

軌跡預測的視覺方法綜述

最近一個綜述論文“Trajectory-Prediction With Vision: A Survey ”,來自現代和安波福的公司Motional;不過它參考了牛津大學的綜述文章“Vision-based Intention and Trajectory Prediction in Autonomous Vehicles: A Survey 」。
預測任務基本上分為兩部分:1)意圖,這是一項分類任務,為智體預先設計一組意圖類;通常將其視為一個監督學習問題,需要標註智體可能的分類意圖;2)軌跡,需要預測智體在後面未來幀中的一組可能位置,稱為路點;這構成了智體之間以及智體和道路之間的交互。
先前的行為預測模型可以分為三類:基於物理、基於機動和互動-感知模型。這句話可以改寫為:利用物理模型的動力學方程,為各種不同類型的智能體設計了可人工控制的運動。此方法無法對整個情境的潛在狀態進行建模,而通常只專注於一個特定的智能體。然而,在深度學習之前的時代,這種趨勢曾經是SOTA。基於機動的模型是基於智體預期運動類型的模型。交互-覺察的模型通常是一種基於機器學習的系統,對場景中的每個智體進行逐對推理,並為所有動態智體產生交互-覺察的預測。在場景中附近不同智體目標之間存在高度相關性。對複雜的智體軌跡注意模組進行建模,可以更好泛化。
預測未來的行動或事件可以表現為隱含的形式,其未來軌跡也可以是顯性的。智體的意圖可能受到以下因素的影響:a)智體自己的信念或意願(通常不會被觀察到,因此難以建模);b) 社會交互,可以用不同的方法進行建模,如社交池化、圖神經網路、注意力等;c) 環境約束,如道路佈局,可透過高清(HD)地圖進行編碼;d) 背景訊息,形式為RGB影像幀、雷射雷達點雲、光流、分割圖等。在另一方面,軌跡預測是一種更具挑戰性的問題,因為它涉及回歸(連續)而不是分類問題,與識別意圖不同。
軌跡和意圖需要從互動-覺察入手。一個合理的假設是,當試圖激進地駛入交通擁堵的高速公路時,一輛經過的車輛可能會緊急煞車。建模。 最好在BEV空間進行建模,這樣可以進行軌跡預測,而且可以在影像視角(也稱為透視圖)中建模。這句話可以重寫為:「這是因為可以將感興趣區域(RoI)以網格的形式分配到一個專用的距離範圍內。」。然而,由於透視圖中的消失線,影像視角理論上可以無限地拓展RoI。 BEV空間更適合對遮蔽進行建模,因為它能更線性地建立運動模型。透過進行姿態估計(自車的平移和旋轉),可以簡單地進行自身運動的補償。此外,這個空間保留了智體的運動和尺度,即不管自車有多遠,周圍車輛將佔據相同數量的BEV像素;但影像視角的情況並非如此。為了預測未來,需要對過去有個了解。這通常可以透過追蹤來完成,也可以用歷史聚合BEV特徵來完成。
下圖是預測模型的一些元件和資料流程框圖:
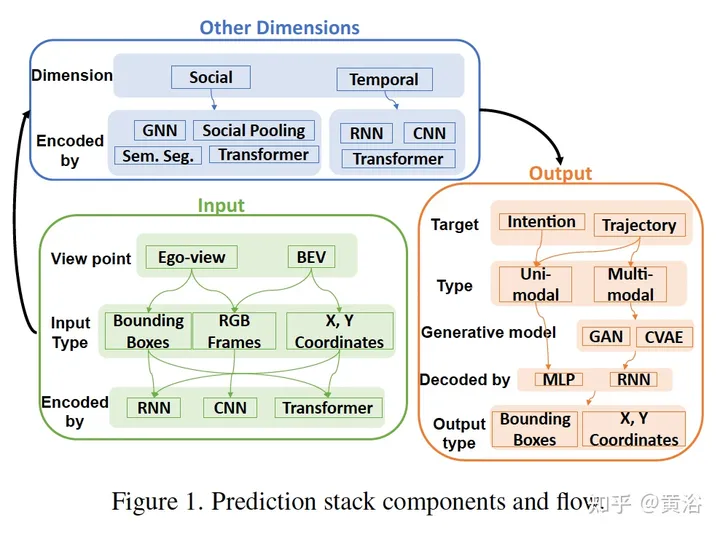
#下表是預測模型的總結:
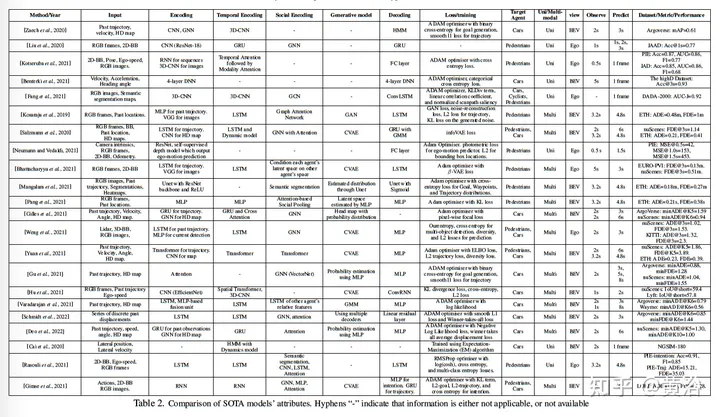
#以下基本上從輸入/輸出入手討論預測模型:
1)Tracklets:感知模組預測所有動態智體的當前狀態。這種狀態包括3-D中心、維度、速度、加速度等屬性。追蹤器可以利用這些數據並建立臨時的關聯,這樣每個追蹤器都能夠保存所有智體的狀態歷史。現在,每個tracklet都表示該智體過去的運動。由於其輸入僅包括稀疏的軌跡,因此這種預測模型形式是最簡單的。一個好的追蹤器能夠追蹤一個智體,即使在當前幀中被遮住。由於傳統的追蹤器是基於非機器學習的網絡,因此實現端到端模型變得十分困難。
2)原始感測器資料:這是一種端到端方法,模型獲取原始感測器資料訊息,並直接預測場景中每個智體的軌跡預測。這種方法可能有也可能沒有輔助輸出及其損失來監督複雜的訓練。這一類方法的缺點是,用於輸入的資訊密集,計算上昂貴。這是由於將感知、追蹤和預測三個問題合併在一起,使得模型在開發時變得困難,甚至更難達到收斂。
3)攝影機-vs- BEV:BEV方法處理來自頂視類似地圖的數據,攝影機預測演算法從自車角度感知世界,由於多種原因,後者通常比前者更具挑戰性;首先,從BEV感知可以獲得更廣闊的視野和更豐富的預測信息,相比之下攝像頭的視野較短,這限制了預測範圍,因為汽車無法做視野以外規劃;此外,攝像頭更容易被遮擋,因此與基於相機的方法相比,BEV方法受到的「部分可觀察性」挑戰更少;其次,除非雷射雷達數據可用,否則單目視覺使演算法難以推斷關注智體的深度,這是預測其行為的重要線索;最後,攝影機正在移動,這需要處理關注智體的運動和自車的運動,這與靜態BEV不同;提一句:作為一種缺點,BEV表徵方法仍然存在累積錯誤的問題;儘管在處理相機視圖方面存在固有的挑戰,但它仍然比BEV更實用,其實汽車很少能訪問顯示道路上BEV和關注智體位置的攝影機。結論是,預測系統應該能夠從自車的角度看待世界,包括光達和/或立體相機,其數據以3D方式感知世界可能是有利的;另一個重要的相關點是,每次若必須包括關注智體的位置以進行預測時,最好使用邊框位置,而不是純粹的中心點,因為前者的坐標隱含自車和行人之間的相對距離變化以及相機自運動;換句話說,隨著智身體接近自車,邊框變得更大,提供了對深度的附加(儘管是初步的)估計。
4)自運動預測:自車運動進行建模產生更準確的軌跡。另外一些方法使用深度網路或動力學模型對關注智體的運動進行建模,利用從資料集輸入計算的額外量,如姿勢、光流、語義圖和熱圖。
5)時域編碼:由於駕駛環境是動態的,有許多活動智體,因此有必要在智體時間維度進行編碼可建立一個更好的預測系統,將過去發生的事情與未來透過現在發生的事情連結;了解智體的來源有助於猜測智體下一步可能會去哪裡,大多數基於攝影機的模型處理較短的時間範圍,而對於較長的時間範圍處理,預測模型需要一個更複雜的結構。
6) 社交編碼:為了回應「多智體」的挑戰,大多數表現最好的演算法使用不同類型的圖神經網路(GNN)來編碼智體之間的社會互動;大多數方法分別對時間和社會維度進行編碼-要麼從時間層面開始,然後考慮社會層面,要麼相反順序;有一種基於Transformer的模型,可以同時對兩個維度進行編碼。
7)基於預期目標的預測:行為意圖預測與場景上下文一樣,通常會受到不同預期目標的影響,並且應該透過解釋來推斷;對於以預期目標為條件的未來預測,這個目標會被建模為未來狀態(定義為目的地座標)或智體期望的運動類型;神經科學和電腦視覺的研究表明,人通常是目標-導向的智體;此外在做出決策的同時,人遵循一系列連續級的推理,最終制定出短期或長期計劃;基於此,這個問題可分為兩類:第一類是認知性的,回答智體要去哪裡的問題;第二個是任意性的,回答這個智體如何達成預期目標的問題。
8)多模態預測:由於道路環境是隨機的,一個先前的軌跡可以展開不同的未來軌跡;因此,解決「隨機彈性(stocasticity)」挑戰的實用預測系統會對問題的不確定性進行建模;儘管存在離散變數的潛空間建模的方法,但多模態僅應用於軌跡,完全顯示其在意圖預測方面的潛力;採用注意力機制,可用於計算加權。
以上是軌跡預測的視覺方法綜述的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 Windows 11 上的智慧型應用程式控制:如何開啟或關閉它
Jun 06, 2023 pm 11:10 PM
Windows 11 上的智慧型應用程式控制:如何開啟或關閉它
Jun 06, 2023 pm 11:10 PM
智慧型應用程式控制是Windows11中非常有用的工具,可幫助保護你的電腦免受可能損害資料的未經授權的應用程式(如勒索軟體或間諜軟體)的侵害。本文將解釋什麼是智慧型應用程式控制、它是如何運作的,以及如何在Windows11中開啟或關閉它。什麼是Windows11中的智慧型應用控制?智慧型應用程式控制(SAC)是Windows1122H2更新中引入的新安全功能。它與MicrosoftDefender或第三方防毒軟體一起運行,以阻止可能不必要的應用,這些應用程式可能會減慢設備速度、顯示意外廣告或執行其他意外操作。智慧應用
 超越ORB-SLAM3! SL-SLAM:低光、嚴重抖動和弱紋理場景全搞定
May 30, 2024 am 09:35 AM
超越ORB-SLAM3! SL-SLAM:低光、嚴重抖動和弱紋理場景全搞定
May 30, 2024 am 09:35 AM
寫在前面今天我們探討下深度學習技術如何改善在複雜環境中基於視覺的SLAM(同時定位與地圖建構)表現。透過將深度特徵提取和深度匹配方法相結合,這裡介紹了一種多功能的混合視覺SLAM系統,旨在提高在諸如低光條件、動態光照、弱紋理區域和嚴重抖動等挑戰性場景中的適應性。我們的系統支援多種模式,包括拓展單目、立體、單目-慣性以及立體-慣性配置。除此之外,也分析如何將視覺SLAM與深度學習方法結合,以啟發其他研究。透過在公共資料集和自採樣資料上的廣泛實驗,展示了SL-SLAM在定位精度和追蹤魯棒性方面優
 五官亂飛,張嘴、瞪眼、挑眉,AI都能模仿到位,影片詐騙要防不住了
Dec 14, 2023 pm 11:30 PM
五官亂飛,張嘴、瞪眼、挑眉,AI都能模仿到位,影片詐騙要防不住了
Dec 14, 2023 pm 11:30 PM
好強大的AI模仿能力,真的防不住,完全防不住。現在AI的發展已經達到這種程度了嗎?你前腳讓自己的五官亂飛,後腳,一模一樣的表情就被復現出來,瞪眼、挑眉、噘嘴,不管多麼誇張的表情,都模仿的非常到位。加大難度,讓眉毛挑的再高些,眼睛睜的再大些,甚至連嘴型都是歪的,虛擬人物頭像也能完美復現表情。當你在左邊調整參數時,右邊的虛擬頭像也會相應地改變動作給嘴巴、眼睛一個特寫,模仿的不能說完全相同,只能說表情一模一樣(最右邊)。這項研究來自慕尼黑工業大學等機構,他們提出了GaussianAvatars,這種
 NeRF是什麼?基於NeRF的三維重建是基於體素嗎?
Oct 16, 2023 am 11:33 AM
NeRF是什麼?基於NeRF的三維重建是基於體素嗎?
Oct 16, 2023 am 11:33 AM
1介紹神經輻射場(NeRF)是深度學習和電腦視覺領域的一個相當新的範式。 ECCV2020論文《NeRF:將場景表示為視圖合成的神經輻射場》(該論文獲得了最佳論文獎)中介紹了這項技術,該技術自此大受歡迎,迄今已獲得近800次引用[1 ]。此方法標誌著機器學習處理3D資料的傳統方式發生了巨大變化。神經輻射場場景表示和可微分渲染過程:透過沿著相機射線採樣5D座標(位置和觀看方向)來合成影像;將這些位置輸入MLP以產生顏色和體積密度;並使用體積渲染技術將這些值合成影像;此渲染函數是可微分的,因此可以透過
 MotionLM:多智能體運動預測的語言建模技術
Oct 13, 2023 pm 12:09 PM
MotionLM:多智能體運動預測的語言建模技術
Oct 13, 2023 pm 12:09 PM
本文經自動駕駛之心公眾號授權轉載,轉載請洽出處。原標題:MotionLM:Multi-AgentMotionForecastingasLanguageModeling論文連結:https://arxiv.org/pdf/2309.16534.pdf作者單位:Waymo會議:ICCV2023論文想法:對於自動駕駛車輛安全規劃來說,可靠地預測道路代理未來行為是至關重要的。本研究將連續軌跡表示為離散運動令牌序列,並將多智能體運動預測視為語言建模任務。我們提出的模型MotionLM有以下幾個優點:首
 自動駕駛第一性之純視覺靜態重建
Jun 02, 2024 pm 03:24 PM
自動駕駛第一性之純視覺靜態重建
Jun 02, 2024 pm 03:24 PM
純視覺的標註方案,主要利用視覺加上一些GPS、IMU和輪速感測器的資料進行動態標註。當然面向量產場景的話,不一定要純視覺,有些量產的車輛裡面,會有像固態雷達(AT128)這樣的感測器。如果從量產的角度做資料閉環,把這些感測器都用上,可以有效解決動態物體的標註問題。但是我們的方案裡面,是沒有固態雷達的。所以,我們就介紹這個最通用的量產標註方案。純視覺的標註方案的核心在於高精度的pose重建。我們採用StructurefromMotion(SFM)的pose重建方案,來確保重建精確度。但是傳
 行人軌跡預測有哪些有效的方法和普遍的Base方法?頂會論文分享!
Oct 17, 2023 am 11:13 AM
行人軌跡預測有哪些有效的方法和普遍的Base方法?頂會論文分享!
Oct 17, 2023 am 11:13 AM
軌跡預測近兩年風頭正猛,但大都聚焦於車輛軌跡預測方向,自動駕駛之心今天就為大家分享頂會NeurIPS上關於行人軌跡預測的演算法—SHENet,在受限場景中人類的移動模式通常在一定程度上符合有限的規律。基於這個假設,SHENet透過學習隱含的場景規律來預測一個人的未來軌跡。文章已經授權自動駕駛之心原創!作者的個人理解由於人類運動的隨機性和主觀性,目前預測一個人的未來軌跡仍然是一個具有挑戰性的問題。然而,由於場景限制(例如平面圖、道路和障礙物)以及人與人或人與物體的互動性,在受限場景中人類的移動模式通
 3D視覺繞不開的點雲配準!一文搞懂所有主流方案與挑戰
Apr 02, 2024 am 11:31 AM
3D視覺繞不開的點雲配準!一文搞懂所有主流方案與挑戰
Apr 02, 2024 am 11:31 AM
作為點集合的點雲有望透過3D重建、工業檢測和機器人操作中,在獲取和生成物體的三維(3D)表面資訊方面帶來一場改變。最具挑戰性但必不可少的過程是點雲配準,即獲得一個空間變換,該變換將在兩個不同座標中獲得的兩個點雲對齊並匹配。這篇綜述介紹了點雲配準的概述和基本原理,對各種方法進行了系統的分類和比較,並解決了點雲配準中存在的技術問題,試圖為該領域以外的學術研究人員和工程師提供指導,並促進點雲配準統一願景的討論。點雲獲取的一般方式分為主動和被動方式,由感測器主動獲取的點雲為主動方式,後期透過重建的方式
