

達摩院貓頭鷹mPLUG-Owl亮相:模組化多模態大模型,追趕GPT-4多模態能力

純文字大模型方興未艾,多模態領域也開始湧現出多模態大模型工作,地表最強的GPT-4 具備讀圖的多模態能力,但是遲遲未向公眾開放體驗,於是乎研究社群開始在這個方向上發力研究並開源。 MiniGPT-4 和 LLaVA 問世不久,阿里達摩院便推出 mPLUG-Owl ,一個基於模組化實現的多模態大模型。
mPLUG-Owl 是阿⾥巴巴達摩院 mPLUG 系列的最新工作,延續了 mPLUG 系列的模組化訓練思想,把 LLM 升級為一個多模態大模型。在 mPLUG 系列工作中,先前的 E2E-VLP 、mPLUG 、mPLUG-2 分別被 ACL2021 、EMNLP2022、ICML2023 錄用,其中 mPLUG 工作在 VQA 榜單首超人類的成績。
今天要介紹的是mPLUG-Owl,該工作不僅透過大量cases 展示出優秀的多模態能力,還第一次針對視覺相關的指令理解提出一個全⾯的測試集OwlEval,透過人工評測比較了已有模型,包括LLaVA 、MiniGPT-4 、BLIP-2 以及系統類MM-REACT 等工作,實驗結果表明mPLUG-Owl 展示出更優的多模態能力,尤其在多模態指令理解能力、多輪對話能力、知識推理能力等方⾯表現突出

論文連結:https://arxiv.org/abs/2304.14178
程式碼連結:https://github.com/X-PLUG /mPLUG-Owl
##https://modelscope. cn/studios/damo/mPLUG-Owl/summary

#HuggingFace體驗位址:
 https://huggingface.co/spaces/MAGAer13/mPLUG-Owl
https://huggingface.co/spaces/MAGAer13/mPLUG-Owl
多模態能力展示
我們把mPLUG-Owl 與現有工作進行比較來感受一下mPLUG-Owl 的多模態效果,值得一提的是,該工作中評比的測試樣例基本上都來自已有工作,避免了cherry pick 問題。
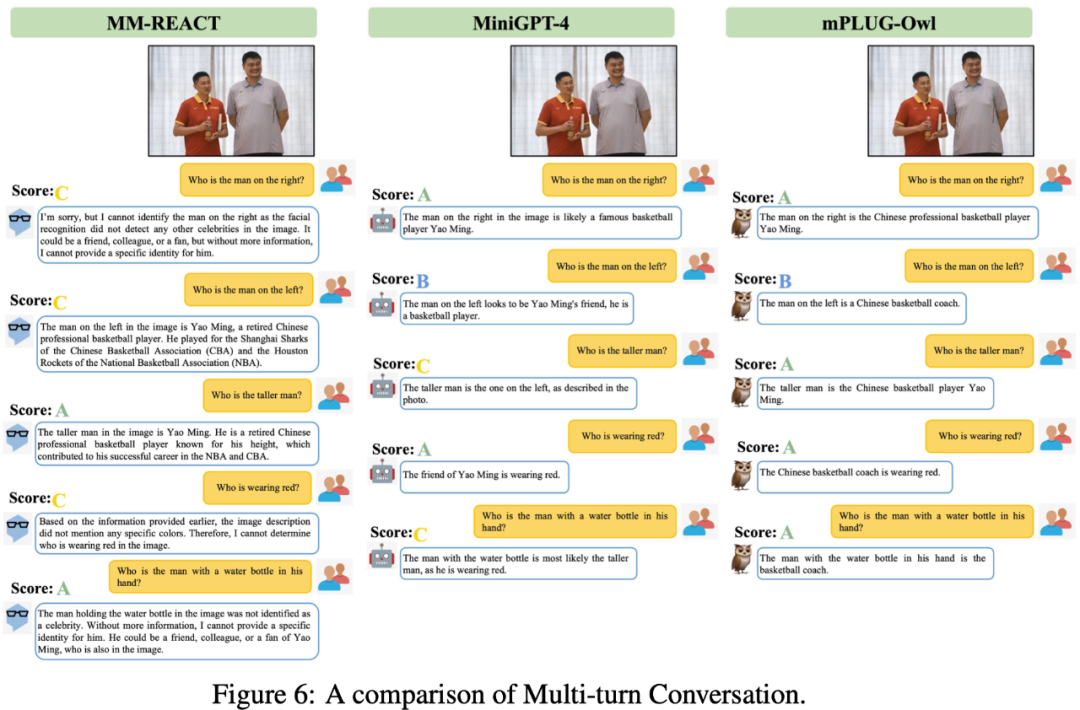
下圖 6 展示了 mPLUG-Owl 很強的多輪對話能力。

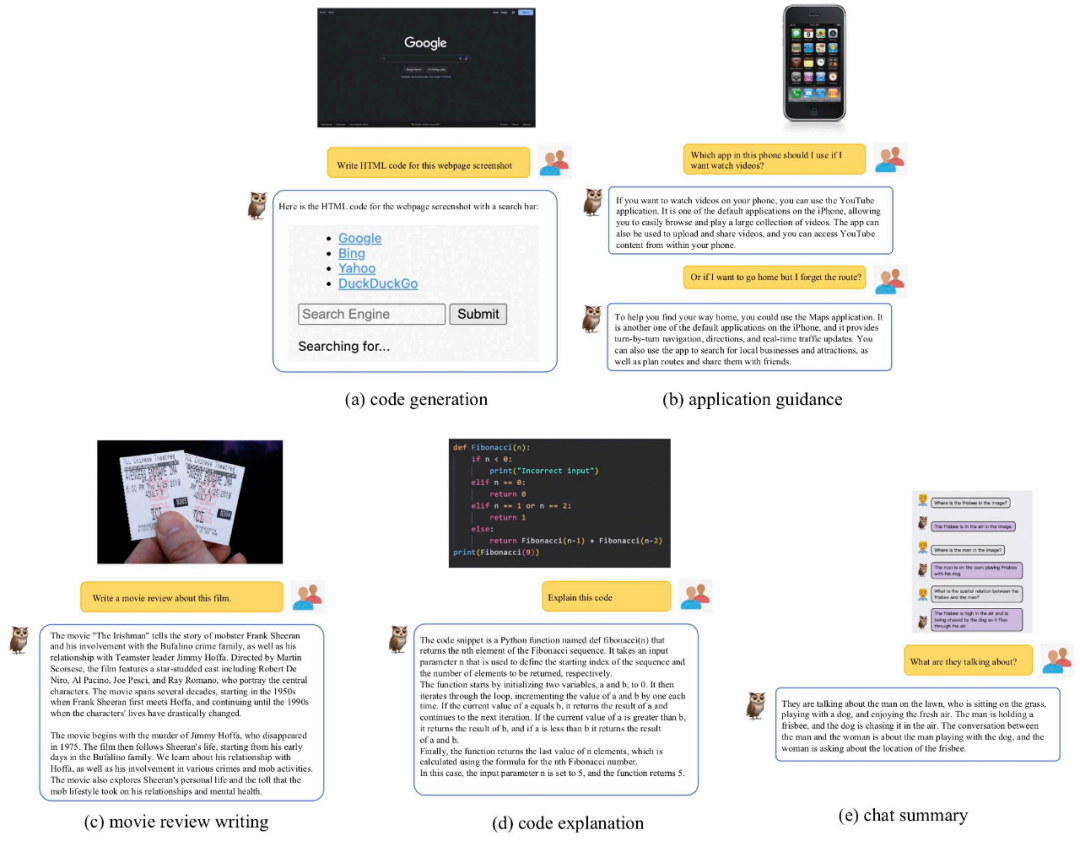
###從圖 7 可以發現, mPLUG-Owl 具有很強的推理能力。 ###########################如圖 9 展示了一些笑話解釋範例⼦。 ###########################在該工作中,除了評測對比外,該研究團隊還觀察到mPLUG-Owl 初顯一些意想不到的能力,例如多圖關聯、多語⾔、文字辨識和文件理解等能力。 ############如圖 10 所示,雖然在訓練階段並沒有進行多圖關聯資料的訓練,mPLUG-Owl 展現出了一定的多圖關聯能力。 ###########################如圖11 所示,儘管mPLUG-Owl 在訓練階段僅使用了英文數據,但其展現出了有趣的多語⾔能力。這可能是因為 mPLUG-Owl 中的語⾔模型使用了 LLaMA,因而出現了這一現象。 ######

儘管mPLUG-Owl 沒有在帶有標註的文檔資料上進行訓練,但其仍然展現出了一定的文字識別和文檔理解能力,測試結果如圖12 所示。
方法介紹
#該工作所提出的mPLUG-Owl,其整體架構如圖2 所示。
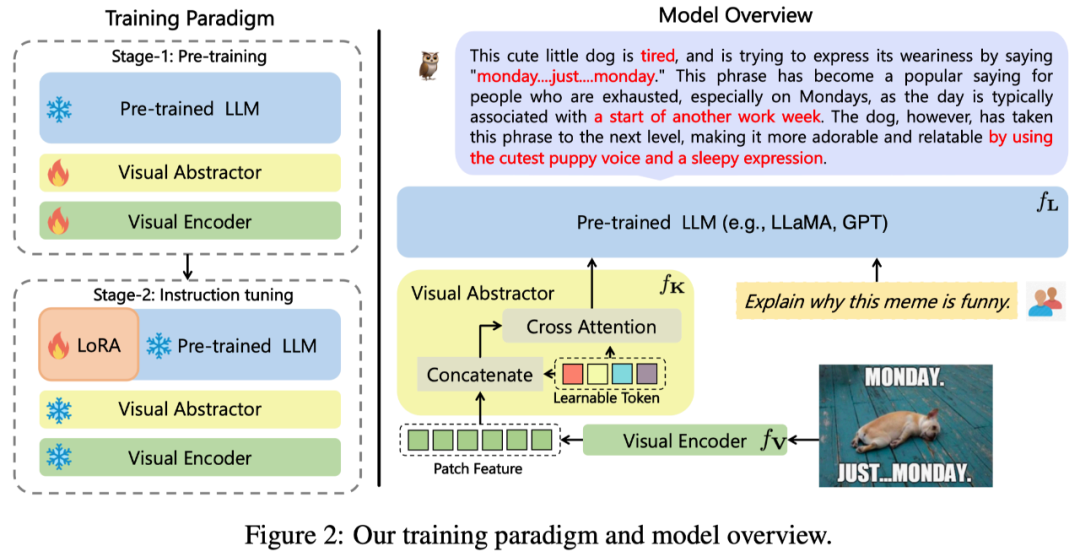
模型結構:它由視覺基礎模組
(開源的ViT-L)、視覺抽像模組
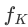
#以及預訓練語⾔模型
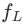
( LLaMA-7B) 組成。視覺抽像模組將較⻓的、細粒度的影像特徵概括為少量可學習的 Token,從而實現對視覺資訊的⾼效建模。 ⽣成的視覺 Token 與文字查詢一起輸⼊到語⾔模型中,以⽣成對應的回應。
模型訓練:採用兩階段的訓練方式
第一階段:主要目的也是先學習視覺和語⾔模態間的對⻬。有別於先前的工作, mPLUG-Owl 提出凍住視覺基礎模組會限制模型關聯視覺知識和文字知識的能力。 因此 mPLUG-Owl 在第一階段只凍住 LLM 的參數,採用 LAION-400M, COYO-700M, CC 以及 MSCOCO 訓練視覺基礎模組和視覺摘要模組。
第⼆階段:延續mPLUG 和mPLUG-2 中不同模態混合訓練對彼此有收益的發現,Owl 在第⼆階段的指令微調訓練中也同時採用了純文本的指令資料(52kfrom Alpaca 90k from Vicuna 50k from Baize) 和多模態的指令資料(150k from LLaVA)。作者透過詳細的消融實驗驗證了引⼊純文字指令微調在指令理解等方⾯帶來的效益。 ⼆階段中視覺基礎模組、視覺摘要模組和原始 LLM 的參數都被凍住,參考 LoRA,只在 LLM 引⼊少量參數的 adapter 結構用於指令微調。
實驗結果
SOTA 對比
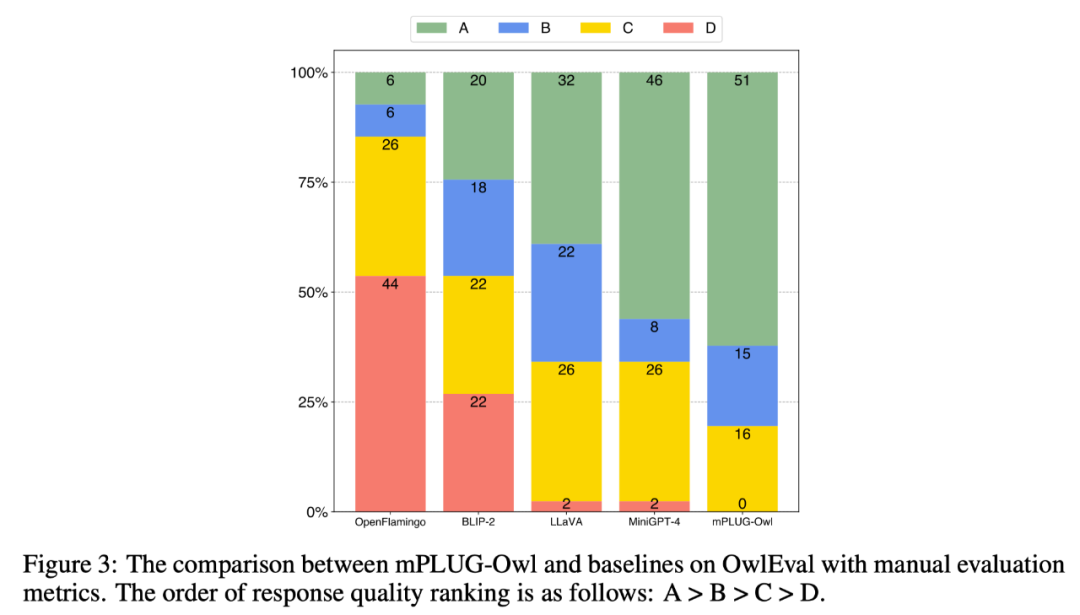
為了比較不同模型的多模態能力,該工作建構一個多模態指令評測集OwlEval。由於⽬前並沒有適當的自動化指標,參考Self-Intruct 對模型的回復進行人工評測,打分規則為:A="正確且令人滿意";B="有一些不完美,但可以接受";C ="理解了指令但是回復有明顯錯誤";D="完全不相關或不正確的回應"。
比較結果如下圖 3 所示,實驗證明 Owl 在視覺相關的指令回復任務上優於現有的 OpenFlamingo 、BLIP-2 、LLaVA、MiniGPT-4。
多重維度能力比較
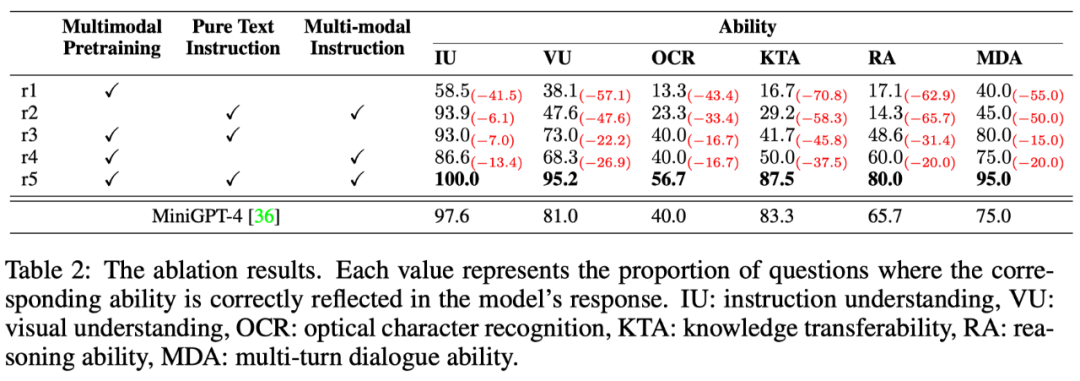
多模態指令回復任務中牽扯到多種能力,例如指令理解、視覺理解、圖⽚上文字理解以及推理等。為了細粒度地探究模型在不同能力上的⽔平,本文進一步定義了多模態場景中的6 種主要的能力,並對OwlEval 每個測試指令人工標註了相關的能力要求以及模型的回復中體現了哪些能力。
結果如下表格6 所示,在該部分實驗,作者既進行了Owl 的消融實驗,驗證了訓練策略和多模態指令微調資料的有效性,也和上一個實驗中表現最佳的baseline— MiniGPT4 進行了對比,結果顯示Owl 在各個能力方⾯都優於MiniGPT4。
以上是達摩院貓頭鷹mPLUG-Owl亮相:模組化多模態大模型,追趕GPT-4多模態能力的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 數字貨幣交易所App前十名蘋果版下載入口匯總
Apr 22, 2025 am 09:27 AM
數字貨幣交易所App前十名蘋果版下載入口匯總
Apr 22, 2025 am 09:27 AM
提供各種複雜的交易工具和市場分析。覆蓋 100 多個國家,日均衍生品交易量超 300 億美元,支持 300 多個交易對與 200 倍槓桿,技術實力強大,擁有龐大的全球用戶基礎,提供專業的交易平台、安全存儲解決方案以及豐富的交易對。
 排名前十的虛擬貨幣交易app有哪些 十大數字貨幣交易所平台推薦
Apr 22, 2025 pm 01:12 PM
排名前十的虛擬貨幣交易app有哪些 十大數字貨幣交易所平台推薦
Apr 22, 2025 pm 01:12 PM
2025年安全的數字貨幣交易所排名前十依次為:1. Binance,2. OKX,3. gate.io,4. Coinbase,5. Kraken,6. Huobi,7. Bitfinex,8. KuCoin,9. Bybit,10. Bitstamp,這些平台均採用了多層次的安全措施,包括冷熱錢包分離、多重簽名技術以及24/7的監控系統,確保用戶資金的安全。
 穩定幣有哪些?穩定幣如何交易?
Apr 22, 2025 am 10:12 AM
穩定幣有哪些?穩定幣如何交易?
Apr 22, 2025 am 10:12 AM
常見的穩定幣有:1. 泰達幣(USDT),由Tether發行,與美元掛鉤,應用廣泛但透明性曾受質疑;2. 美元幣(USDC),由Circle和Coinbase發行,透明度高,受機構青睞;3. 戴幣(DAI),由MakerDAO發行,去中心化,DeFi領域受歡迎;4. 幣安美元(BUSD),由幣安和Paxos合作,交易和支付表現出色;5. 真實美元(TUSD),由TrustTo
 目前有多少穩定幣交易所?穩定幣種類有多少?
Apr 22, 2025 am 10:09 AM
目前有多少穩定幣交易所?穩定幣種類有多少?
Apr 22, 2025 am 10:09 AM
截至2025年,穩定幣交易所數量約為千家。 1. 法定貨幣支持的穩定幣包括USDT、USDC等。 2. 加密貨幣支持的穩定幣如DAI、sUSD。 3. 算法穩定幣如TerraUSD。 4. 還有混合型穩定幣。

 幣圈十大交易所有哪些 最新幣圈app推薦
Apr 24, 2025 am 11:57 AM
幣圈十大交易所有哪些 最新幣圈app推薦
Apr 24, 2025 am 11:57 AM
選擇可靠的交易所至關重要,Binance、OKX、Gate.io等十大交易所各具特色,CoinGecko、Crypto.com等新app也值得關注。
 2025下一個千倍幣可能有哪些
Apr 24, 2025 pm 01:45 PM
2025下一個千倍幣可能有哪些
Apr 24, 2025 pm 01:45 PM
截至2025年4月,有七个加密货币项目被认为具有显著增长潜力:1. Filecoin(FIL)通过分布式存储网络实现快速发展;2. Aptos(APT)以高性能Layer 1公链吸引DApp开发者;3. Polygon(MATIC)提升以太坊网络性能;4. Chainlink(LINK)作为去中心化预言机网络满足智能合约需求;5. Avalanche(AVAX)以快速交易和

