

單卡30秒跑出虛擬3D老婆! Text to 3D產生看清毛孔細節的高精度數字人,無縫銜接Maya、Unity等製作工具

ChatGPT為AI產業注入一劑雞血,一切曾經的不敢想,都成為現今的基操。
正持續進擊的Text-to-3D,就被視為繼Diffusion(圖像)和GPT(文字)後, AIGC領域的下一個前沿熱點,得到了前所未有的關注。
這不,一款名為ChatAvatar的產品低調公測,火速收攬超70萬瀏覽與關注,並登上抱抱臉週熱門(Spaces of the week)。

△ChatAvatar也將支援從AI生成的單視角/多視角原畫生成3D風格化角色的Image to 3D技術,受到了廣泛關注
現行beta版本產生的3D模型,能夠直接連同PBR材質下載到本地。不僅效果不錯,更重要的是免費可玩。有網友驚呼:
有夠酷的,感覺能很便捷地生成自己的數位孿生了。

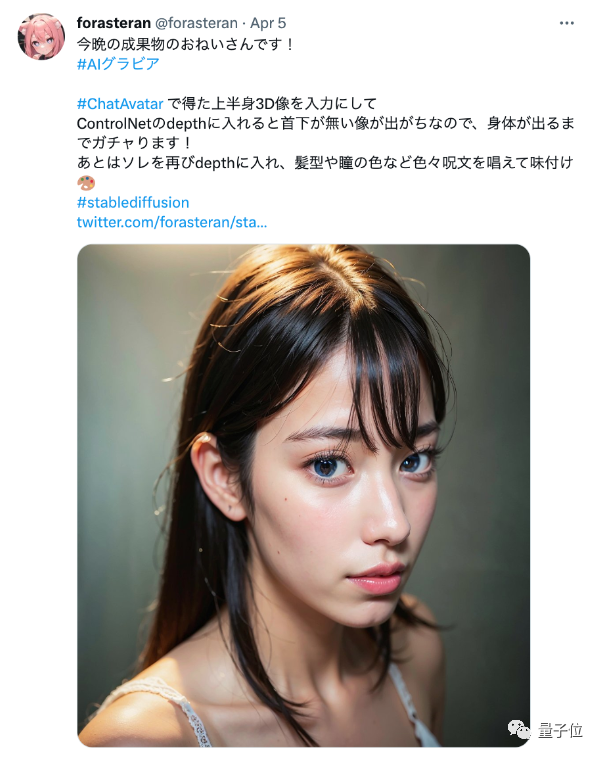
因此吸引不少網友紛紛試用並貢獻腦洞。有人拿這款產品和ControlNet結合,發現效果細膩寫實到有些出乎意料。
這款使用起來幾乎零門檻的Text-to-3D工具名叫ChatAvatar,由國內AI新創公司影眸科技團隊打造。
據了解,這是全球首款Production-Ready的Text to 3D產品,透過簡單的文本,例如一個明星的名字、或是某個想要的人物長相,就能生成影視級的3D超寫實數位人資產。
效率也非常高,平均只需30秒,就能做出一張以假亂真的臉——甚至是你自己的。
未來,生成領域也將拓展到其他三維資產。
且模型帶有規則的拓撲、具有4k解析度的PBR材質,同時帶有綁定,可以直接連接到Unity、Unreal Engine和Maya等製作引擎的生產管線中。
所以,ChatAvatar到底是怎樣一個3D生成工具?背後究竟用到了什麼技術?
30秒完成一次「畫皮」
親身體驗ChatAvatar的玩法發現,可以說是真零門檻。
具體而言,只需以對話的形式,在官網上用大白話向ChatBot描述自己的需求,就能按需生成3D人臉,並覆蓋一張貼合模型的真實「人皮」。
對話全流程裡,根據使用者需求,ChatBot會進行引導,盡可能細節地了解使用者對所需模型的想法。在
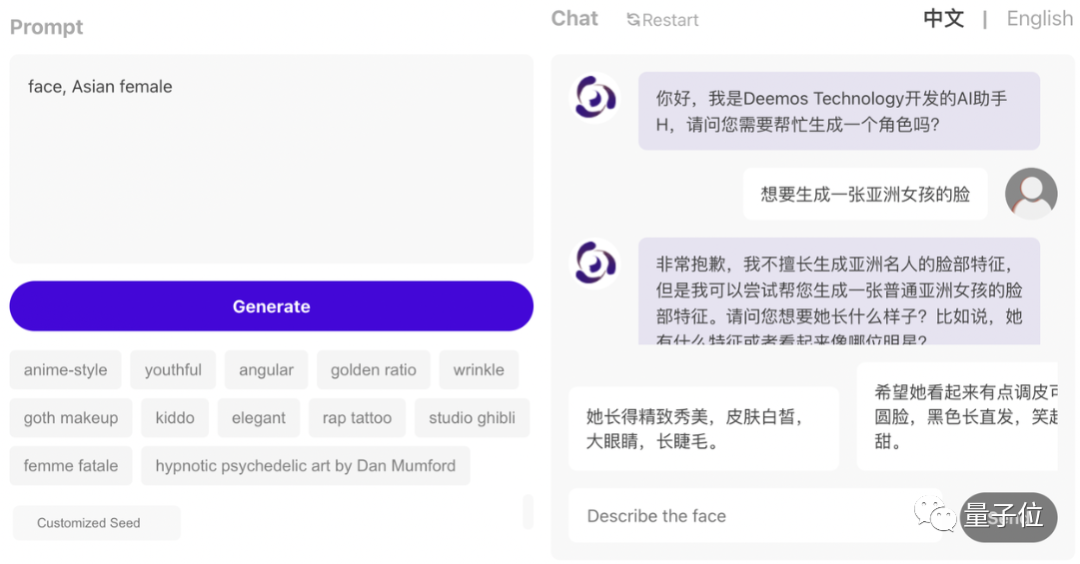
體驗過程中,我們向ChatBot描述了這樣一個想要產生的3D形象:
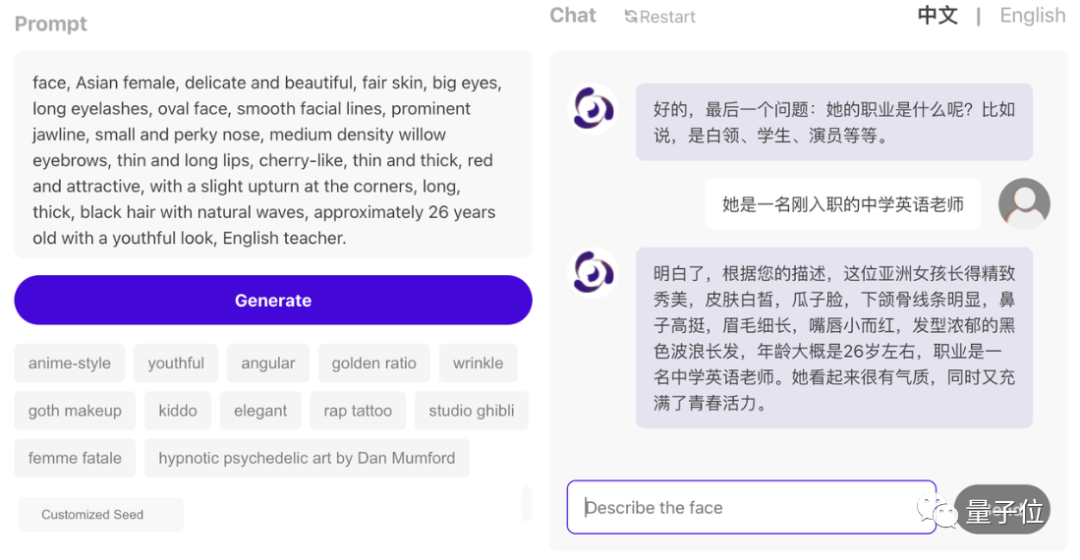
點擊左側的Generate按鈕,平均10s不到,螢幕上就出現根據描述生成的9種不同3D人臉的初始雛形。
隨意選擇其中一種後,會基於選擇繼續優化模型和材質,最後出現覆蓋皮膚後的模型渲染結果,並展現不同光影下的渲染效果——這些渲染在瀏覽器內實時完成:

用滑鼠拖動,還能旋轉頭部,並放大看更細節的局部效果,毛孔和痘痘都清晰可見:

值得一提的是,如果使用者是個提示工程高手,直接在左側框中輸入prompt,同樣可以完成生成。
最後,一鍵下載,就能取得可直接接取製作引擎並被驅動的3D數位頭部資產:
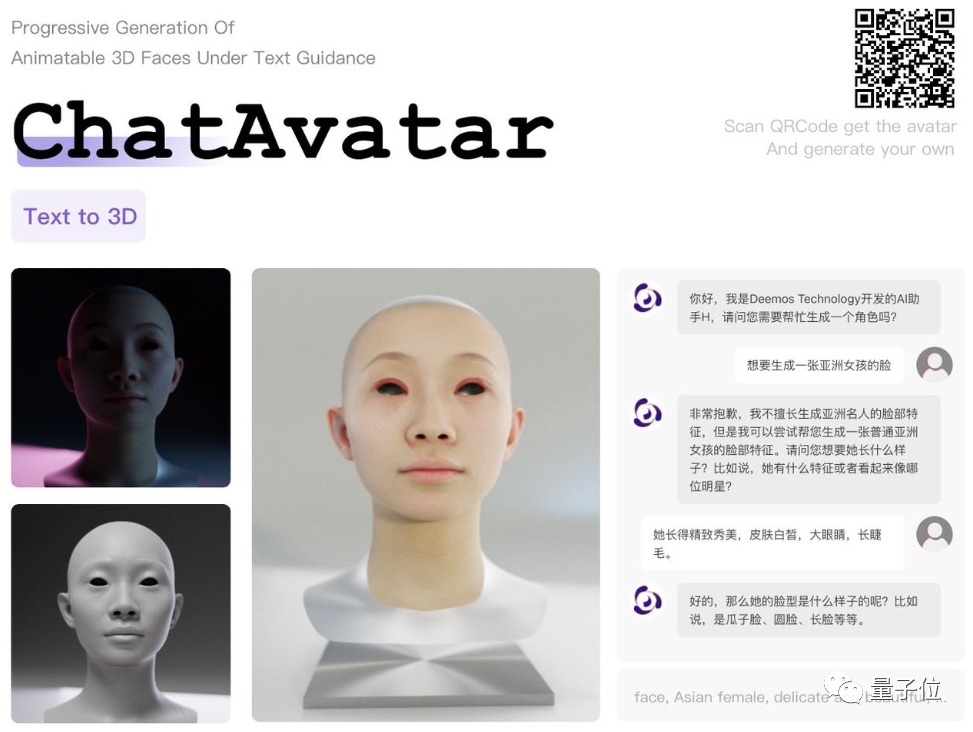
雖然beta版本還沒上線髮型功能,但整體而言,最後產生的3D數位人資產與描述內容已經有高匹配度。
官網上也陳列了許多ChatAvatar用戶的生成資產,不同人種、不同膚色、不同年齡,喜怒哀樂,美醜胖瘦,各式相貌應有盡有。
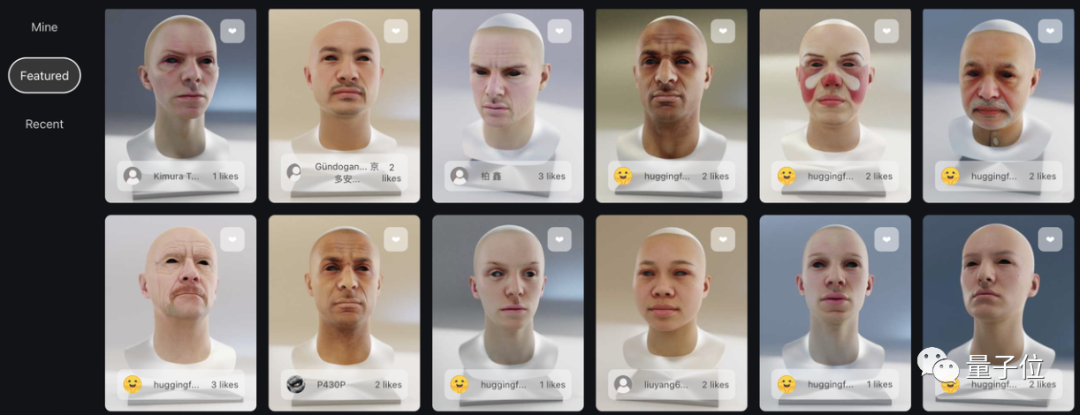
總結一下ChatAvatar這款產品產生3D數字人資產的效果亮點:
首先是使用簡單;其次是生成跨度大,且五官可改,還能生成與臉部貼合的面具、刺青等,譬如這樣:

根據官方宣傳片介紹,ChatAvatar甚至可以進一步生成超越人類範疇的角色,如阿凡達等影視作品中的角色:

最重要的是,ChatAvatar解決了3D模型與傳統渲染軟體存在的相容性問題。
這意味著,ChatAvatar產生的3D資產可以直接連接到遊戲和影視生產流程。
當然,在正式接入工業流程之前,首輪公測,ChatAvatar已經吸引了數千名藝術家和專業美術人員參與,推特相關話題受到近百萬的瀏覽與關注。
隨便一則推文,瀏覽量都能破50k。
累積了大批「自來水」不是沒有原因,看看3D的愛因斯坦之臉,試問誰不說一句真的很像?

要是和ControlNet結合,產生效果不亞於單反相片直出:

已經有不少用戶體驗後,開始暢想將這個Text-to-3D工具大規模地應用在遊戲、影視等工業應用上了。
據了解,使用者回饋會成為ChatAvatar團隊快速迭代和更新的重要依據,形成資料飛輪,以便及時提供更完整、貼近需求的功能。
事實上,對於先前的3D產業設計師或公司來說,大部分AI文字轉3D應用並非效果不好,但實際落地到工業設計流程上,還是有不少難度。
這次ChatAvatar能如此出圈,背後究竟有什麼技術上的原因?
符合產業要求的3D資產生成,究竟難在哪?
都說AI要取代人類,事實上光是Text-to-3D領域,就並非那麼容易取代。
最大的困難,在於讓AI生成的東西從標準上符合產業對3D資產的要求。
這裡面的產業標準怎麼理解?從專業3D美工設計的角度來說,至少有三個面向—
品質、可控制性和生成速度。
首先是質量。尤其是對於強調視覺效果的影視、遊戲產業來說,要想生成符合管線要求的3D資產,拓樸規整度、紋理貼圖的精度等“行業潛規則”,都是AI產品第一道必須邁過去的坎。
以拓樸結構的規整度為例,這裡本質上指的是3D資產佈線的合理度。
對於3D資產來說,拓樸的規整度,往往直接影響物體的動畫效果、修改處理效率和貼圖繪製速度:
據行內3D美工設計介紹,手工重拓撲的時間成本往往比製作3D模型本身更高,甚至以倍數計。這意味著即使AI模型產生的3D資產再酷炫,如果產生的拓樸規整度達不到要求,成本就無法從根本上降低。更別提紋理精度。
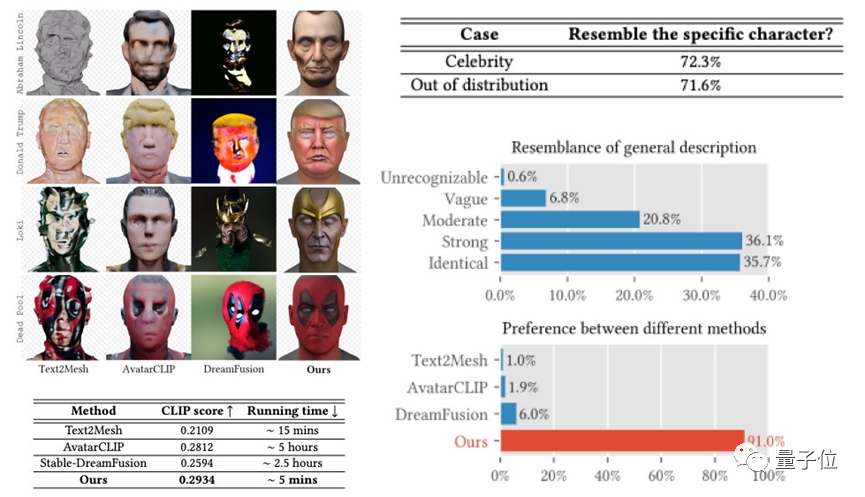
△影眸科技的ChatAvatar專案在產生品質、速度以及標準相容上相比先前的工作都有明顯的提升
以目前遊戲、影視行業普遍要求的PBR貼圖為例,包含的反射率貼圖、法線貼圖等一系列貼圖,相當於2D圖像PSD文件的“圖層”,是3D資產流水線生產必不可少的條件之一。
然而,目前AI生成的3D資產往往是一個“整體”,少有能按要求單獨生成符合產業環境的PBR貼圖的效果。
其次是可控性,對於生成式AI而言,如何讓生成的內容更加“可控”,是CG產業對於這項技術提出的又一大要求。
以大眾所熟知的2D產業為例,在ControlNet出現之前,2D AIGC產業一直處於「半摸黑前進」的狀態。
也就是說,AI能產生指定類別的物體畫面,卻無法產生指定姿態的物體,生成效果全靠提示工程和「玄學」。
而在ControlNet出現後,2D AI影像生成的可控性獲得了突飛猛進的提升,然而對於3D AI而言,要想生成對應效果的資產,很大程度上依舊得依靠專業的提示工程。
最後是生成速度。相較於3D美工設計而言,AI生成的優勢在於速度,然而如果AI渲染的速度與效果無法與人工匹敵的話,那麼這項技術依舊無法為產業帶來效益。
以目前在AI技術上頗受歡迎的NeRF為例,其產業化落地就面臨速度和品質的兼容性難題。
在生成品質較高的情況下,基於NeRF的3D生成往往需要相當漫長的時間;然而如果追求速度,即使是NeRF生成的3D資產便完全無法投入產業使用。
但即使解決了這個問題,如何在不損失精度的前提下讓NeRF與傳統CG行業的主流引擎兼容仍然是一個巨大的問題。
從上面的產業標準化流程不難發現,大部分AI文字轉3D應用程式落地存在兩大瓶頸:
一個是需要手動完成提示工程,對於非AI專業人士、或不了解AI的設計師來說不夠友好;另一個是生成的3D資產往往不符合產業標準,即使再好看也無法投入使用。
針對這兩點,ChatAvatar給出了兩點具體有效的解決方案。
一方面,ChatAvatar實現了手動輸入提示工程外的第二條道路,也是更適合普通人的捷徑:透過「甲方模式」直接對話描述需求。
團隊官方推特介紹稱,為了實現這一特性,ChatAvatar基於GPT的能力,開發了一種對話描述轉人像特徵的方法。
設計師只需要不斷和GPT聊天,描述自己想要的「感覺」:

GPT就能自動幫忙完成提示工程,將結果輸送給AI:
換而言之,如果說ControlNet是2D產業的“Game Changer”,那麼對於3D產業來說,能實現文字轉3D的ChatAvatar ,無異於產業的遊戲規則改變者。
另一方面更為重要,那就是ChatAvatar能完美相容CG管線,即產生的資產在拓樸結構、可控性和速度上都符合產業要求。
這不僅意味著生成3D資產之後,下載的內容可以直接導入各種後製軟體進行二次編輯,可控性更強;
同時,產生的模型和高精準度材質貼圖,還能在後期的渲染中達到極為逼真的渲染效果。
為了達到這樣的效果,團隊為ChatAvatar自研了一個漸進式3D生成框架DreamFace。
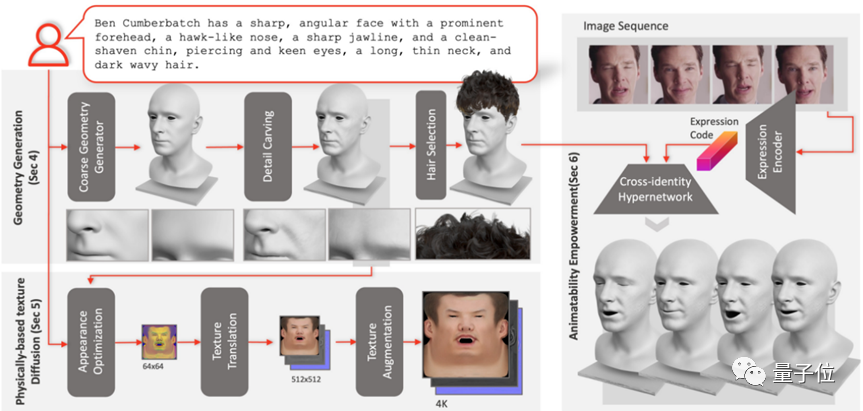
其中的關鍵,在於訓練該模型用的底層數據,即影眸科技基於「穹頂光場」所採集到的世界首個大體量、高精度、多表情的人臉高精度資料集。
基於這個資料集,DreamFace可以有效率地完成產品級三維資產的生成,即生成的資產帶有規則的拓撲、材質,並帶有綁定。
DreamFace主要包括三個模組:幾何體生成,基於物理的材質擴散和動畫能力生成。
透過引入外部3D資料庫,DreamFace能夠直接輸出符合CG流程的資產。

△產生的資產驅動渲染的效果
上述兩大技術瓶頸的解決,本質上進一步加速了AIGC洪流下,「生成」將取代「搜尋」的時代趨勢——
影眸團隊認為,「生成」將成為新一代數位資產的獲取方式。
先前,我們需要找到一張符合需求的圖片或資產時,通常會使用搜尋引擎來查詢。
ChatAvatar專案主頁上展示的巨大的「搜尋框」和整齊的資產卡片,看似搜尋引擎,但實際上是一種與搜尋截然不同的資產查找方式。
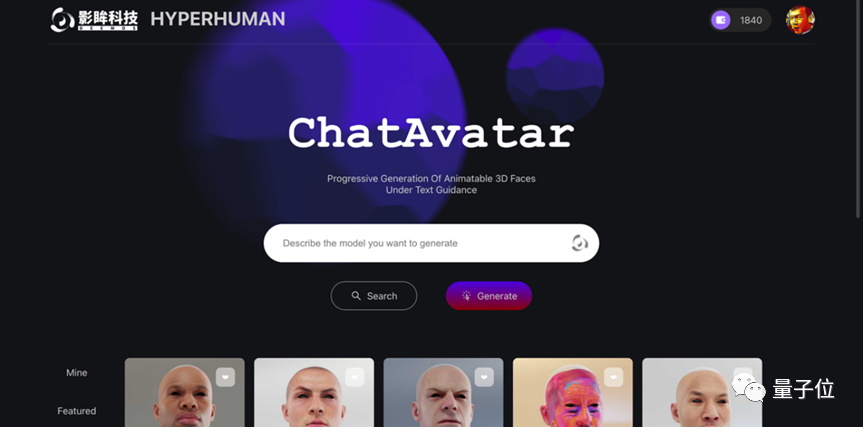
△ChatAvatar專案首頁
影眸科技CTO張啟煊對此介紹:
以前,如果我們需要一張插圖,可能要在多個圖庫中反覆搜索,或是透過Photoshop合成、手繪等較複雜的方式才能得到結果。但在Stable Diffusion等技術出現後,只需要透過文字描述想要的圖像,就能直接產生符合需求的結果。
這對傳統的資產庫來說是一個巨大的衝擊。而ChatAvatar的目標,正是用3D生成取代傳統的搜尋式3D資產庫。
AIGC領域的下一個前沿熱點
ChatGPT一石激起千層浪,進入AI 2.0時代之後,人們的目光也投向包含圖像、視頻、3D等信息的多模態AI。
僅就3D生成領域而言,無論是影視還是遊戲產業,3D內容生產和消費市場已經擁有足夠大的規模,但在製作層面卻因技術難度遭遇掣肘。
譬如,文字領域大行其道的Transformer,在3D生成領域的使用還相對有限。
去年夏天,當文生圖領域因Diffusion Model取得成績後,人們開始期待文字生成3D有同樣驚豔的表現。一旦生成式AI的3D創作技術成熟,VR、影片等的內容創作都將起飛。
△擴散模式Midjourney5.1產生的「梵谷風攝影」
事實上,無論是科技巨頭還是新創公司,的確都在朝Text-to-3D這個方向暗暗發力。
去年9月,Google發布了基於文字提示產生3D模型的FreamFusion,聲稱不需要3D訓練數據,也不需要修改影像擴散模型。緊接在後,Meta也推出可以從文字一鍵產生影片的Make-A-Video模型。
後來的Text-to-3D的AI模型隊伍中,也先後出現了英偉達Magic3D、OpenAI最新開源專案Shap-E等,今年8月將舉辦的電腦圖形頂會SIGGRAPH 2023所展示的論文,也有多篇與Text-to-3D有關。
影眼科技有關文本指導的漸進式3D生成框架DreamFace的論文,就是其中之一。
而ChatAvatar,也是目前為止最集中在3D數位人資產方向的生成式模型產品。
背後的AI新創公司影眸科技,2020年孵化自上海科技大學MARS實驗室,成立後獲得奇績創壇與紅杉種子的兩輪投資。
公司專注於專注於電腦圖形學、生成式AI的研究與產品化。 2021年,AIGC還未掀起巨浪之時,公司就已經推出國內首個AIGC ToC繪畫應用Wand,產品一度登頂AppStore分區榜首。

而這個頗具前瞻性,且已在業界小有名氣的團隊,平均年齡只有25歲。
將首個商業化場景具體錨定在數字人後,ChatAvatar是他們乘坐AIGC東風在該方向的最新進展。
作為一個新推出的產品,ChatAvatar在相容性、完成度和精確度等產品效果層面,都超越了影眼團隊預期。然而在吳迪口中,行至此處的過程「很狼狽」。
主要原因不外乎「缺人」一事。目前,影眸已經在多類別3D生成技術上取得了進展,下一步也計畫推出「3D生成大模型」。
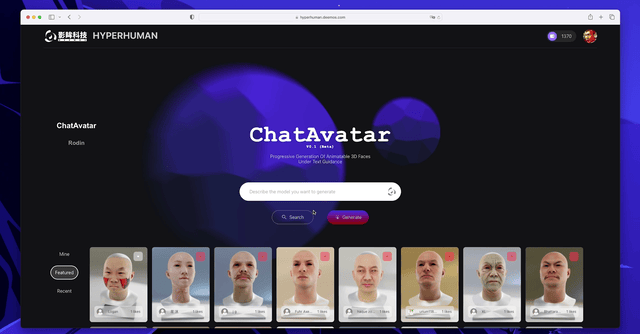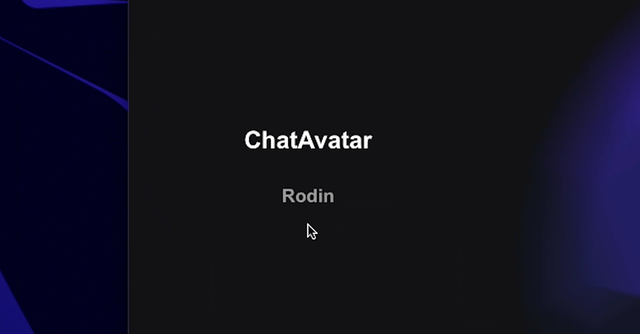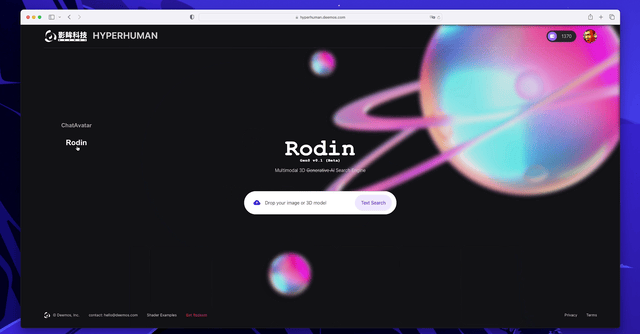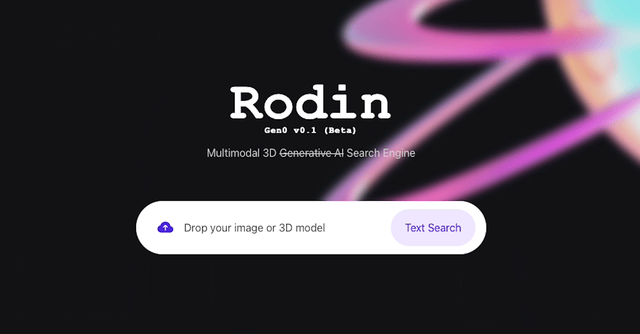
#△影眸科技將於5月上線首個多模態跨平台3D搜尋引擎Rodin,打通Sketchfab等多個3D資產平台,支援以文搜3D、以圖搜尋3D甚至以3D搜尋3D。搜尋引擎只是Rodin的初級形態,影眸將把Rodin打造為3D生成大模型。
需要持續向前推進,就需要更多的工程化團隊、技術美術和擁抱生成式AI的產品人才加入團隊。作為一個以研發為背景主基調的團隊,這樣的人才仍然很緊張。
「人是萬物的尺度,」吳迪表示道,「我們需要更多志同道合的人加入,共同推動3D領域的創新發展。」
可以看到,ChatAvatar背後技術從無到有的搭建,揭示了一家AI新創公司的不斷創新;而從這家公司對人才的渴望以小見大,更揭示著AIGC浪潮下,每一個細分領域想要從水下浮出水面的心。
你願意擁抱生成式AI,成為Text-to-3D領域的Game Changer嗎?
以上是單卡30秒跑出虛擬3D老婆! Text to 3D產生看清毛孔細節的高精度數字人,無縫銜接Maya、Unity等製作工具的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!
熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 為何在自動駕駛方面Gaussian Splatting如此受歡迎,開始放棄NeRF?
Jan 17, 2024 pm 02:57 PM
為何在自動駕駛方面Gaussian Splatting如此受歡迎,開始放棄NeRF?
Jan 17, 2024 pm 02:57 PM
寫在前面&筆者的個人理解三維Gaussiansplatting(3DGS)是近年來在顯式輻射場和電腦圖形學領域出現的一種變革性技術。這種創新方法的特點是使用了數百萬個3D高斯,這與神經輻射場(NeRF)方法有很大的不同,後者主要使用隱式的基於座標的模型將空間座標映射到像素值。 3DGS憑藉其明確的場景表示和可微分的渲染演算法,不僅保證了即時渲染能力,而且引入了前所未有的控制和場景編輯水平。這將3DGS定位為下一代3D重建和表示的潛在遊戲規則改變者。為此我們首次系統性地概述了3DGS領域的最新發展與關
 ChatGPT 現在允許免費用戶使用 DALL-E 3 產生每日限制的圖像
Aug 09, 2024 pm 09:37 PM
ChatGPT 現在允許免費用戶使用 DALL-E 3 產生每日限制的圖像
Aug 09, 2024 pm 09:37 PM
DALL-E 3 於 2023 年 9 月正式推出,是比其前身大幅改進的車型。它被認為是迄今為止最好的人工智慧圖像生成器之一,能夠創建具有複雜細節的圖像。然而,在推出時,它不包括
 手機怎麼安裝chatgpt
Mar 05, 2024 pm 02:31 PM
手機怎麼安裝chatgpt
Mar 05, 2024 pm 02:31 PM
安裝步驟:1、在ChatGTP官網或手機商店下載ChatGTP軟體;2、開啟後在設定介面中,選擇語言為中文;3、在對局介面中,選擇人機對局並設定中文相譜;4 、開始後在聊天視窗中輸入指令,即可與軟體互動。
 選擇相機還是光達?實現穩健的三維目標檢測的最新綜述
Jan 26, 2024 am 11:18 AM
選擇相機還是光達?實現穩健的三維目標檢測的最新綜述
Jan 26, 2024 am 11:18 AM
0.寫在前面&&個人理解自動駕駛系統依賴先進的感知、決策和控制技術,透過使用各種感測器(如相機、光達、雷達等)來感知周圍環境,並利用演算法和模型進行即時分析和決策。這使得車輛能夠識別道路標誌、檢測和追蹤其他車輛、預測行人行為等,從而安全地操作和適應複雜的交通環境。這項技術目前引起了廣泛的關注,並認為是未來交通領域的重要發展領域之一。但是,讓自動駕駛變得困難的是弄清楚如何讓汽車了解周圍發生的事情。這需要自動駕駛系統中的三維物體偵測演算法可以準確地感知和描述周圍環境中的物體,包括它們的位置、
 ChatGPT與Python的完美結合:打造智慧客服聊天機器人
Oct 27, 2023 pm 06:00 PM
ChatGPT與Python的完美結合:打造智慧客服聊天機器人
Oct 27, 2023 pm 06:00 PM
ChatGPT與Python的完美結合:打造智慧客服聊天機器人引言:在當今資訊時代,智慧客服系統已成為企業與客戶之間重要的溝通工具。而為了提供更好的客戶服務體驗,許多企業開始轉向採用聊天機器人的方式來完成客戶諮詢、問題解答等任務。在這篇文章中,我們將介紹如何使用OpenAI的強大模型ChatGPT和Python語言結合,來打造一個智慧客服聊天機器人,以提高
 CLIP-BEVFormer:明確監督BEVFormer結構,提升長尾偵測性能
Mar 26, 2024 pm 12:41 PM
CLIP-BEVFormer:明確監督BEVFormer結構,提升長尾偵測性能
Mar 26, 2024 pm 12:41 PM
寫在前面&筆者的個人理解目前,在整個自動駕駛系統當中,感知模組扮演了其中至關重要的角色,行駛在道路上的自動駕駛車輛只有通過感知模組獲得到準確的感知結果後,才能讓自動駕駛系統中的下游規控模組做出及時、正確的判斷和行為決策。目前,具備自動駕駛功能的汽車中通常會配備包括環視相機感測器、光達感測器以及毫米波雷達感測器在內的多種數據資訊感測器來收集不同模態的信息,用於實現準確的感知任務。基於純視覺的BEV感知演算法因其較低的硬體成本和易於部署的特點,以及其輸出結果能便捷地應用於各種下游任務,因此受到工業
 牛津大學最新! Mickey:3D中的2D影像匹配SOTA! (CVPR\'24)
Apr 23, 2024 pm 01:20 PM
牛津大學最新! Mickey:3D中的2D影像匹配SOTA! (CVPR\'24)
Apr 23, 2024 pm 01:20 PM
寫在前面項目連結:https://nianticlabs.github.io/mickey/給定兩張圖片,可以透過建立圖片之間的對應關係來估計它們之間的相機姿態。通常,這些對應關係是二維到二維的,而我們估計的姿態在尺度上是不確定的。一些應用,例如隨時隨地實現即時增強現實,需要尺度度量的姿態估計,因此它們依賴外部的深度估計器來恢復尺度。本文提出了MicKey,這是一個關鍵點匹配流程,能夠夠預測三維相機空間中的度量對應關係。透過學習跨影像的三維座標匹配,我們能夠在沒有深度測試的情況下推斷度量相對
 LLM全搞定! OmniDrive:集3D感知、推理規劃於一體(英偉達最新)
May 09, 2024 pm 04:55 PM
LLM全搞定! OmniDrive:集3D感知、推理規劃於一體(英偉達最新)
May 09, 2024 pm 04:55 PM
寫在前面&筆者的個人理解這篇論文致力於解決當前多模態大語言模型(MLLMs)在自動駕駛應用中存在的關鍵挑戰,即將MLLMs從2D理解擴展到3D空間的問題。由於自動駕駛車輛(AVs)需要針對3D環境做出準確的決策,這項擴展顯得格外重要。 3D空間理解對於AV來說至關重要,因為它直接影響車輛做出明智決策、預測未來狀態以及與環境安全互動的能力。目前的多模態大語言模型(如LLaVA-1.5)通常只能處理較低解析度的影像輸入(例如),這是由於視覺編碼器的分辨率限制,LLM序列長度的限制。然而,自動駕駛應用需
