

深度學習架構的比較分析

深度學習的概念源自於人工神經網路的研究,含有多個隱藏層的多層感知器是一種深度學習結構。深度學習透過組合低層特徵形成更抽象的高層表示,以表徵資料的類別或特徵。它能夠發現資料的分佈式特徵表示。深度學習是機器學習的一種,而機器學習是實現人工智慧的必經之路。
那麼,各種深度學習的系統架構之間有哪些差異呢?
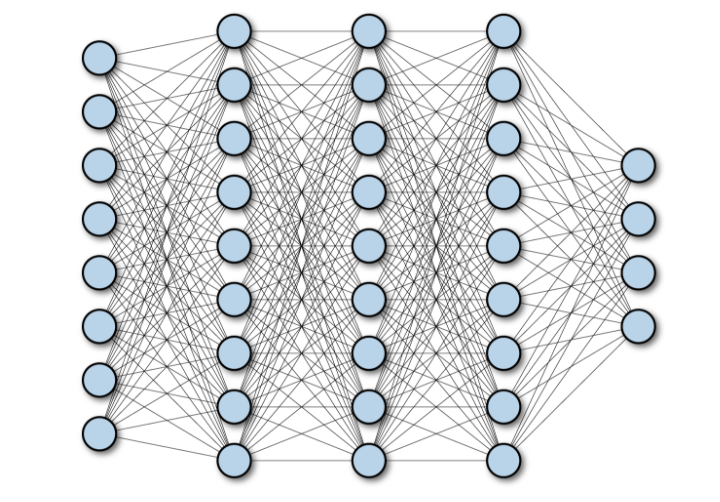
1. 全連接網路(FCN)
完全連接網路(FCN)由一系列完全連接的層組成,每個層中的每個神經元都連接到另一層中的每個神經元。其主要優點是“結構不可知”,即不需要對輸入做出特殊的假設。雖然這種結構不可知使得完全連接網絡非常廣泛適用,但是這樣的網絡傾向於比專門針對問題空間結構調整的特殊網絡表現更弱。
下圖顯示了一個多層深度的完全連接網路:
#2. 卷積神經網路(CNN)
卷積神經網路(CNN)是一種多層神經網路架構,主要用於影像處理應用。 CNN架構明確假定輸入具有空間維度(以及可選的深度維度),例如圖像,這允許將某些屬性編碼到模型架構中。 Yann LeCun創建了第一個CNN,該架構最初用於識別手寫字元。
2.1 CNN的架構特點
分解一下使用CNN的電腦視覺模型的技術細節:
- 模型的輸入:CNN模型的輸入通常是圖像或文字. CNN也可用於文本,但通常不怎麼使用。
圖像在這裡被表示為像素網格,就是由正整數組成的網格,每個數字都被分配一種顏色。
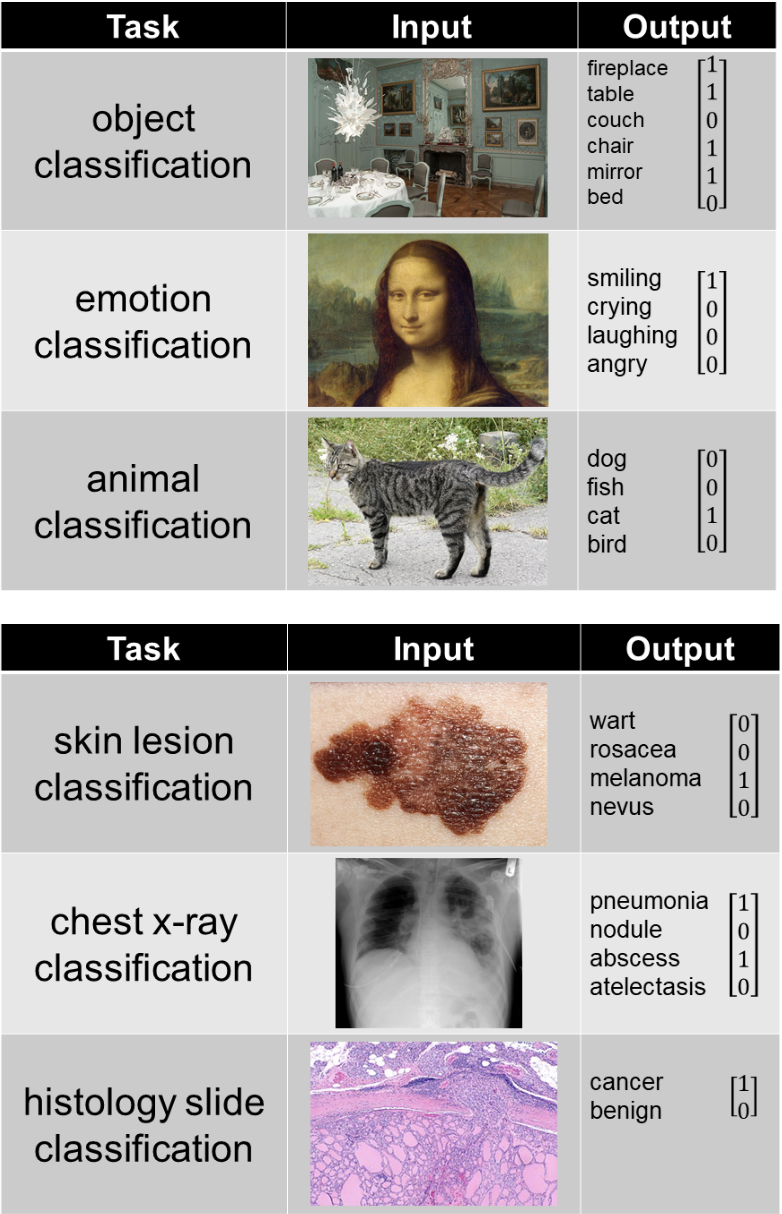
- 模型的輸出:模型的輸出取決於它試圖預測什麼,而下面的範例表示一些常見的任務:
-

一個簡單的捲積神經網路由一系列層構成,每一層透過可微分函數將一個活化的體積塊轉換為另一個表達。卷積神經網路的架構主要使用三種類型的層:卷積層、池化層和全連接層。下圖展示了卷積神經網路層的不同部分:
- #卷積: 卷積過濾器掃描影像,使用加法和乘法運算。 CNN試圖學習卷積濾波器中的值以預測所需的輸出。
- 非線性: 這是應用於卷積濾波器的方程,它允許CNN學習輸入和輸出影像之間的複雜關係。
- 池化: 也稱為“最大池化”,它只選擇一系列數字中的最大數字。這有助於減少表達的大小並減少CNN必須進行的計算量,用於提升效率。
這三種運算的結合組成了完全卷積網路。
2.2 CNN的用例
CNN(卷積神經網路)是一種常用於解決與空間資料相關的問題的神經網絡,通常用於影像(2D CNN)和音訊( 1D CNN)等領域。 CNN的廣泛應用包括人臉辨識、醫學分析和分類等。透過CNN,可以在影像或音訊資料中捕捉到更細緻的特徵,從而實現更精確的識別和分析。此外,CNN也可以應用於其他領域,如自然語言處理和時間序列資料等。總之,CNN是可以幫助我們更好地理解和分析各種類型的數據。
2.3 CNN對比FCN的優勢
參數共享/運算可行性:
#由於CNN使用參數共享,所以CNN與FCN架構的權重數量通常相差幾個數量級。
對於全連接神經網絡,有一個形狀為(Hin×Win×Cin)的輸入和一個形狀為(Hout×Wout×Cout)的輸出。這意味著輸出特徵的每個像素顏色都與輸入特徵的每個像素顏色連接。對於輸入影像和輸出影像的每個像素,都有一個獨立的可學習參數。因此,參數數為(Hin×Hout×Win×Wout×Cin×Cout)。
在卷积层中,输入是形状为(Hin,Win,Cin)的图像,权重考虑给定像素的邻域大小为K×K。输出是给定像素及其邻域的加权和。输入通道和输出通道的每个对(Cin,Cout)都有一个单独的内核,但内核的权重形状为(K,K,Cin,Cout)的张量与位置无关。实际上,该层可以接受任何分辨率的图像,而全连接层只能使用固定分辨率。最后,该层参数为(K,K,Cin,Cout),对于内核大小K远小于输入分辨率的情况,变量数量会显著减少。
自从AlexNet赢得ImageNet比赛以来,每个赢得比赛的神经网络都使用了CNN组件,这一事实证明CNN对于图像数据更有效。很可能找不到任何有意义的比较,因为仅使用FC层处理图像数据是不可行的,而CNN可以处理这些数据。为什么呢?
FC层中有1000个神经元的权重数量对于图像而言大约为1.5亿。 这仅仅是一个层的权重数量。 而现代的CNN体系结构具有50-100层,同时具有总共几十万个参数(例如,ResNet50具有23M个参数,Inception V3具有21M个参数)。
从数学角度来看,比较CNN和FCN(具有100个隐藏单元)之间的权重数量,输入图像为500×500×3的话:
- FC layer 的 Wx = 100×(500×500×3)=100×750000=75M
- CNN layer =
<code>((shape of width of the filter * shape of height of the filter * number of filters in the previous layer+1)*number of filters)( +1 是为了偏置) = (Fw×Fh×D+1)×F=(5×5×3+1)∗2=152</code>
平移不变性
不变性指的是一个对象即使位置发生了改变,仍然能够被正确地识别。这通常是一个积极的特性,因为它维护了对象的身份(或类别)。这里的“平移”是指在几何学中的特定含义。下图显示了相同的对象在不同的位置上,由于平移不变性,CNN能够正确地识别它们都是猫。
3. 循环神经网络(RNN)
RNN是构建其他深度学习架构的基础网络体系结构之一。一个关键的不同之处在于,与正常的前馈网络不同,RNN可以具有反馈到其先前或同一层的连接。从某种意义上说,RNN在先前的计算中具有“记忆”,并将这些信息用于当前处理。
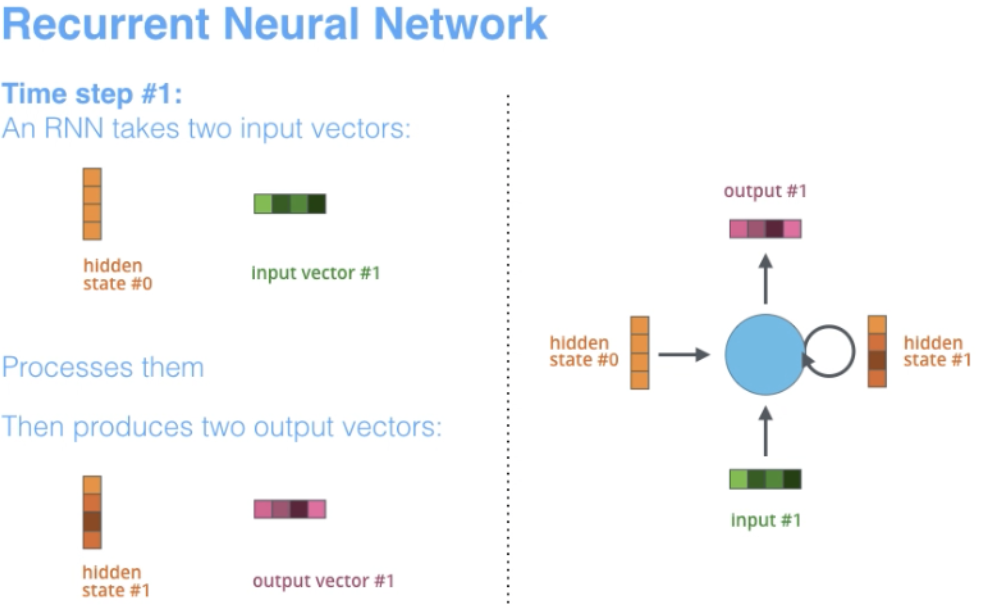
3.1 RNN 的架构特点
“Recurrent”这个术语适用于网络在每个序列实例上执行相同的任务,因此输出取决于先前的计算和结果。
RNN自然适用于许多NLP任务,如语言建模。它们能够捕捉“狗”和“热狗”之间的含义差异,因此RNN是为建模语言和类似序列建模任务中的这种上下文依赖而量身定制的,这成为在这些领域使用RNN而不是CNN的主要原因。RNN的另一个优点是模型大小不随输入大小而增加,因此有可能处理任意长度的输入。
此外,与CNN不同的是,RNN具有灵活的计算步骤,提供更好的建模能力,并创造了捕捉无限上下文的可能性,因为它考虑了历史信息,并且其权重在时间上是共享的。然而,循环神经网络会面临梯度消失问题。梯度变得很小,因此使得反向传播的更新权重非常小。由于每个标记需要顺序处理以及存在梯度消失/爆炸,RNN训练速度慢并且有时很难收敛。
下图斯坦福大学是RNN架构示例。
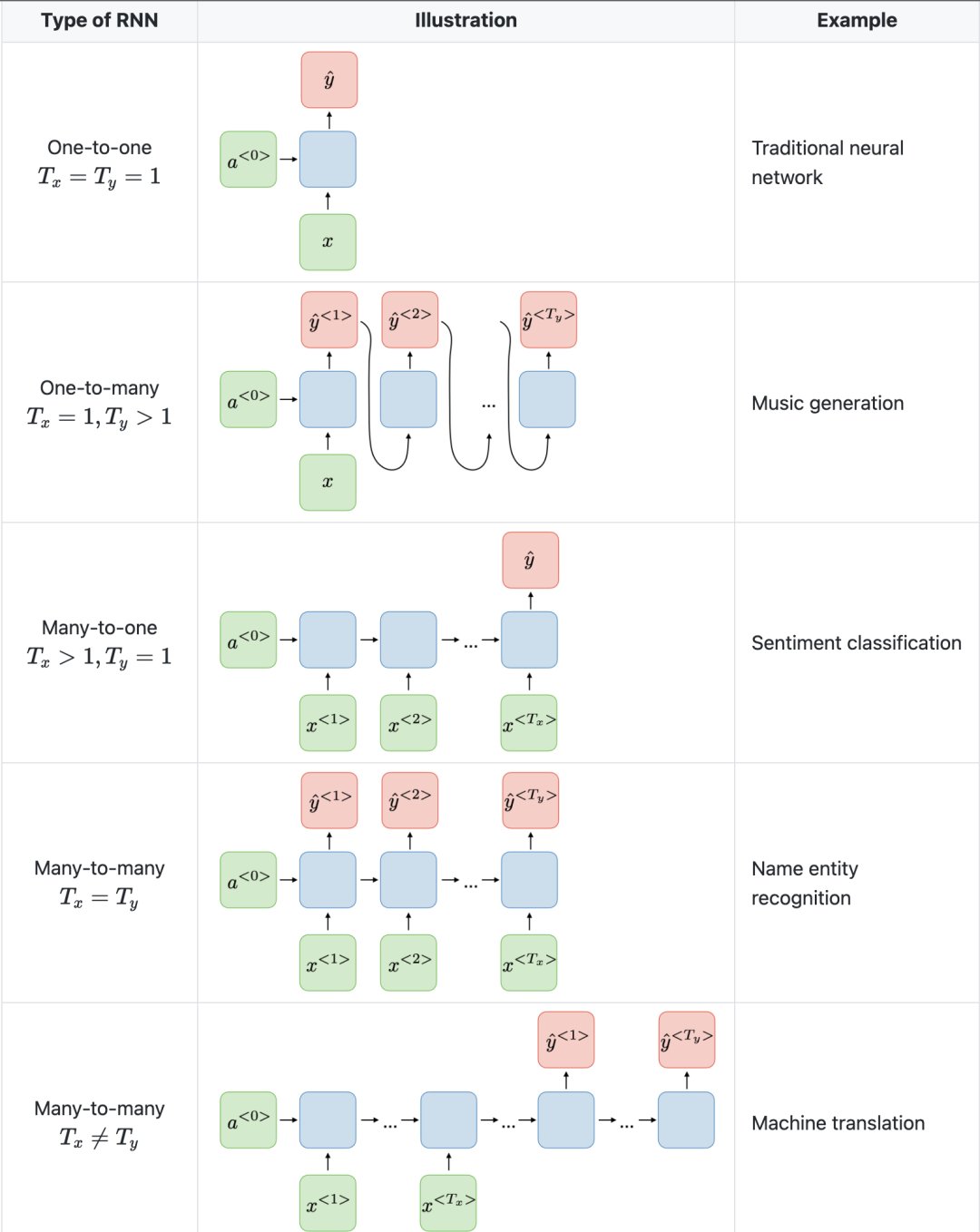
另一个需要注意的是,CNN与RNN具有不同的架构。CNN是一种前馈神经网络,它使用过滤器和池化层,而RNN则通过自回归的方式将结果反馈到网络中。
3.2 RNN的典型用例
RNN是一种专门用于分析时间序列数据的神经网络。其中,时间序列数据是指按时间顺序排列的数据,例如文本或视频。RNN在文本翻译、自然语言处理、情感分析和语音分析等方面具有广泛的应用。例如,它可以用于分析音频记录,以便识别说话人的语音并将其转换为文本。另外,RNN还可以用于文本生成,例如为电子邮件或社交媒体发布创建文本。
3.3 RNN 與CNN 的比較優勢
在CNN中,輸入和輸出的大小是固定的。這意味著CNN接收固定大小的圖像,並將其輸出到適當的級別,同時伴隨其預測的置信度。然而,在RNN中,輸入和輸出的大小可能會有所變化。這個特性適用於需要可變大小輸入和輸出的應用,例如生成文字。
門控循環單元(GRU)和長短時記憶單元(LSTM)都提供了解決循環神經網路(RNN)遇到的梯度消失問題的解決方案。
4. 長短記憶神經網路(LSTM)
長短記憶神經網路(LSTM)是一種特殊的RNN。它透過學習長期依賴關係,使RNN更容易在許多時間戳上保留資訊。下圖是LSTM架構的可視化表示。
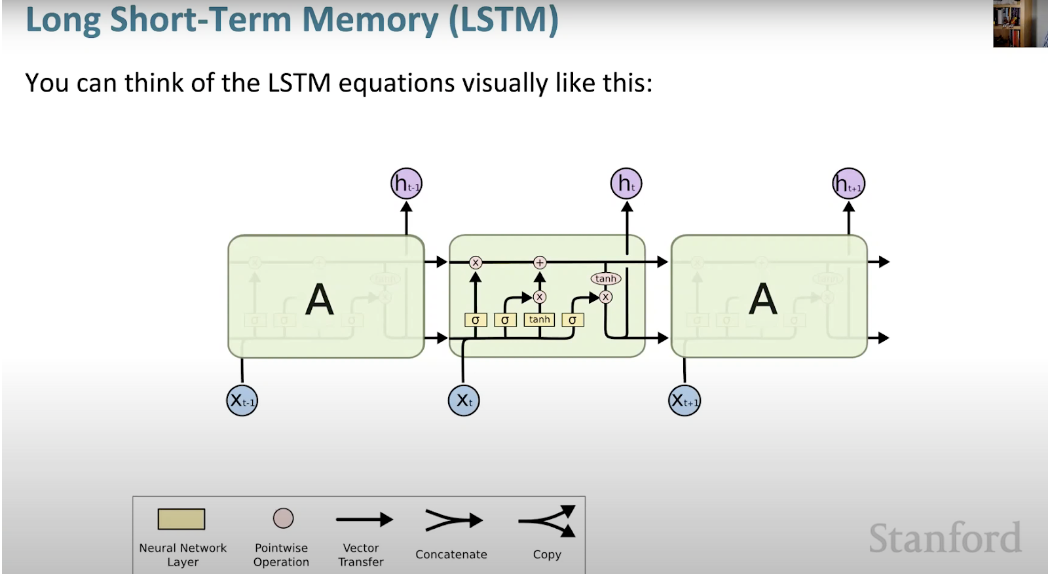
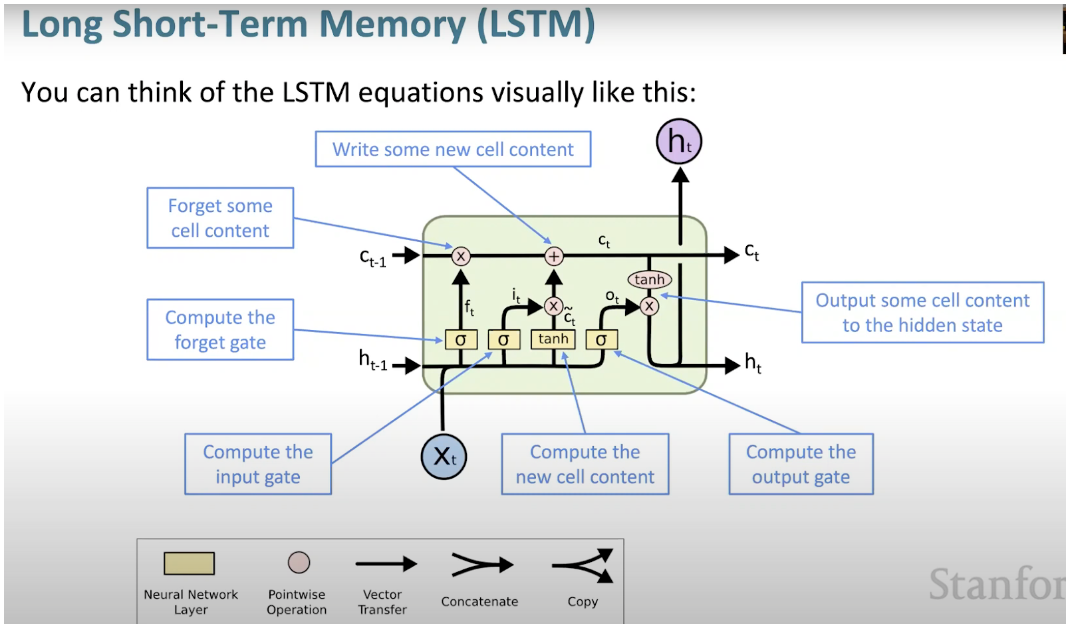
#LSTM無所不在,可以在許多應用程式或產品中找到,例如智慧型手機。其強大之處在於它擺脫了典型的基於神經元的架構,而是採用了記憶單元的概念。這個記憶單元根據其輸入的函數保留其值,可以短時間或長時間保持其值。這允許單元記住重要的內容,而不僅僅是最後計算的值。
LSTM 記憶單元包含三個門,控制其單元內的訊息流入或流出。
- 輸入閘門:控制何時可以將資訊流入記憶體。
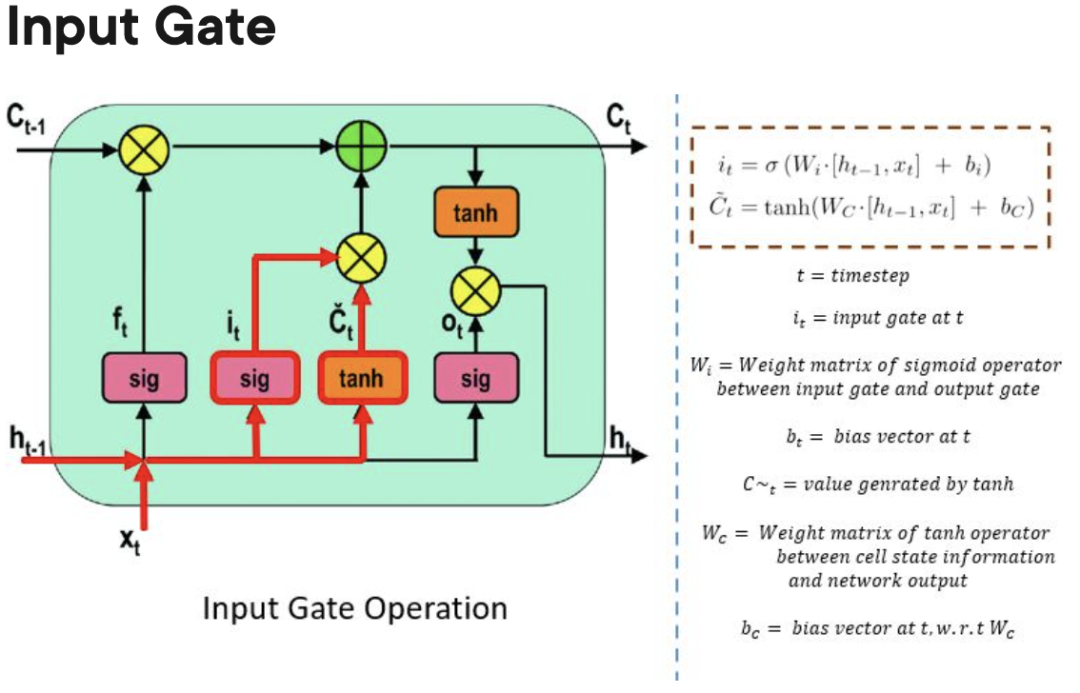
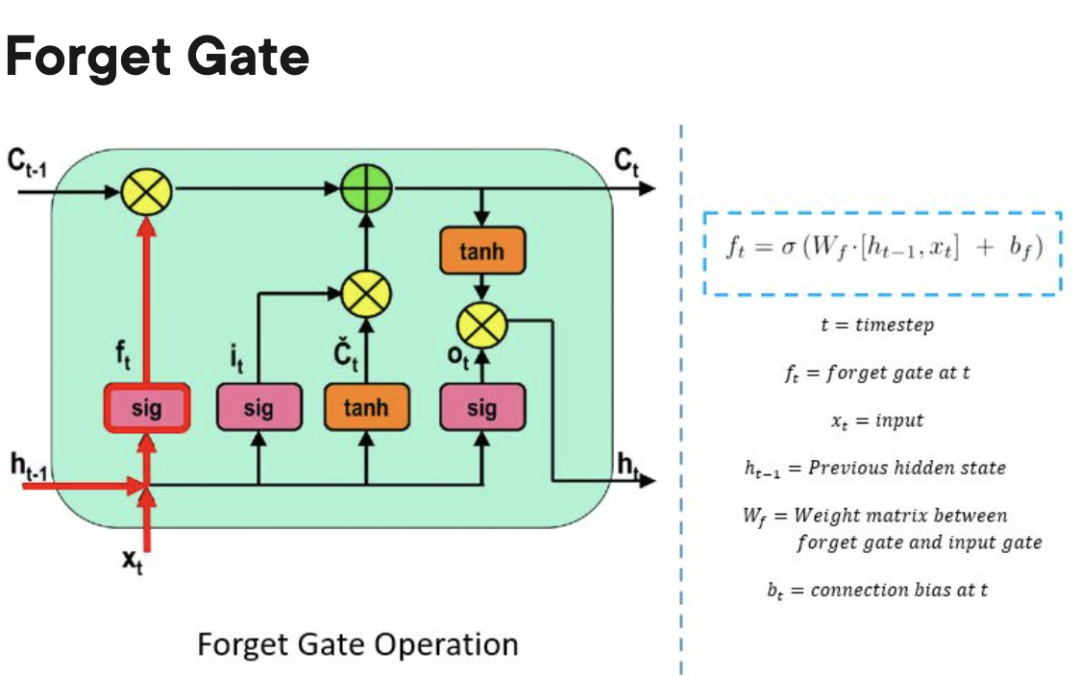
忘記門:負責追蹤哪些資訊可以“遺忘”,為處理單元騰出空間記住新資料。
輸出閘門:決定處理單元內儲存的資訊何時可以用作細胞的輸出。
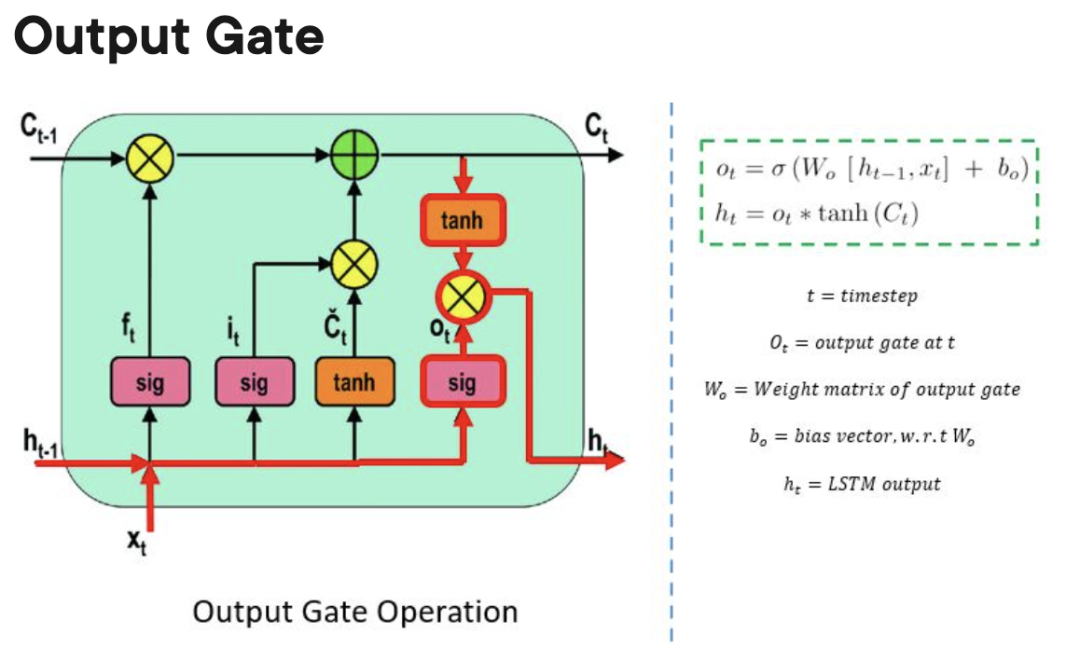
LSTM對比於GRU和RNN的優缺點
相較於GRU和尤其是RNN,LSTM可以學習到更長期的依賴關係。由於有三個閘門(GRU中為兩個,RNN中為零),因此與RNN和GRU相比,LSTM有較多的參數。這些額外的參數允許LSTM模型更好地處理複雜的序列數據,如自然語言或時間序列數據。此外,LSTM還可以處理變長的輸入序列,因為它們的閘門結構允許它們忽略不必要的輸入。因此,LSTM在許多應用中都表現出色,包括語音辨識、機器翻譯和股票市場預測等。
5. 閘控循環單元(GRU)
GRU有兩個閘門:更新閘和重置閘門(本質上是兩個向量),以決定應該傳遞什麼訊息到輸出。
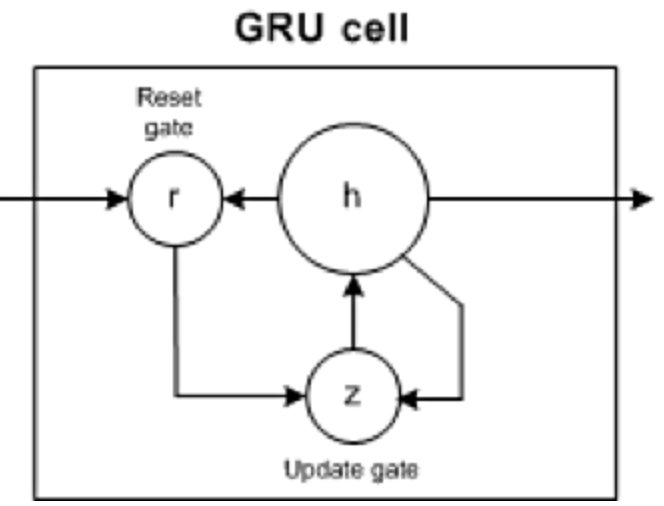
- 重設閘門(Reset gate): 幫助模型決定可以忘記多少過去的資訊。
- 更新閘門(Update gate): 幫助模型確定過去資訊(先前的時間步驟)中有多少需要傳遞到未來。
GRU對比LSTM 和RNN的優缺點
與RNN類似,GRU也是一種遞歸神經網絡,它可以有效地長時間保留資訊並捕捉比RNN更長的依賴關係。然而,GRU相比較於LSTM更為簡單,訓練速度更快。
儘管GRU在實作上比RNN更為複雜,但由於其僅包含兩個門控機制,因此其參數數量較少,通常無法像LSTM那樣捕捉更長範圍的依賴關係。因此,GRU在某些情況下可能需要更多的訓練資料以達到與LSTM相同的表現水準。
此外,由於GRU相對較為簡單,其運算成本也較低,因此在資源有限的環境下,如行動裝置或嵌入式系統,使用GRU可能更為合適。另一方面,如果模型的準確性對應用至關重要,則LSTM可能是更好的選擇。
6.Transformer
有關 Transformers 的論文 「Attention is All You Need」 幾乎是 Arxiv 上有史以來排名第一的論文。變形金剛是一種大型編碼器-解碼器模型,能夠使用複雜的注意力機制來處理整個序列。
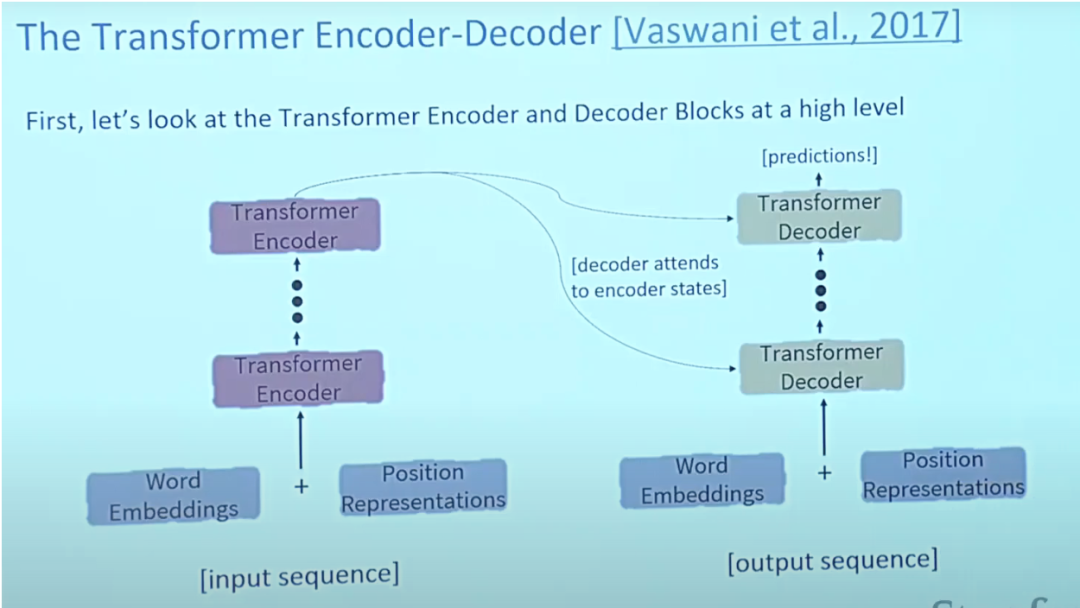
通常,在自然語言處理應用中,首先使用嵌入演算法將每個輸入單字轉換為向量。嵌入只在最底層的編碼器中發生。所有編碼器共享的抽像是,它們接收一個大小為512的向量列表,這將是詞嵌入,但在其他編碼器中,它將是直接位於下面的編碼器輸出中。
注意提供了解決瓶頸問題的方法。對於這些類型的模型,上下文向量成為了一個瓶頸,這使得模型難以處理長句子。注意力允許模型根據需要集中關注輸入序列的相關部分,並將每個單字的表示視為一個查詢,以存取和合併一組值中的資訊。
6.1 Transformer的架構特點
通常,在Transformer架構中,編碼器能夠將所有隱藏狀態傳遞給解碼器。但是,在產生輸出之前,解碼器使用注意力進行了額外的步驟。解碼器透過其softmax得分乘以每個隱藏狀態,從而放大得分更高的隱藏狀態並淹沒其他隱藏狀態。這使得模型能夠集中關注與輸出相關的輸入部分。
自我專注位於編碼器中,第一步是從每個編碼器輸入向量(每個單字的嵌入)建立3個向量:Key、Query和Value向量,這些向量是透過將嵌入乘以在訓練過程中訓練的3個矩陣來建立的。 K、V、Q維度為64,而嵌入和編碼器輸入/輸出向量的維度為512。下圖來自Jay Alammar的 Illustrated Transformer,這可能是網路上最好的視覺化解讀。
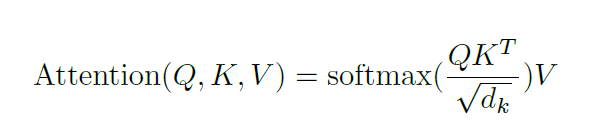
這個清單的大小是可以設定的超參數,基本上將是訓練資料集中最長句子的長度。
- 注意:
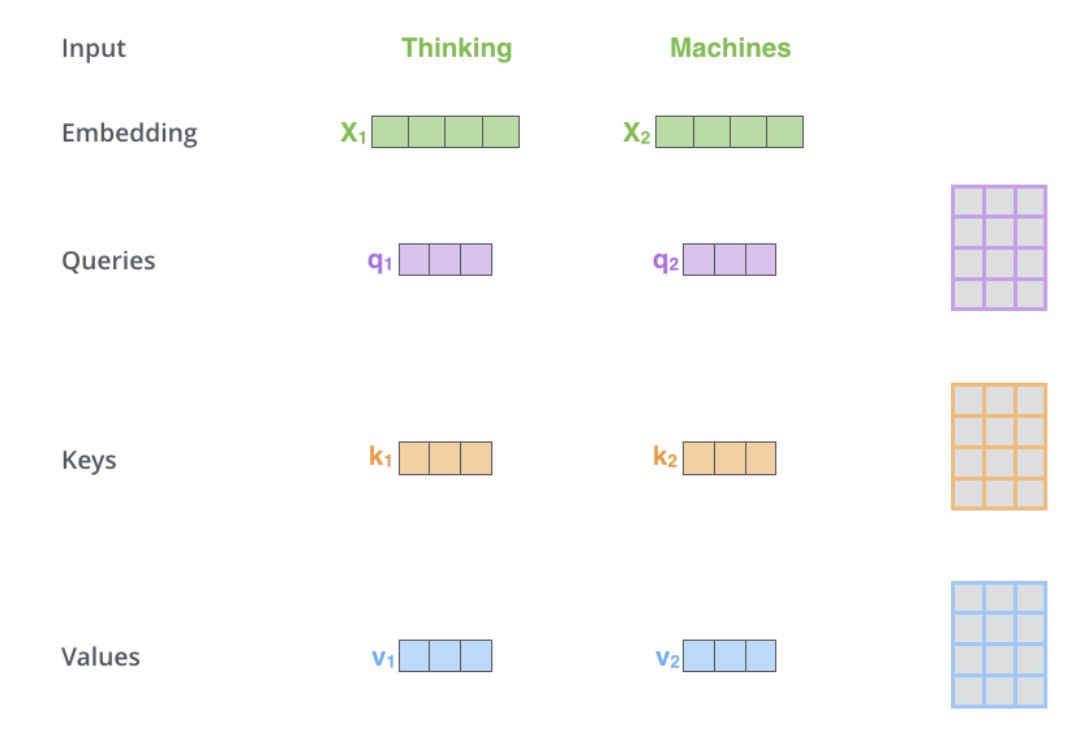
#什麼是query、key和value向量?它們是在計算和思考注意力時有用的抽象概念。在解碼器中的交叉注意力除了輸入之外,計算與自註意力的計算相同。交叉注意力不對稱地組合了兩個維度相同的獨立嵌入序列,而自註意力的輸入是單獨的嵌入序列。
為了討論Transformer,還必須討論兩個預訓練模型,即BERT和GPT,因為它們導致了Transformer的成功。
GPT 的預訓練解碼器有12層,其中包含768維隱藏狀態,3072維前饋隱藏層,採用40,000個合併的位元組對編碼。主要應用在自然語言的推理中,將句子對標示為蘊含、矛盾或中性。
BERT是預訓練編碼器,使用掩碼語言建模,將輸入中的一部分單字替換為特殊的[MASK]標記,然後嘗試預測這些單字。因此,只需要在預測的掩碼單字上計算損失。兩種BERT模型大小都有大量的編碼器層(論文稱為Transformer塊)-Base版本有12個,Large版本有24個。這些也具有比初始論文中Transformer參考實作中的預設配置(6個編碼器層,512個隱藏單元和8個注意頭)更大的前饋網路(分別為768和1024個隱藏單元)和更多的注意頭(分別為12和16)。 BERT模型很容易進行微調,通常可以在單一GPU上完成。 BERT可以用在NLP中翻譯,特別是低資源語言翻譯。
Transformer的一個效能缺點是,它們在自我關注方面的計算時間是二次的,而RNN只是線性成長。
6.2 Transformer的用例
6.2.1 語言領域
在傳統的語言模型中,相鄰的單字會先被分組在一起,而Transformer則能夠並行處理,使得輸入資料中的每個元素都能夠連接或關注每個其他元素。這被稱為「自我注意力」。這意味著Transformer一開始訓練時就可以看到整個資料集的內容。
在Transformer出現之前,AI語言任務的進展在很大程度上落後於其他領域的發展。實際上,在過去的10年左右的深度學習革命中,自然語言處理是後來者,而NLP在某種程度上落後於電腦視覺。然而,隨著Transformers的出現,NLP領域得到了極大的推動,並且推出了一系列在各種NLP任務中取得佳績的模型。
例如,為了理解基於傳統語言模型(基於遞歸架構,如RNN、LSTM或GRU)與Transformer之間的區別,我們可以舉個例子:「The owl spied a squirrel. It tried to grab it with its talons but only got the end of its tail.」第二句的結構很令人困惑:那個「it」是指什麼?僅專注於「it」周圍單字的傳統語言模型會遇到困難,但是將每個單字與每個其他單字相連的Transformer可以分辨出貓頭鷹抓住了松鼠,而鬆鼠失去了部分尾巴。
6.2.2 視覺領域
在CNN中,我們從局部開始,逐漸獲得全局視角。 CNN透過從局部到全局的方式建構特徵,逐像素識別影像,以識別例如角落或線條等特徵。然而,在transformer中,透過自我注意力,即使在資訊處理的第一層上,也會建立遠端影像位置之間的連接(就像語言一樣)。如果CNN的方法就像從單一像素開始縮放,那麼transformer會逐漸將整個模糊的影像聚焦。

CNN透過重複應用輸入資料的局部補丁上的濾鏡,產生局部特徵表示,並逐步增加它們的感受視野並建立全局特徵表示。正是因為卷積,照片應用程式才能將梨子與雲彩區分開來。在transformer架構之前,CNN被認為是視覺任務不可或缺的。
Vision Transformer模型的架構與2017年提出的第一個transformer幾乎相同,只有一些微小的變化使其能夠分析圖像而不是單字。由於語言往往是離散的,因此需要將輸入影像離散化,以使transformer能夠處理視覺輸入。在每個像素上完全模仿語言方法並執行自我關注將計算時間變得極為昂貴。因此,ViT將更大的圖像分成方形單元或補丁(類似於NLP中的令牌)。大小是任意的,因為根據原始影像的分辨率,token可以變大或變小(預設為16x16像素)。但是透過處理組中的像素並對每個像素應用自我注意力,ViT可以快速處理巨大的訓練資料集,輸出越來越準確的分類。
6.2.3 多模態任務
與Transformer 相比,其他深度學習架構只會一種技巧,而多模態學習需要在一個流暢的架構中處理具有不同模式的模態,並具有相當高的關係歸納偏差,才能達到人類智能的水平。換句話說,需要一個單一多用途的架構,可以無縫地在閱讀/觀看、說話和聆聽等感官之間轉換。
對於多模態任務,需要同時處理多種類型的數據,如原始圖像、視訊和語言等,而 Transformer 提供了通用架構的潛力。
由於早期架構中採用的分立方法,每種類型的資料都有自己特定的模型,因此這是一項難以完成的任務。然而,Transformer 提供了一種簡單的方法來組合多個輸入來源。例如,多模態網路可以為系統提供動力,讀取人的嘴唇動作並同時使用語言和圖像資訊的豐富表示來監聽他們的聲音。透過交叉注意力,Transformer 能夠從不同來源衍生查詢、鍵和值向量,成為多模態學習的強大工具。
因此,Transformer 是實現神經網路架構「融合」的一大步,從而可以幫助實現對多種模態資料的通用處理。
6.3 Transformer對比RNN/GRU/LSTM的優缺點
與RNN/GRU/LSTM相比,Transformer可以學習比RNN和其變體(如GRU和LSTM)更長的依賴關係。
然而,最大的好處來自於Transformer如何適用於並行化。與在每個時間步驟處理一個單字的RNN不同,Transformer的一個關鍵屬性是每個位置上的單字都通過自己的路徑流經編碼器。在自我注意力層中,由於自我注意層計算每個輸入序列中的其他單字對該單字的重要性,這些路徑之間存在依賴關係。但是,一旦產生了自我注意力輸出,前饋層就沒有這些依賴關係,因此各個路徑可以在通過前饋層時並行執行。這在Transformer編碼器的情況下是一個特別有用的特性,它可以在自我注意力層後與其他單字並行處理每個輸入單字。然而,這個特性對於解碼器並不是非常重要,因為它一次只產生一個單詞,不使用平行單字路徑。
Transformer架構的運行時間與輸入序列的長度呈二次方關係,這表示當處理長文件或將字元作為輸入時,處理速度可能會很慢。換句話說,在進行自我注意力形成期間,需要計算所有交互對,這意味著計算隨著序列長度呈二次增長,即O(T^2 d),其中T序列長度,D是維度。例如,對應一個簡單的句子d=1000,T≤30⇒T^2≤900⇒T^2d≈900K。而對於循環神經,它僅以線性方式成長。
如果Transformer不需要在句子中的每一對單字之間計算成對的交互作用,那不是很好?有研究表明可以在不計算所有單字對之間的交互作用(例如透過近似成對關注)的情況下實現相當高的表現水準。
與CNN相比,Transformer的資料需求極高。 CNN仍然具有樣本效率,這使它們成為低資源任務的絕佳選擇。這對於圖像/視訊生成任務尤其如此,即使對於CNN架構,需要大量資料(因此暗示Transformer架構需要極高的資料需求)。例如,Radford等人最近提出的CLIP架構是使用基於CNN的ResNets作為視覺骨幹進行訓練的(而不是類似ViT的Transformer架構)。雖然Transformer在滿足其數據需求後提供了準確性提升,但CNN則提供了一種在可用數據量不是異常高的任務中提供良好準確性表現的方式。因此,兩種架構都有其用途。
由於Transformer 架構的運行時間與輸入序列的長度呈現二次方關係。也就是說,在所有單字對上計算注意力需要圖中邊的數量隨節點數呈二次方增長,即在一個 n 個單字的句子中,Transformer 需要計算 n^2 個單字對。這意味著參數數量龐大(即記憶體佔用高),導致計算複雜度高。高運算需求對電源和電池壽命都會產生負面影響,特別是對於可移動裝置而言。總體而言,為了提供更好的效能(例如準確性),Transformer需要更高的運算能力、更多的資料、電源/電池壽命和記憶體佔用。
7. 推理偏差
實踐中使用的每個機器學習演算法,從最近鄰到梯度提升,都帶有自己關於哪些分類更容易學習的歸納偏差。幾乎所有學習演算法都有一個偏差,即學習那些相似的項(在某些特徵空間中「接近」彼此)更可能屬於同一類。線性模型,例如邏輯迴歸,也假設類別可以透過線性邊界分離,這是一個「硬」偏差,因為模型無法學習其他內容。即便對於正則化回歸,這幾乎是機器學習中經常使用的類型,也存在一種偏差,即傾向於學習涉及少數特徵,具有低特徵權重的邊界,這是「軟」偏差,因為模型可以學習涉及許多具有高權重功能的類別邊界,但這更困難/需要更多資料。
即使是深度學習模型也同樣具有推理偏差,例如,LSTM神經網路對自然語言處理任務非常有效,因為它偏向於在長序列上保留上下文資訊。

了解領域知識和問題難度可以幫助我們選擇適當的演算法應用。例如,從臨床記錄中提取相關術語以確定患者是否被診斷為癌症的問題。在這種情況下,邏輯迴歸表現良好,因為有許多獨立有資訊量的術語。對於其他問題,例如從複雜的PDF報告中提取遺傳測試的結果,使用LSTM可以更好地處理每個單字的長程上下文,從而獲得更好的效能。一旦選擇了基礎演算法,了解其偏差也可以幫助我們執行特徵工程,即選擇要輸入到學習演算法中的資訊的過程。
每個模型結構都有一種內在的推理偏差,幫助理解資料中的模式,從而實現學習。例如,CNN表現出空間參數共享、平移/空間不變性,而RNN則表現出時間參數共享。
8. 小結
老碼農嘗試比較分析了深度學習架構中的Transformer、CNN、RNN/GRU/LSTM,理解到Transformer可以學習更長的依賴關係,但需要更高的數據需求和計算能力;Transformer適用於多模態任務,可以無縫地在閱讀/觀看、說話和聽取等感官之間轉換;每個模型結構都有一種內在的推理偏差,幫助理解數據中的模式,從而實現學習。
【參考資料】
- CNN vs fully connected network for image recognition?,https://stats.stackexchange.com/questions/341863/cnn-vs-fully-connected -network-for-image-recognition
- https://web.stanford.edu/class/archive/cs/cs224n/cs224n.1184/lectures/lecture12.pdf
- #Introduction to LSTM Units in RNN,https://www.pluralsight.com/guides/introduction-to-lstm-units-in-rnn
- Learning Transferable Visual Models From Natural Language Supervision,https://arxiv.org/ abs/2103.00020
- Linformer: Self-Attention with Linear Complexity,https://arxiv.org/abs/2006.04768
- Rethinking Attention with Performers,https://arxiv.org/abs/ Rethinking Attention with Performers,https://arxiv.org/abs/
- Rethinking Attention with Performers,https://arxiv.org/abs/ Rethinking Attention with Performers,https://arxiv.org/abs/
- Rethinking Attention with Performers,https://arxiv.org/abs/ Rethinking Attention with Performers,https://arxiv.org/abs/
- 」 2009.14794
- Big Bird: Transformers for Longer Sequences,https://arxiv.org/abs/2007.14062
以上是深度學習架構的比較分析的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 開源!超越ZoeDepth! DepthFM:快速且精確的單目深度估計!
Apr 03, 2024 pm 12:04 PM
開源!超越ZoeDepth! DepthFM:快速且精確的單目深度估計!
Apr 03, 2024 pm 12:04 PM
0.這篇文章乾了啥?提出了DepthFM:一個多功能且快速的最先進的生成式單目深度估計模型。除了傳統的深度估計任務外,DepthFM還展示了在深度修復等下游任務中的最先進能力。 DepthFM效率高,可以在少數推理步驟內合成深度圖。以下一起來閱讀這項工作~1.論文資訊標題:DepthFM:FastMonocularDepthEstimationwithFlowMatching作者:MingGui,JohannesS.Fischer,UlrichPrestel,PingchuanMa,Dmytr
 使用ddrescue在Linux上恢復數據
Mar 20, 2024 pm 01:37 PM
使用ddrescue在Linux上恢復數據
Mar 20, 2024 pm 01:37 PM
DDREASE是一種用於從檔案或區塊裝置(如硬碟、SSD、RAM磁碟、CD、DVD和USB儲存裝置)復原資料的工具。它將資料從一個區塊設備複製到另一個區塊設備,留下損壞的資料區塊,只移動好的資料區塊。 ddreasue是一種強大的恢復工具,完全自動化,因為它在恢復操作期間不需要任何干擾。此外,由於有了ddasue地圖文件,它可以隨時停止和恢復。 DDREASE的其他主要功能如下:它不會覆寫恢復的數據,但會在迭代恢復的情況下填補空白。但是,如果指示工具明確執行此操作,則可以將其截斷。將資料從多個檔案或區塊還原到單
 Google狂喜:JAX性能超越Pytorch、TensorFlow!或成GPU推理訓練最快選擇
Apr 01, 2024 pm 07:46 PM
Google狂喜:JAX性能超越Pytorch、TensorFlow!或成GPU推理訓練最快選擇
Apr 01, 2024 pm 07:46 PM
谷歌力推的JAX在最近的基準測試中表現已經超過Pytorch和TensorFlow,7項指標排名第一。而且測試並不是JAX性能表現最好的TPU上完成的。雖然現在在開發者中,Pytorch依然比Tensorflow更受歡迎。但未來,也許有更多的大型模型會基於JAX平台進行訓練和運行。模型最近,Keras團隊為三個後端(TensorFlow、JAX、PyTorch)與原生PyTorch實作以及搭配TensorFlow的Keras2進行了基準測試。首先,他們為生成式和非生成式人工智慧任務選擇了一組主流
 超越ORB-SLAM3! SL-SLAM:低光、嚴重抖動和弱紋理場景全搞定
May 30, 2024 am 09:35 AM
超越ORB-SLAM3! SL-SLAM:低光、嚴重抖動和弱紋理場景全搞定
May 30, 2024 am 09:35 AM
寫在前面今天我們探討下深度學習技術如何改善在複雜環境中基於視覺的SLAM(同時定位與地圖建構)表現。透過將深度特徵提取和深度匹配方法相結合,這裡介紹了一種多功能的混合視覺SLAM系統,旨在提高在諸如低光條件、動態光照、弱紋理區域和嚴重抖動等挑戰性場景中的適應性。我們的系統支援多種模式,包括拓展單目、立體、單目-慣性以及立體-慣性配置。除此之外,也分析如何將視覺SLAM與深度學習方法結合,以啟發其他研究。透過在公共資料集和自採樣資料上的廣泛實驗,展示了SL-SLAM在定位精度和追蹤魯棒性方面優
 iPhone上的蜂窩數據網路速度慢:修復
May 03, 2024 pm 09:01 PM
iPhone上的蜂窩數據網路速度慢:修復
May 03, 2024 pm 09:01 PM
在iPhone上面臨滯後,緩慢的行動數據連線?通常,手機上蜂窩互聯網的強度取決於幾個因素,例如區域、蜂窩網絡類型、漫遊類型等。您可以採取一些措施來獲得更快、更可靠的蜂窩網路連線。修復1–強制重啟iPhone有時,強制重啟設備只會重置許多內容,包括蜂窩網路連線。步驟1–只需按一次音量調高鍵並放開即可。接下來,按降低音量鍵並再次釋放它。步驟2–過程的下一部分是按住右側的按鈕。讓iPhone完成重啟。啟用蜂窩數據並檢查網路速度。再次檢查修復2–更改資料模式雖然5G提供了更好的網路速度,但在訊號較弱
 特斯拉機器人進廠打工,馬斯克:手的自由度今年將達到22個!
May 06, 2024 pm 04:13 PM
特斯拉機器人進廠打工,馬斯克:手的自由度今年將達到22個!
May 06, 2024 pm 04:13 PM
特斯拉機器人Optimus最新影片出爐,已經可以在工廠裡打工了。正常速度下,它分揀電池(特斯拉的4680電池)是這樣的:官方還放出了20倍速下的樣子——在小小的「工位」上,揀啊揀啊揀:這次放出的影片亮點之一在於Optimus在廠子裡完成這項工作,是完全自主的,全程沒有人為的干預。而且在Optimus的視角之下,它還可以把放歪了的電池重新撿起來放置,主打一個自動糾錯:對於Optimus的手,英偉達科學家JimFan給出了高度的評價:Optimus的手是全球五指機器人裡最靈巧的之一。它的手不僅有觸覺
 阿里7B多模態文件理解大模型拿下新SOTA
Apr 02, 2024 am 11:31 AM
阿里7B多模態文件理解大模型拿下新SOTA
Apr 02, 2024 am 11:31 AM
多模態文件理解能力新SOTA!阿里mPLUG團隊發布最新開源工作mPLUG-DocOwl1.5,針對高解析度圖片文字辨識、通用文件結構理解、指令遵循、外部知識引入四大挑戰,提出了一系列解決方案。話不多說,先來看效果。複雜結構的圖表一鍵識別轉換為Markdown格式:不同樣式的圖表都可以:更細節的文字識別和定位也能輕鬆搞定:還能對文檔理解給出詳細解釋:要知道,“文檔理解”目前是大語言模型實現落地的一個重要場景,市面上有許多輔助文檔閱讀的產品,有的主要透過OCR系統進行文字識別,配合LLM進行文字理
 超級智能體生命力覺醒!可自我更新的AI來了,媽媽再也不用擔心資料瓶頸難題
Apr 29, 2024 pm 06:55 PM
超級智能體生命力覺醒!可自我更新的AI來了,媽媽再也不用擔心資料瓶頸難題
Apr 29, 2024 pm 06:55 PM
哭死啊,全球狂煉大模型,一網路的資料不夠用,根本不夠用。訓練模型搞得跟《飢餓遊戲》似的,全球AI研究者,都在苦惱怎麼才能餵飽這群資料大胃王。尤其在多模態任務中,這問題尤其突出。一籌莫展之際,來自人大系的初創團隊,用自家的新模型,率先在國內把「模型生成數據自己餵自己」變成了現實。而且還是理解側和生成側雙管齊下,兩側都能產生高品質、多模態的新數據,對模型本身進行數據反哺。模型是啥?中關村論壇上剛露面的多模態大模型Awaker1.0。團隊是誰?智子引擎。由人大高瓴人工智慧學院博士生高一鑷創立,高
