
讀心術可以說是人類最想要的超能力之一,同時也必定是人們最不希望別人擁有的一種超能力。只要在搜尋引擎中輸入「讀心術」這個關鍵字,你就能找到大量相關書籍、影片和教程,足可見人們對這項能力的執著。但拋開那些心理學、行為學或神秘主義的內容不談,單從技術角度看,人類的大腦訊號是存在模式的,也因此讀心術(解析大腦訊號的模式)是可能實現的。
現今,隨著 AI 技術的發展,其分析模式的能力也越精進,讀心術正在變成現實。
前幾天,德州大學奧斯汀分校發表於Nature Neuroscience 一篇論文引起了熱議,其可以透過非侵入式地讀取大腦訊號而重建出語義相符的連續語句- 不意外,模型同樣使用了目前大受追捧的GPT 語言模式。但我們先暫時按下這項最新的成果不表,看看稍早時間其它一些有關 AI 讀心術的研究成果,以大概理解該課題的當前研究圖景。
寬泛地說,讀心術可分為兩大類:直接讀心術和間接讀心術。
間接讀心術是指透過間接的特徵來揣度一個人的想法和情緒。這些特徵包括人臉表情、身體姿態、體溫、心率、呼吸節律、說話語速和語調等。近年來基於大數據的深度學習技術已經能讓AI 相當準確地透過人臉表情識別情緒,例如輕量級的開源人臉辨識軟體庫Deepface 能在年齡、性別、情緒和種族多項特徵上整體達到97.53% 的測試集準確度。但基於上述特徵的情緒分析技術通常不會被視為讀心術,畢竟人類本身也或多或少能透過他人的表情等特徵猜到其情緒,因此本文關注的讀心術僅限於直接讀心術。

使用Deepfake 函式庫得到人臉屬性分析結果
#直接讀心術是指直接將大腦訊號「翻譯」成他人能理解的形式,例如文字、語音和圖像。目前而言,研究者關注的大腦訊號主要有三種:侵入式腦機介面、腦波(brain wave)和神經影像(neuroimaging)。
侵入式的腦機介面可以說賽博龐克作品的標配,你能在《賽博龐克2077》等許多電影或遊戲中看到它。其基本想法就是在大腦或神經系統中或附近讀取神經細胞之間傳遞的電訊號。相較於非侵入式的方法,侵入式讀取的大腦訊號通常準確度更高,雜訊也更低。
2021 年,在論文《Neuroprosthesis for Decoding Speech in a Paralyzed Person with Anarthria》中,加州大學舊金山分校的研究者提出使用AI 幫助有語音障礙的殘障人士交流。在該研究中,受試者是一位發音不清且獨臂的殘障人士。值得注意的是,他們在實驗中使用了一種神經植入物來獲取訊號,該植入物組合使用了高密度皮質腦電圖電極陣列和一個經過皮膚的連接器。這種侵入式的方法自然具備更高的準確度 —— 能達到最高 98% 的準確度和 75% 的中位數解碼率,該模型的解碼速度可達到最高每分鐘 18 個字。除此之外,語言模型的應用也大幅提升了解碼結果的意義表達,不再只是簡單的字串堆積。在
之後,團隊在2022 年的Nature Neuroscience 論文《Generalizable spelling using a speech neuroprosthesis in an individual with severe limb and vocal paralysis》中進一步改進了他們的系統,整合了新興的語言模型GPT,使性能得到了進一步提升。
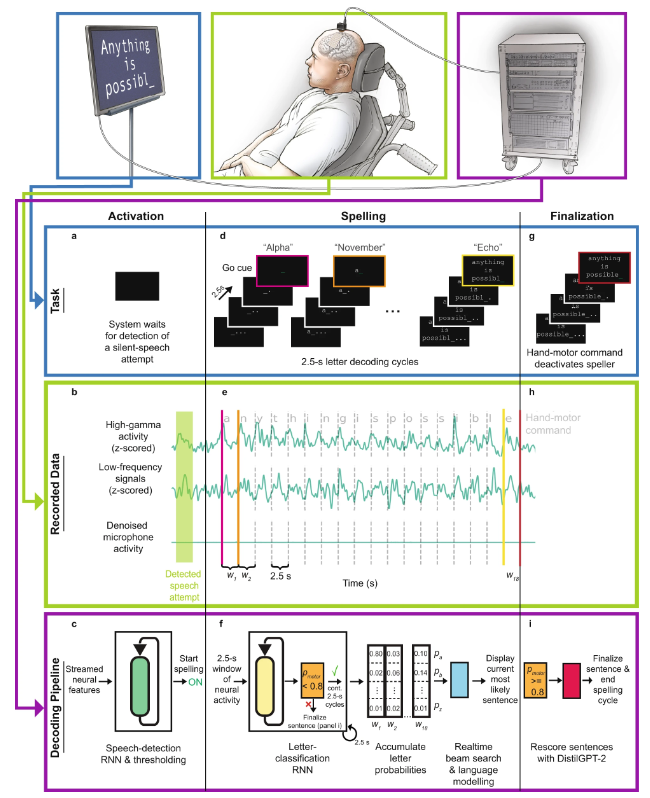
#直接語音腦機介面工作流程示意圖
具體來說,其工作流程為:
另一個植入式腦-機介面的研究聲稱成功實現了高效的手寫文字辨識和腦電訊號轉化為文字的功能。在Nature 論文《High-performance brain-to-text communication via handwriting》,史丹佛大學的研究者成功讓脊椎損傷的癱瘓人士能以每分鐘90 字符的速度打字,並且在線原始準確度達到了94.1%,使用了語言模型的離線準確度更是超過99%!
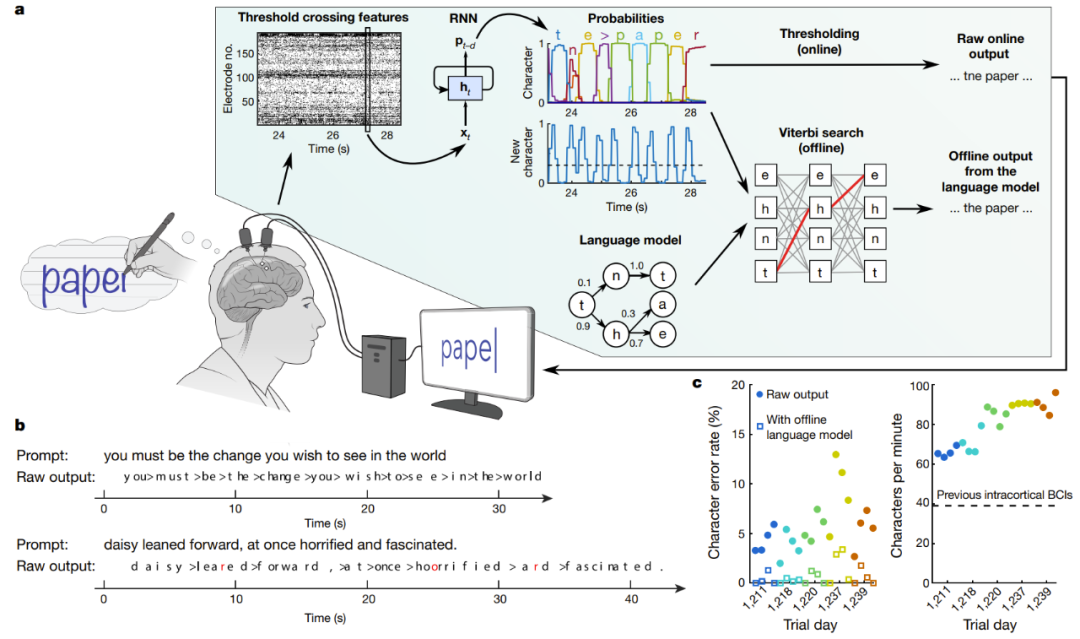
即時解碼受試者嘗試手寫的大腦訊號
#圖中a 是解碼演算法的示意圖。首先,每個電極上的神經活動被暫時合併及平滑化。然後,使用 RNN 將神經群體時間序列轉換成機率時間序列,其描述了每個字元的可能性和任何新字元開始的機率。該 RNN 有 1 秒的輸出延遲(d),讓其在確定字元的身份之前有時間完整地觀察每個字元。最後,設定字元機率的閾值,為即時使用得到「原始線上輸出」(當新字元的機率在時間t 超過某個閾值時,就在時間t 0.3 秒給出最有可能的字元並將其展示在螢幕上)。在離線的回顧性分析中,研究者將字元機率與一個具有大詞彙庫的語言模型組合在一起,用以解碼參與者最有可能寫下的文本。
基於近幾十年腦科學的研究成果,我們知道大腦中神經細胞傳遞訊號過程中會有微小電流,這就會產生細微的電磁波動。當大量神經細胞同時運作時,可使用非侵入式的精密儀器捕捉到這些電磁波動。 1875 年,科學家首次在動物身上觀察到了一種流動的電場現象,即腦波。 1925 年,Hans Berger 發明了腦電圖(EEG),並首次記錄了人類大腦的電活動現象。此後的近百年裡,EEG 技術不斷改進,其精度和實時性能都已經達到了相當高的程度並已得到了商業應用,現在你甚至能買到便攜式的腦波檢測分析設備。
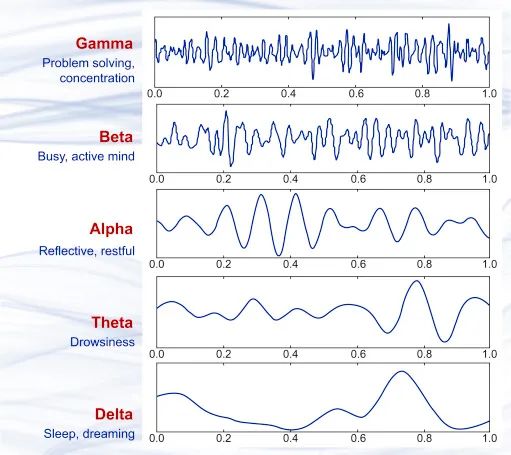
幾種不同的腦波波形樣本,從上到下依序為γ 波(35Hz 以上)、β 波(12-35 Hz)、α 波(8-12 Hz)、θ 波(4-8 Hz)、δ 波(0.5-4 Hz),它們分別大致於不同的大腦狀態。
#透過腦波來分析人的情緒和想法方面,最常見的方法是分析 P300 波,即受試者的大腦在看到刺激物後大約 300 毫秒時產生的腦波。解析腦波的研究在腦波被發現以後就一直沒有中斷,例如2001 年,該領域頗具爭議的研究者Lawrence Farwell 提出了一種演算法,可以透過評估腦波響應來檢測受試者是否經歷過某個事件,並且即便受試者試圖隱瞞也無濟於事。也就是說,這是一種基於腦波的測謊儀。
由於腦波本身是一種具備模式的訊號,因此使用神經網路來分析腦波也就成了自然而然的事情。以下我們將透過一些近年來的研究介紹科學們正透過什麼方法來將腦波訊號翻譯成語音、文字和圖像。
2019 年,俄羅斯一個研究團隊提出了一個視覺腦機介面(BCI)系統,可基於腦波來重建影像。其研究想法很直接,就是從腦電波訊號提取特徵,然後提取特徵向量,再進行映射,找到特徵在隱藏空間中的位置,最後解碼重建出影像。其中,圖像解碼器是用了一個圖像到圖像卷積自動編碼器模型的一部分,包含1 個全連接輸入層,之後是5 個去卷積模組,每個模組都由1 個去卷積層和ReLU 活化組成,而最後一個模組的活化是雙曲正切激活層。
此模型另一個重要元件是 EEG 特徵映射器,其功能是將資料從 EEG 特徵域轉譯到影像解碼器的隱藏空間域。團隊在模型中運用了LSTM作為循環單元,並且採用注意力機制進行進一步細化。其損失函數是最小化 EEG 和影像的特徵表徵之間的均方誤差。詳情請參閱他們的論文《Natural image reconstruction from brain waves: a novel visual BCI system with native feedback》。
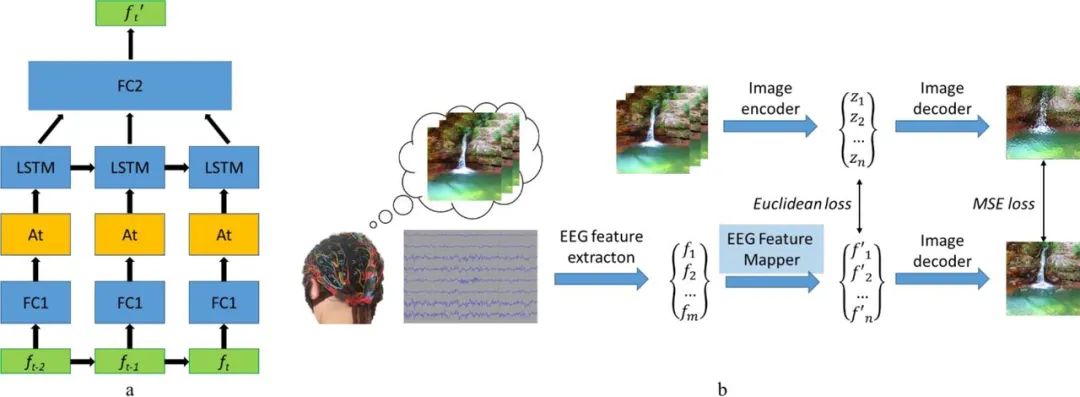
EEG 特徵映射器的模型結構(a) 與訓練程式(b)
以下是一些範例結果,可以看出重建影像與原始影像之間有顯著關聯。

受試者看到的原始影像(每對圖左)以及根據受試者腦波重建的圖像(每對圖右)
2022 年,Meta AI 團隊在論文《Decoding speech from non-invasive brain recordings》提出了一種可從腦電圖(EEG)或腦磁圖(MEG)訊號解碼出語音訊號的神經網路架構。
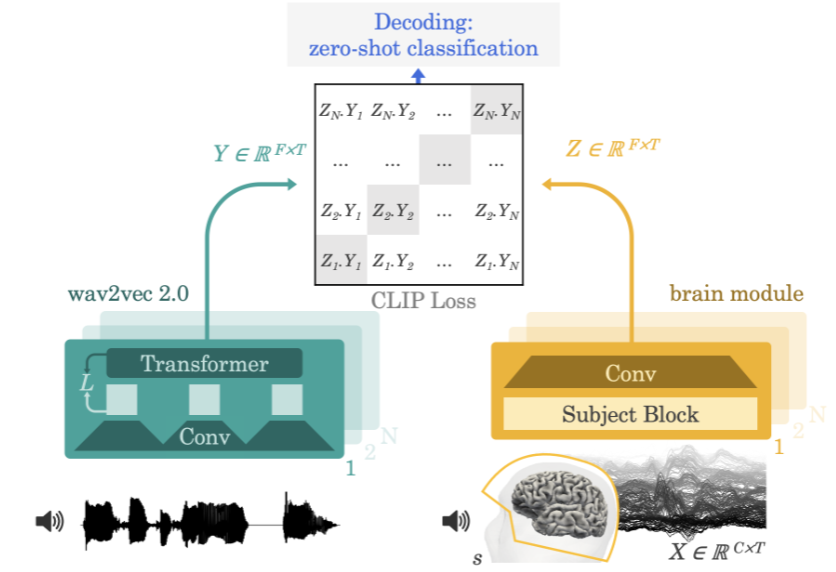
Meta AI 團隊的方法示意圖
團隊採用的方法是讓實驗參與者一邊聽故事或句子一邊記錄大腦活動的腦電圖或腦磁圖。為此,該模型首先會透過一個預訓練自監督模型(wav2vec 2.0)提取3 秒語音訊號(Y)的深度情境表徵,同時還會學習相應對齊的3 秒視窗(X)中的大腦活動的表徵(Z)。表徵 Z 是由一個深度卷積網絡給出的。在評估時,研究者向模型輸入剩餘的句子,並根據每個大腦表徵計算出每段 3 秒的語言片段。由此,這樣的解碼過程可以做到 zero-shot,讓模型可以預測出訓練集不曾有的音訊片段。
科學家還能使用一種名為功能性磁振造影(fMRI)的技術來了解大腦的活動情況。這項技術誕生於 1990 年代初期,其工作機制是透過磁振造影觀察大腦中的血液流動來檢測大腦活動。此技術能揭示大腦中特定功能區是否活躍。
當我們說某個大腦區域「更活躍」時,我們指的是什麼呢? fMRI 又是如何檢測這種活動的?
當一個大腦區域中的神經元開始發出比之前更多的電訊號時,我們就說這個大腦區域更活躍了。舉個例子,如果你在抬腿時某個特定的大腦區域變得更加活躍,那麼你就可以認為這片大腦區域負責控制抬腿動作。
fMRI 是透過檢測血液中的含氧水平來檢測這種電活動。這被稱為血氧水平依賴(BOLD)反應。其運作方式為:當神經元更活躍時,就會需要紅血球提供更多氧。為此,周圍的血管就會變寬以便讓更多血液流過。所以,當神經元更活躍時,氧濃度就會上升。相較於脫氧血液,含氧血液產生的場幹擾更少,這讓神經元的訊號(其實就是水中的氫)能持續更久。所以當訊號留存時間更長時,fMRI 就知道該區域有更多氧,也表示這裡更活躍。用顏色編碼這種活動之後,就能得到 fMRI 影像。
接下來我們就來看看前文提到的使用 GPT 重建出語意相符的連續語句的研究《Semantic reconstruction of continuous language from non-invasive brain recordings》。他們提出了一種非侵入式的解碼器,可以根據 fMRI 記錄中語義含義的大腦皮質表徵而重建出連續的自然語言。當出現新的大腦記錄時,該解碼器能產生可理解的詞序列,其能復現受試者聽到的語音、想像的語音甚至無聲視頻中的含義,這表明單一語言解碼器可以應用於一系列不同的語意任務。此語言解碼器的工作流程如下:
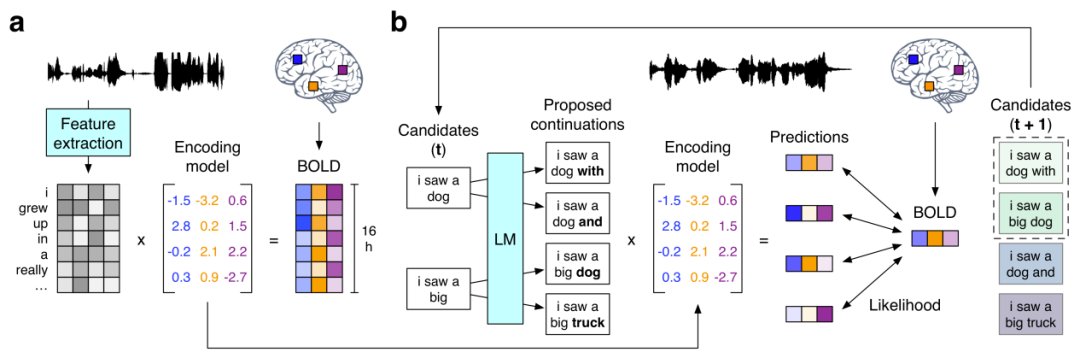
#(a) 當三位受試者聽16 小時的敘事故事時所記錄的BOLD fMRI 反應。系統為每位受試者都估計了一個編碼模型,以預測作為刺激物的詞的語義特徵所引發的大腦反應。 (b) 為了基於全新的大腦記錄重建語言,解碼器維持一個候選詞序列集合。當偵測到新的單字時,會有一個語言模型為每個序列提議連續性,然後會用該編碼模型評估每種連續條件下所記錄大腦反應的可能性。最後保留最可能的連續序列。
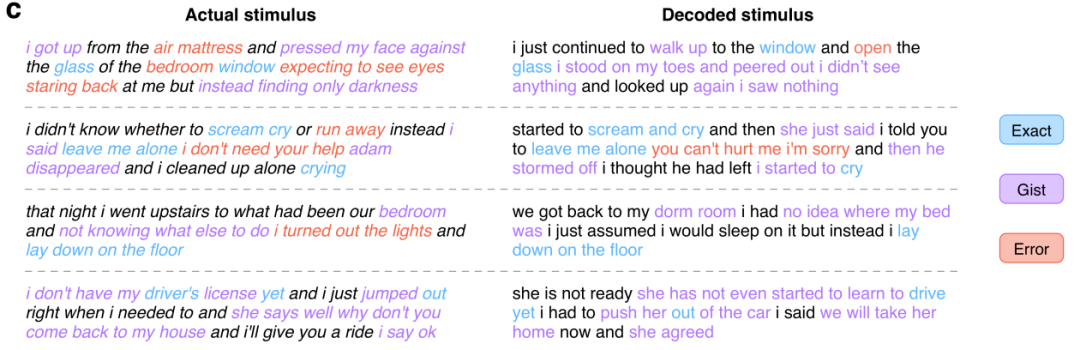
在這其中,語言模型所使用的正是現處於 AI 領域研究核心的 GPT 模型。研究者在一個大型語料庫上對所用 GPT 進行了微調,該語料庫包含超過 2 億字 Reddit 評論以及來自 The Moth Radio Hour 和 Modern Love 的 240 個自傳故事。模型訓練了 50 epoch,最大上下文長度為 100。以下展示了一些實驗結果:
#最後我們再來看看這篇CVPR 2023 論文《Seeing Beyond the Brain : Conditional Diffusion Model with Sparse Masked Modeling for Vision Decoding》。來自新加坡國立大學、香港中文大學和史丹佛大學的研究者宣稱他們提出的MinD-Vis 模型首次實現了將基於fMRI 的大腦活動信號解碼成圖像的成就,並且重建的圖像不僅細節豐富而且還包含準確的語義和圖像特徵(紋理和形狀等)。
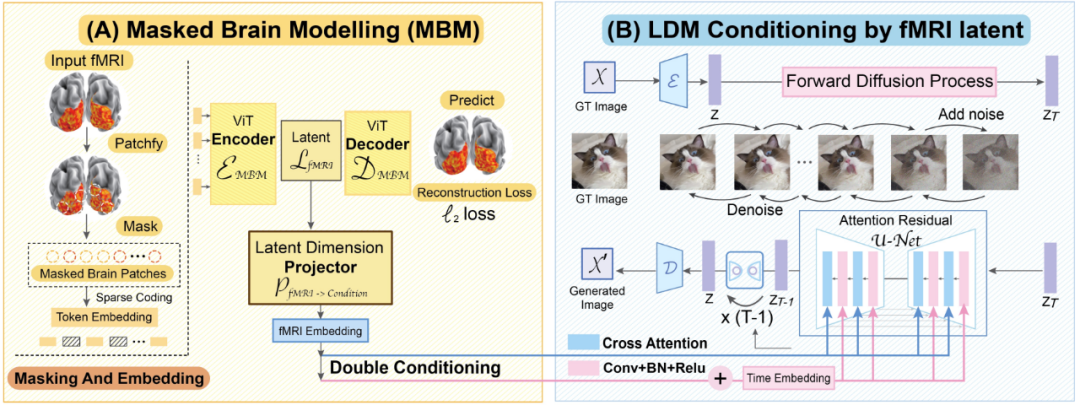
MinD-Vis 工作流程示意圖
我們來看看MinD-Vis 的兩個工作階段。如圖所示,在 A 階段,使用 SC-MBM(稀疏編碼的遮罩大腦建模)在 fMRI 上進行預訓練。然後為 fMRI 隨機加掩碼,再將它們 token 化成大型嵌入。研究者訓練了一個自動編碼器來恢復被掩蓋的圖塊。在 B 階段,透過雙條件(double conditioning)與隱含擴散模型(LDM)整合。使用一個隱含維度投射演算法,透過兩條路徑將 fMRI 隱含空間投射到 LDM 條件空間。其中一條路徑是直接連接 LDM 中的交叉注意力頭。另一條路徑是將 fMRI 隱含量加到時間嵌入。
從論文給出的實驗結果看,這個模型的讀心能力確實非常不錯:

其中左圖是受試者看到的原始圖片,紅框標記了MinD-Vis 的重建結果,而後面三列是其它方法的結果。
隨著資料量的成長和演算法的改進,人工智慧正在越來越深刻地理解我們這個世界,而我們人類作為這個世界的一部分自然也是被理解的對象—— 透過發掘人類大腦的活動模式,機器正在獲得從底層理解人類所思所想的能力。也許未來某一天,AI 能夠成為真正的讀心大師,甚至可能也將具備高保真捕捉人類夢境的能力!
上文只是簡單介紹了AI 在直接讀心方面的一些近期研究成果,而實際上已經有一些公司開始致力於相關技術的商業化,比如以Neuralink 和Blackrock Neurotech 為代表的腦機介面和神經科技公司,它們未來的潛在產品將具有令人興奮的應用前景,例如幫助無法表達的殘障人士重建與世界的聯繫、遠端操控在深海和太空等危險區域作業的機器。同時,這些技術的發展也讓許多人看到了破解人類意識之謎的希望。
當然,這類技術也引發了不少人關於隱私、安全和道德倫理的擔憂,畢竟我們已經在許多電影或小說中看到這類技術被使用於邪惡目的了。如今,這類技術的進一步發展已經不可避免,因此如何確保這些技術與人類的利益保持一致就成了需要所有相關人士和政策制定者思考和討論的重要問題。
以上是腦機介面、腦波和fMRI,AI正在掌握讀心術的詳細內容。更多資訊請關注PHP中文網其他相關文章!






















