

生成影片如此簡單,給句提示就行,還能在線上試玩

你輸入文字,讓 AI 來生成視頻,這種想法在以前只出現在人們的想像中,現在,隨著技術的發展,這種功能已經實現了。
近年來,生成式人工智慧在電腦視覺領域引起巨大的關注。隨著擴散模型的出現,從文字 Prompt 產生高品質影像,即文字到影像的合成,已經變得非常流行和成功。
最近的研究試圖透過在影片領域重複文字到圖像擴散模型,將其成功擴展到文字到影片生成和編輯的任務。雖然這樣的方法取得了可喜的成果,但大部分方法都需要使用大量標記資料進行大量訓練,這可能對許多用戶來說太過昂貴。
為了讓影片產生更廉價,Jay Zhangjie Wu 等人去年提出的Tune-A-Video 引入了一種機制,可以將Stable Diffusion (SD) 模型應用到影片領域。只需要調整一個視頻,從而讓訓練工作量大大減少。雖然這比以前的方法效率提升很多,但仍需要進行最佳化。此外,Tune-A-Video 的生成能力僅限於 text-guided 的影片編輯應用,而從頭開始合成影片仍然超出了它的能力範圍。
本文中,來自Picsart AI Resarch (PAIR) 、德州大學奧斯汀分校等機構的研究者在zero-shot 以及無需訓練的情況下,在文字到影片合成的新問題方向上向前邁進了一步,即無需任何優化或微調的情況下根據文字提示生成視訊。

- #論文網址:https://arxiv.org/ pdf/2303.13439.pdf
- #專案網址:https://github.com/Picsart-AI-Research/Text2Video-Zero
- #試用網址:https://huggingface.co/spaces/PAIR/Text2Video-Zero
下面我們看看效果如何。例如一隻熊貓在衝浪;一隻熊在時代廣場上跳舞:

#該研究還能根據目標生成動作:

此外,也能進行邊緣偵測:

本文提出的方法的一個關鍵概念是修改預訓練的文字到圖像模型(例如Stable Diffusion),透過時間一致的生成來豐富它。透過建立在已經訓練好的文本到圖像模型的基礎上,本文的方法利用它們出色的圖像生成質量,增強了它們在視頻領域的適用性,而無需進行額外的訓練。
為了加強時間一致性,本文提出兩個創新修改:(1)首先用運動資訊豐富產生幀的潛在編碼,以保持全局場景和背景時間一致;(2 ) 然後使用跨幀注意力機制來保留整個序列中前景物件的上下文、外觀和身分。實驗表明,這些簡單的修改可以產生高品質和時間一致的影片(如圖 1 所示)。

儘管其他人的工作是在大規模視訊資料上進行訓練,但本文的方法實現了相似甚至有時更好的性能(如圖 8、9 所示)。

本文的方法不僅限於文字到影片的合成,也適用於有條件的(見圖6、5)和專門的影片產生(見圖7),以及instruction-guided 的影片編輯,可以稱其為由Instruct-Pix2Pix 驅動的Video Instruct-Pix2Pix(見圖9)。 

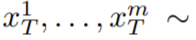 在這篇論文中,本文利用Stable Diffusion (SD)的文本到圖像合成能力來處理zero-shot 情況下文本到視頻的任務。針對視訊生成而非影像生成的需求,SD 應專注於潛在程式碼序列的操作。樸素的方法是從標準高斯分佈獨立取樣m 個潛在程式碼,即
在這篇論文中,本文利用Stable Diffusion (SD)的文本到圖像合成能力來處理zero-shot 情況下文本到視頻的任務。針對視訊生成而非影像生成的需求,SD 應專注於潛在程式碼序列的操作。樸素的方法是從標準高斯分佈獨立取樣m 個潛在程式碼,即
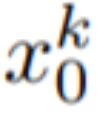
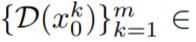
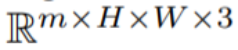
。然而,如圖 10 的第一行所示,這會導致完全隨機的圖像生成,僅共享

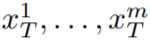
為了解決這個問題,本文建議採用以下兩種方法:(i)在潛在編碼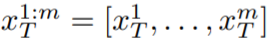 #之間引入運動動態,以保持全域場景的時間一致性;(ii)使用跨幀注意力機制來保留前景物件的外觀和身分。下面詳細描述了本文使用的方法的每個組成部分,該方法的概述可以在圖 2 中找到。
#之間引入運動動態,以保持全域場景的時間一致性;(ii)使用跨幀注意力機制來保留前景物件的外觀和身分。下面詳細描述了本文使用的方法的每個組成部分,該方法的概述可以在圖 2 中找到。
注意,為了簡化符號,本文將整個潛在程式碼序列表示為:
##實驗
################## ########定性結果###############Text2Video-Zero 的所有應用都表明它成功生成了視頻,其中全局場景和背景具有時間一致性,前景物件的上下文、外觀和身分在整個序列中都得到了保持。 ######
在文字轉影片的情況下,可以觀察到它產生與文字提示良好對齊的高品質影片(見圖 3)。例如,繪製的熊貓可以自然地在街上行走。同樣,使用額外的邊緣或姿勢指導 (見圖 5、圖 6 和圖 7),生成了與 Prompt 和指導相匹配的高質量視頻,顯示出良好的時間一致性和身份保持。

#在Video Instruct-Pix2Pix(見圖1)的情況下,產生的視頻相對於輸入影片具有高保真,同時嚴格遵循指令。
與Baseline 比較
#本文將其方法與兩個公開可用的baseline 進行比較:CogVideo 和Tune -A-Video。由於 CogVideo 是一種文字到影片的方法,本文在純文字引導的影片合成場景中與它進行了比較;使用 Video Instruct-Pix2Pix 與 Tune-A-Video 進行比較。
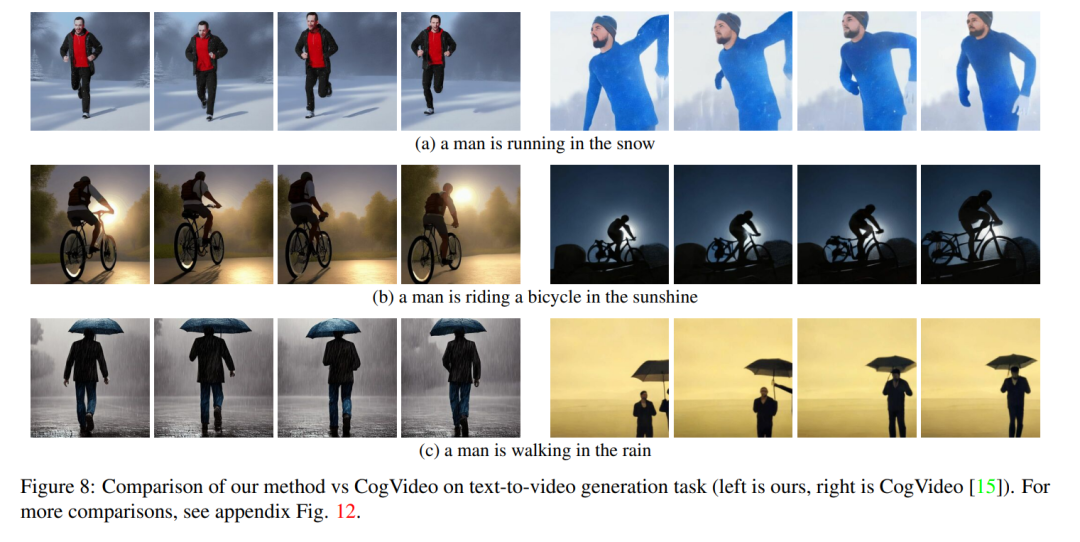
為了進行定量對比,本文使用 CLIP 分數對模型評估,CLIP 分數表示視訊文字對齊程度。透過隨機獲取 CogVideo 生成的 25 個視頻,並根據本文的方法使用相同的提示合成相應的視頻。本文的方法和 CogVideo 的 CLIP 分數分別為 31.19 和 29.63。因此,本文的方法略優於 CogVideo,儘管後者有 94 億個參數並且需要對影片進行大規模訓練。
圖 8 展示了本文提出的方法的幾個結果,並提供了與 CogVideo 的定性比較。這兩種方法在整個序列中都顯示出良好的時間一致性,保留了物件的身份以及背景。本文的方法顯示出更好的文字 - 視訊對齊能力。例如,本文的方法在圖 8 (b) 中正確生成了一個人在陽光下騎自行車的視頻,而 CogVideo 將背景設置為月光。同樣在圖 8 (a) 中,本文的方法正確地顯示了一個人在雪地裡奔跑,而 CogVideo 生成的影片中雪地和奔跑的人是看不清楚的。
Video Instruct-Pix2Pix 的定性結果以及與 per-frame Instruct-Pix2Pix 和 Tune-AVideo 在視覺上的比較如圖 9 所示。雖然 Instruct-Pix2Pix 每幀顯示出良好的編輯效能,但它缺乏時間一致性。這在描繪滑雪者的影片中尤其明顯,影片中的雪和天空使用不同的樣式和顏色繪製。使用 Video Instruct-Pix2Pix 方法解決了這些問題,從而在整個序列中實現了時間上一致的影片編輯。
雖然Tune-A-Video 創建了時間一致的影片生成,但與本文的方法相比,它與指令指導的一致性較差,難以創建本地編輯,並遺失了輸入序列的細節。當看到圖 9 左側中描繪的舞者影片的編輯時,這一點變得顯而易見。與 Tune-A-Video 相比,本文的方法將整件衣服畫得更亮,同時更好地保留了背景,例如舞者身後的牆幾乎保持不變。 Tune-A-Video 繪製了一堵經過嚴重變形的牆。此外,本文的方法更忠實於輸入細節,例如,與Tune-A-Video 相比,Video Instruction-Pix2Pix 使用所提供的姿勢繪製舞者(圖9 左),並顯示輸入影片中出現的所有滑雪人員(如圖9 右側的最後一格所示)。 Tune-A-Video 的所有上述弱點也可以在圖 23、24 中觀察到。


以上是生成影片如此簡單,給句提示就行,還能在線上試玩的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 抖音發布他人影片侵權嗎?它怎麼剪輯影片不算侵權?
Mar 21, 2024 pm 05:57 PM
抖音發布他人影片侵權嗎?它怎麼剪輯影片不算侵權?
Mar 21, 2024 pm 05:57 PM
隨著短影片平台的興起,抖音成為了大家日常生活中不可或缺的一部分。在抖音上,我們可以看到來自世界各地的有趣影片。有些人喜歡發布他人的視頻,這就引發了一個問題:抖音發布他人視頻侵權嗎?本文將圍繞這個問題展開討論,告訴大家怎樣剪輯影片不算侵權,以及如何避免侵權問題。一、抖音發布他人影片侵權嗎?根據我國《著作權法》的規定,未經著作權人許可,擅自使用其作品,屬於侵權行為。因此,在抖音上發布他人視頻,如果未經原作者或著作權人許可,就屬於侵權行為。二、怎樣剪輯影片不算侵權? 1.使用公共領域或授權的內容:公共
 如何發布小紅書影片作品?發影片要注意什麼?
Mar 23, 2024 pm 08:50 PM
如何發布小紅書影片作品?發影片要注意什麼?
Mar 23, 2024 pm 08:50 PM
隨著短影片平台的興起,小紅書成為了許多人分享生活、表達自我、獲取流量的平台。在這個平台上,發布影片作品是一種非常受歡迎的互動方式。那麼,如何發布小紅書影片作品呢?一、如何發布小紅書影片作品?首先,確保準備好一段適合分享的影片內容。你可以利用手機或其他攝影設備拍攝,需要注意畫質和聲音的清晰度。 2.剪輯影片:為了讓作品更具吸引力,可以剪輯影片。可使用專業的影片剪輯軟體,如抖音、快手等,加入濾鏡、音樂、字幕等元素。 3.選擇封面:封面是吸引用戶點擊的關鍵,選擇一張清晰、有趣的圖片作為封面,讓
 微博發影片怎麼不壓縮畫質_微博發影片不壓縮畫質方法
Mar 30, 2024 pm 12:26 PM
微博發影片怎麼不壓縮畫質_微博發影片不壓縮畫質方法
Mar 30, 2024 pm 12:26 PM
1.先打開手機微博,點選右下角【我】(如圖所示)。 2、接著點選右上角【齒輪】打開設定(如圖所示)。 3.然後找到並開啟【通用設定】(如圖所示)。 4.隨後進入【影片隨著】選項(如圖所示)。 5.再開啟【影片上傳清晰度】設定(如圖)。 6.最後選擇【原畫質】就能不壓縮了(如圖)。
 抖音發布影片如何賺收益?新手小白怎麼在抖音上賺錢啊?
Mar 21, 2024 pm 08:17 PM
抖音發布影片如何賺收益?新手小白怎麼在抖音上賺錢啊?
Mar 21, 2024 pm 08:17 PM
抖音,這個全民短視頻平台,不僅讓我們在閒暇時間享受到各種有趣、新奇的短視頻,同時也給了我們一個展示自我、實現價值的舞台。那麼,如何在抖音發布影片中賺取收益呢?本文將詳細解答這個問題,幫助你在抖音上賺取更多的收益。一、抖音發布影片如何賺收益?發布影片在抖音上獲得一定的播放量後,可以有機會參與廣告分成計畫。這項收益方式是抖音用戶最熟悉的之一,也是許多創作者主要的收入來源。抖音根據帳號權重、影片內容以及觀眾回饋等多種因素來決定是否提供廣告分成的機會。抖音平台允許觀眾透過發送禮物來支持自己喜歡的創作者,
 四款值得推薦的AI輔助程式工具
Apr 22, 2024 pm 05:34 PM
四款值得推薦的AI輔助程式工具
Apr 22, 2024 pm 05:34 PM
這個AI輔助程式工具在這個AI快速發展的階段,挖掘出了一大批好用的AI輔助程式工具。 AI輔助程式設計工具能夠提升開發效率、提升程式碼品質、降低bug率,是現代軟體開發過程中的重要助手。今天大姚給大家分享4款AI輔助程式工具(而且都支援C#語言),希望對大家有幫助。 https://github.com/YSGStudyHards/DotNetGuide1.GitHubCopilotGitHubCopilot是一款AI編碼助手,可幫助你更快、更省力地編寫程式碼,從而將更多精力集中在問題解決和協作上。 Git
 抖音15秒太短想延長怎麼延長? 15秒以上影片怎麼弄?
Mar 22, 2024 pm 08:11 PM
抖音15秒太短想延長怎麼延長? 15秒以上影片怎麼弄?
Mar 22, 2024 pm 08:11 PM
隨著抖音的火爆,越來越多的人喜歡在這個平台上分享自己的生活、才藝和創意。抖音的15秒時長限制讓許多使用者覺得不夠過癮,希望能夠延長影片時長。那麼,如何才能在抖音上實現影片長度的延長呢?一、抖音15秒太短想延長怎麼延長? 1.拍攝多個視頻拼接最便捷的方式是錄製多個15秒的視頻,接著利用抖音的編輯功能將它們組合在一起。在錄製時,請確保每段影片的開頭和結尾都留有一些空白,以便後續拼接。拼接後的影片長度可以達到幾分鐘,但這可能會導致影片畫面切換過於頻繁,影響觀看體驗。 2.利用抖音特效和貼紙抖音提供了一系列特效
 CNN、Transformer、Uniformer之外,我們終於有了更有效率的影片理解技術
Mar 25, 2024 am 09:16 AM
CNN、Transformer、Uniformer之外,我們終於有了更有效率的影片理解技術
Mar 25, 2024 am 09:16 AM
影片理解的核心目標是準確理解時空表示,但面臨兩個主要挑戰:短影片片段中存在大量時空冗餘,且複雜的時空依賴關係。三維卷積神經網路(CNN)和影片Transformer曾在解決其中一個挑戰方面表現出色,但它們在同時應對這兩個挑戰時存在一定不足。 UniFormer嘗試結合這兩種方法的優勢,但在建模長影片方面遇到了困難。 S4、RWKV和RetNet等低成本方案在自然語言處理領域的出現,為視覺模型開闢了新的途徑。 Mamba憑藉其選擇性狀態空間模型(SSM)脫穎而出,實現了在保持線性複雜性的同時促進長期動
 AI程式設計師哪家強?探索Devin、通靈靈碼和SWE-agent的潛力
Apr 07, 2024 am 09:10 AM
AI程式設計師哪家強?探索Devin、通靈靈碼和SWE-agent的潛力
Apr 07, 2024 am 09:10 AM
2022年3月3日,距離世界首個AI程式設計師Devin誕生不足一個月,普林斯頓大學的NLP團隊開發了一個開源AI程式設計師SWE-agent。它利用GPT-4模型在GitHub儲存庫中自動解決問題。 SWE-agent在SWE-bench測試集上的表現與Devin相似,平均耗時93秒,解決了12.29%的問題。 SWE-agent透過與專用終端交互,可以開啟、搜尋文件內容,使用自動語法檢查、編輯特定行,以及編寫和執行測試。 (註:以上內容為原始內容微調,但保留了原文中的關鍵訊息,未超過指定字數限制。)SWE-A
