

用ChatGPT寫程式碼,已經是不少程式設計師的常規操作了。
但你有沒有想過,ChatGPT產生的程式碼,有不少只是「看起來準確」而已?
來自伊利諾大學香檳分校和南京大學的一項最新研究表明:
ChatGPT和GPT-4生成程式碼的準確率,比之前評估的至少要降低13%!

有網友感嘆,太多ML論文都在用一些有問題或有限制的基準來評估模型,來短暫地達到“SOTA”,結果換個測評方法就現出原形了。

還有網友表示,這也說明大模型產生的程式碼仍然需要人工監督,「AI寫程式碼的黃金時間還沒到呢」。

所以,論文提出了一個怎樣的新評量方法?
這個新方法叫做EvalPlus,是一個自動化程式碼評估框架。
具體來說,它會透過改進現有評估資料集的輸入多樣性和問題描述準確性,來將這些評估基準變得更嚴格。
一方面是輸入多樣性。 EvalPlus會先根據標準答案,用ChatGPT產生一些種子輸入範例(雖然要測ChatGPT的程式設計能力,但用它產生種子輸入似乎也不矛盾doge)
隨後,用EvalPlus改進這些種子輸入,將它們改得更難、更複雜、更刁鑽。
另一方面是問題描述準確性。 EvalPlus會將程式碼需求描述改得更精確,在約束輸入條件的同時,補充自然語言問題描述,以提高對模型輸出的精確度要求。
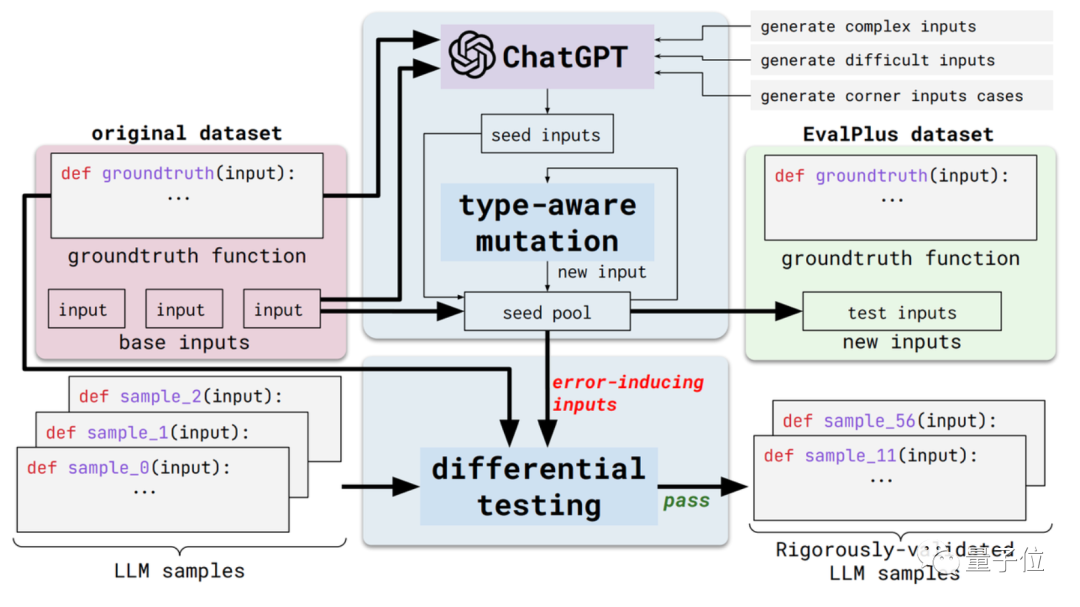
這裡,論文選擇了HUMANEVAL資料集作為示範。
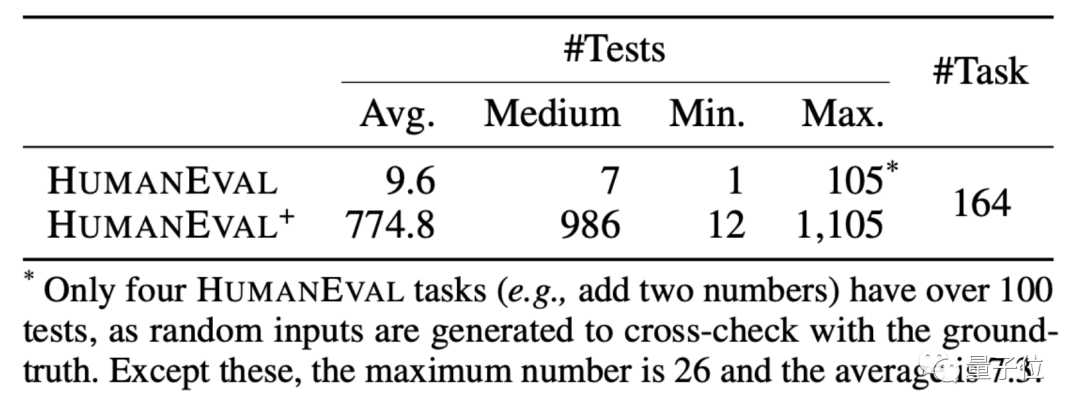
HUMANEVAL是OpenAI和Anthropic AI一起製作的程式碼資料集,包含164個原始程式設計題,涉及語言理解、演算法、數學和軟體面試幾種類型的題目。
EvalPlus會透過改進這類資料集的輸入類型和功能描述,讓程式設計問題看起來更清晰,同時用於測試的輸入更「刁鑽」或更困難。
以其中的一道求並集程式設計題為例,請AI寫一段程式碼,找出兩個資料列表中的共同元素,並給這些元素排序。
EvalPlus用它來測測ChatGPT寫的程式碼準確度。
在進行簡單輸入測試後,發現 ChatGPT 能夠輸出準確的答案。但如果換個輸入,就找出了ChatGPT版程式碼的bug:

#屬實是給AI們加大了考題難度。

基於這套方法,EvalPlus也做了一個改進版HUMANEVAL 資料集,增加輸入的同時,修正了一些HUMANEVAL裡面答案就有問題的程式題。
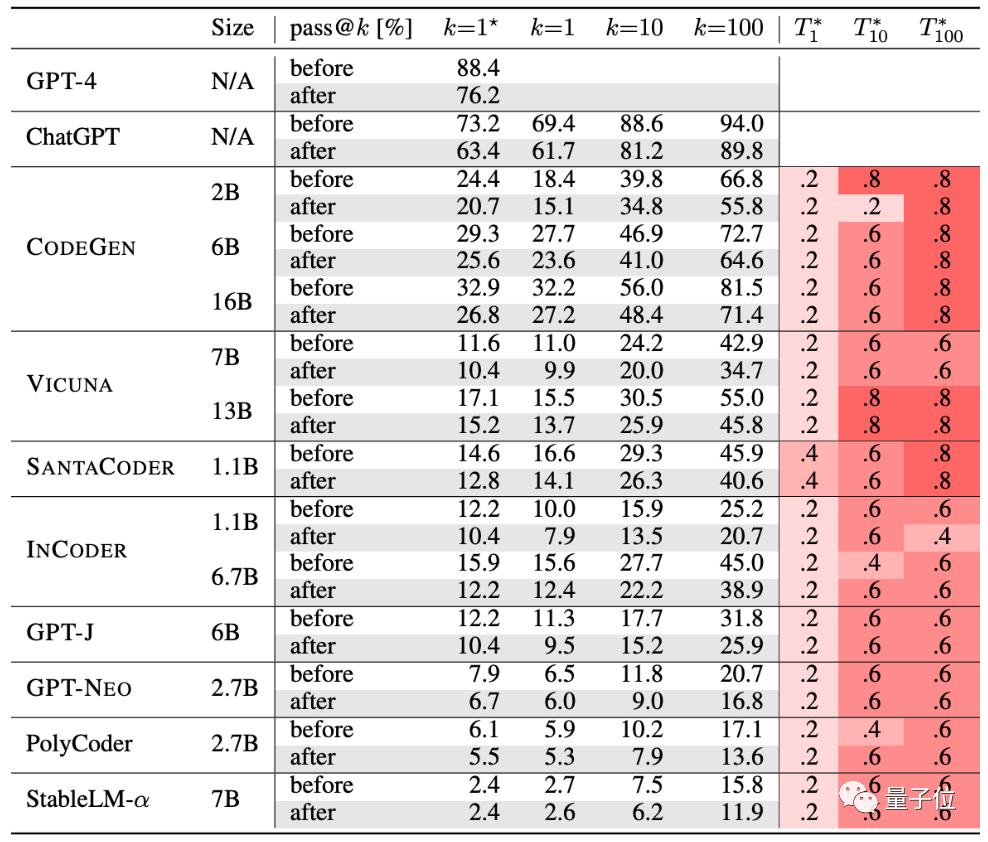
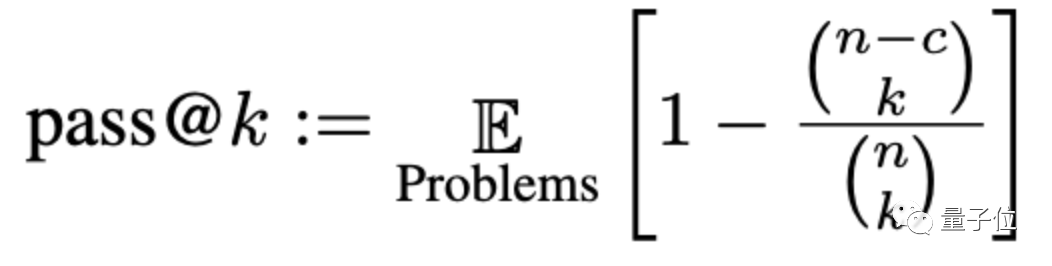
那麼,在這套「新考題」下,大語言模型們的準確率其實要打幾折?
作者們測試了目前比較受歡迎的10種程式碼產生AI。
GPT-4、ChatGPT、CODEGEN、VICUNA、SANTACODER、INCODER、GPT-J、GPT-NEO、PolyCoder、StableLM-α。
從表格中來看,經過嚴格測試後,這群AI的生成準確率都有所下降:
以上是ChatGPT編程準確率暴降13%! UIUC&南大新基準讓AI程式碼現原形了的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















