
#np.random.permutation() 整體來說他是一個隨機排列函數,就是將輸入的資料進行隨機排列,官方文件指出,此函數只能針對一維資料隨機排列,對於多維資料只能對第一維度的資料進行隨機排列。
簡而言之:np.random.permutation函數的作用就是按照給定列表產生一個打亂後的隨機列表
在處理數據集時,通常可以使用該函數進行打亂資料集內部順序,並按照相同的順序進行標籤序列的打亂。
import numpy as np data = np.array([1,2,3,4,5,6,7]) a = np.random.permutation(data) b = np.random.permutation([5,0,9,0,1,1,1]) print(a) print( "data:", data ) print(b)
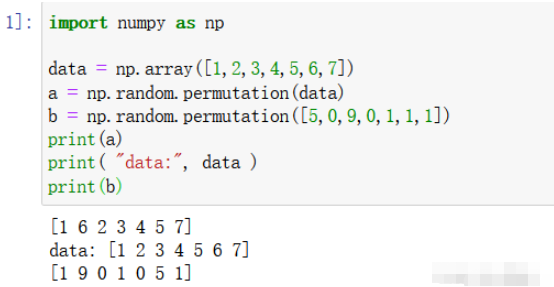
label = np.array([1,2,3,4,5,6,7])
a = np.random.permutation(np.arange(len(label)))
print("Label[a] :" ,label[a] )
補充:一般只能用於N維數組只能將整數標量數組轉換為標量索引
why?label1[a1] label1是列表,a1是列表下標的隨機排列但是!列表結構沒有標量索引label1[a1]報錯
label1=[1,2,3,4,5,6,7]
print(len(label1))
a1 = np.random.permutation(np.arange(len(label1)))#有结果
print(a1)
print("Label1[a1] :" ,label1[a1] )#这列表结构没有标量索引 所以会报错
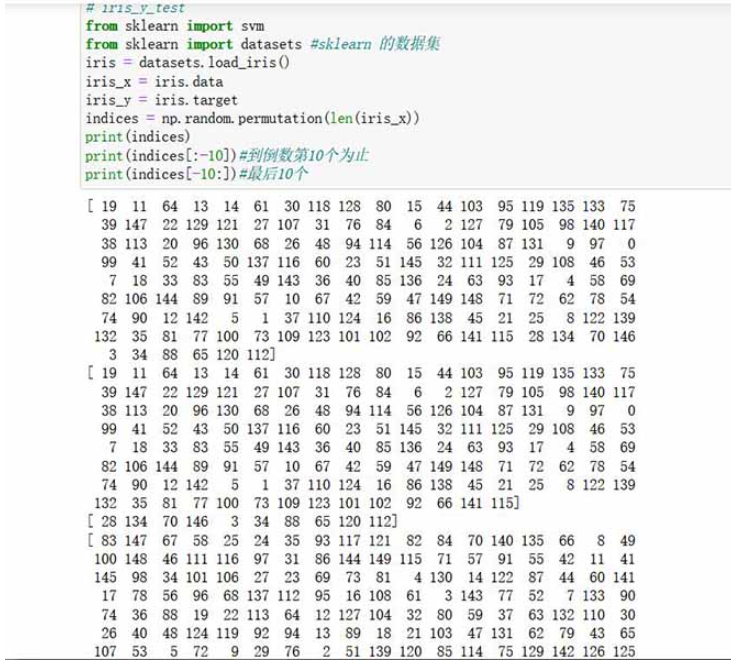
from sklearn import svm from sklearn import datasets #sklearn 的数据集 iris = datasets.load_iris() iris_x = iris.data iris_y = iris.target indices = np.random.permutation(len(iris_x)) #此时 打乱的是数组的下标的排序 print(indices) print(indices[:-10])#到倒数第10个为止 print(indices[-10:])#最后10个 # print(type(iris_x)) <class 'numpy.ndarray'> #9:1分类 #iris_x_train = iris_x[indices[:-10]]#使用的数组打乱后的下标 #iris_y_train = iris_y[indices[:-10]] #iris_x_test= iris_x[indices[-10:]] #iris_y_test= iris_y[indices[-10:]]
陣列下標即標量索引的重新分佈情況: 下標是0開始
以上是python中的np.random.permutation函數怎麼使用的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















