

百度文心一言在國產模型中倒數?我看懵了

夕小瑤科技說 原創
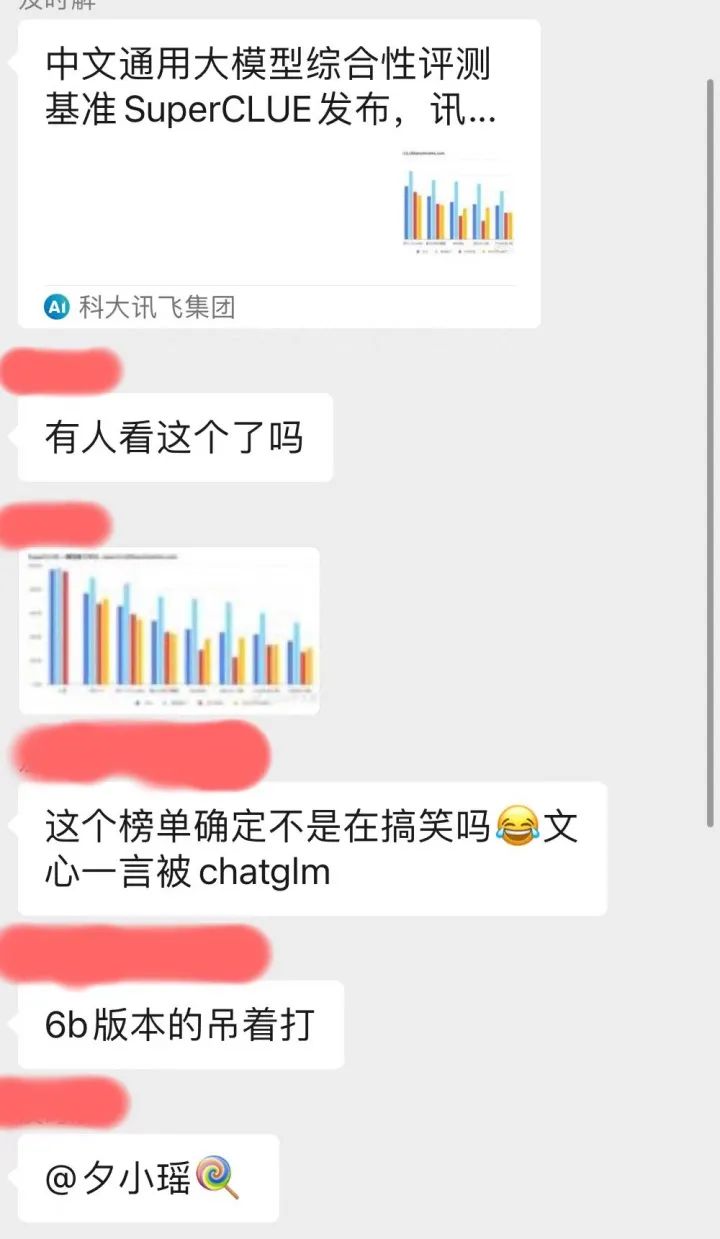
作者 | 賣萌醬最近幾天,我們公眾號的社群在紛紛轉發一張名為SuperClue 評測的截圖。科大訊飛甚至在官號進行了宣傳:

由於訊飛星火大模型剛發布,筆者玩的少,它是不是真的是國產最強這個筆者不敢下結論。
但在這篇評測截圖中,當下國產模型中熱度最高的百度文心一言竟然連一個小型的學術開源模型ChatGLM-6B都打不過。這不僅與筆者自己的使用體驗嚴重不符,而且在我們的專業NLP技術社群中,大家也紛紛表示一臉懵逼:
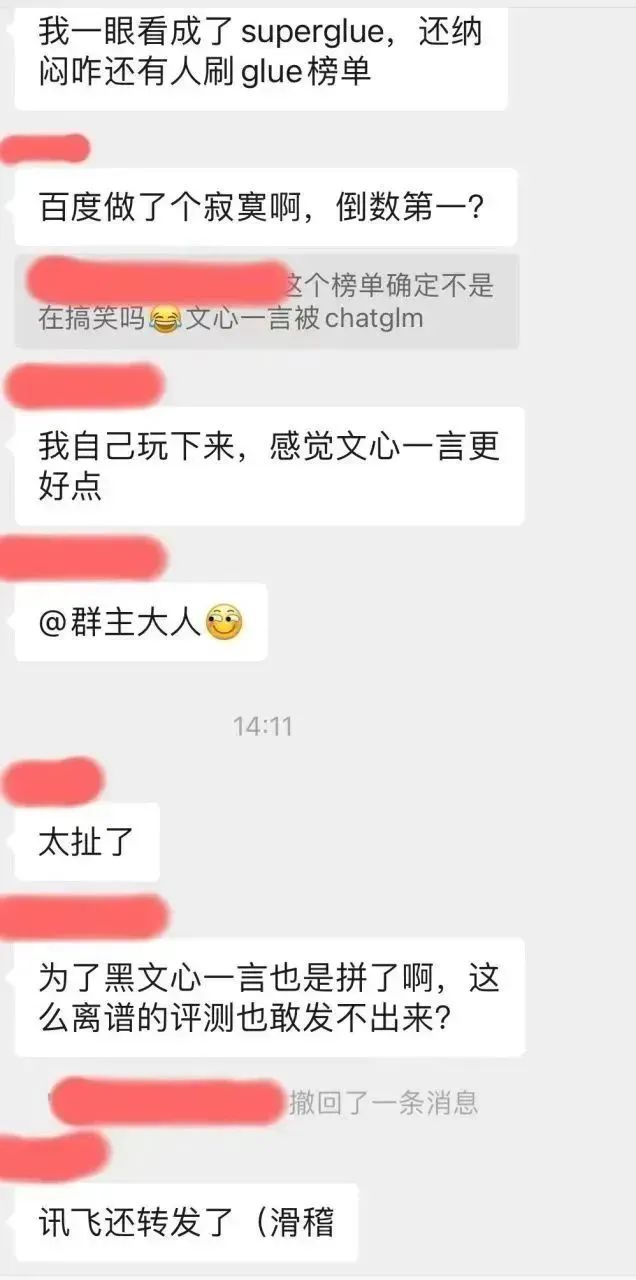
好奇之下,筆者去這個superclue榜的github,想看看這個評量結論是怎麼得出來的:https://www.php.cn/link/97c8dd44858d3568fdf9537c4b8743b2
首先筆者註意到這個repo下面已經有一些issue了:
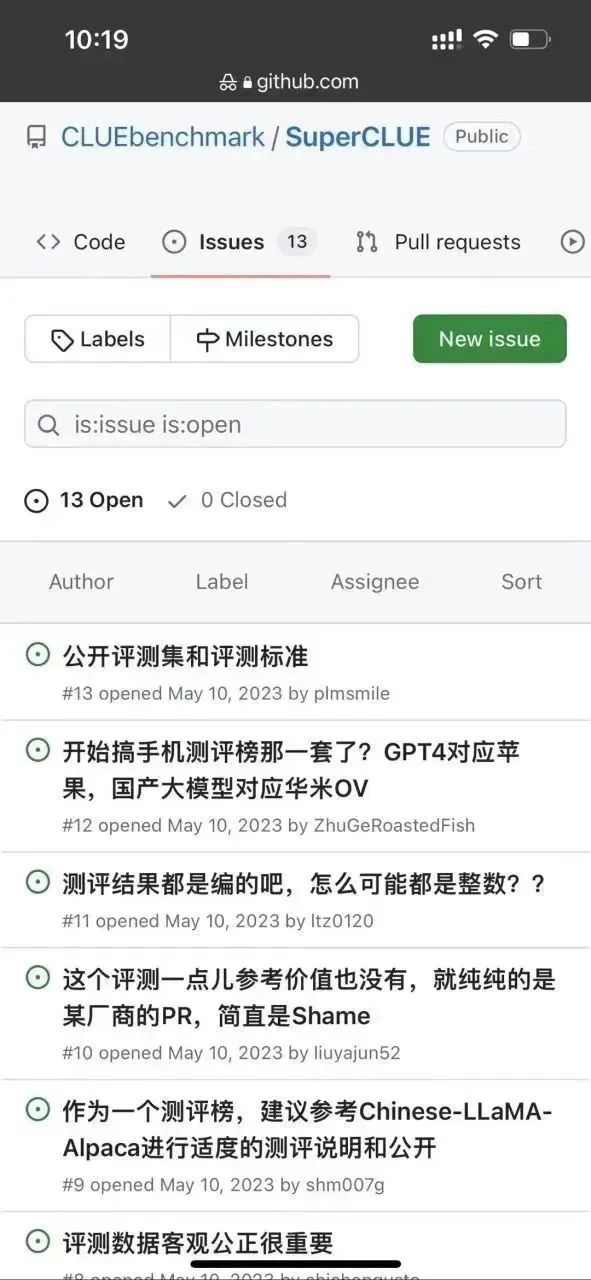
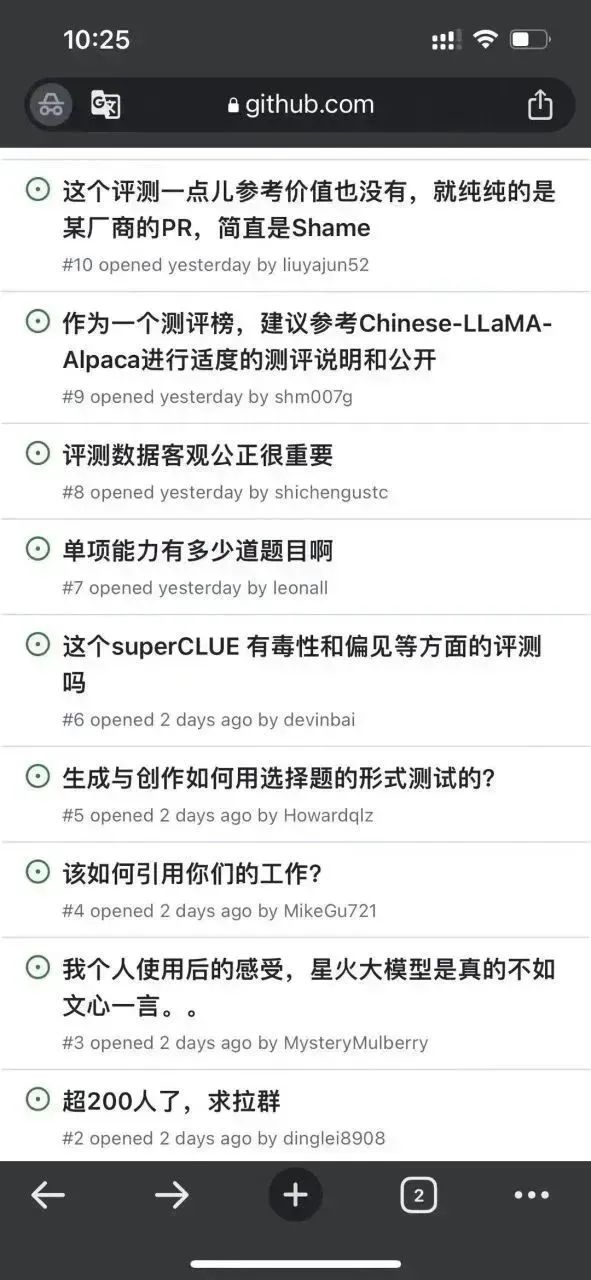
#看起來這個離譜的感覺不只是筆者有,果然群眾的眼睛還是雪亮的。 。 。
筆者進一步看了一下這個榜單的評測方式:

#好傢伙,原來所謂的生成式大模型的測試,竟然全都是讓模型做選擇題。 。 。
很明顯這種做選擇題的評測方式是針對BERT時代的判別式AI模型的,那時候的AI模型普遍不具備生成能力,僅僅有判別能力(比如能判別一段文本屬於什麼類別,選項中哪一個是問題的正確答案,判斷兩段文本的語意是否一致等)。
而生成式模型的評測與判別式模型的評測有相當於大的差異。
例如,對於機器翻譯這種特殊的生成任務而言,一般採用BLEU等評估指標來偵測模型產生的回覆與參考回覆之間的「詞彙、短語覆蓋度」。但機器翻譯這種有參考回應的生成類任務是極少數,絕大多數的生成類評測都要採用人工評測的方式。
例如閒聊式對話生成、文本風格遷移、篇章生成、標題生成、文本摘要等生成任務,都需要各個待評測模型去自由生成回复,然後人工去對比這些不同模型生成的回复的質量,或人工判斷是否滿足了任務需求。
目前這一輪的AI競爭,是模型生成能力的競爭,而不是模型判別能力的競爭。最有評價權的是真實的用戶口碑,不再是個冰冷的學術榜單。更何況是一個壓根沒測模型產生能力的榜單。
回想起來前幾年-
2019年,OpenAI發布了GPT-2的時候,我們在堆tricks刷榜;
2020年,OpenAI發布了GPT-3的時候,我們在堆tricks刷榜;
2021-2022年,FLAN、T0、InstructGPT等instruction tuning和RLHF工作爆發的時候,我們還有不少團隊在堅持堆tricks刷榜…
希望這波生成式模型的軍備競賽,我們不要再重蹈覆轍。
那麼生成式AI模型到底該怎麼測?
很抱歉,我前面說過,如果想做到無偏測試,非常非常的難,甚至比你自研一個生成式模型出來難得多。難度有哪些?具體拋幾個問題:
- 评测维度该如何划分?按理解、记忆、推理、表达?按专业领域?还是将传统的NLP生成式评测任务杂揉起来?
- 评测人员如何培训?对于写代码、debug、数学推导、金融法律医疗问答这种专业门槛极高的测试题,该如何招募人员测试?
- 主观性极高的测试题(如生成小红书风格的文案),该如何定义评测标准?
- 问几个泛泛的写作类问题就能代表一个模型的文本生成/写作能力了吗?
- 考察模型的文本生成子能力,篇章生成、问答生成、翻译、摘要、风格迁移都覆盖到了吗?各个任务的占比均匀吗?评判标准都清晰吗?统计显著吗?
- 在上面的问答生成子任务里,科学、医疗、汽车、母婴、金融、工程、政治、军事、娱乐等各个垂类都覆盖到了吗?占比均匀吗?
- 如何测评对话能力?对话的一致性、多样性、话题深度、人格化分别怎么设计的考察任务?
- 对于同一项能力测试,简单问题、中等难度问题和复杂长冷问题都覆盖到了吗?如何界定?分别占比多少?
这只是随手抛的几个要解决的基础问题,在实际基准设计的过程中,要面临大量比以上问题棘手得多的问题。
因此,作为AI从业者,笔者呼吁大家理性看待各类AI模型排名。连一个无偏的测试基准都没有出现,要这排名有何用?
还是那句话,一个生成式模型好不好,真实用户说了算。
一个模型在一个榜单的排名再高,它解决不好你在意的问题,它对你来说就是个一般般的模型。换言之,一个排名倒数的模型,如果在你关注的场景下发现非常强,那它对你来说就是个宝藏模型。
在此,笔者公开了我们团队内部富集和撰写的一个hard case(困难样例)测试集。这份测试集重点关注模型对困难问题/指令的解决能力。
这个困难测试集重点考察了模型的语言理解、复杂指令理解与遵循、文本生成、复杂内容生成、多轮对话、矛盾检测、常识推理、数学推理、反事实推理、危害信息识别、法律伦理意识、中国文学知识、跨语言能力和代码能力等。
再次强调一遍,这是笔者团队为测试生成式模型对困难样例解决能力而做的一个case集,评测结果只能代表“对笔者团队而言,哪个模型感觉更好”,远远不能代表一个无偏的测试结论,如果想要无偏的测试结论,请先解答以上提到的测评问题,再去定义权威测试基准。
想要自己评测验证的小伙伴,可以在本公众号“夕小瑶科技说”后台回复【AI评测】口令来下载测试文件
以下是在superclue榜单中受争议最大的讯飞星火、文心一言与ChatGPT这三个模型的测评结果:



困难Case解决率:
- ChatGPT(GPT-3.5-turbo):11/24=45.83%
- 文心一言(2023.5.10版本):13/24=54.16%
- 讯飞星火(2023.5.10版本):7/24=29.16%
这是要论证讯飞星火不如文心一言吗?如果你仔细看前文了,就明白笔者想说什么。
确实,尽管在这份我们内部的困难case集上,星火模型不如文心一言,但这不能说明综合起来谁一定比谁强,仅仅说明,在我们团队内部的困难case测试集上,文心一言表现最强,甚至比ChatGPT多解决了2个困难case。
對於簡單問題而言,其實國產模型跟ChatGPT已經沒有太大差距。而對於困難問題而言,各個模型各有所長。就筆者團隊的綜合使用經驗來看,文心一言完全足以吊打ChatGLM-6B等學術測驗性質的開源模型,部分能力上不如ChatGPT,部分能力上又超越了ChatGPT。
阿里通義千問、訊飛星火等其他大廠出品的國產模型也是相同的道理。
還是那句話,如今連一個無偏的測試基準都沒出現,你要那模型排名有啥用?
比起爭論各類有偏的榜單排名,不如像筆者團隊一樣去做一個自己關心的測試集。
能解決你問題的模型,就是好模型。
以上是百度文心一言在國產模型中倒數?我看懵了的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 無需OpenAI數據,躋身程式碼大模型榜單! UIUC發表StarCoder-15B-Instruct
Jun 13, 2024 pm 01:59 PM
無需OpenAI數據,躋身程式碼大模型榜單! UIUC發表StarCoder-15B-Instruct
Jun 13, 2024 pm 01:59 PM
在软件技术的前沿,UIUC张令明组携手BigCode组织的研究者,近日公布了StarCoder2-15B-Instruct代码大模型。这一创新成果在代码生成任务取得了显著突破,成功超越CodeLlama-70B-Instruct,登上代码生成性能榜单之巅。StarCoder2-15B-Instruct的独特之处在于其纯自对齐策略,整个训练流程公开透明,且完全自主可控。该模型通过StarCoder2-15B生成了数千个指令,响应对StarCoder-15B基座模型进行微调,无需依赖昂贵的人工标注数
 Yolov10:詳解、部署、應用一站式齊全!
Jun 07, 2024 pm 12:05 PM
Yolov10:詳解、部署、應用一站式齊全!
Jun 07, 2024 pm 12:05 PM
一、前言在过去的几年里,YOLOs由于其在计算成本和检测性能之间的有效平衡,已成为实时目标检测领域的主导范式。研究人员探索了YOLO的架构设计、优化目标、数据扩充策略等,取得了显著进展。同时,依赖非极大值抑制(NMS)进行后处理阻碍了YOLO的端到端部署,并对推理延迟产生不利影响。在YOLOs中,各种组件的设计缺乏全面彻底的检查,导致显著的计算冗余,限制了模型的能力。它提供了次优的效率,以及相对大的性能改进潜力。在这项工作中,目标是从后处理和模型架构两个方面进一步提高YOLO的性能效率边界。为此
 清華接手,YOLOv10問世:效能大幅提升,登上GitHub熱門榜
Jun 06, 2024 pm 12:20 PM
清華接手,YOLOv10問世:效能大幅提升,登上GitHub熱門榜
Jun 06, 2024 pm 12:20 PM
目標偵測系統的標竿YOLO系列,再次獲得了重磅升級。自今年2月YOLOv9發布之後,YOLO(YouOnlyLookOnce)系列的接力棒傳到了清華大學研究人員的手上。上週末,YOLOv10推出的消息引發了AI界的關注。它被認為是電腦視覺領域的突破性框架,以其即時的端到端目標檢測能力而聞名,透過提供結合效率和準確性的強大解決方案,延續了YOLO系列的傳統。論文網址:https://arxiv.org/pdf/2405.14458專案網址:https://github.com/THU-MIG/yo
 GoogleGemini 1.5技術報告:輕鬆證明奧數題,Flash版比GPT-4 Turbo快5倍
Jun 13, 2024 pm 01:52 PM
GoogleGemini 1.5技術報告:輕鬆證明奧數題,Flash版比GPT-4 Turbo快5倍
Jun 13, 2024 pm 01:52 PM
今年2月,Google上線了多模態大模型Gemini1.5,透過工程和基礎設施最佳化、MoE架構等策略大幅提升了效能和速度。擁有更長的上下文,更強推理能力,可以更好地處理跨模態內容。本週五,GoogleDeepMind正式發布了Gemini1.5的技術報告,內容涵蓋Flash版等最近升級,該文件長達153頁。技術報告連結:https://storage.googleapis.com/deepmind-media/gemini/gemini_v1_5_report.pdf在本報告中,Google介紹了Gemini1
 deepseek網頁版入口 deepseek官網入口
Feb 19, 2025 pm 04:54 PM
deepseek網頁版入口 deepseek官網入口
Feb 19, 2025 pm 04:54 PM
DeepSeek 是一款強大的智能搜索與分析工具,提供網頁版和官網兩種訪問方式。網頁版便捷高效,免安裝即可使用;官網則提供全面產品信息、下載資源和支持服務。無論個人還是企業用戶,都可以通過 DeepSeek 輕鬆獲取和分析海量數據,提升工作效率、輔助決策和促進創新。
 綜述!全面概括基礎模型對於推動自動駕駛的重要作用
Jun 11, 2024 pm 05:29 PM
綜述!全面概括基礎模型對於推動自動駕駛的重要作用
Jun 11, 2024 pm 05:29 PM
写在前面&笔者的个人理解最近来,随着深度学习技术的发展和突破,大规模的基础模型(FoundationModels)在自然语言处理和计算机视觉领域取得了显著性的成果。基础模型在自动驾驶当中的应用也有很大的发展前景,可以提高对于场景的理解和推理。通过对丰富的语言和视觉数据进行预训练,基础模型可以理解和解释自动驾驶场景中的各类元素并进行推理,为驾驶决策和规划提供语言和动作命令。基础模型可以根据对驾驶场景的理解来实现数据增强,用于提供在常规驾驶和数据收集期间不太可能遇到的长尾分布中那些罕见的可行
 不同資料集有不同的Scaling law?而你可用一個壓縮演算法來預測它
Jun 07, 2024 pm 05:51 PM
不同資料集有不同的Scaling law?而你可用一個壓縮演算法來預測它
Jun 07, 2024 pm 05:51 PM
一般而言,訓練神經網路耗費的運算量越大,其效能就越好。在擴大計算規模時,必須要做個決定:是增加模型參數量還是提升資料集大小-必須在固定的計算預算下權衡這兩個因素。增加模型參數量的好處是可以提高模型的複雜度和表達能力,從而更好地擬合訓練資料。然而,過多的參數可能導致過度擬合,使得模型在未見過的數據上表現不佳。另一方面,擴大資料集大小可以提高模型的泛化能力,減少過度擬合問題。我們告訴你們:只要能適當分配參數和數據,就能在固定計算預算下達到效能最大化。之前已有不少研究探索過神經語言模型的Scalingl
 模組化重構LLaVA,替換組件只需添加1-2個文件,開源TinyLLaVA Factory來了
Jun 08, 2024 pm 09:21 PM
模組化重構LLaVA,替換組件只需添加1-2個文件,開源TinyLLaVA Factory來了
Jun 08, 2024 pm 09:21 PM
TinyLLaVA+計畫由清華大學電子系多媒體訊號與智慧資訊處理實驗室(MSIIP)吳及教授團隊及北京航空航天大學人工智慧學院黃雷老師團隊聯袂打造。清華大學MSIIP實驗室長期致力於智慧醫療、自然語言處理與知識發現、多模態等研究領域。北京航空團隊長期致力於深度學習、多模態、電腦視覺等研究領域。 TinyLLaVA+計畫的目標是開發一種小型跨語言智慧助手,具備語言理解、問答、對話等多模態能力。專案團隊將充分發揮各自的優勢,共同攻克技術難題,實現智慧助理的設計與開發。這將為智慧醫療、自然語言處理與知
