

GPT-4的32k輸入框還是不夠用? Unlimiformer把上下文長度拉到無限長

Transformer 是時下最強大的 seq2seq 架構。預訓練 transformer 通常具有 512(例如 BERT)或 1024 個(例如 BART)token 的個上下文窗口,這對於目前許多文本摘要資料集(XSum、CNN/DM)來說是足夠長的。
但16384 並不是產生所需上下文長度的上限:涉及長篇敘事的任務,如書籍摘要(Krys-´cinski et al.,2021)或敘事問答(Kociskýet al .,2018),通常輸入超過10 萬個token。維基百科文章產生的挑戰集(Liu*et al.,2018)包含超過 50 萬個 token 的輸入。生成式問答中的開放域任務可以從更大的輸入中綜合信息,例如回答關於維基百科上所有健在作者的文章的聚合屬性的問題。圖 1 根據常見的上下文視窗長度繪製了幾個流行的摘要和問答資料集的大小;最長的輸入比 Longformer 的上下文視窗長 34 倍以上。
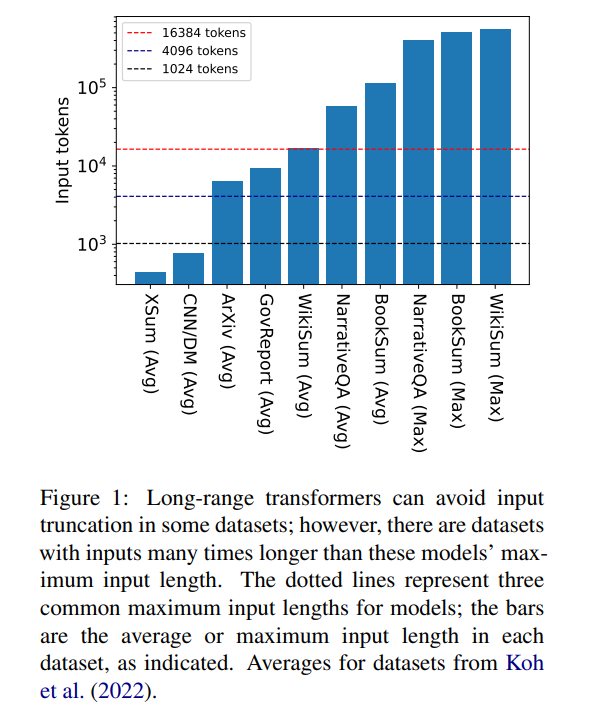
在這些超長輸入的情況下,vanilla transformer 無法進行縮放,因為原生注意力機制具有平方級的複雜度。長輸入 transformer 雖然比標準 transformer 更有效率,但仍需要大量的運算資源,這些資源隨著上下文視窗大小的增加而增加。此外,增加上下文視窗需要用新的上下文視窗大小從頭開始重新訓練模型,計算上和環境上的代價都不小。
在「Unlimiformer: Long-Range Transformers with Unlimited Length Input」一文中,來自卡內基美隆大學的研究者引進了 Unlimiformer。這是一種基於檢索的方法,這種方法增強了預先訓練的語言模型,以在測試時接受無限長度的輸入。

論文連結:https://arxiv.org/pdf/2305.01625v1.pdf
Unlimiformer 可以被注入到任何現有的編碼器- 解碼器transformer 中,能夠處理長度不限的輸入。給定一個長的輸入序列,Unlimiformer 可以在所有輸入 token 的隱藏狀態上建立一個資料儲存。然後,解碼器的標準交叉注意力機制能夠查詢資料存儲,並關注前 k 個輸入 token。資料儲存可以儲存在 GPU 或 CPU 記憶體中,能夠次線性查詢。
Unlimiformer 可以直接應用於經過訓練的模型,並且可以在沒有任何進一步訓練的情況下改進現有的 checkpoint。 Unlimiformer 經過微調後,效能會進一步提升。本文證明,Unlimiformer 可以應用於多個基礎模型,如 BART(Lewis et al.,2020a)或 PRIMERA(Xiao et al.,2022),且無需添加權重和重新訓練。在各種長程seq2seq 資料集中,Unlimiformer 不僅在這些資料集上比Longformer(Beltagy et al.,2020b)、SLED(Ivgi et al.,2022)和Memorizing transformers(Wu et al.,2021)等強長程Transformer表現較好,本文也發現Unlimiform 可以應用於Longformer 編碼器模型之上,以進行進一步改進。
Unlimiformer 技術原理
由於編碼器上下文視窗的大小是固定的,Transformer 的最大輸入長度受到限制。然而,在解碼過程中,不同的訊息可能是相關的;此外,不同的注意力頭可能會關注不同類型的訊息(Clark et al.,2019)。因此,固定的上下文視窗可能會在註意力不那麼關注的 token 上浪費精力。
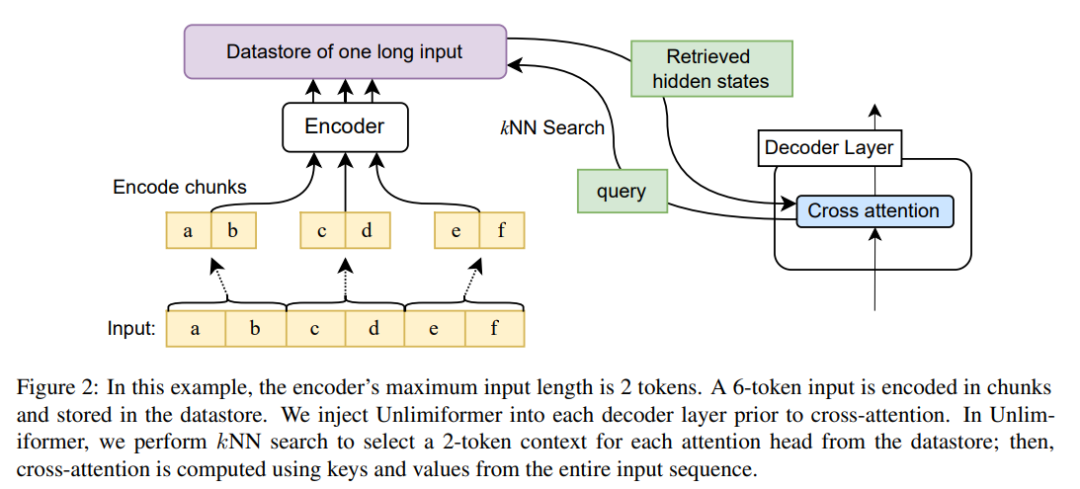
在每個解碼步驟中,Unlimiformer 中每個注意力頭都會從全部輸入中選擇一個單獨的上下文視窗。透過將Unlimiformer 查找注入解碼器來實現:在進入交叉注意力模組之前,該模型在外部資料儲存中執行k 最近鄰(kNN) 搜索,在每個解碼器層中的每個注意力頭中選一組token 來參與。
編碼
#為了將比模型的上下文視窗長度更長的輸入序列進行編碼,本文按照Ivgi et al. (2022) 的方法對輸入的重疊塊進行編碼(Ivgi et al. ,2022),只保留每個chunk 的輸出的中間一半,以確保編碼過程前後都有足夠的上下文。最後,本文使用 Faiss (Johnson et al., 2019) 等資料庫對資料儲存中的編碼輸入進行索引(Johnson et al.,2019)。
檢索增強的交叉注意力機制
#在標準的交叉注意力機制中,transformer 的解碼器專注於編碼器的最終隱狀態,編碼器通常截斷輸入,並僅對輸入序列中的前k 個token 進行編碼。
本文不是只關注輸入的這前k 個token,對於每個交叉注意頭,都檢索更長的輸入系列的前k 個隱狀態,並只關注這前k 個。這樣就能從整個輸入序列中檢索關鍵字,而不是截斷關鍵字。在運算和 GPU 記憶體方面,本文的方法也比處理所有輸入 token 更便宜,同時通常還能保留 99% 以上的注意力效能。
圖 2 顯示了本文對 seq2seq transformer 架構的變更。使用編碼器對完整輸入進行區塊編碼,並將其儲存在資料儲存中;然後,解碼時查詢編碼的隱狀態資料儲存。 kNN 搜尋是非參數的,並且可以被注入到任何預先訓練的 seq2seq transformer 中,詳情如下。
#實驗結果
#長文件摘要
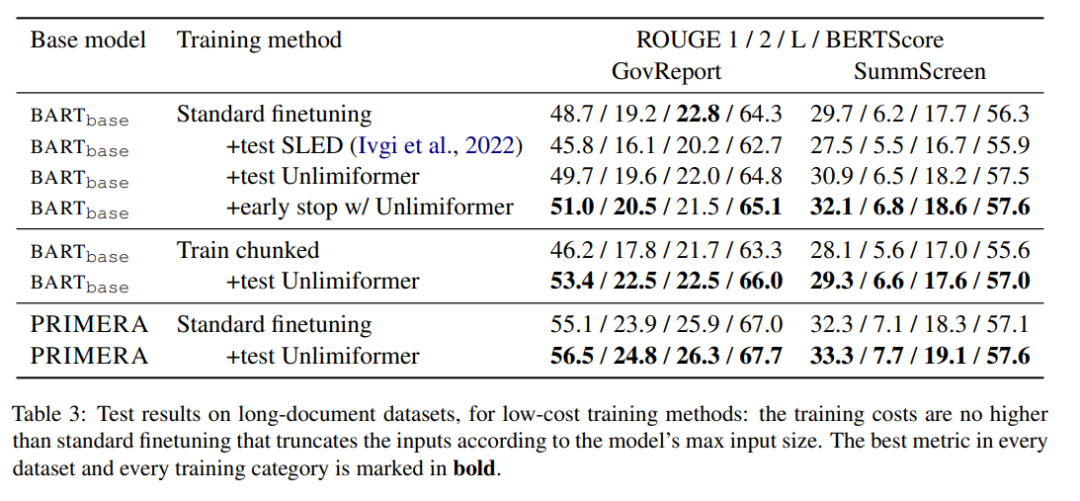
表3 顯示了長文本(4k 及16k 的token 輸入)摘要資料集中的結果。
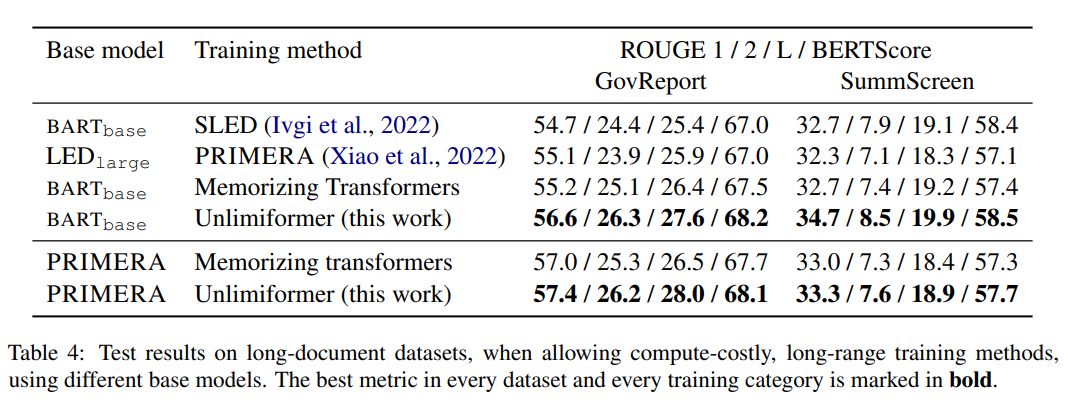
在表 4 的訓練方法中,Unlimiformer 能夠在各項指標上達到最優。
書籍摘要
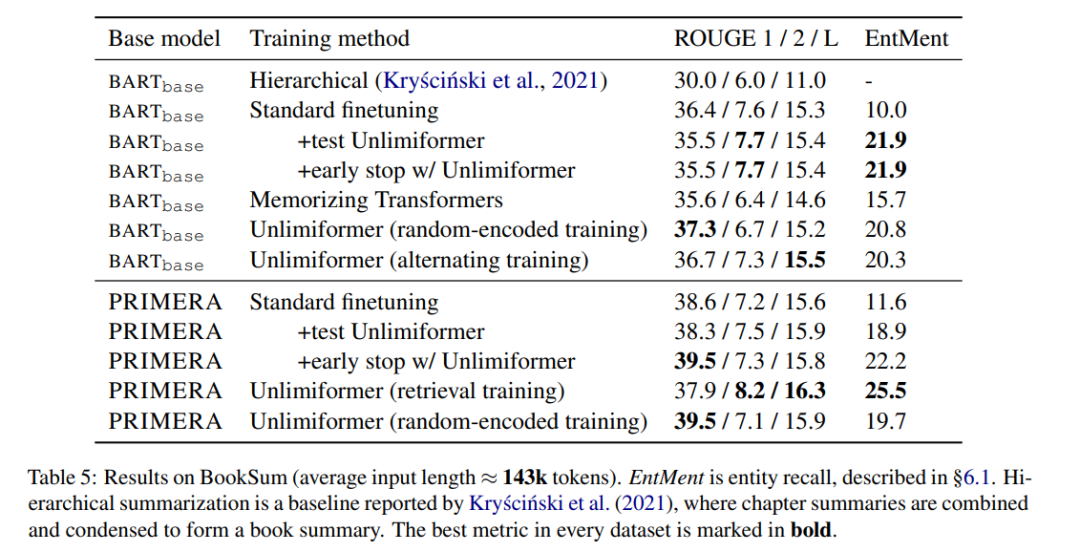
表5 顯示了在書籍摘要上的結果。可以看到,基於 BARTbase 和 PRIMERA,應用 Unlimiformer 都能達到一定的改善效果。
以上是GPT-4的32k輸入框還是不夠用? Unlimiformer把上下文長度拉到無限長的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

AI Hentai Generator
免費產生 AI 無盡。

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)
熱門話題



 SQL 如何添加新列
Apr 09, 2025 pm 02:09 PM
SQL 如何添加新列
Apr 09, 2025 pm 02:09 PM
SQL 中通過使用 ALTER TABLE 語句為現有表添加新列。具體步驟包括:確定表名稱和列信息、編寫 ALTER TABLE 語句、執行語句。例如,為 Customers 表添加 email 列(VARCHAR(50)):ALTER TABLE Customers ADD email VARCHAR(50);
 SQL 添加列的語法是什麼
Apr 09, 2025 pm 02:51 PM
SQL 添加列的語法是什麼
Apr 09, 2025 pm 02:51 PM
SQL 中添加列的語法為 ALTER TABLE table_name ADD column_name data_type [NOT NULL] [DEFAULT default_value]; 其中,table_name 是表名,column_name 是新列名,data_type 是數據類型,NOT NULL 指定是否允許空值,DEFAULT default_value 指定默認值。
 SQL 清空表:性能優化技巧
Apr 09, 2025 pm 02:54 PM
SQL 清空表:性能優化技巧
Apr 09, 2025 pm 02:54 PM
提高 SQL 清空表性能的技巧:使用 TRUNCATE TABLE 代替 DELETE,釋放空間並重置標識列。禁用外鍵約束,防止級聯刪除。使用事務封裝操作,保證數據一致性。批量刪除大數據,通過 LIMIT 限制行數。清空後重建索引,提高查詢效率。
 SQL 添加列時如何設置默認值
Apr 09, 2025 pm 02:45 PM
SQL 添加列時如何設置默認值
Apr 09, 2025 pm 02:45 PM
為新添加的列設置默認值,使用 ALTER TABLE 語句:指定添加列並設置默認值:ALTER TABLE table_name ADD column_name data_type DEFAULT default_value;使用 CONSTRAINT 子句指定默認值:ALTER TABLE table_name ADD COLUMN column_name data_type CONSTRAINT default_constraint DEFAULT default_value;
 使用 DELETE 語句清空 SQL 表
Apr 09, 2025 pm 03:00 PM
使用 DELETE 語句清空 SQL 表
Apr 09, 2025 pm 03:00 PM
是的,DELETE 語句可用於清空 SQL 表,步驟如下:使用 DELETE 語句:DELETE FROM table_name;替換 table_name 為要清空的表的名稱。
 Redis內存碎片如何處理?
Apr 10, 2025 pm 02:24 PM
Redis內存碎片如何處理?
Apr 10, 2025 pm 02:24 PM
Redis內存碎片是指分配的內存中存在無法再分配的小塊空閒區域。應對策略包括:重啟Redis:徹底清空內存,但會中斷服務。優化數據結構:使用更適合Redis的結構,減少內存分配和釋放次數。調整配置參數:使用策略淘汰最近最少使用的鍵值對。使用持久化機制:定期備份數據,重啟Redis清理碎片。監控內存使用情況:及時發現問題並採取措施。
 phpmyadmin建立數據表
Apr 10, 2025 pm 11:00 PM
phpmyadmin建立數據表
Apr 10, 2025 pm 11:00 PM
要使用 phpMyAdmin 創建數據表,以下步驟必不可少:連接到數據庫並單擊“新建”標籤。為表命名並選擇存儲引擎(推薦 InnoDB)。通過單擊“添加列”按鈕添加列詳細信息,包括列名、數據類型、是否允許空值以及其他屬性。選擇一個或多個列作為主鍵。單擊“保存”按鈕創建表和列。
 怎麼創建oracle數據庫 oracle怎麼創建數據庫
Apr 11, 2025 pm 02:33 PM
怎麼創建oracle數據庫 oracle怎麼創建數據庫
Apr 11, 2025 pm 02:33 PM
創建Oracle數據庫並非易事,需理解底層機制。 1. 需了解數據庫和Oracle DBMS的概念;2. 掌握SID、CDB(容器數據庫)、PDB(可插拔數據庫)等核心概念;3. 使用SQL*Plus創建CDB,再創建PDB,需指定大小、數據文件數、路徑等參數;4. 高級應用需調整字符集、內存等參數,並進行性能調優;5. 需注意磁盤空間、權限和參數設置,並持續監控和優化數據庫性能。 熟練掌握需不斷實踐,才能真正理解Oracle數據庫的創建和管理。
