

Python3怎麼使用tracemalloc實現追蹤mmap記憶體變化

技術背景
在前面一篇部落格中我們介紹了一些用python3處理表格資料的方法,其中重點包含了vaex這樣一個大規模數據處理的方案。這個資料處理的方案是基於記憶體映射(memory map)的技術,透過創建記憶體映射檔案來避免在記憶體中直接載入來源資料而導致的大規模記憶體佔用問題,這使得我們可以在本地電腦記憶體規模並不是很大的條件下對大規模的數據進行處理。在Python 3中,存在一個名為mmap的函式庫,可用來直接建立記憶體映射檔。
用tracemalloc追蹤python程式記憶體佔用
這裡我們希望能夠比較記憶體映射技術的實際記憶體佔用,因此我們需要引入一個基於python的記憶體追蹤工具:tracemalloc。我們先舉一個簡單的例子,即建立一個隨機數組,然後觀察該數組所佔用的記憶體大小
# tracem.py
import tracemalloc
import numpy as np
tracemalloc.start()
length=10000
test_array=np.random.randn(length) # 分配一个定长随机数组
snapshot=tracemalloc.take_snapshot() # 内存摄像
top_stats=snapshot.statistics('lineno') # 内存占用数据获取
print ('[Top 10]')
for stat in top_stats[:10]: # 打印占用内存最大的10个子进程
print (stat)輸出結果如下:
##[dechin@dechin-manjaro mmap ]$ python3 tracem.py假如我們是使用top指令來直接偵測記憶體的話,毫無疑問佔記憶體最高的還是Google瀏覽器:[Top 10]
tracem.py:8: size=78.2 KiB, count=2, average=39.1 KiB
top - 10:04:08 up 6 days, 15:18, 5 users, load average: 0.23 , 0.33, 0.27因為這幾乎就是10000個float32浮點數的記憶體佔用大小,這表示所有的元素都已經儲存在記憶體中。任務: 309 total, 1 running, 264 sleeping, 23 stopped, 21 zombie##%Cpu(s): 0.6 us, 21 zombie##%Cpu(s): 0.6 us, 0.2 sy, 0.0。 used. 36775.8 avail Mem
Out[3]: 10009.6
進程號USER PR NI VIRT RES SHR %CPU %MEM TIME COMMAND 175832 117544 S 4.0 0.4 1:02.32 chromium
因此根據進程編號來追蹤子進程的記憶體佔用才是使用tracemalloc的一個重點,這裡我們發現一個10000大小的numpy向量的記憶體佔用約為39.1 KiB,這其實是符合我們的預期的:
##In [3]: 39.1* 1024/4
用tracemalloc追蹤記憶體變化
在上面一個章節中我們介紹了snapshot記憶體快照的使用方法,那麼我們很容易可以想到,透過「拍攝」兩張記憶體快照,然後對比一下快照中的變化,不就可以得到記憶體變化的大小麼?接下來做一個簡單嘗試:
# comp_tracem.py
import tracemalloc
import numpy as np
tracemalloc.start()
snapshot0=tracemalloc.take_snapshot() # 第一张快照
length=10000
test_array=np.random.randn(length)
snapshot1=tracemalloc.take_snapshot() # 第二张快照
top_stats=snapshot1.compare_to(snapshot0,'lineno') # 快照对比
print ('[Top 10 differences]')
for stat in top_stats[:10]:
print (stat)執行結果如下:
[dechin@dechin-manjaro mmap]$ python3 comp_tracem.py[Top 10 differences]
comp_tracem.py:9: size=78.2 KiB ( 78.2 KiB), count=2 ( 2), average=39.1 KiB#可以看到這個快照前後的平均記憶體大小差異就是在39.1 KiB,假如我們把向量的維度改為1000000:[dechin@dechin-manjaro mmap]$ python3 comp_tracem.pylength=1000000登入後複製
再執行一遍看看效果:
#[Top 10 differences]
comp_tracem.py:9: size=7813 KiB ( 7813 KiB), count=2 ( 2), average=3906 KiB我們發現結果是3906,相當於放大了100倍,是比較符合預期的。當然如果我們仔細去算一下:#我們發現這裡面並不完全是float32的類型,相比於完全的float32類型缺失了一部分內存大小,這裡懷疑是否是中間產生了一些0,被自動的壓縮了大小?不過這個問題並不是我們要重點關注的,我們繼續向下測試記憶體的變化曲線。Out[4]: 999936.0
In [4]: 3906*1024/4
記憶體佔用曲線
延續前面兩個章節的內容,我們主要測試一下不同維度的隨機數組所需要佔用的記憶體空間,在上述程式碼模組的基礎上增加了一個for循環:
# comp_tracem.py
import tracemalloc
import numpy as np
tracemalloc.start()
x=[]
y=[]
multiplier={'B':1,'KiB':1024,'MiB':1048576}
snapshot0=tracemalloc.take_snapshot()
for length in range(1,1000000,100000):
np.random.seed(1)
test_array=np.random.randn(length)
snapshot1=tracemalloc.take_snapshot()
top_stats=snapshot1.compare_to(snapshot0,'lineno')
for stat in top_stats[:10]:
if 'comp_tracem.py' in str(stat): # 判断是否属于当前文件所产生的内存占用
x.append(length)
mem=str(stat).split('average=')[1].split(' ')
y.append(float(m曲线em[0])*multiplier[mem[1]])
break
import matplotlib.pyplot as plt
plt.figure()
plt.plot(x,y,'D',color='black',label='Experiment')
plt.plot(x,np.dot(x,4),color='red',label='Expect') # float32的预期占用空间
plt.title('Memery Difference vs Array Length')
plt.xlabel('Number Array Length')
plt.ylabel('Memory Difference')
plt.legend()
plt.savefig('comp_mem.png')畫出來的效果圖如下所示:
#這裡我們又發現,雖然大部分情況下是符合記憶體佔用預期的,但有很多個點比預期佔用的要少,我們懷疑是因為存在0元素,因此稍微修改了一下程式碼,在原程式碼的基礎上增加了一個操作來盡可能的避免0的出現:# comp_tracem.py
import tracemalloc
import numpy as np
tracemalloc.start()
x=[]
y=[]
multiplier={'B':1,'KiB':1024,'MiB':1048576}
snapshot0=tracemalloc.take_snapshot()
for length in range(1,1000000,100000):
np.random.seed(1)
test_array=np.random.randn(length)
test_array+=np.ones(length)*np.pi # 在原数组基础上加一个圆周率,内存不变
snapshot1=tracemalloc.take_snapshot()
top_stats=snapshot1.compare_to(snapshot0,'lineno')
for stat in top_stats[:10]:
if 'comp_tracem.py' in str(stat):
x.append(length)
mem=str(stat).split('average=')[1].split(' ')
y.append(float(mem[0])*multiplier[mem[1]])
break
import matplotlib.pyplot as plt
plt.figure()
plt.plot(x,y,'D',color='black',label='Experiment')
plt.plot(x,np.dot(x,4),color='red',label='Expect')
plt.title('Memery Difference vs Array Length')
plt.xlabel('Number Array Length')
plt.ylabel('Memory Difference')
plt.legend()
plt.savefig('comp_mem.png')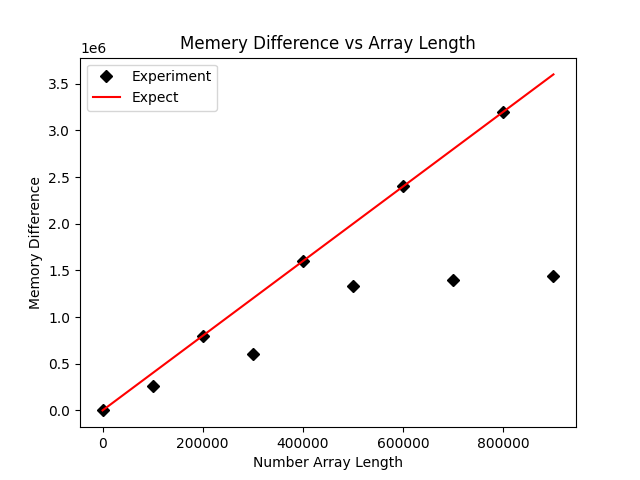
#
虽然不符合预期的点数少了,但是这里还是有两个点不符合预期的内存占用大小,疑似数据被压缩了。
mmap内存占用测试
在上面几个章节之后,我们已经基本掌握了内存追踪技术的使用,这里我们将其应用在mmap内存映射技术上,看看有什么样的效果。
将numpy数组写入txt文件
因为内存映射本质上是一个对系统文件的读写操作,因此这里我们首先将前面用到的numpy数组存储到txt文件中:
# write_array.py
import numpy as np
x=[]
y=[]
for length in range(1,1000000,100000):
np.random.seed(1)
test_array=np.random.randn(length)
test_array+=np.ones(length)*np.pi
np.savetxt('numpy_array_length_'+str(length)+'.txt',test_array)写入完成后,在当前目录下会生成一系列的txt文件:
-rw-r--r-- 1 dechin dechin 2500119 4月 12 10:09 numpy_array_length_100001.txt
-rw-r--r-- 1 dechin dechin 25 4月 12 10:09 numpy_array_length_1.txt
-rw-r--r-- 1 dechin dechin 5000203 4月 12 10:09 numpy_array_length_200001.txt
-rw-r--r-- 1 dechin dechin 7500290 4月 12 10:09 numpy_array_length_300001.txt
-rw-r--r-- 1 dechin dechin 10000356 4月 12 10:09 numpy_array_length_400001.txt
-rw-r--r-- 1 dechin dechin 12500443 4月 12 10:09 numpy_array_length_500001.txt
-rw-r--r-- 1 dechin dechin 15000526 4月 12 10:09 numpy_array_length_600001.txt
-rw-r--r-- 1 dechin dechin 17500606 4月 12 10:09 numpy_array_length_700001.txt
-rw-r--r-- 1 dechin dechin 20000685 4月 12 10:09 numpy_array_length_800001.txt
-rw-r--r-- 1 dechin dechin 22500788 4月 12 10:09 numpy_array_length_900001.txt
我们可以用head或者tail查看前n个或者后n个的元素:
[dechin@dechin-manjaro mmap]$ head -n 5 numpy_array_length_100001.txt
4.765938017253034786e+00
2.529836239939717846e+00
2.613420901326337642e+00
2.068624031433622612e+00
4.007000282914471967e+00
numpy文件读取测试
前面几个测试我们是直接在内存中生成的numpy的数组并进行内存监测,这里我们为了严格对比,统一采用文件读取的方式,首先我们需要看一下numpy的文件读取的内存曲线如何:
# npopen_tracem.py
import tracemalloc
import numpy as np
tracemalloc.start()
x=[]
y=[]
multiplier={'B':1,'KiB':1024,'MiB':1048576}
snapshot0=tracemalloc.take_snapshot()
for length in range(1,1000000,100000):
test_array=np.loadtxt('numpy_array_length_'+str(length)+'.txt',delimiter=',')
snapshot1=tracemalloc.take_snapshot()
top_stats=snapshot1.compare_to(snapshot0,'lineno')
for stat in top_stats[:10]:
if '/home/dechin/anaconda3/lib/python3.8/site-packages/numpy/lib/npyio.py:1153' in str(stat):
x.append(length)
mem=str(stat).split('average=')[1].split(' ')
y.append(float(mem[0])*multiplier[mem[1]])
break
import matplotlib.pyplot as plt
plt.figure()
plt.plot(x,y,'D',color='black',label='Experiment')
plt.plot(x,np.dot(x,8),color='red',label='Expect')
plt.title('Memery Difference vs Array Length')
plt.xlabel('Number Array Length')
plt.ylabel('Memory Difference')
plt.legend()
plt.savefig('open_mem.png')需要注意的一点是,这里虽然还是使用numpy对文件进行读取,但是内存占用已经不是名为npopen_tracem.py的源文件了,而是被保存在了npyio.py:1153这个文件中,因此我们在进行内存跟踪的时候,需要调整一下对应的统计位置。最后的输出结果如下:
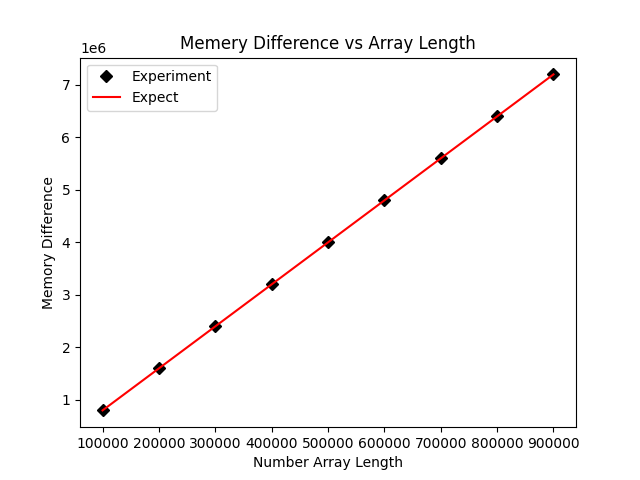
由于读入之后是默认以float64来读取的,因此预期的内存占用大小是元素数量×8,这里读入的数据内存占用是几乎完全符合预期的。
mmap内存占用测试
伏笔了一大篇幅的文章,最后终于到了内存映射技术的测试,其实内存映射模块mmap的使用方式倒也不难,就是配合os模块进行文件读取,基本上就是一行的代码:
# mmap_tracem.py
import tracemalloc
import numpy as np
import mmap
import os
tracemalloc.start()
x=[]
y=[]
multiplier={'B':1,'KiB':1024,'MiB':1048576}
snapshot0=tracemalloc.take_snapshot()
for length in range(1,1000000,100000):
test_array=mmap.mmap(os.open('numpy_array_length_'+str(length)+'.txt',os.O_RDWR),0) # 创建内存映射文件
snapshot1=tracemalloc.take_snapshot()
top_stats=snapshot1.compare_to(snapshot0,'lineno')
for stat in top_stats[:10]:
print (stat)
if 'mmap_tracem.py' in str(stat):
x.append(length)
mem=str(stat).split('average=')[1].split(' ')
y.append(float(mem[0])*multiplier[mem[1]])
break
import matplotlib.pyplot as plt
plt.figure()
plt.plot(x,y,'D',color='black',label='Experiment')
plt.title('Memery Difference vs Array Length')
plt.xlabel('Number Array Length')
plt.ylabel('Memory Difference')
plt.legend()
plt.savefig('mmap.png')运行结果如下:
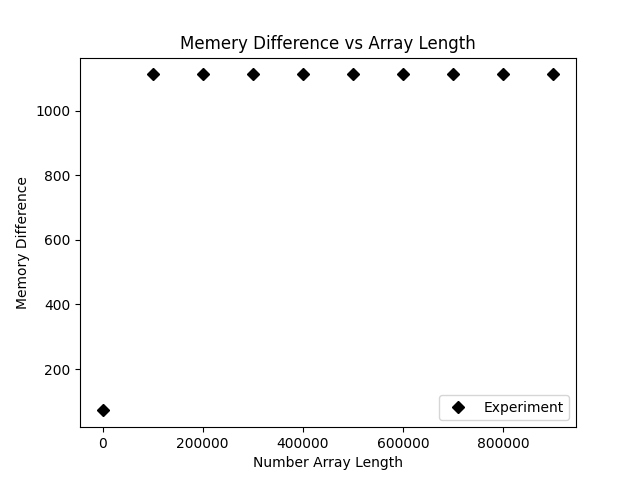
我们可以看到内存上是几乎没有波动的,因为我们并未把整个数组加载到内存中,而是在内存中加载了其内存映射的文件。我们能够以较小的内存开销读取文件中的任意字节位置。当我们去修改写入文件的时候需要额外的小心,因为对于内存映射技术来说,byte数量是需要保持不变的,否则内存映射就会发生错误。
以上是Python3怎麼使用tracemalloc實現追蹤mmap記憶體變化的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 PHP和Python:解釋了不同的範例
Apr 18, 2025 am 12:26 AM
PHP和Python:解釋了不同的範例
Apr 18, 2025 am 12:26 AM
PHP主要是過程式編程,但也支持面向對象編程(OOP);Python支持多種範式,包括OOP、函數式和過程式編程。 PHP適合web開發,Python適用於多種應用,如數據分析和機器學習。
 在PHP和Python之間進行選擇:指南
Apr 18, 2025 am 12:24 AM
在PHP和Python之間進行選擇:指南
Apr 18, 2025 am 12:24 AM
PHP適合網頁開發和快速原型開發,Python適用於數據科學和機器學習。 1.PHP用於動態網頁開發,語法簡單,適合快速開發。 2.Python語法簡潔,適用於多領域,庫生態系統強大。
 Python vs. JavaScript:學習曲線和易用性
Apr 16, 2025 am 12:12 AM
Python vs. JavaScript:學習曲線和易用性
Apr 16, 2025 am 12:12 AM
Python更適合初學者,學習曲線平緩,語法簡潔;JavaScript適合前端開發,學習曲線較陡,語法靈活。 1.Python語法直觀,適用於數據科學和後端開發。 2.JavaScript靈活,廣泛用於前端和服務器端編程。
 PHP和Python:深入了解他們的歷史
Apr 18, 2025 am 12:25 AM
PHP和Python:深入了解他們的歷史
Apr 18, 2025 am 12:25 AM
PHP起源於1994年,由RasmusLerdorf開發,最初用於跟踪網站訪問者,逐漸演變為服務器端腳本語言,廣泛應用於網頁開發。 Python由GuidovanRossum於1980年代末開發,1991年首次發布,強調代碼可讀性和簡潔性,適用於科學計算、數據分析等領域。
 vs code 可以在 Windows 8 中運行嗎
Apr 15, 2025 pm 07:24 PM
vs code 可以在 Windows 8 中運行嗎
Apr 15, 2025 pm 07:24 PM
VS Code可以在Windows 8上運行,但體驗可能不佳。首先確保系統已更新到最新補丁,然後下載與系統架構匹配的VS Code安裝包,按照提示安裝。安裝後,注意某些擴展程序可能與Windows 8不兼容,需要尋找替代擴展或在虛擬機中使用更新的Windows系統。安裝必要的擴展,檢查是否正常工作。儘管VS Code在Windows 8上可行,但建議升級到更新的Windows系統以獲得更好的開發體驗和安全保障。
 visual studio code 可以用於 python 嗎
Apr 15, 2025 pm 08:18 PM
visual studio code 可以用於 python 嗎
Apr 15, 2025 pm 08:18 PM
VS Code 可用於編寫 Python,並提供許多功能,使其成為開發 Python 應用程序的理想工具。它允許用戶:安裝 Python 擴展,以獲得代碼補全、語法高亮和調試等功能。使用調試器逐步跟踪代碼,查找和修復錯誤。集成 Git,進行版本控制。使用代碼格式化工具,保持代碼一致性。使用 Linting 工具,提前發現潛在問題。
 notepad 怎麼運行python
Apr 16, 2025 pm 07:33 PM
notepad 怎麼運行python
Apr 16, 2025 pm 07:33 PM
在 Notepad 中運行 Python 代碼需要安裝 Python 可執行文件和 NppExec 插件。安裝 Python 並為其添加 PATH 後,在 NppExec 插件中配置命令為“python”、參數為“{CURRENT_DIRECTORY}{FILE_NAME}”,即可在 Notepad 中通過快捷鍵“F6”運行 Python 代碼。
 vscode 擴展是否是惡意的
Apr 15, 2025 pm 07:57 PM
vscode 擴展是否是惡意的
Apr 15, 2025 pm 07:57 PM
VS Code 擴展存在惡意風險,例如隱藏惡意代碼、利用漏洞、偽裝成合法擴展。識別惡意擴展的方法包括:檢查發布者、閱讀評論、檢查代碼、謹慎安裝。安全措施還包括:安全意識、良好習慣、定期更新和殺毒軟件。
