

Python遞歸下降Parser怎麼實現

1. 算術運算表達式求值
#要解析這類文本,需要另外一種特定的語法規則。我們在這裡介紹可以表示上下文無關文法(context free grammer)的語法規則巴科斯範式(BNF)和擴展巴科斯範式(EBNF)。從小到一個算術運算表達式,到大到幾乎所有程式設計語言,都是利用上下文無關文法來定義的。
對於簡單的算術運算表達式,假定我們已經用分詞技術將其轉換為輸入的tokens流,如NUM NUM*NUM(分詞方法參見上一篇博文)。
在此基礎上,我們定義BNF規則定義如下:
expr ::= expr + term
| expr - term
| term
term ::= term * factor
| term / factor
| factor
factor ::= (expr)
| NUM當然,這種計法還不夠簡潔明了,我們實際採用的為EBNF形式:
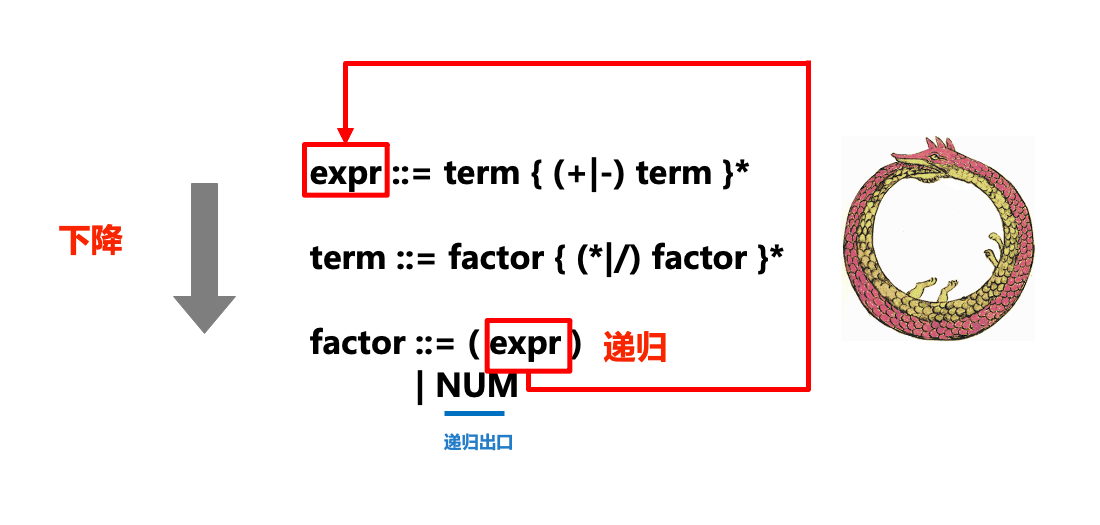
expr ::= term { (+|-) term }*
term ::= factor { (*|/) factor }*
factor ::= (expr)
| NUMBNF和EBNF每一條規則(形如::=的式子)都可以看做是一種替換,即左側的符號可以被右側的符號所替換。我們在解析過程中嘗試使用BNF/EBNF將輸入文字與語法規則進行匹配,以完成各種替換和擴展。在EBNF中,被放置在{...}*內的規則是可選的,而*則表示可以重複零次或多次(類比於正規表示式)。
下圖形像地展示了遞歸下降解析器(parser)中「遞歸」和「下降」部分和ENBF的關係:
class ExpressionEvaluator():
...
def expr(self):
...
def term(self):
...
def factor(self):
...expr ::= term { ( |-) term }*),我們則透過while循環來實現。
import re
import collections
# 定义匹配token的模式
NUM = r'(?P<NUM>\d+)' # \d表示匹配数字,+表示任意长度
PLUS = r'(?P<PLUS>\+)' # 注意转义
MINUS = r'(?P<MINUS>-)'
TIMES = r'(?P<TIMES>\*)' # 注意转义
DIVIDE = r'(?P<DIVIDE>/)'
LPAREN = r'(?P<LPAREN>\()' # 注意转义
RPAREN = r'(?P<RPAREN>\))' # 注意转义
WS = r'(?P<WS>\s+)' # 别忘记空格,\s表示空格,+表示任意长度
master_pat = re.compile(
'|'.join([NUM, PLUS, MINUS, TIMES, DIVIDE, LPAREN, RPAREN, WS]))
# Tokenizer
Token = collections.namedtuple('Token', ['type', 'value'])
def generate_tokens(text):
scanner = master_pat.scanner(text)
for m in iter(scanner.match, None):
tok = Token(m.lastgroup, m.group())
if tok.type != 'WS': # 过滤掉空格符
yield tokclass ExpressionEvaluator():
""" 递归下降的Parser实现,每个语法规则都对应一个方法,
使用 ._accept()方法来测试并接受当前处理的token,不匹配不报错,
使用 ._except()方法来测试当前处理的token,并在不匹配的时候抛出语法错误
"""
def parse(self, text):
""" 对外调用的接口 """
self.tokens = generate_tokens(text)
self.tok, self.next_tok = None, None # 已匹配的最后一个token,下一个即将匹配的token
self._next() # 转到下一个token
return self.expr() # 开始递归
def _next(self):
""" 转到下一个token """
self.tok, self.next_tok = self.next_tok, next(self.tokens, None)
def _accept(self, tok_type):
""" 如果下一个token与tok_type匹配,则转到下一个token """
if self.next_tok and self.next_tok.type == tok_type:
self._next()
return True
else:
return False
def _except(self, tok_type):
""" 检查是否匹配,如果不匹配则抛出异常 """
if not self._accept(tok_type):
raise SyntaxError("Excepted"+tok_type)
# 接下来是语法规则,每个语法规则对应一个方法
def expr(self):
""" 对应规则: expression ::= term { ('+'|'-') term }* """
exprval = self.term() # 取第一项
while self._accept("PLUS") or self._accept("DIVIDE"): # 如果下一项是"+"或"-"
op = self.tok.type
# 再取下一项,即运算符右值
right = self.term()
if op == "PLUS":
exprval += right
elif op == "MINUS":
exprval -= right
return exprval
def term(self):
""" 对应规则: term ::= factor { ('*'|'/') factor }* """
termval = self.factor() # 取第一项
while self._accept("TIMES") or self._accept("DIVIDE"): # 如果下一项是"+"或"-"
op = self.tok.type
# 再取下一项,即运算符右值
right = self.factor()
if op == "TIMES":
termval *= right
elif op == "DIVIDE":
termval /= right
return termval
def factor(self):
""" 对应规则: factor ::= NUM | ( expr ) """
if self._accept("NUM"): # 递归出口
return int(self.tok.value)
elif self._accept("LPAREN"):
exprval = self.expr() # 继续递归下去求表达式值
self._except("RPAREN") # 别忘记检查是否有右括号,没有则抛出异常
return exprval
else:
raise SyntaxError("Expected NUMBER or LPAREN")e = ExpressionEvaluator()
print(e.parse("2"))
print(e.parse("2+3"))
print(e.parse("2+3*4"))
print(e.parse("2+(3+4)*5"))2如果我們輸入的文字不符合語法規則:5
14
37
print(e.parse("2 + (3 + * 4)"))Expected NUMBER or LPAREN。 綜上,可見我們的表達式求值演算法運行正確。
class ExpressionTreeBuilder(ExpressionEvaluator):
def expr(self):
""" 对应规则: expression ::= term { ('+'|'-') term }* """
exprval = self.term() # 取第一项
while self._accept("PLUS") or self._accept("DIVIDE"): # 如果下一项是"+"或"-"
op = self.tok.type
# 再取下一项,即运算符右值
right = self.term()
if op == "PLUS":
exprval = ('+', exprval, right)
elif op == "MINUS":
exprval -= ('-', exprval, right)
return exprval
def term(self):
""" 对应规则: term ::= factor { ('*'|'/') factor }* """
termval = self.factor() # 取第一项
while self._accept("TIMES") or self._accept("DIVIDE"): # 如果下一项是"+"或"-"
op = self.tok.type
# 再取下一项,即运算符右值
right = self.factor()
if op == "TIMES":
termval = ('*', termval, right)
elif op == "DIVIDE":
termval = ('/', termval, right)
return termval
def factor(self):
""" 对应规则: factor ::= NUM | ( expr ) """
if self._accept("NUM"): # 递归出口
return int(self.tok.value) # 字符串转整形
elif self._accept("LPAREN"):
exprval = self.expr() # 继续递归下去求表达式值
self._except("RPAREN") # 别忘记检查是否有右括号,没有则抛出异常
return exprval
else:
raise SyntaxError("Expected NUMBER or LPAREN")print(e.parse("2+3"))
print(e.parse("2+3*4"))
print(e.parse("2+(3+4)*5"))
print(e.parse('2+3+4'))(' ' , 2, 3)可以看到表達式樹產生正確。 我們上面的這個例子非常簡單,但遞歸下降的解析器也可以用來實現相當複雜的解析器,例如Python程式碼就是透過一個遞歸下降解析器解析的。您要是對此跟感興趣可以檢查Python原始碼中的(' ', 2, ('*', 3, 4))
(' ', 2, ('*', (' ', 3, 4), 5))
(' ', (' ', 2, 3), 4)
Grammar檔案來一探究竟。然而,下面我們接著會看到,自己動手寫一個解析器會面對各種陷阱和挑戰。
左遞歸形式的語法規則,都沒法用遞歸下降parser來解決。所謂左遞歸,即規則式子右側最左邊的符號是規則頭,例如對於以下規則:
items ::= items ',' item
| itemdef items(self):
itemsval = self.items() # 取第一项,然而此处会无穷递归!
if itemsval and self._accept(','):
itemsval.append(self.item())
else:
itemsval = [self.item()]self.items()從而產生無窮遞歸錯誤。
expr ::= factor { ('+'|'-'|'*'|'/') factor }*
factor ::= '(' expr ')'
| NUM以上是Python遞歸下降Parser怎麼實現的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 PHP和Python:解釋了不同的範例
Apr 18, 2025 am 12:26 AM
PHP和Python:解釋了不同的範例
Apr 18, 2025 am 12:26 AM
PHP主要是過程式編程,但也支持面向對象編程(OOP);Python支持多種範式,包括OOP、函數式和過程式編程。 PHP適合web開發,Python適用於多種應用,如數據分析和機器學習。
 在PHP和Python之間進行選擇:指南
Apr 18, 2025 am 12:24 AM
在PHP和Python之間進行選擇:指南
Apr 18, 2025 am 12:24 AM
PHP適合網頁開發和快速原型開發,Python適用於數據科學和機器學習。 1.PHP用於動態網頁開發,語法簡單,適合快速開發。 2.Python語法簡潔,適用於多領域,庫生態系統強大。
 PHP和Python:深入了解他們的歷史
Apr 18, 2025 am 12:25 AM
PHP和Python:深入了解他們的歷史
Apr 18, 2025 am 12:25 AM
PHP起源於1994年,由RasmusLerdorf開發,最初用於跟踪網站訪問者,逐漸演變為服務器端腳本語言,廣泛應用於網頁開發。 Python由GuidovanRossum於1980年代末開發,1991年首次發布,強調代碼可讀性和簡潔性,適用於科學計算、數據分析等領域。
 Python vs. JavaScript:學習曲線和易用性
Apr 16, 2025 am 12:12 AM
Python vs. JavaScript:學習曲線和易用性
Apr 16, 2025 am 12:12 AM
Python更適合初學者,學習曲線平緩,語法簡潔;JavaScript適合前端開發,學習曲線較陡,語法靈活。 1.Python語法直觀,適用於數據科學和後端開發。 2.JavaScript靈活,廣泛用於前端和服務器端編程。
 vs code 可以在 Windows 8 中運行嗎
Apr 15, 2025 pm 07:24 PM
vs code 可以在 Windows 8 中運行嗎
Apr 15, 2025 pm 07:24 PM
VS Code可以在Windows 8上運行,但體驗可能不佳。首先確保系統已更新到最新補丁,然後下載與系統架構匹配的VS Code安裝包,按照提示安裝。安裝後,注意某些擴展程序可能與Windows 8不兼容,需要尋找替代擴展或在虛擬機中使用更新的Windows系統。安裝必要的擴展,檢查是否正常工作。儘管VS Code在Windows 8上可行,但建議升級到更新的Windows系統以獲得更好的開發體驗和安全保障。
 sublime怎麼運行代碼python
Apr 16, 2025 am 08:48 AM
sublime怎麼運行代碼python
Apr 16, 2025 am 08:48 AM
在 Sublime Text 中運行 Python 代碼,需先安裝 Python 插件,再創建 .py 文件並編寫代碼,最後按 Ctrl B 運行代碼,輸出會在控制台中顯示。
 visual studio code 可以用於 python 嗎
Apr 15, 2025 pm 08:18 PM
visual studio code 可以用於 python 嗎
Apr 15, 2025 pm 08:18 PM
VS Code 可用於編寫 Python,並提供許多功能,使其成為開發 Python 應用程序的理想工具。它允許用戶:安裝 Python 擴展,以獲得代碼補全、語法高亮和調試等功能。使用調試器逐步跟踪代碼,查找和修復錯誤。集成 Git,進行版本控制。使用代碼格式化工具,保持代碼一致性。使用 Linting 工具,提前發現潛在問題。
 vscode在哪寫代碼
Apr 15, 2025 pm 09:54 PM
vscode在哪寫代碼
Apr 15, 2025 pm 09:54 PM
在 Visual Studio Code(VSCode)中編寫代碼簡單易行,只需安裝 VSCode、創建項目、選擇語言、創建文件、編寫代碼、保存並運行即可。 VSCode 的優點包括跨平台、免費開源、強大功能、擴展豐富,以及輕量快速。
