

繞開算力限制,如何用單GPU微調 LLM?這是一份「梯度累積」演算法教程

自從大模型變成熱門趨勢後,GPU 就變成了緊俏的物資。很多企業的儲備不一定充足,更不用說個人開發者了。有沒有什麼方法可以更有效率的利用算力訓練模式?
在最近的一篇博客,Sebastian Raschka 介紹了「梯度累積」的方法,能夠在 GPU 記憶體受限時使用更大 batch size 訓練模型,繞過硬體限制。

在此之前,Sebastian Raschka 也分享過一篇運用多GPU 訓練策略加速大型語言模型微調的文章,包括模型或tensor sharding 等機制,這些機制將模型權重和計算分佈在不同的設備上,以解決GPU 的記憶體限制。
微調 BLOOM 模型進行分類
假設我們有興趣採用近期預訓練的大型語言模型來處理文字分類等下游任務。那麼,我們可能會選擇使用GPT-3 的開源替代品BLOOM 模型,特別是「僅有」 5.6 億個參數的BLOOM 版本—— 它應該可以毫無問題地融入到傳統GPU 的RAM 中(Google Colab 免費版本擁有15 Gb RAM 的GPU)。
一旦開始,就很可能遇到問題:記憶體會在訓練或微調期間迅速增加。訓練這個模型的唯一方法是讓批次大小為 1(batch size=1)。

使用批次大小為 1(batch size=1)為目標分類任務微調 BLOOM 的程式碼如下所示。你也可以在GitHub 專案頁面下載完整程式碼:
https://github.com/rasbt/gradient-accumulation-blog/blob/main/src/1_batchsize-1.py
你可以將此程式碼直接複製並貼上到Google Colab 中,但也必須將隨附的local_dataset_utilities.py 檔案拖放到從該檔案匯入了一些資料集實用程式的同一資料夾中。
<code># pip install torch lightning matplotlib pandas torchmetrics watermark transformers datasets -Uimport osimport os.path as opimport timefrom datasets import load_datasetfrom lightning import Fabricimport torchfrom torch.utils.data import DataLoaderimport torchmetricsfrom transformers import AutoTokenizerfrom transformers import AutoModelForSequenceClassificationfrom watermark import watermarkfrom local_dataset_utilities import download_dataset, load_dataset_into_to_dataframe, partition_datasetfrom local_dataset_utilities import IMDBDatasetdef tokenize_text (batch):return tokenizer (batch ["text"], truncatinotallow=True, padding=True, max_length=1024)def train (num_epochs, model, optimizer, train_loader, val_loader, fabric):for epoch in range (num_epochs):train_acc = torchmetrics.Accuracy (task="multiclass", num_classes=2).to (fabric.device)for batch_idx, batch in enumerate (train_loader):model.train ()### FORWARD AND BACK PROPoutputs = model (batch ["input_ids"],attention_mask=batch ["attention_mask"],labels=batch ["label"]) fabric.backward (outputs ["loss"])### UPDATE MODEL PARAMETERSoptimizer.step ()optimizer.zero_grad ()### LOGGINGif not batch_idx % 300:print (f"Epoch: {epoch+1:04d}/{num_epochs:04d}"f"| Batch {batch_idx:04d}/{len (train_loader):04d}"f"| Loss: {outputs ['loss']:.4f}")model.eval ()with torch.no_grad ():predicted_labels = torch.argmax (outputs ["logits"], 1)train_acc.update (predicted_labels, batch ["label"])### MORE LOGGINGmodel.eval ()with torch.no_grad ():val_acc = torchmetrics.Accuracy (task="multiclass", num_classes=2).to (fabric.device)for batch in val_loader:outputs = model (batch ["input_ids"],attention_mask=batch ["attention_mask"],labels=batch ["label"])predicted_labels = torch.argmax (outputs ["logits"], 1)val_acc.update (predicted_labels, batch ["label"])print (f"Epoch: {epoch+1:04d}/{num_epochs:04d}"f"| Train acc.: {train_acc.compute ()*100:.2f}%"f"| Val acc.: {val_acc.compute ()*100:.2f}%")train_acc.reset (), val_acc.reset ()if __name__ == "__main__":print (watermark (packages="torch,lightning,transformers", pythnotallow=True))print ("Torch CUDA available?", torch.cuda.is_available ())device = "cuda" if torch.cuda.is_available () else "cpu"torch.manual_seed (123)# torch.use_deterministic_algorithms (True)############################# 1 Loading the Dataset##########################download_dataset ()df = load_dataset_into_to_dataframe ()if not (op.exists ("train.csv") and op.exists ("val.csv") and op.exists ("test.csv")):partition_dataset (df)imdb_dataset = load_dataset ("csv",data_files={"train": "train.csv","validation": "val.csv","test": "test.csv",},)############################################ 2 Tokenization and Numericalization#########################################tokenizer = AutoTokenizer.from_pretrained ("bigscience/bloom-560m", max_length=1024)print ("Tokenizer input max length:", tokenizer.model_max_length, flush=True)print ("Tokenizer vocabulary size:", tokenizer.vocab_size, flush=True)print ("Tokenizing ...", flush=True)imdb_tokenized = imdb_dataset.map (tokenize_text, batched=True, batch_size=None)del imdb_datasetimdb_tokenized.set_format ("torch", columns=["input_ids", "attention_mask", "label"])os.environ ["TOKENIZERS_PARALLELISM"] = "false"############################################ 3 Set Up DataLoaders#########################################train_dataset = IMDBDataset (imdb_tokenized, partition_key="train")val_dataset = IMDBDataset (imdb_tokenized, partition_key="validation")test_dataset = IMDBDataset (imdb_tokenized, partition_key="test")train_loader = DataLoader (dataset=train_dataset,batch_size=1,shuffle=True,num_workers=4,drop_last=True,)val_loader = DataLoader (dataset=val_dataset,batch_size=1,num_workers=4,drop_last=True,)test_loader = DataLoader (dataset=test_dataset,batch_size=1,num_workers=2,drop_last=True,)############################################ 4 Initializing the Model#########################################fabric = Fabric (accelerator="cuda", devices=1, precisinotallow="16-mixed")fabric.launch ()model = AutoModelForSequenceClassification.from_pretrained ("bigscience/bloom-560m", num_labels=2)optimizer = torch.optim.Adam (model.parameters (), lr=5e-5)model, optimizer = fabric.setup (model, optimizer)train_loader, val_loader, test_loader = fabric.setup_dataloaders (train_loader, val_loader, test_loader)############################################ 5 Finetuning#########################################start = time.time ()train (num_epochs=1,model=model,optimizer=optimizer,train_loader=train_loader,val_loader=val_loader,fabric=fabric,)end = time.time ()elapsed = end-startprint (f"Time elapsed {elapsed/60:.2f} min")with torch.no_grad ():model.eval ()test_acc = torchmetrics.Accuracy (task="multiclass", num_classes=2).to (fabric.device)for batch in test_loader:outputs = model (batch ["input_ids"],attention_mask=batch ["attention_mask"],labels=batch ["label"])predicted_labels = torch.argmax (outputs ["logits"], 1)test_acc.update (predicted_labels, batch ["label"])print (f"Test accuracy {test_acc.compute ()*100:.2f}%")</code>作者使用了 Lightning Fabric,因為它可以讓開發者在不同硬體上運行此程式碼時靈活地改變 GPU 數量和多 GPU 訓練策略。它還允許僅透過調整查準率 flag 來啟用混合精度訓練(mixed-precision training)。在這種情況下,混合精度訓練可以將訓練速度提高三倍,並將記憶體需求降低約 25%。
上面展示的主要程式碼都是在主函數(if __name__ == "__main__" 的context)中執行的,即使只使用單一GPU,也建議使用PyTorch 執行環境執行多GPU 訓練。而後,包含在if __name__ == "__main__" 中的以下三個代碼部分負責資料載入:
# 1 載入資料集
# 2 token 化與數值化
# 3 設定資料載入器
第4 節是初始化模型(Initializing the Model)中,然後在第5 節微調(Finetuning)中,呼叫train 函數,這是開始讓事情變得有趣的地方。在 train (...) 函數中,實現了標準的 PyTorch 迴圈。核心訓練循環的註解版本如下所示:
批次大小為1(Batch size=1)的問題是梯度更新將會變得非常混亂和困難,正如下述訓練模型時基於波動的訓練損失和糟糕的測試集性能所看到的:
<code>...torch : 2.0.0lightning : 2.0.0transformers: 4.27.2Torch CUDA available? True...Epoch: 0001/0001 | Batch 23700/35000 | Loss: 0.0969Epoch: 0001/0001 | Batch 24000/35000 | Loss: 1.9902Epoch: 0001/0001 | Batch 24300/35000 | Loss: 0.0395Epoch: 0001/0001 | Batch 24600/35000 | Loss: 0.2546Epoch: 0001/0001 | Batch 24900/35000 | Loss: 0.1128Epoch: 0001/0001 | Batch 25200/35000 | Loss: 0.2661Epoch: 0001/0001 | Batch 25500/35000 | Loss: 0.0044Epoch: 0001/0001 | Batch 25800/35000 | Loss: 0.0067Epoch: 0001/0001 | Batch 26100/35000 | Loss: 0.0468Epoch: 0001/0001 | Batch 26400/35000 | Loss: 1.7139Epoch: 0001/0001 | Batch 26700/35000 | Loss: 0.9570Epoch: 0001/0001 | Batch 27000/35000 | Loss: 0.1857Epoch: 0001/0001 | Batch 27300/35000 | Loss: 0.0090Epoch: 0001/0001 | Batch 27600/35000 | Loss: 0.9790Epoch: 0001/0001 | Batch 27900/35000 | Loss: 0.0503Epoch: 0001/0001 | Batch 28200/35000 | Loss: 0.2625Epoch: 0001/0001 | Batch 28500/35000 | Loss: 0.1010Epoch: 0001/0001 | Batch 28800/35000 | Loss: 0.0035Epoch: 0001/0001 | Batch 29100/35000 | Loss: 0.0009Epoch: 0001/0001 | Batch 29400/35000 | Loss: 0.0234Epoch: 0001/0001 | Batch 29700/35000 | Loss: 0.8394Epoch: 0001/0001 | Batch 30000/35000 | Loss: 0.9497Epoch: 0001/0001 | Batch 30300/35000 | Loss: 0.1437Epoch: 0001/0001 | Batch 30600/35000 | Loss: 0.1317Epoch: 0001/0001 | Batch 30900/35000 | Loss: 0.0112Epoch: 0001/0001 | Batch 31200/35000 | Loss: 0.0073Epoch: 0001/0001 | Batch 31500/35000 | Loss: 0.7393Epoch: 0001/0001 | Batch 31800/35000 | Loss: 0.0512Epoch: 0001/0001 | Batch 32100/35000 | Loss: 0.1337Epoch: 0001/0001 | Batch 32400/35000 | Loss: 1.1875Epoch: 0001/0001 | Batch 32700/35000 | Loss: 0.2727Epoch: 0001/0001 | Batch 33000/35000 | Loss: 0.1545Epoch: 0001/0001 | Batch 33300/35000 | Loss: 0.0022Epoch: 0001/0001 | Batch 33600/35000 | Loss: 0.2681Epoch: 0001/0001 | Batch 33900/35000 | Loss: 0.2467Epoch: 0001/0001 | Batch 34200/35000 | Loss: 0.0620Epoch: 0001/0001 | Batch 34500/35000 | Loss: 2.5039Epoch: 0001/0001 | Batch 34800/35000 | Loss: 0.0131Epoch: 0001/0001 | Train acc.: 75.11% | Val acc.: 78.62%Time elapsed 69.97 minTest accuracy 78.53%</code>
#由於沒有多的GPU 可用於張量分片(tensor sharding),又能做些什麼來訓練具有更大批大小(batch size)的模型呢?
其中一個解決方法就是梯度累積,可以透過它來修改前面提到的訓練循環。
什么是梯度积累?
梯度累积是一种在训练期间虚拟增加批大小(batch size)的方法,当可用的 GPU 内存不足以容纳所需的批大小时,这非常有用。在梯度累积中,梯度是针对较小的批次计算的,并在多次迭代中累积(通常是求和或平均),而不是在每一批次之后更新模型权重。一旦累积梯度达到目标「虚拟」批大小,模型权重就会使用累积梯度进行更新。
参考下面更新的 PyTorch 训练循环:
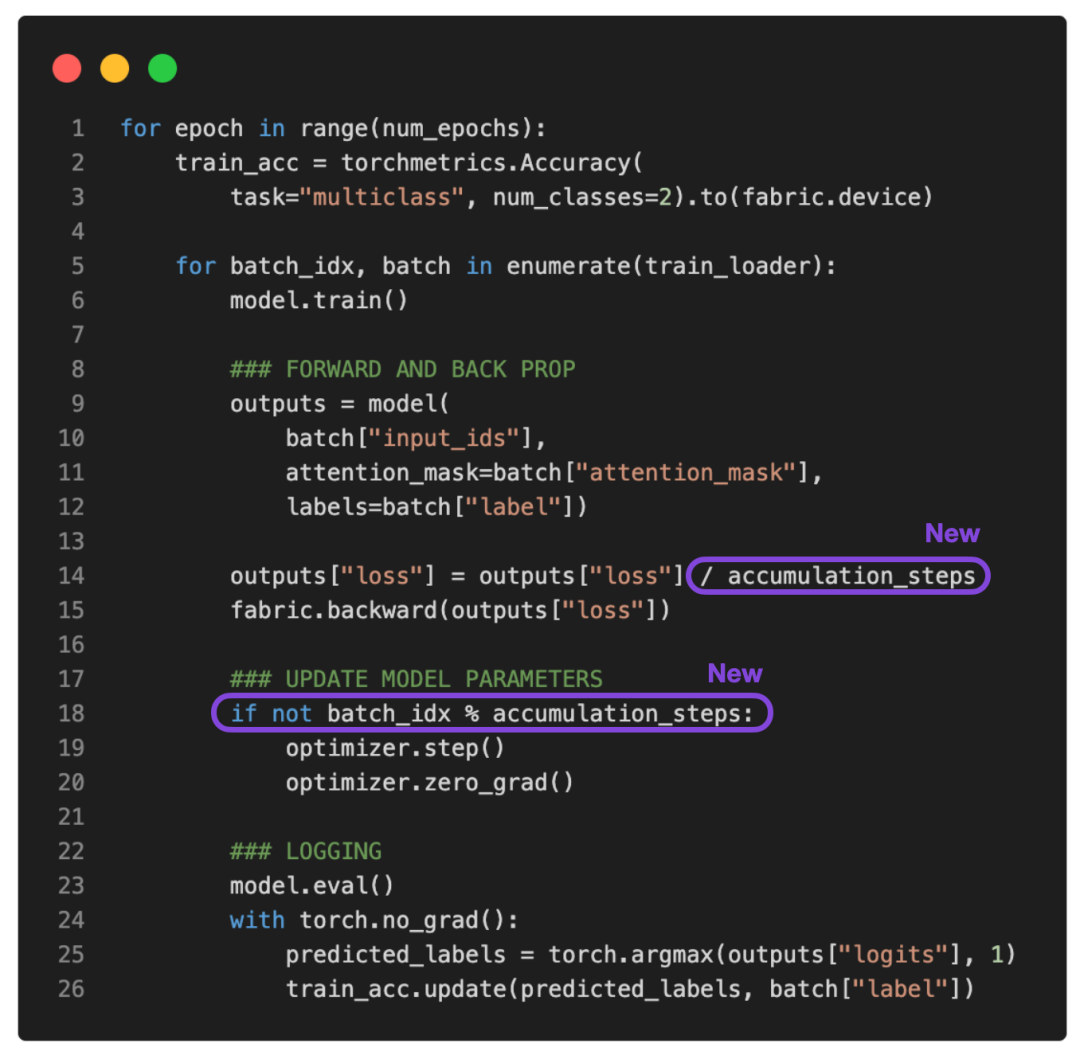
如果将 accumulation_steps 设置为 2,那么 zero_grad () 和 optimizer.step () 将只会每隔一秒调用一次。因此,使用 accumulation_steps=2 运行修改后的训练循环与将批大小(batch size)加倍具有相同的效果。
例如,如果想使用 256 的批大小,但只能将 64 的批大小放入 GPU 内存中,就可以对大小为 64 的四个批执行梯度累积。(处理完所有四个批次后,将获得相当于单个批大小为 256 的累积梯度。)这样能够有效地模拟更大的批大小,而无需更大的 GPU 内存或跨不同设备的张量分片。
虽然梯度累积可以帮助我们训练具有更大批量大小的模型,但它不会减少所需的总计算量。实际上,它有时会导致训练过程略慢一些,因为权重更新的执行频率较低。尽管如此,它却能帮我们解决限制问题,即批大小非常小时导致的更新频繁且混乱。
例如,现在让我们运行上面的代码,批大小为 1,需要 16 个累积步骤(accumulation steps)来模拟批大小等于 16。
输出如下:
<code>...torch : 2.0.0lightning : 2.0.0transformers: 4.27.2Torch CUDA available? True...Epoch: 0001/0001 | Batch 23700/35000 | Loss: 0.0168Epoch: 0001/0001 | Batch 24000/35000 | Loss: 0.0006Epoch: 0001/0001 | Batch 24300/35000 | Loss: 0.0152Epoch: 0001/0001 | Batch 24600/35000 | Loss: 0.0003Epoch: 0001/0001 | Batch 24900/35000 | Loss: 0.0623Epoch: 0001/0001 | Batch 25200/35000 | Loss: 0.0010Epoch: 0001/0001 | Batch 25500/35000 | Loss: 0.0001Epoch: 0001/0001 | Batch 25800/35000 | Loss: 0.0047Epoch: 0001/0001 | Batch 26100/35000 | Loss: 0.0004Epoch: 0001/0001 | Batch 26400/35000 | Loss: 0.1016Epoch: 0001/0001 | Batch 26700/35000 | Loss: 0.0021Epoch: 0001/0001 | Batch 27000/35000 | Loss: 0.0015Epoch: 0001/0001 | Batch 27300/35000 | Loss: 0.0008Epoch: 0001/0001 | Batch 27600/35000 | Loss: 0.0060Epoch: 0001/0001 | Batch 27900/35000 | Loss: 0.0001Epoch: 0001/0001 | Batch 28200/35000 | Loss: 0.0426Epoch: 0001/0001 | Batch 28500/35000 | Loss: 0.0012Epoch: 0001/0001 | Batch 28800/35000 | Loss: 0.0025Epoch: 0001/0001 | Batch 29100/35000 | Loss: 0.0025Epoch: 0001/0001 | Batch 29400/35000 | Loss: 0.0000Epoch: 0001/0001 | Batch 29700/35000 | Loss: 0.0495Epoch: 0001/0001 | Batch 30000/35000 | Loss: 0.0164Epoch: 0001/0001 | Batch 30300/35000 | Loss: 0.0067Epoch: 0001/0001 | Batch 30600/35000 | Loss: 0.0037Epoch: 0001/0001 | Batch 30900/35000 | Loss: 0.0005Epoch: 0001/0001 | Batch 31200/35000 | Loss: 0.0013Epoch: 0001/0001 | Batch 31500/35000 | Loss: 0.0112Epoch: 0001/0001 | Batch 31800/35000 | Loss: 0.0053Epoch: 0001/0001 | Batch 32100/35000 | Loss: 0.0012Epoch: 0001/0001 | Batch 32400/35000 | Loss: 0.1365Epoch: 0001/0001 | Batch 32700/35000 | Loss: 0.0210Epoch: 0001/0001 | Batch 33000/35000 | Loss: 0.0374Epoch: 0001/0001 | Batch 33300/35000 | Loss: 0.0007Epoch: 0001/0001 | Batch 33600/35000 | Loss: 0.0341Epoch: 0001/0001 | Batch 33900/35000 | Loss: 0.0259Epoch: 0001/0001 | Batch 34200/35000 | Loss: 0.0005Epoch: 0001/0001 | Batch 34500/35000 | Loss: 0.4792Epoch: 0001/0001 | Batch 34800/35000 | Loss: 0.0003Epoch: 0001/0001 | Train acc.: 78.67% | Val acc.: 87.28%Time elapsed 51.37 minTest accuracy 87.37%</code>
根据上面的结果,损失的波动比以前小了。此外,测试集性能提升了 10%。由于只迭代了训练集一次,因此每个训练样本只会遇到一次。训练用于 multiple epochs 的模型可以进一步提高预测性能。
你可能还会注意到,这段代码的执行速度也比之前使用的批大小为 1 的代码快。如果使用梯度累积将虚拟批大小增加到 8,仍然会有相同数量的前向传播(forward passes)。然而,由于每八个 epoch 只更新一次模型,因此反向传播(backward passes)会很少,这样可更快地在一个 epoch(训练轮数)内迭代样本。
结论
梯度累积是一种在执行权重更新之前通过累积多个小的批梯度来模拟更大的批大小的技术。该技术在可用内存有限且内存中可容纳批大小较小的情况下提供帮助。
但是,首先请思考一种你可以运行批大小的场景,这意味着可用内存大到足以容纳所需的批大小。在那种情况下,梯度累积可能不是必需的。事实上,运行更大的批大小可能更有效,因为它允许更多的并行性且能减少训练模型所需的权重更新次数。
总之,梯度累积是一种实用的技术,可以用于降低小批大小干扰信息对梯度更新准确性的影响。这是迄今一种简单而有效的技术,可以让我们绕过硬件的限制。
PS:可以让这个运行得更快吗?
没问题。可以使用 PyTorch 2.0 中引入的 torch.compile 使其运行得更快。只需要添加一些 model = torch.compile,如下图所示:
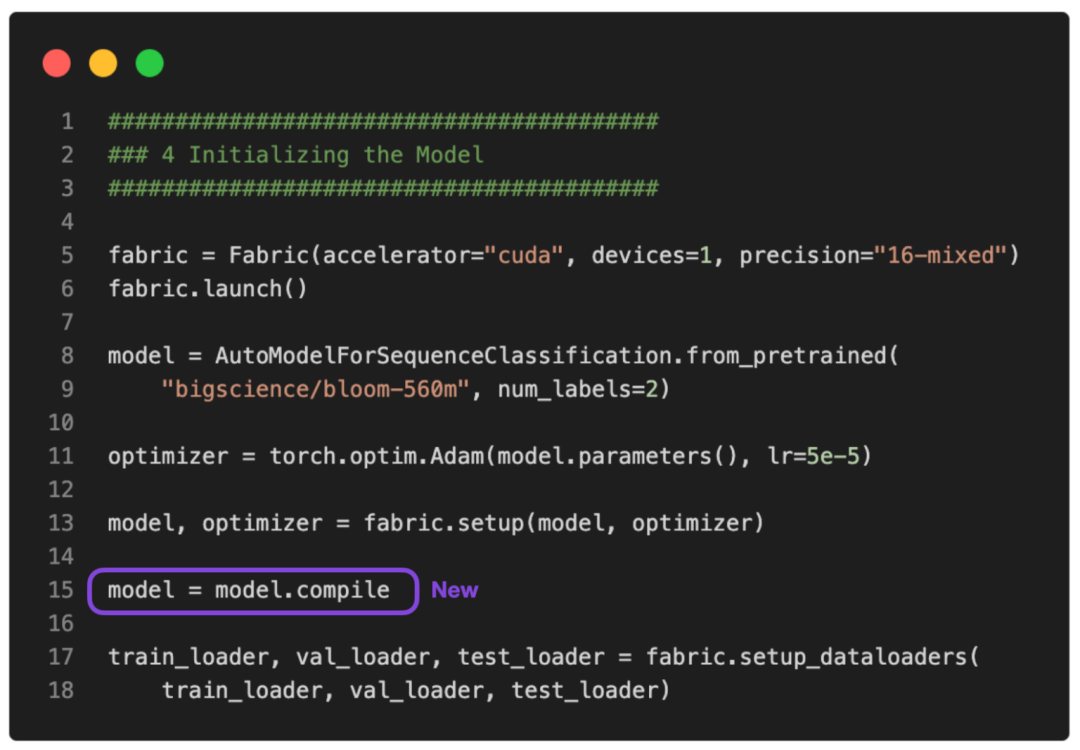
GitHub 上提供了完整的脚本。
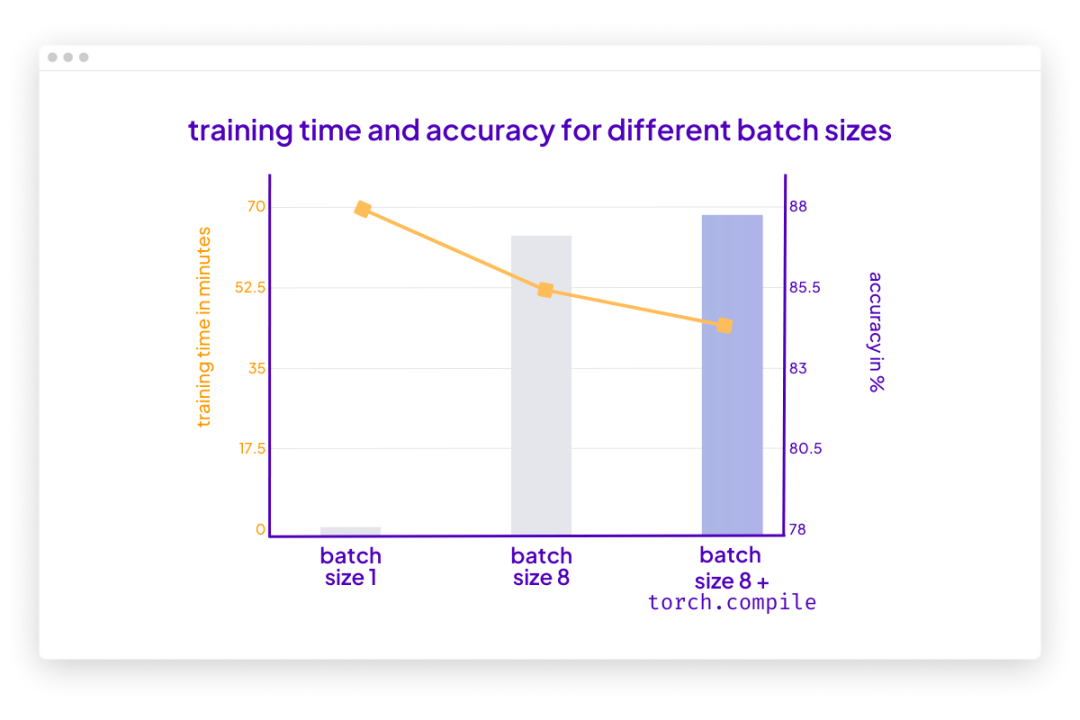
在这种情况下,torch.compile 在不影响建模性能的情况下又减少了十分钟的训练时间:
<code>poch: 0001/0001 | Batch 26400/35000 | Loss: 0.0320Epoch: 0001/0001 | Batch 26700/35000 | Loss: 0.0010Epoch: 0001/0001 | Batch 27000/35000 | Loss: 0.0006Epoch: 0001/0001 | Batch 27300/35000 | Loss: 0.0015Epoch: 0001/0001 | Batch 27600/35000 | Loss: 0.0157Epoch: 0001/0001 | Batch 27900/35000 | Loss: 0.0015Epoch: 0001/0001 | Batch 28200/35000 | Loss: 0.0540Epoch: 0001/0001 | Batch 28500/35000 | Loss: 0.0035Epoch: 0001/0001 | Batch 28800/35000 | Loss: 0.0016Epoch: 0001/0001 | Batch 29100/35000 | Loss: 0.0015Epoch: 0001/0001 | Batch 29400/35000 | Loss: 0.0008Epoch: 0001/0001 | Batch 29700/35000 | Loss: 0.0877Epoch: 0001/0001 | Batch 30000/35000 | Loss: 0.0232Epoch: 0001/0001 | Batch 30300/35000 | Loss: 0.0014Epoch: 0001/0001 | Batch 30600/35000 | Loss: 0.0032Epoch: 0001/0001 | Batch 30900/35000 | Loss: 0.0004Epoch: 0001/0001 | Batch 31200/35000 | Loss: 0.0062Epoch: 0001/0001 | Batch 31500/35000 | Loss: 0.0032Epoch: 0001/0001 | Batch 31800/35000 | Loss: 0.0066Epoch: 0001/0001 | Batch 32100/35000 | Loss: 0.0017Epoch: 0001/0001 | Batch 32400/35000 | Loss: 0.1485Epoch: 0001/0001 | Batch 32700/35000 | Loss: 0.0324Epoch: 0001/0001 | Batch 33000/35000 | Loss: 0.0155Epoch: 0001/0001 | Batch 33300/35000 | Loss: 0.0007Epoch: 0001/0001 | Batch 33600/35000 | Loss: 0.0049Epoch: 0001/0001 | Batch 33900/35000 | Loss: 0.1170Epoch: 0001/0001 | Batch 34200/35000 | Loss: 0.0002Epoch: 0001/0001 | Batch 34500/35000 | Loss: 0.4201Epoch: 0001/0001 | Batch 34800/35000 | Loss: 0.0018Epoch: 0001/0001 | Train acc.: 78.39% | Val acc.: 86.84%Time elapsed 43.33 minTest accuracy 87.91%</code>
请注意,与之前相比准确率略有提高很可能是由于随机性。
以上是繞開算力限制,如何用單GPU微調 LLM?這是一份「梯度累積」演算法教程的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

AI Hentai Generator
免費產生 AI 無盡。

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)
熱門話題



 四款值得推薦的AI輔助程式工具
Apr 22, 2024 pm 05:34 PM
四款值得推薦的AI輔助程式工具
Apr 22, 2024 pm 05:34 PM
這個AI輔助程式工具在這個AI快速發展的階段,挖掘出了一大批好用的AI輔助程式工具。 AI輔助程式設計工具能夠提升開發效率、提升程式碼品質、降低bug率,是現代軟體開發過程中的重要助手。今天大姚給大家分享4款AI輔助程式工具(而且都支援C#語言),希望對大家有幫助。 https://github.com/YSGStudyHards/DotNetGuide1.GitHubCopilotGitHubCopilot是一款AI編碼助手,可幫助你更快、更省力地編寫程式碼,從而將更多精力集中在問題解決和協作上。 Git
 AI程式設計師哪家強?探索Devin、通靈靈碼和SWE-agent的潛力
Apr 07, 2024 am 09:10 AM
AI程式設計師哪家強?探索Devin、通靈靈碼和SWE-agent的潛力
Apr 07, 2024 am 09:10 AM
2022年3月3日,距離世界首個AI程式設計師Devin誕生不足一個月,普林斯頓大學的NLP團隊開發了一個開源AI程式設計師SWE-agent。它利用GPT-4模型在GitHub儲存庫中自動解決問題。 SWE-agent在SWE-bench測試集上的表現與Devin相似,平均耗時93秒,解決了12.29%的問題。 SWE-agent透過與專用終端交互,可以開啟、搜尋文件內容,使用自動語法檢查、編輯特定行,以及編寫和執行測試。 (註:以上內容為原始內容微調,但保留了原文中的關鍵訊息,未超過指定字數限制。)SWE-A
 五大熱門Go語言庫總表:開發必備利器
Feb 22, 2024 pm 02:33 PM
五大熱門Go語言庫總表:開發必備利器
Feb 22, 2024 pm 02:33 PM
五大熱門Go語言庫總結:開發必備利器,需要具體程式碼範例Go語言自從誕生以來,受到了廣泛的關注和應用。作為一門新興的高效、簡潔的程式語言,Go的快速發展離不開豐富的開源程式庫的支援。本文將介紹五大熱門的Go語言庫,這些庫在Go開發中扮演了至關重要的角色,為開發者提供了強大的功能和便利的開發體驗。同時,為了更好地理解這些庫的用途和功能,我們會結合具體的程式碼範例進行講
 學習如何利用Go語言開發行動應用程式
Mar 28, 2024 pm 10:00 PM
學習如何利用Go語言開發行動應用程式
Mar 28, 2024 pm 10:00 PM
Go語言開發行動應用程式教學隨著行動應用程式市場的不斷蓬勃發展,越來越多的開發者開始探索如何利用Go語言開發行動應用程式。作為一種簡潔高效的程式語言,Go語言在行動應用開發中也展現了強大的潛力。本文將詳細介紹如何利用Go語言開發行動應用程序,並附上具體的程式碼範例,幫助讀者快速入門並開始開發自己的行動應用程式。一、準備工作在開始之前,我們需要準備好開發環境和工具。首
 Android開發最適合的Linux發行版是哪一個?
Mar 14, 2024 pm 12:30 PM
Android開發最適合的Linux發行版是哪一個?
Mar 14, 2024 pm 12:30 PM
Android開發是一項繁忙而又令人興奮的工作,而選擇適合的Linux發行版來進行開發則顯得尤為重要。在眾多的Linux發行版中,究竟哪一個最適合Android開發呢?本文將從幾個方面來探討這個問題,並給出具體的程式碼範例。首先,我們來看看目前流行的幾個Linux發行版:Ubuntu、Fedora、Debian、CentOS等,它們都有各自的優點和特點。
 了解VSCode:這款工具到底是用來做什麼的?
Mar 25, 2024 pm 03:06 PM
了解VSCode:這款工具到底是用來做什麼的?
Mar 25, 2024 pm 03:06 PM
《了解VSCode:這款工具到底是用來做什麼的? 》身為程式設計師,無論是初學者或資深開發者,都離不開程式碼編輯工具的使用。在眾多編輯工具中,VisualStudioCode(簡稱VSCode)作為一款開源、輕量級、強大的程式碼編輯器備受開發者歡迎。那麼,VSCode到底是用來做什麼的呢?本文將深入探討VSCode的功能和用途,並提供具體的程式碼範例,以幫助讀者
 Go語言前端技術探秘:前端開發新視野
Mar 28, 2024 pm 01:06 PM
Go語言前端技術探秘:前端開發新視野
Mar 28, 2024 pm 01:06 PM
Go語言作為一種快速、高效的程式語言,在後端開發領域廣受歡迎。然而,很少有人將Go語言與前端開發聯繫起來。事實上,使用Go語言進行前端開發不僅可以提高效率,還能為開發者帶來全新的視野。本文將探討使用Go語言進行前端開發的可能性,並提供具體的程式碼範例,幫助讀者更了解這一領域。在傳統的前端開發中,通常會使用JavaScript、HTML和CSS來建立使用者介面
 國內首個算力互聯公共平台發布,可查詢全國算力資源及調度服務
Jul 16, 2024 am 10:55 AM
國內首個算力互聯公共平台發布,可查詢全國算力資源及調度服務
Jul 16, 2024 am 10:55 AM
本站7月12日消息,根據中國資訊通信研究院(簡稱「中國信通院」)官方消息,國內首個算力互聯公共平台7月11日發布。平台將對全國範圍內的算力資源進行標識註冊和測試,透過平台可以查詢全國範圍內的算力資源和相關算力調度服務,為各行各業提供真實、可信的算力支持,加速推動算力互聯互通。 7月11日,中國信通院發布算力互聯公共服務平台,聯合產業界進行算力互聯網共識共創行動。算力互聯公共服務平台是推動和管理全國算力互聯互通和算力互聯網體系的綜合服務平台,包括算力標識管理、算力互聯網業務查詢、算力統一大市場、政策和
