

GPT-4拿下最難數學推理資料集新SOTA,新型Prompting讓大模型推理能力狂升

近期,華為聯和港中文發表論文《Progressive-Hint Prompting Improves Reasoning in Large Language Models》,提出 Progressive-Hint Prompting (PHP),用來模擬人類做題過程。在 PHP 框架下,Large Language Model (LLM) 能夠利用前幾次產生的推理答案作為之後推理的提示,逐步靠近最終的正確答案。要使用 PHP,只需要滿足兩個要求: 1) 問題能夠和推理答案進行合併,形成新的問題;2) 模型可以處理這個新的問題,給出新的推理答案。
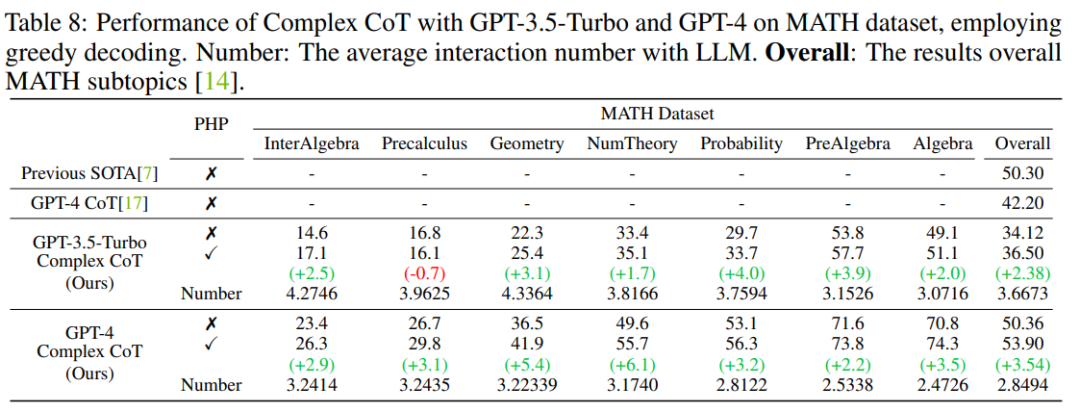
結果表明,GP-T-4 PHP 在多個資料集上取得了SOTA 結果,包括SVAMP ( 91.9%), AQuA (79.9%), GSM8K (95.5%) 以及MATH (53.9%)。此方法大幅超過 GPT-4 CoT。例如,在現在最難的數學推理資料集MATH 上,GPT-4 CoT 只有42.5%,而GPT-4 PHP 在MATH 資料集的Nember Theory (數論) 子集提升6.1%, 將MATH 整體提升到53.9% ,達到SOTA。

- #論文連結:https://arxiv .org/abs/2304.09797
- #程式碼連結:https://github.com/chuanyang-Zheng/Progressive-Hint
#介紹
隨著LLM 的發展,湧現了關於prompting 的一些工作,其中有兩個主流方向:
- 一個以Chain-Of-Thought( CoT,思考鏈) 為代表,透過清楚得寫下推理過程,激發模型的推理能力;
- 另一個以Self- Consistency (SC) 為代表,透過取樣多個答案,然後進行投票得到最終答案。
顯然,現存的兩種方法,沒有對問題進行任何的修改,相當於做了一遍題目之後就結束了,而沒有反過來帶著答案進行再次檢查。 PHP 嘗試模擬更類人推理過程:對上次的推理過程進行處理,然後合併到初始的問題當中,詢問 LLM 進行再次推理。當最近兩次推理答案一致時,得到的答案是準確的,將返回最終答案。具體的流程圖如下:

#第一次與LLM 互動的時候,應使用Base Prompting (基礎提示), 其中的prompt(提示)可以是Standard prompt,CoT prompt 或其改進版本。透過 Base Prompting,可以進行第一次交互,然後得到初步的答案。在隨後的交互中,應使用 PHP,直至最新的兩個答案一致。
PHP prompt 基於 Base Prompt 進行修改。給定一個 Base Prompt,可以透過制定的 PHP prompt design principles 來得到對應的 PHP prompt。具體如下圖所示:

#作者希望PHP prompt 能夠讓大模型學習到兩個映射模式:
1)如果給的Hint 是正確答案,那麼回傳的答案依然要是正確答案(如上圖所示的「Hint is the correct answer」);
#2)如果給的Hint 是錯誤答案,那麼LLM 要通過推理,跳出錯誤答案的Hint,返回正確答案(具體如上圖所示的“Hint is the incorrect answer”)。
依照這個 PHP prompt 的設計規則,給定任意現存的 Base Prompt,作者都可以設定出對應的 PHP Prompt。
实验
作者使用七个数据集,包括 AddSub、MultiArith、SingleEQ、SVAMP、GSM8K、 AQuA 和 MATH。同时,作者一共使用了四个模型来验证作者的想法,包括 text-davinci-002、text-davinci-003、GPT-3.5-Turbo 和 GPT-4。
主要结果
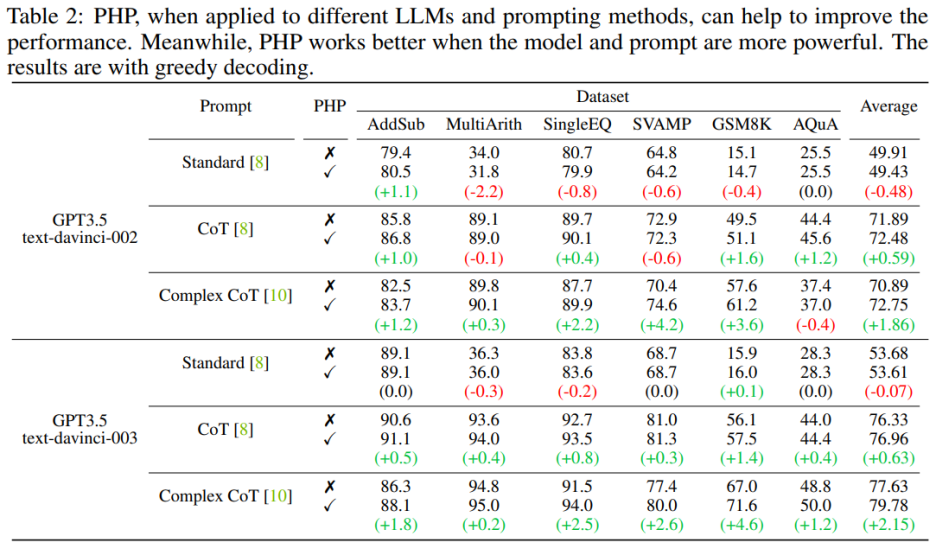
当语言模型更强大、提示更有效时,PHP 的效果更好。相比于 Standard Prompt 和 CoT Prompt,Complex CoT prompt 表现出了显著的性能提升。分析还显示,使用强化学习进行微调的 text-davinci-003 语言模型比使用监督指令微调的 text-davinci-002 模型表现更好,能够提升文档效果。text-davinci-003 的性能提高归因于其增强的能力,使其更好地理解和应用给定的提示。同时,如果只是使用 Standard prompt,那么 PHP 所带来的提升并不明显。如果需要让 PHP 起到效果,至少需要 CoT 来激发模型的推理能力。
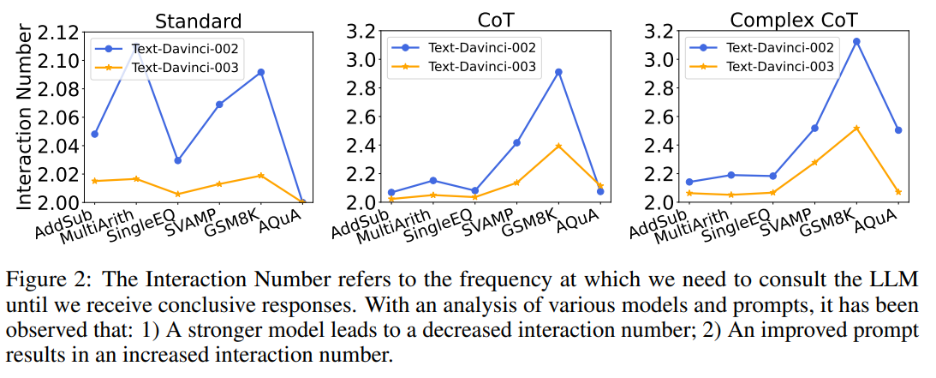
同时,作者也探究了交互次数与模型、prompt 之间的关系。当语言模型更强大,提示更弱时,交互次数会减少。交互次数指代智能体与 LLMs 互动的次数。当收到第一个答案时,交互次数为 1;收到第二个答案时,交互次数增加到 2。在图 2 中,作者展示了各种模型和提示的交互次数。作者的研究结果表明:
1)在给定相同提示的情况下,text-davinci-003 的交互次数通常低于 text-davinci-002。这主要是由于 text-davinci-003 的准确性更高,导致基础答案和后续答案的正确率更高,因此需要更少的交互才能得到最终的正确答案;
2)当使用相同的模型时,随着提示变得更强大,交互次数通常会增加。这是因为当提示变得更有效时,LLMs 的推理能力会得到更好的发挥,从而使它们能够利用提示跳出错误答案,最终导致需要更高的交互次数才能达到最终答案,这使得交互次数增加。
Hint 质量的影响
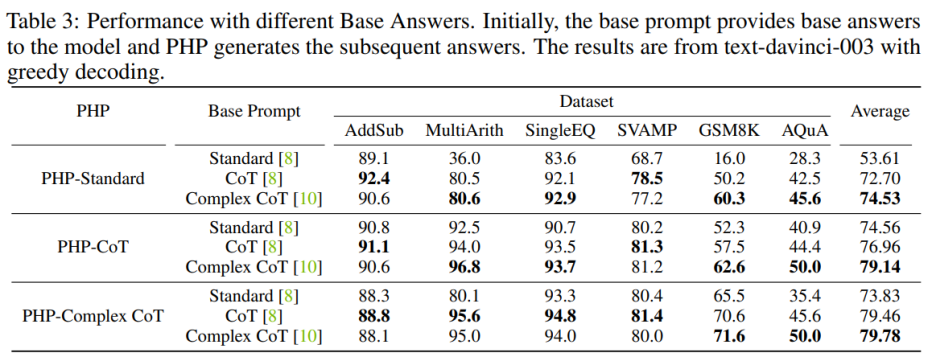
为了增强 PHP-Standard 的性能,将 Base Prompt Standard 替换为 Complex CoT 或 CoT 可以显著提高最终性能。对 PHP-Standard 而言,作者观察到在 Base Prompt Standard 下,GSM8K 的性能从 16.0% 提高到了在基础提示 CoT 下的 50.2%,再提高到在基础提示 Complex CoT 下的 60.3%。相反,如果将 Base Prompt Complex CoT 替换为 Standard,则最终性能会降低。例如,在将基础提示 Complex CoT 替换为 Standard 后,PHP-Complex CoT 在 GSM8K 数据集上的性能从 71.6% 下降到了 65.5%。
如果 PHP 不是基于相应的 Base Prompt 进行设计,那么效果可能进一步提高。使用 Base Prompt Complex CoT 的 PHP-CoT 在六个数据集中的四个数据集表现优于使用 CoT 的 PHP-CoT。同样地,使用基础提示 CoT 的 PHP-Complex CoT 在六个数据集中的四个数据集表现优于使用 Base Prompt Complex CoT 的 PHP-Complex CoT。作者推推测这是因为两方面的原因:1)在所有六个数据集上,CoT 和 Complex CoT 的性能相似;2)由于 Base Answer 是由 CoT(或 Complex CoT)提供的,而后续答案是基于 PHP-Complex CoT(或 PHP-CoT),这就相当于有两个人合作解决问题。因此,在这种情况下,系统的性能可能进一步提高。
消融实验
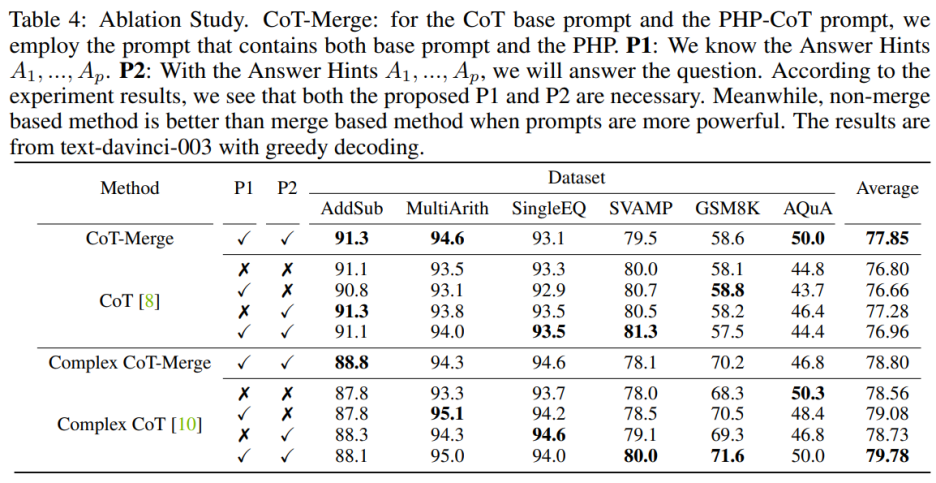
将句子 P1 和 P2 纳入模型可以提高 CoT 在三个数据集上的表现,但当使用 Complex CoT 方法时,这两个句子的重要性尤为明显。在加入 P1 和 P2 后,该方法在六个数据集中有五个数据集的表现得到了提升。例如,在 SVAMP 数据集上,Complex CoT 的表现从 78.0% 提高到了 80.0%,在 GSM8K 数据集上从 68.3% 提高到了 71.6%。这表明,尤其是在模型的逻辑能力更强时,句子 P1 和 P2 的效果更为显著。
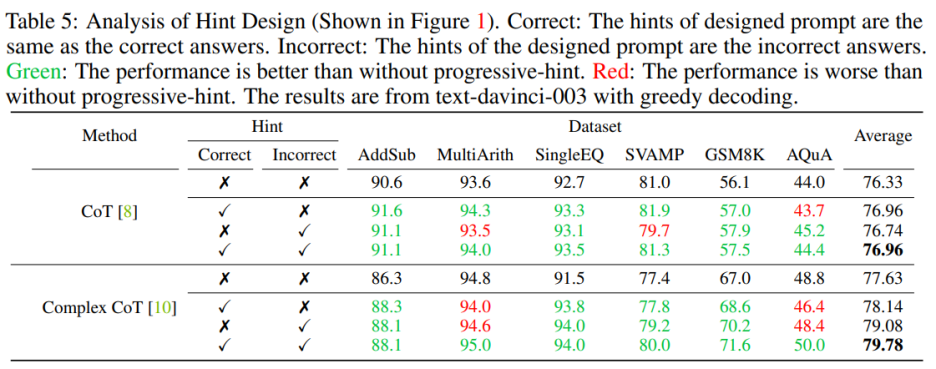
在设计提示时需要同时包含正确和错误的提示。当设计的提示同时包含正确和错误的提示时,使用 PHP 的效果优于不使用 PHP。具体来说,提示中提供正确的提示会促进生成与给定提示相符的答案。相反,提示中提供错误的提示则会通过给定的提示鼓励生成其他答案
PHP Self-Consistency
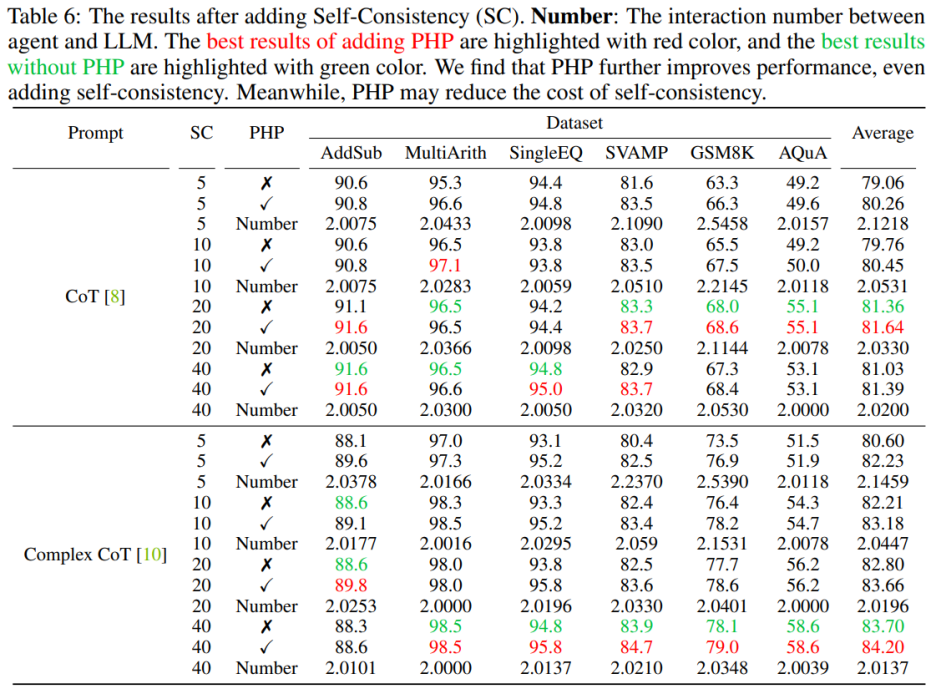
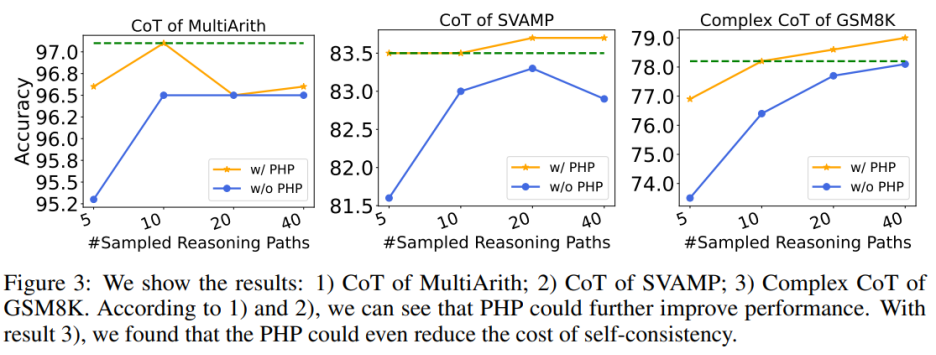
使用 PHP 可以进一步提高性能。通过使用类似的提示和样本路径数量,作者发现在表 6 和图 3 中,作者提出的 PHP-CoT 和 PHP-Complex CoT 总是比 CoT 和 Complex CoT 表现更好。例如,CoT SC 的样本路径为 10、20 和 40 时,能够在 MultiArith 数据集上达到 96.5% 的准确率。因此,可以得出结论,CoT SC 的最佳性能为 96.5%,使用 text-davinci-003。然而,在实施 PHP 之后,性能升至 97.1%。同样,作者还观察到在 SVAMP 数据集上,CoT SC 的最佳准确率为 83.3%,在实施 PHP 后进一步提高到 83.7%。这表明,PHP 可以打破性能瓶颈并进一步提高性能。
使用 PHP 可以降低 SC 的成本,众所周知,SC 涉及更多的推理路径,导致成本更高。表 6 说明,PHP 可以是降低成本的有效方法,同时仍保持性能增益。如图 3 所示,使用 SC Complex CoT,可以使用 40 个样本路径达到 78.1% 的准确率,而加入 PHP 将所需平均推理路径降低到 10×2.1531=21.531 条路径,并且结果更好,准确率达到了 78.2%。
GPT-3.5-Turbo 和 GPT-4
作者按照以前的工作设置,使用文本生成模型进行实验。随着 GPT-3.5-Turbo 和 GPT-4 的 API 发布,作者在相同的六个数据集上验证了具有 PHP 的 Complex CoT 的性能。作者对这两个模型都使用贪心解码(即温度 = 0)和 Complex CoT 作为提示。
如表 7 所示,提出的 PHP 增强了性能,在 GSM8K 上提高了 2.3%,在 AQuA 上提高了 3.2%。然而,与 text-davinci-003 相比,GPT-3.5-Turbo 表现出对提示的依附能力降低。作者提供了两个例子来说明这一点:a)在提示缺失的情况下,GPT-3.5-Turbo 无法回答问题,并回复类似于 “由于答案提示缺失,我无法回答此问题。请提供答案提示以继续” 的声明。相比之下,text-davinci-003 在回答问题之前会自主生成并填充缺失的答案提示;b)当提供超过十个提示时,GPT-3.5-Turbo 可能会回复 “由于给出了多个答案提示,我无法确定正确的答案。请为问题提供一个答案提示。”
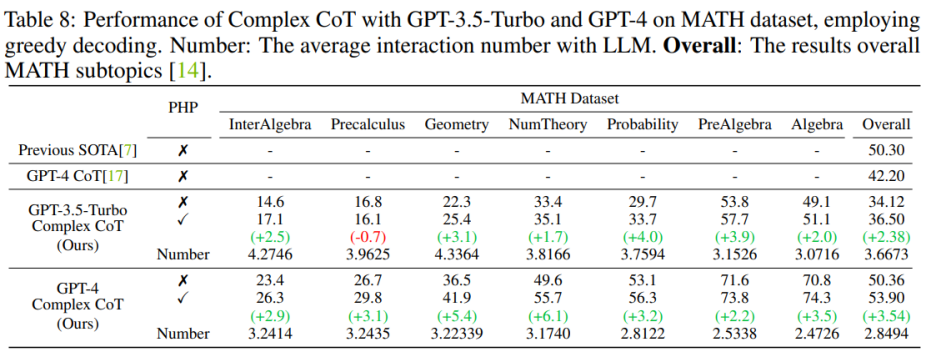
在部署 GPT-4 模型后,作者能够在 SVAMP、GSM8K、AQuA 和 MATH 基准测试上实现新的 SOTA 性能。作者提出的 PHP 方法不断改善了 GPT-4 的性能。此外,与 GPT-3.5-Turbo 模型相比,作者观察到 GPT-4 所需的交互次数减少了,这与 “当模型更加强大时,交互次数会减少” 的发现相一致。
总结
本文介绍了 PHP 与 LLMs 交互的新方法,具有多个优点:1)PHP 在数学推理任务上实现了显著的性能提升,在多个推理基准测试上领先于最先进的结果;2)使用更强大的模型和提示,PHP 可以更好地使 LLMs 受益;3)PHP 可以与 CoT 和 SC 轻松结合,进一步提高性能。
为了更好地增强 PHP 方法,未来的研究可以集中在改进问题阶段的手工提示和答案部分的提示句子的设计上。此外,除了将答案当作 hint,还可以确定和提取有助于 LLMs 重新考虑问题的新 hint。
以上是GPT-4拿下最難數學推理資料集新SOTA,新型Prompting讓大模型推理能力狂升的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 值得購買以獲得短期收益的九種加密貨幣盤點
May 14, 2025 pm 09:54 PM
值得購買以獲得短期收益的九種加密貨幣盤點
May 14, 2025 pm 09:54 PM
目錄如何選擇加密貨幣進行短期交易?短期交易最佳加密貨幣列表比特幣雪崩索拉納狗狗幣多邊形世界幣Chainlink新興企業如何選擇加密貨幣進行短期交易?短期交易是指購買加密貨幣並持有一段時間,從幾分鐘到幾天不等。這種方法前景光明,但也存在風險,耗時較長,因為你需要持續關注市場行情。但這還不是全部;在選擇合適的加密貨幣資產時,你還應該注意以下幾點:波動性:短期交易成功的主要指標之一是高揮發性加密貨幣的價值;價值越高,價格波動越大,從而創造更
 一文搞清楚經濟波動期間穩定幣的作用
May 14, 2025 pm 09:15 PM
一文搞清楚經濟波動期間穩定幣的作用
May 14, 2025 pm 09:15 PM
你不需要是經濟學家也能感受到經濟的動盪。物價下跌,工作穩定性下降,每個人似乎都對自己的財務未來感到焦慮。什麼是穩定幣?穩定幣就像加密世界中的救生衣:一種設計用來保持價值穩定的數字貨幣,通常與美元或黃金等穩定資產掛鉤。與比特幣或以太坊等價格波動劇烈的加密貨幣不同,穩定幣追求穩定性。當經濟風暴來襲時,投資者自然會尋求穩定,而穩定幣恰好提供了這種避險資產——免受波動的影響。為什麼穩定幣在經濟不穩定時蓬勃發展在
 VINU幣未來如何? 2025年VINU幣價格分析與投資策略
May 14, 2025 pm 09:30 PM
VINU幣未來如何? 2025年VINU幣價格分析與投資策略
May 14, 2025 pm 09:30 PM
目錄 什麼是VitaInu(VINU)?什麼是VINU代幣? 2025年VINU幣價格預測VitaInu(VINU)價格預測2025-2030至2030年VitaInu(VINU)價格預測2025年VitaInu價格預測2026年VitaInu價格預測2027年VitaInu價格預測2028年VitaInu價格預測2029年VitaInu價格預測2030年VitaInu價格預測解讀VINU的市場表現
 Solayer(LAYER)是什麼?Solayer代幣經濟學和價格預測
May 14, 2025 pm 10:06 PM
Solayer(LAYER)是什麼?Solayer代幣經濟學和價格預測
May 14, 2025 pm 10:06 PM
介紹去中心化金融(DeFi)正在改變用戶與區塊鏈技術的交互方式,為交易、借貸和收益創造創造無縫靈活的途徑。 Solayer(LAYER)正是這一變革的核心,它構建了一個跨多條區塊鏈連接流動性和實用性的協議。隨著DeFi的普及以及對高效跨鏈基礎設施需求的增長,Solayer正吸引著交易員、開發者和投資者的關注,他們正在尋找下一個重大機遇。本文將解釋Solayer的概念,詳細介紹其創新功能和代幣經濟學,並展望其2030年
 Zebec Network(ZBCN)是什麼?ZBCN代幣經濟學和價格預測
May 14, 2025 pm 09:48 PM
Zebec Network(ZBCN)是什麼?ZBCN代幣經濟學和價格預測
May 14, 2025 pm 09:48 PM
在當今的數字經濟中,傳統金融與區塊鏈技術之間的界限開始變得模糊。人們渴望更快的支付、無邊界的交易以及對自身資金的更多掌控——而且他們渴望立即實現。 ZebecNetwork是眾多旨在通過構建可編程資金流基礎設施來滿足這一需求的項目之一。 Zebec專注於實時工資單、加密支付和去中心化系統,將自己定位為連接成熟金融實踐與新興區塊鏈解決方案的橋樑。本文概述了ZebecNetwork——它
 什麼是 Sign Protocol (SIGN)?跨鏈驗證網絡入門指南
May 14, 2025 pm 10:48 PM
什麼是 Sign Protocol (SIGN)?跨鏈驗證網絡入門指南
May 14, 2025 pm 10:48 PM
區塊鏈技術持續改變著人們在線上交換價值、驗證信息和建立信任的方式。隨著去中心化應用在各行各業的蓬勃發展,跨多個區塊鏈確認聲明和身份的能力變得越來越重要,也越來越複雜。傳統的、依賴於中心化權威的信任模型往往不足以支撐去中心化的生態系統,因此對區塊鏈原生驗證解決方案的需求也日益增長。 SignProtocol(SIGN)通過提供一個用於跨多個區塊鍊網絡創建、驗證和管理證明的框架來應對這一挑戰。 SignProtocol旨在打造一個全鏈
 Solana鏈上Meme幣MOODENG、GOAT登陸幣安Alpha!幣價齊暴漲
May 14, 2025 pm 10:24 PM
Solana鏈上Meme幣MOODENG、GOAT登陸幣安Alpha!幣價齊暴漲
May 14, 2025 pm 10:24 PM
Solana鏈上兩大Meme幣——MooDeng(MOODENG)、GoatseusMaximus(GOAT)昨(11)日登陸幣安「Alpha」平台後迅速翻紅,重燃投資人熱情,其中MOODENG幣價單日狂飆逾123%,一舉刷新今年以來新高。幣安Alpha主要聚焦於早期潛力幣種,通常會上架社群熱度高、有成長潛力的幣種,如今正式上線MOODENG、GOAT,不僅為這兩款Meme幣注入資金活水,更讓Solana生態再
 SWCH是什麼幣種?值得投資嗎?SWCH幣詳細購買教程
May 14, 2025 pm 10:30 PM
SWCH是什麼幣種?值得投資嗎?SWCH幣詳細購買教程
May 14, 2025 pm 10:30 PM
加密貨幣市場項目隨著區塊鏈發展而不斷湧現,目的就是改變傳統金融實踐,SwissCheese就是其中一個項目。據了解,SwissCheese是一個讓用戶能夠交易通證化股票的去中心化平台,旨在增強市場的可及性並降低交易成本,為更具包容性的金融環境鋪平道路。平台的原生代幣為SWCH,主要作用就是交易、治理等。該項目上線後立即引起了投資者的關注,但僅僅了解SWCH是什麼幣種?還不能分析出SWCH值得投資嗎?結合當前數據來看,SWCH具有一定的
