析度模組產生4K基於物理的紋理,以進行高品質渲染。

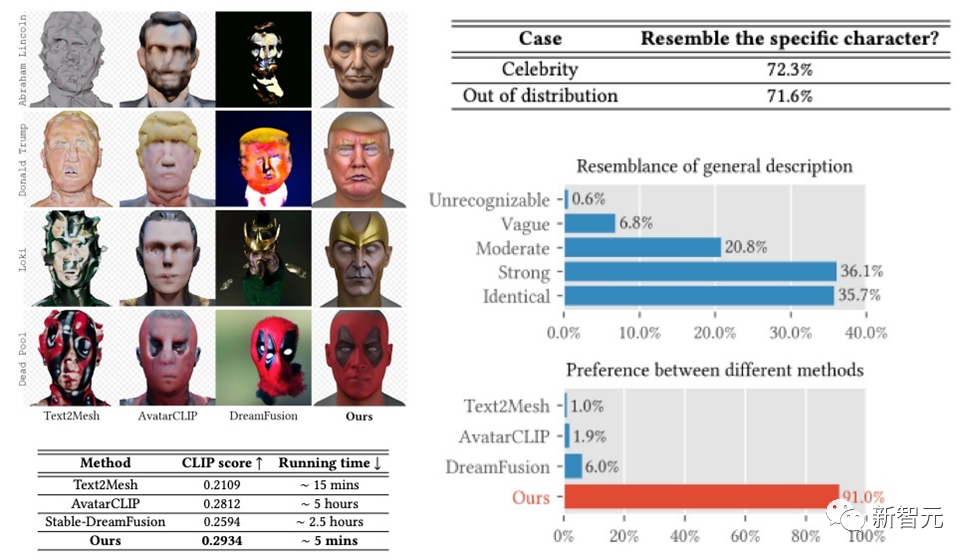
DreamFace框架在名人生成,根據描述生成角色上都取得了相當不錯的效果,在User Study中獲得了遠超過先前工作的成績。相較於先前的工作,在運行時間上也具備明顯的優勢。
除此之外,DreamFace也支援使用提示和草圖進行紋理編輯。透過直接使用微調的紋理LDM和提示,可以實現全局的編輯效果,如老化和化妝。透過進一步結合遮罩或草圖,可以創造各種效果,如紋身、鬍鬚和胎記。

#動畫能力產生
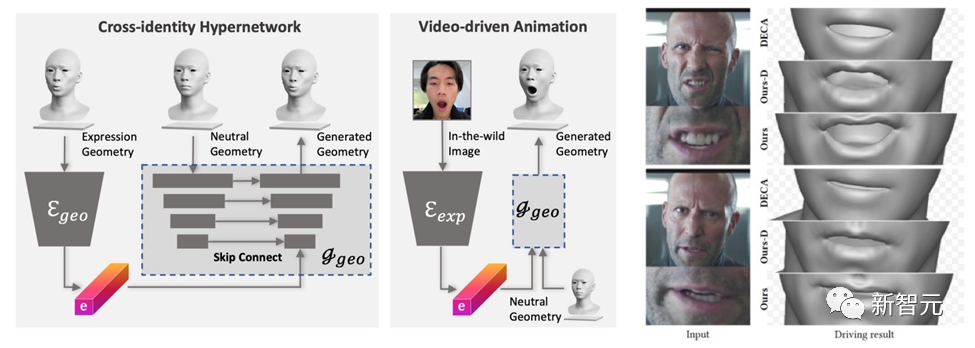
########################################## #DreamFace生成的模式具備動畫能力。與基於BlendShapes的方法不同,DreamFace的神經面部動畫方法透過預測獨特的變形來為生成的靜息(Neutral)模型賦予動畫效果,從而產生個性化的動畫。 ######
首先,訓練一個幾何生成器,學習表情的潛在空間,其中解碼器被擴展為以中性幾何形狀為條件。接著,進一步訓練表情編碼器,從RGB影像中提取表情特徵。因此,DreamFace能夠透過使用單目RGB影像以中性幾何形狀為條件來產生個人化的動畫。
與使用通用BlendShapes進行表情控制的DECA相比,DreamFace的框架提供了細緻的表情細節,並且能夠精細地捕捉表演。
結論
本文介紹了DreamFace,一種文字指導的漸進式3D生成框架,它結合了最新的視覺-語言模型、隱式擴散模型,以及基於物理的材質擴散技術。
DreamFace的主要創新包括幾何體生成、基於物理的材質擴散生成和動畫能力生成。與傳統的3D生成方法相比,DreamFace具有更高的準確性、更快的運行速度和較好的CG管線相容性。
DreamFace的漸進式生成框架為解決複雜的3D生成任務提供了一個有效的解決方案,有望推動更多類似的研究和技術發展。
此外,基於物理的材質擴散生成和動畫能力生成將推動3D生成技術在影視製作、遊戲開發和其他相關行業的應用。
以上是上科大等發表DreamFace:只需文字即可產生「超寫實3D數位人」的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 上科大等發表DreamFace:只需文字即可產生「超寫實3D數位人」
May 17, 2023 am 08:02 AM
上科大等發表DreamFace:只需文字即可產生「超寫實3D數位人」
May 17, 2023 am 08:02 AM
隨著大型語言模式(LLM)、擴散(Diffusion)等技術的發展,ChatGPT、Midjourney等產品的誕生掀起了新一波的AI熱潮,生成式AI也成為備受關注的話題。與文字和圖像不同,3D生成仍處於技術探索階段。 2022年年底,Google、NVIDIA和微軟相繼推出了自己的3D生成工作,但大多基於先進的神經輻射場(NeRF)隱式表達,與工業界3D軟體如Unity、UnrealEngine和Maya等的渲染管線不相容。即使透過傳統方案將其轉換為Mesh表達的幾何和顏色貼圖,也會造成精度不足
 大模型捲爆數字人:一句話5分鐘實現定制,跳舞主持帶貨都能hold住
May 08, 2024 pm 08:10 PM
大模型捲爆數字人:一句話5分鐘實現定制,跳舞主持帶貨都能hold住
May 08, 2024 pm 08:10 PM
最快5分鐘,打造一個直接上崗工作的3D數位人。這是大模型為數位人領域帶來的最新震撼。就像這樣,一句話描述需求:產生的數位人直接就能進駐直播間當主播。跳起女團舞也不在話下。整個製作過程中,想到什麼說什麼就行,大模型都能自動拆解需求,瞬間get設計、修改思路。 △2倍速再也不怕老闆/甲方的想法太新奇。這樣的文生數位人技術,來自百度智慧雲端最新發布。該說不說,是要把數字人的使用門檻一口氣砍沒的節奏了。聽聞如此神器,我們照例第一時間爭取到了內測資格,更多細節,一起先睹為快~一句話5分鐘,3D數字人直接上崗從
 完蛋,我被數位同事包圍了!小冰AI數位員工再升級,零樣本定制,即時上崗
Jul 19, 2024 pm 05:52 PM
完蛋,我被數位同事包圍了!小冰AI數位員工再升級,零樣本定制,即時上崗
Jul 19, 2024 pm 05:52 PM
「你好,我在咱們公司剛入職。業務上有什麼事兒,就請您多多指教啦!」什麼,這些同事竟然都是大模型驅動的「數字人」?只需30秒畫面,10秒音頻,10分鐘就能極速定制一個這樣和真人無異的「數位同事」。它可以直接和你即時交互,並且有著通訊運營商級別的高品質低延遲的音畫傳輸。就這樣:像這樣:這是小冰公司最新上線的「零樣本」數位人(Zero-shotXiaoiceNeuralRendering,Zero-XNR)技術,依托超千億大模型基座,新技
 數位人點燃亞運主火炬,從這篇ICCV論文透視螞蟻的生成式AI黑科技
Sep 29, 2023 pm 11:57 PM
數位人點燃亞運主火炬,從這篇ICCV論文透視螞蟻的生成式AI黑科技
Sep 29, 2023 pm 11:57 PM
打開一個數位人,裡面全是生成式AI。 9月23日晚上,杭州亞運會的開幕式上,點燃主火炬的環節展現了上億線上數字火炬手的「小火苗」聚集在錢塘江上,形成了一個數字人形象。接著,數位人火炬手和現場的第六棒火炬手一同走到火炬台前,共同點燃了主火炬作為開幕式的核心創意,數實互聯的火炬點燃形式衝上了熱搜,引發了人們的重點關注。重寫後的內容:作為開幕式的核心創意,數實互聯的火炬點燃方式引起了熱議,吸引了人們的關注數字人點火是一個前所未有的創舉,上億人參與其中,涉及了大量先進且複雜的技術。其中最重要的問題之一是如
 DreamFace:一句話生成 3D 數位人?
May 16, 2023 pm 09:46 PM
DreamFace:一句話生成 3D 數位人?
May 16, 2023 pm 09:46 PM
在科技迅速發展的今天,生成式人工智慧和電腦圖形學領域的研究日益引人注目,影視製作、遊戲開發等產業正面臨巨大的挑戰和機會。本文將為您介紹一項3D生成領域的研究—DreamFace,它是首個支援Production-Ready3D資產生成的文本指導漸進式3D生成框架,能夠實現文本生成可驅動的3D超寫實數位人。這項工作已經被電腦圖形領域國際頂尖期刊TransactionsonGraphics接收,並將在國際電腦圖形頂級會議SIGGRAPH2023上展示。專案網站:https://sites.
 Unity大中華區平台技術總監楊棟:開啟元宇宙的數位人之旅
Apr 08, 2023 pm 06:11 PM
Unity大中華區平台技術總監楊棟:開啟元宇宙的數位人之旅
Apr 08, 2023 pm 06:11 PM
作為建構元宇宙內容的基石,數位人是最早可落地且可持續發展的元宇宙細分成熟場景,目前,虛擬偶像、電商帶貨、電視主持、虛擬主播等商業應用已被大眾認可。在元宇宙世界中,最核心的內容之一非數字人莫屬,因為數字人不光是真實世界人類在元宇宙中的“化身”,也是我們在元宇宙中進行各種交互的重要載具之一。眾所周知,創建和渲染逼真的數位人類角色是電腦圖形學中最困難的問題之一。近日,在由51CTO主辦的MetaCon元宇宙技術大會《遊戲與AI互動》分會場中,Unity大中華區平台技術總監楊棟透過一系列的Demo演示
 AI+數位人實現全新互動 中國電信攜AI帶來智慧生活
May 27, 2023 pm 12:34 PM
AI+數位人實現全新互動 中國電信攜AI帶來智慧生活
May 27, 2023 pm 12:34 PM
(圖片來源:攝圖網)(記者陳錦鋒)近日,2023上海資訊消費節拉開序幕,「數位人」成為當仁不讓的主角。業內人士認為,AI技術應用將加快優質內容開發,虛擬數位人或成為新的流量入口。 AI數位人走進日常生活隨著人工智慧、虛擬實境等技術的發展,虛擬數位人走進人們日常生活,在許多領域發揮獨特作用。虛擬美妝達人柳夜熙,抖音出道三天點讚即超百萬,一夜之間成為國內虛擬偶像界的頂流;在江蘇衛視跨年演唱會上,昔日歌后鄧麗君重返舞台,與歌手週深同台對唱,交織幾代人的青春記憶;20多位數位人同台亮相冬奧會,擔任手語主
 什麼是數位人,未來前景如何?
Oct 16, 2023 pm 02:25 PM
什麼是數位人,未來前景如何?
Oct 16, 2023 pm 02:25 PM
在當今技術先進的世界中,栩栩如生的數位人已經成為了一個備受關注的新興領域。作為一種基於電腦圖形(CG)技術與人工智慧技術創造出的與人類形象接近的數位化虛擬形象,數位人能夠為人們提供更便利、更有效率、更個人化的服務。同時,數位人的出現也可以促進虛擬經濟的發展,為數位內容創新和數位消費提供更多機會。根據國際數據公司(IDC)發布的報告預測,全球虛擬數位人市場規模預計在2025年將達到270億美元,年複合成長率高達22.5%。由此可見,數位人具有非常廣泛的應用前景和市場潛力。什麼是數位人?數位人是運
