

Python虛擬機器中字典的實作原理是什麼

字典資料結構分析
/* The ma_values pointer is NULL for a combined table
* or points to an array of PyObject* for a split table
*/
typedef struct {
PyObject_HEAD
Py_ssize_t ma_used;
PyDictKeysObject *ma_keys;
PyObject **ma_values;
} PyDictObject;
struct _dictkeysobject {
Py_ssize_t dk_refcnt;
Py_ssize_t dk_size;
dict_lookup_func dk_lookup;
Py_ssize_t dk_usable;
PyDictKeyEntry dk_entries[1];
};
typedef struct {
/* Cached hash code of me_key. */
Py_hash_t me_hash;
PyObject *me_key;
PyObject *me_value; /* This field is only meaningful for combined tables */
} PyDictKeyEntry;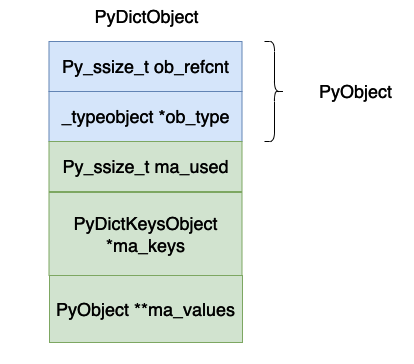
上面的各個欄位的意義為:
ob_refcnt,物件的參考計數。
ob_type,物件的資料型態。
ma_used,目前雜湊表當中的資料個數。
ma_keys,指向儲存鍵值對的陣列。
ma_values,這個指向值的數組,但是在cpython 的具體實現當中不一定使用這個值,因為_dictkeysobject 當中的PyDictKeyEntry 數組當中的對像也是可以存儲value 的,這個數值只有在鍵全部是字串的時候才可能會使用,在本篇文章當中主要使用PyDictKeyEntry 當中的value 來討論字典的實現,因此大家可以忽略這個變數。
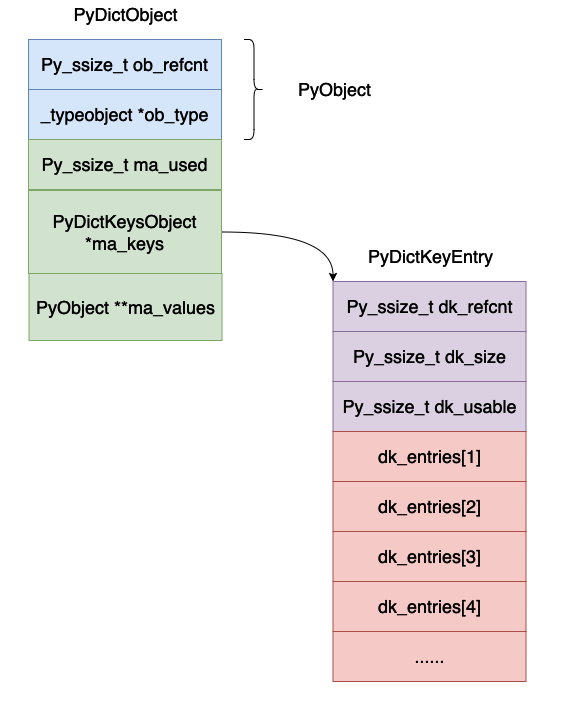
dk_refcnt,這個也是用來表示引用計數,這個跟字典的視圖有關係,原理和引用計數類似,這裡暫時不管。
dk_size,這個表示雜湊表的大小,必須是 2n,這樣的話可以將模運算變成位元與運算。
dk_lookup,這個表示哈希表的查找函數,他是一個函數指標。
dk_usable,表示目前陣列當中還有多少個可以使用的鍵值對。
dk_entries,雜湊表,真正儲存鍵值對的地方。
整個雜湊表的版面大致如下圖所示:
#建立新字典物件
##這個函數還是比較簡單,先申請記憶體空間,然後再進行一些初始化操作,申請哈希表用來保存鍵值對。static PyObject *
dict_new(PyTypeObject *type, PyObject *args, PyObject *kwds)
{
PyObject *self;
PyDictObject *d;
assert(type != NULL && type->tp_alloc != NULL);
// 申请内存空间
self = type->tp_alloc(type, 0);
if (self == NULL)
return NULL;
d = (PyDictObject *)self;
/* The object has been implicitly tracked by tp_alloc */
if (type == &PyDict_Type)
_PyObject_GC_UNTRACK(d);
// 因为还没有增加数据 因此哈希表当中 ma_used = 0
d->ma_used = 0;
// 申请保存键值对的数组 PyDict_MINSIZE_COMBINED 是一个宏定义 值为 8 表示哈希表数组的最小长度
d->ma_keys = new_keys_object(PyDict_MINSIZE_COMBINED);
// 如果申请失败返回 NULL
if (d->ma_keys == NULL) {
Py_DECREF(self);
return NULL;
}
return self;
}
// new_keys_object 函数如下所示
static PyDictKeysObject *new_keys_object(Py_ssize_t size)
{
PyDictKeysObject *dk;
Py_ssize_t i;
PyDictKeyEntry *ep0;
assert(size >= PyDict_MINSIZE_SPLIT);
assert(IS_POWER_OF_2(size));
// 这里是申请内存的位置真正申请内存空间的大小为 PyDictKeysObject 的大小加上 size-1 个PyDictKeyEntry的大小
// 这里你可能会有一位为啥不是 size 个 PyDictKeyEntry 的大小 因为在结构体 PyDictKeysObject 当中已经申请了一个 PyDictKeyEntry 对象了
dk = PyMem_MALLOC(sizeof(PyDictKeysObject) +
sizeof(PyDictKeyEntry) * (size-1));
if (dk == NULL) {
PyErr_NoMemory();
return NULL;
}
// 下面主要是一些初始化的操作 dk_refcnt 设置成 1 因为目前只有一个字典对象使用 这个 PyDictKeysObject 对象
DK_DEBUG_INCREF dk->dk_refcnt = 1;
dk->dk_size = size; // 哈希表的大小
// 下面这行代码主要是表示哈希表当中目前还能存储多少个键值对 在 cpython 的实现当中允许有 2/3 的数组空间去存储数据 超过这个数则需要进行扩容
dk->dk_usable = USABLE_FRACTION(size); // #define USABLE_FRACTION(n) ((((n) << 1)+1)/3)
ep0 = &dk->dk_entries[0];
/* Hash value of slot 0 is used by popitem, so it must be initialized */
ep0->me_hash = 0;
// 将所有的键值对初始化成 NULL
for (i = 0; i < size; i++) {
ep0[i].me_key = NULL;
ep0[i].me_value = NULL;
}
dk->dk_lookup = lookdict_unicode_nodummy;
return dk;
}#define GROWTH_RATE(d) (((d)->ma_used*2)+((d)->ma_keys->dk_size>>1))
- 計算新的陣列的大小。
- 建立新的陣列。
- 將原來的雜湊表當中的資料加入新的陣列當中(也就是再雜湊的過程)。
static int
insertion_resize(PyDictObject *mp)
{
return dictresize(mp, GROWTH_RATE(mp));
}
static int
dictresize(PyDictObject *mp, Py_ssize_t minused)
{
Py_ssize_t newsize;
PyDictKeysObject *oldkeys;
PyObject **oldvalues;
Py_ssize_t i, oldsize;
// 下面的代码的主要作用就是计算得到能够大于等于 minused 最小的 2 的整数次幂
/* Find the smallest table size > minused. */
for (newsize = PyDict_MINSIZE_COMBINED;
newsize <= minused && newsize > 0;
newsize <<= 1)
;
if (newsize <= 0) {
PyErr_NoMemory();
return -1;
}
oldkeys = mp->ma_keys;
oldvalues = mp->ma_values;
/* Allocate a new table. */
// 创建新的数组
mp->ma_keys = new_keys_object(newsize);
if (mp->ma_keys == NULL) {
mp->ma_keys = oldkeys;
return -1;
}
if (oldkeys->dk_lookup == lookdict)
mp->ma_keys->dk_lookup = lookdict;
oldsize = DK_SIZE(oldkeys);
mp->ma_values = NULL;
/* If empty then nothing to copy so just return */
if (oldsize == 1) {
assert(oldkeys == Py_EMPTY_KEYS);
DK_DECREF(oldkeys);
return 0;
}
/* Main loop below assumes we can transfer refcount to new keys
* and that value is stored in me_value.
* Increment ref-counts and copy values here to compensate
* This (resizing a split table) should be relatively rare */
if (oldvalues != NULL) {
for (i = 0; i < oldsize; i++) {
if (oldvalues[i] != NULL) {
Py_INCREF(oldkeys->dk_entries[i].me_key);
oldkeys->dk_entries[i].me_value = oldvalues[i];
}
}
}
/* Main loop */
// 将原来数组当中的元素加入到新的数组当中
for (i = 0; i < oldsize; i++) {
PyDictKeyEntry *ep = &oldkeys->dk_entries[i];
if (ep->me_value != NULL) {
assert(ep->me_key != dummy);
insertdict_clean(mp, ep->me_key, ep->me_hash, ep->me_value);
}
}
// 更新一下当前哈希表当中能够插入多少数据
mp->ma_keys->dk_usable -= mp->ma_used;
if (oldvalues != NULL) {
/* NULL out me_value slot in oldkeys, in case it was shared */
for (i = 0; i < oldsize; i++)
oldkeys->dk_entries[i].me_value = NULL;
assert(oldvalues != empty_values);
free_values(oldvalues);
DK_DECREF(oldkeys);
}
else {
assert(oldkeys->dk_lookup != lookdict_split);
if (oldkeys->dk_lookup != lookdict_unicode_nodummy) {
PyDictKeyEntry *ep0 = &oldkeys->dk_entries[0];
for (i = 0; i < oldsize; i++) {
if (ep0[i].me_key == dummy)
Py_DECREF(dummy);
}
}
assert(oldkeys->dk_refcnt == 1);
DK_DEBUG_DECREF PyMem_FREE(oldkeys);
}
return 0;
}static void
insertdict_clean(PyDictObject *mp, PyObject *key, Py_hash_t hash,
PyObject *value)
{
size_t i;
size_t perturb;
PyDictKeysObject *k = mp->ma_keys;
// 首先得到 mask 的值
size_t mask = (size_t)DK_SIZE(k)-1;
PyDictKeyEntry *ep0 = &k->dk_entries[0];
PyDictKeyEntry *ep;
i = hash & mask;
ep = &ep0[i];
for (perturb = hash; ep->me_key != NULL; perturb >>= PERTURB_SHIFT) {
// 下面便是遇到哈希冲突时的处理办法
i = (i << 2) + i + perturb + 1;
ep = &ep0[i & mask];
}
assert(ep->me_value == NULL);
ep->me_key = key;
ep->me_hash = hash;
ep->me_value = value;
}以上是Python虛擬機器中字典的實作原理是什麼的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

AI Hentai Generator
免費產生 AI 無盡。

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)
熱門話題



 PHP和Python:代碼示例和比較
Apr 15, 2025 am 12:07 AM
PHP和Python:代碼示例和比較
Apr 15, 2025 am 12:07 AM
PHP和Python各有優劣,選擇取決於項目需求和個人偏好。 1.PHP適合快速開發和維護大型Web應用。 2.Python在數據科學和機器學習領域佔據主導地位。
 CentOS上如何進行PyTorch模型訓練
Apr 14, 2025 pm 03:03 PM
CentOS上如何進行PyTorch模型訓練
Apr 14, 2025 pm 03:03 PM
在CentOS系統上高效訓練PyTorch模型,需要分步驟進行,本文將提供詳細指南。一、環境準備:Python及依賴項安裝:CentOS系統通常預裝Python,但版本可能較舊。建議使用yum或dnf安裝Python3併升級pip:sudoyumupdatepython3(或sudodnfupdatepython3),pip3install--upgradepip。 CUDA與cuDNN(GPU加速):如果使用NVIDIAGPU,需安裝CUDATool
 CentOS上PyTorch的GPU支持情況如何
Apr 14, 2025 pm 06:48 PM
CentOS上PyTorch的GPU支持情況如何
Apr 14, 2025 pm 06:48 PM
在CentOS系統上啟用PyTorchGPU加速,需要安裝CUDA、cuDNN以及PyTorch的GPU版本。以下步驟將引導您完成這一過程:CUDA和cuDNN安裝確定CUDA版本兼容性:使用nvidia-smi命令查看您的NVIDIA顯卡支持的CUDA版本。例如,您的MX450顯卡可能支持CUDA11.1或更高版本。下載並安裝CUDAToolkit:訪問NVIDIACUDAToolkit官網,根據您顯卡支持的最高CUDA版本下載並安裝相應的版本。安裝cuDNN庫:前
 docker原理詳解
Apr 14, 2025 pm 11:57 PM
docker原理詳解
Apr 14, 2025 pm 11:57 PM
Docker利用Linux內核特性,提供高效、隔離的應用運行環境。其工作原理如下:1. 鏡像作為只讀模板,包含運行應用所需的一切;2. 聯合文件系統(UnionFS)層疊多個文件系統,只存儲差異部分,節省空間並加快速度;3. 守護進程管理鏡像和容器,客戶端用於交互;4. Namespaces和cgroups實現容器隔離和資源限制;5. 多種網絡模式支持容器互聯。理解這些核心概念,才能更好地利用Docker。
 Python vs. JavaScript:社區,圖書館和資源
Apr 15, 2025 am 12:16 AM
Python vs. JavaScript:社區,圖書館和資源
Apr 15, 2025 am 12:16 AM
Python和JavaScript在社區、庫和資源方面的對比各有優劣。 1)Python社區友好,適合初學者,但前端開發資源不如JavaScript豐富。 2)Python在數據科學和機器學習庫方面強大,JavaScript則在前端開發庫和框架上更勝一籌。 3)兩者的學習資源都豐富,但Python適合從官方文檔開始,JavaScript則以MDNWebDocs為佳。選擇應基於項目需求和個人興趣。
 CentOS下PyTorch版本怎麼選
Apr 14, 2025 pm 02:51 PM
CentOS下PyTorch版本怎麼選
Apr 14, 2025 pm 02:51 PM
在CentOS下選擇PyTorch版本時,需要考慮以下幾個關鍵因素:1.CUDA版本兼容性GPU支持:如果你有NVIDIAGPU並且希望利用GPU加速,需要選擇支持相應CUDA版本的PyTorch。可以通過運行nvidia-smi命令查看你的顯卡支持的CUDA版本。 CPU版本:如果沒有GPU或不想使用GPU,可以選擇CPU版本的PyTorch。 2.Python版本PyTorch
 minio安裝centos兼容性
Apr 14, 2025 pm 05:45 PM
minio安裝centos兼容性
Apr 14, 2025 pm 05:45 PM
MinIO對象存儲:CentOS系統下的高性能部署MinIO是一款基於Go語言開發的高性能、分佈式對象存儲系統,與AmazonS3兼容。它支持多種客戶端語言,包括Java、Python、JavaScript和Go。本文將簡要介紹MinIO在CentOS系統上的安裝和兼容性。 CentOS版本兼容性MinIO已在多個CentOS版本上得到驗證,包括但不限於:CentOS7.9:提供完整的安裝指南,涵蓋集群配置、環境準備、配置文件設置、磁盤分區以及MinI
 CentOS上PyTorch的分佈式訓練如何操作
Apr 14, 2025 pm 06:36 PM
CentOS上PyTorch的分佈式訓練如何操作
Apr 14, 2025 pm 06:36 PM
在CentOS系統上進行PyTorch分佈式訓練,需要按照以下步驟操作:PyTorch安裝:前提是CentOS系統已安裝Python和pip。根據您的CUDA版本,從PyTorch官網獲取合適的安裝命令。對於僅需CPU的訓練,可以使用以下命令:pipinstalltorchtorchvisiontorchaudio如需GPU支持,請確保已安裝對應版本的CUDA和cuDNN,並使用相應的PyTorch版本進行安裝。分佈式環境配置:分佈式訓練通常需要多台機器或單機多GPU。所
