
译者 | 李睿
审校 | 孙淑娟
文本分类是将文本分类为一个或多个不同类别以组织、构造和过滤成任何参数的过程。例如,文本分类用于法律文件、医学研究和文件中,或者简单地用于产品评论。数据比以往任何时候都更重要;很多企业花费巨资试图获取尽可能多的洞察力。
随着文本/文档数据比其他数据类型丰富得多,使用新方法势在必行。由于数据本质上是非结构化的,并且极其丰富,因此以易于理解的方式组织数据以理解它可以显著地提高其价值。使用文本分类和机器学习可以更快、更经济高效地自动构造相关文本。
以下将定义文本分类、其工作原理、一些最知名的算法,并提供可能有助于开始文本分类之旅的数据集。

一些基本方法可以在一定程度上对不同的文本文档进行分类,但最常用的方法采用机器学习。文本分类模型在部署之前需要经历六个基本步骤。
数据集是原始数据块,用作模型的数据源。在文本分类的情况下,使用监督机器学习算法,为机器学习模型提供标记数据。标记数据是为算法预定义的数据,并附有信息标签。
由于机器学习模型只能理解数值,因此需要对提供的文本进行标记化和文字嵌入,以使模型能够正确识别数据。
标记化是将文本文档拆分成更小的部分(称为标记)的过程。标记可以表示为整个单词、子单词或单个字符。例如,可以这样更智能地标记工作:
为什么标记化很重要?因为文本分类模型只能在基于标记的级别上处理数据,不能理解和处理完整的句子。模型需要对给定的原始数据集进行进一步处理才能轻松消化给定的数据。删除不必要的功能,过滤掉空值和无限值等等。重组整个数据集将有助于防止在训练阶段出现任何偏差。
希望在保留20%的数据集的同时,在80%的数据集上训练数据,以测试算法的准确性。
通过使用训练数据集运行模型,该算法可以通过识别隐藏的模式和见解将提供的文本分类为不同类别。
接下来,使用步骤3中提到的测试数据集测试模型的完整性。测试数据集将被取消标记,以根据实际结果测试模型的准确性。为了准确测试模型,测试数据集必须包含新的测试用例(与以前的训练数据集不同的数据),以避免过度拟合模型。
通过调整模型的不同超参数来调整机器学习模型,而不会过度拟合或产生高方差。超参数是一个参数,其值控制模型的学习过程。现在可以部署了。
在以上提到的过滤过程中,机器和深度学习算法只能理解数值,迫使开发人员对数据集执行一些单词嵌入技术。单词嵌入是将单词表示为实值向量的过程,实值向量可以对给定单词的含义进行编码。
以下是三種最著名、最有效的文字分類演算法。需要記住,每種方法中都嵌入了進一步的定義演算法。
線性支援向量機演算法被認為是目前最好的文字分類演算法之一,它根據給定的特徵繪製給定的資料點,然後繪製一條最佳擬合線,將資料拆分並分類為不同的類別。
邏輯迴歸是迴歸的子類,主要關注分類問題。它使用決策邊界、回歸和距離來評估和分類資料集。
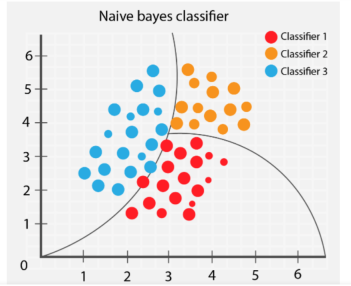
樸素貝葉斯演算法根據物件提供的特徵對不同的物件進行分類。然後繪製組邊界以推斷這些組分類以進一步解決和分類。
為演算法提供低品質資料將導致糟糕的未來預測。對於機器學習從業者來說,一個常見的問題是,向訓練模型提供的資料集過多,並且包括不必要的特徵。過度使用不相關的數據會導致模型性能的下降。而在選擇和組織資料集時,越少越好。
錯誤的訓練與測試資料的比率會大大影響模型的效能,並影響資料的洗牌和篩選。精確的數據點不會被其他不必要的因素所干擾,訓練模型將更有效地執行。
在訓練模型時,選擇符合模型要求的資料集,過濾不必要的值,洗牌資料集,並測試最終模型的準確性。更簡單的演算法需要更少的計算時間和資源,而最好的模型是可以解決複雜問題的最簡單的模型。
在訓練達到高峰時,模型的準確度隨著訓練的持續逐漸降低。這稱為過度擬合;由於訓練持續時間過長,模型開始學習意想不到的模式。在訓練集上實現高精度時要小心,因為主要目標是開發其準確性植根於測試集的模型(模型以前從未見過的資料)。
另一方面,欠擬合是指訓練模型仍有改進的空間,尚未達到最大潛力。訓練不佳的模型源自於訓練的時間長度或對資料集過度正規化。這體現了擁有簡潔和精確數據的意義。
在訓練模式時找到最佳位置至關重要。將資料集拆分為80/20是一個很好的開始,但調整參數可能是特定模型需要以最佳方式執行的操作。
儘管在本文中沒有詳細提及,但針對文字分類問題使用正確的文字格式將獲得更好的結果。一些表示文字資料的方法包括GloVe、Word2Vec和嵌入模型。
使用正確的文字格式將改善模型讀取和解釋資料集的方式,進而幫助它理解模式。

擁有大量標記和即用型資料集,隨時可以搜尋符合模型要求的完美資料集。
雖然在決定使用哪一個時可能會遇到一些問題,但以下將推薦一些可供公眾使用的最知名的資料集。
Kaggle等網站包含涵蓋所有主題的各種資料集。可以嘗試在上述幾個資料集上運行模型進行練習。
隨著機器學習在過去十年中產生了巨大的影響,企業正在嘗試一切可能的方法來利用機器學習實現流程自動化。評論、貼文、文章、期刊和文件在文本中都具有無價的價值。而透過以多種創意方式使用文字分類來提取使用者見解和模式,企業可以做出有數據支援的決策;專業人士可以比以往更快地獲取和學習有價值的資訊。
原文標題:What Is Text Classification?,作者:Kevin Vu
以上是什麼是文本分類?的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















