

對資料科學家來說,說故事是一個至關重要的技能。為了表達我們的想法並且說服別人,我們需要有效的溝通。而漂漂亮亮的視覺化是完成這項任務的絕佳工具。
本文將介紹5種非傳統的視覺化技術,讓你的數據故事更漂亮、更有效。這裡將使用Python的Plotly圖形庫,讓你可以毫不費力地產生動畫圖表和互動式圖表。
如果你還沒安裝Plotly,只需在你的終端機執行以下指令即可完成安裝:
pip install plotly
在研究這個或那個指標的演變時,我們常常涉及到時間資料。 Plotly動畫工具只要一行程式碼就能讓人觀看資料隨時間的變化情況,如下圖所示:
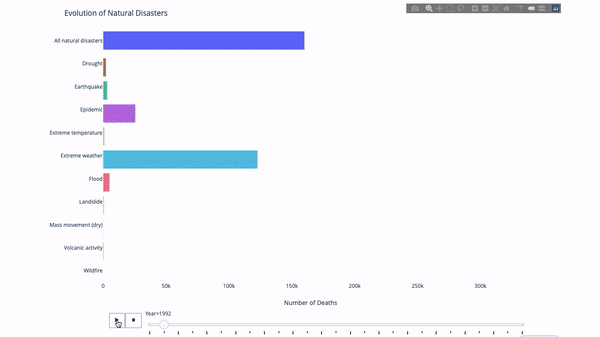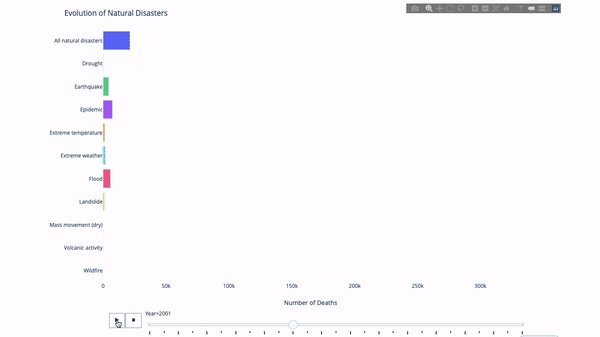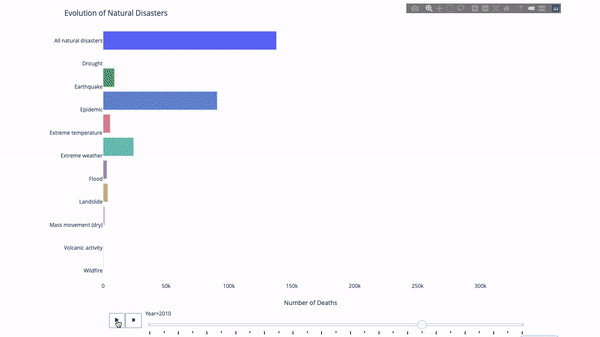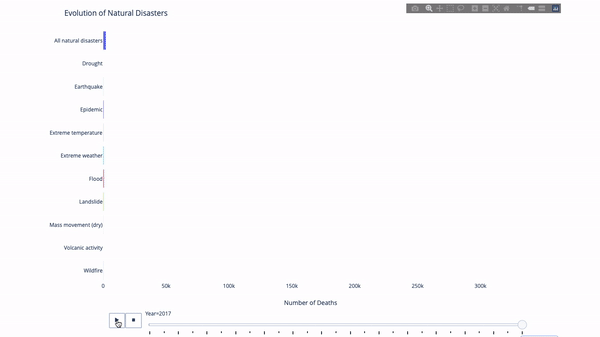
#程式碼如下:
import plotly.express as px from vega_datasets import data df = data.disasters() df = df[df.Year > 1990] fig = px.bar(df, y="Entity", x="Deaths", animation_frame="Year", orientation='h', range_x=[0, df.Deaths.max()], color="Entity") # improve aesthetics (size, grids etc.) fig.update_layout(width=1000, height=800, xaxis_showgrid=False, yaxis_showgrid=False, paper_bgcolor='rgba(0,0,0,0)', plot_bgcolor='rgba(0,0,0,0)', title_text='Evolution of Natural Disasters', showlegend=False) fig.update_xaxes(title_text='Number of Deaths') fig.update_yaxes(title_text='') fig.show()
只要你有一個時間變數來過濾,那麼幾乎任何圖表都可以做成動畫。以下是一個製作散點圖動畫的例子:
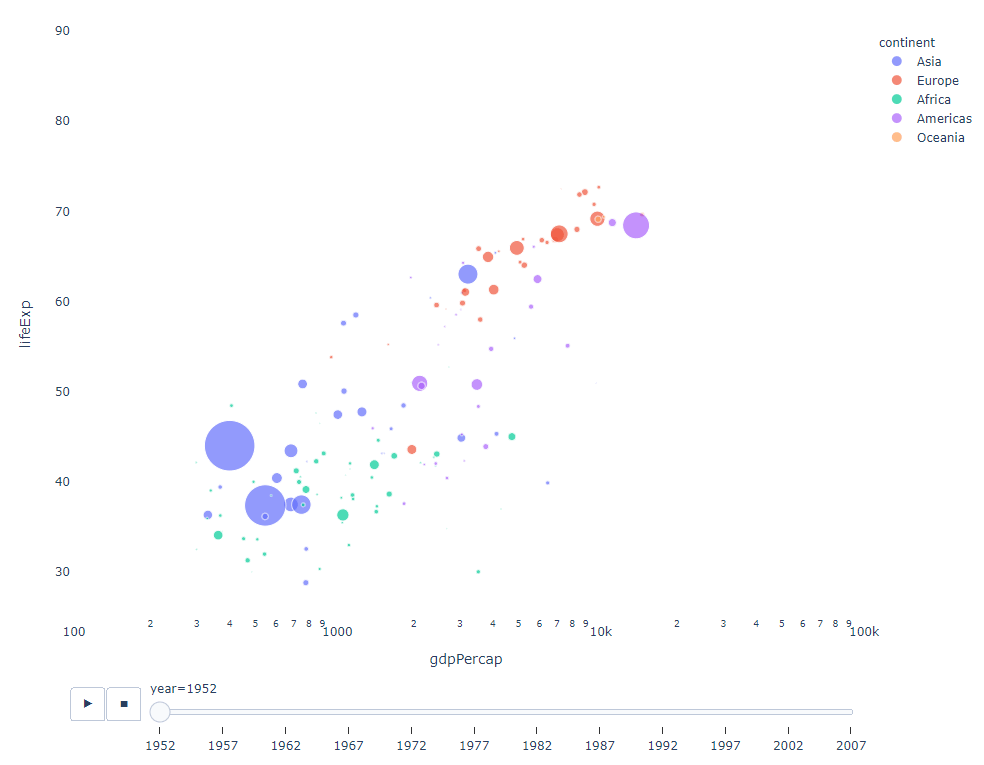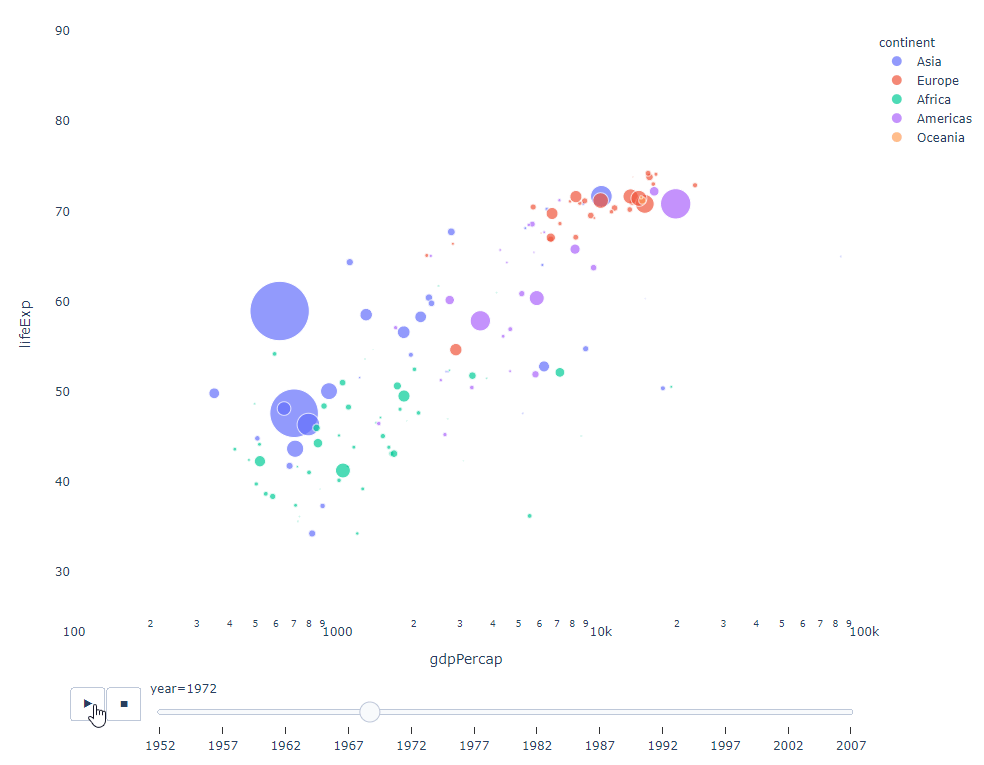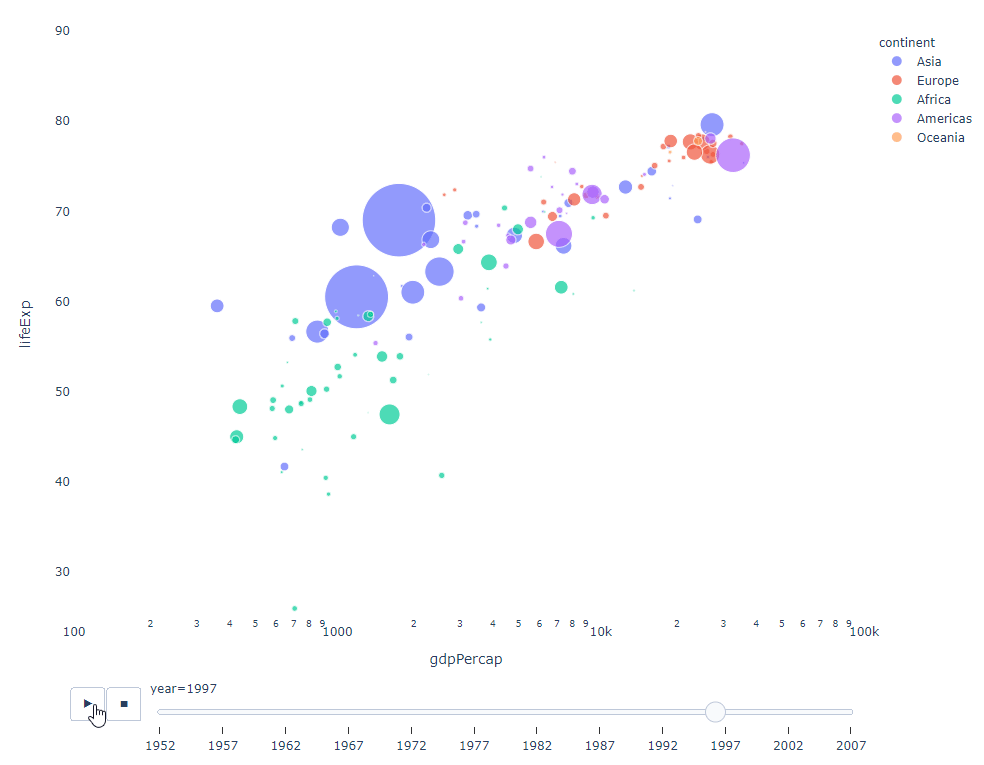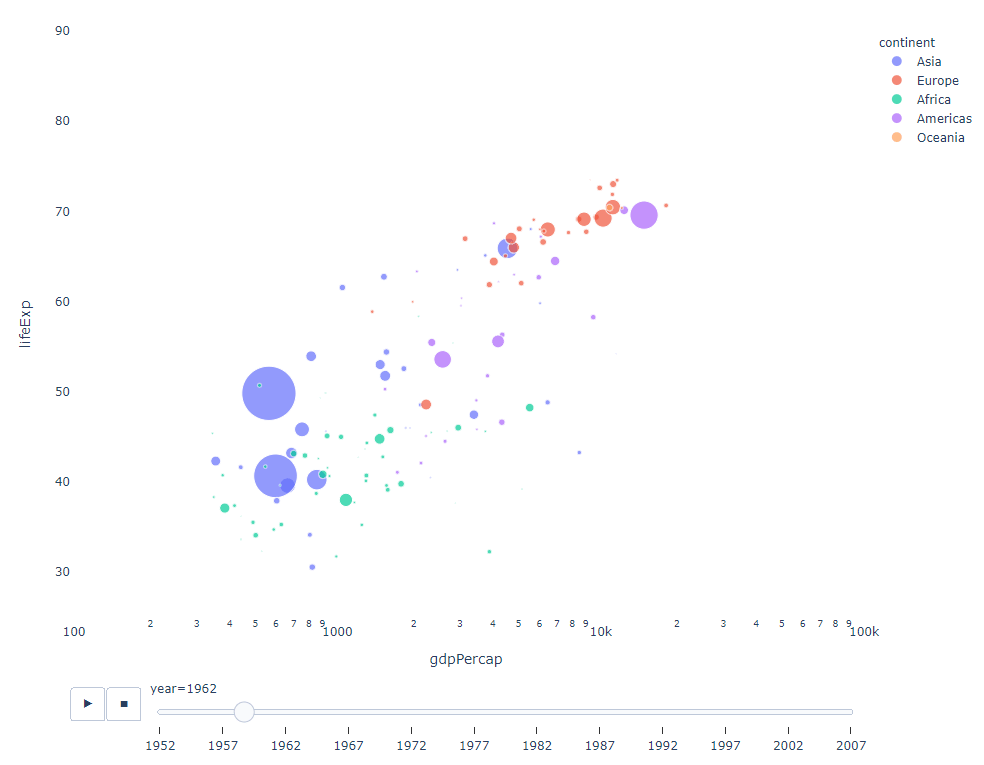
import plotly.express as px df = px.data.gapminder() fig = px.scatter( df, x="gdpPercap", y="lifeExp", animation_frame="year", size="pop", color="continent", hover_name="country", log_x=True, size_max=55, range_x=[100, 100000], range_y=[25, 90], # color_continuous_scale=px.colors.sequential.Emrld ) fig.update_layout(width=1000, height=800, xaxis_showgrid=False, yaxis_showgrid=False, paper_bgcolor='rgba(0,0,0,0)', plot_bgcolor='rgba(0,0,0,0)')
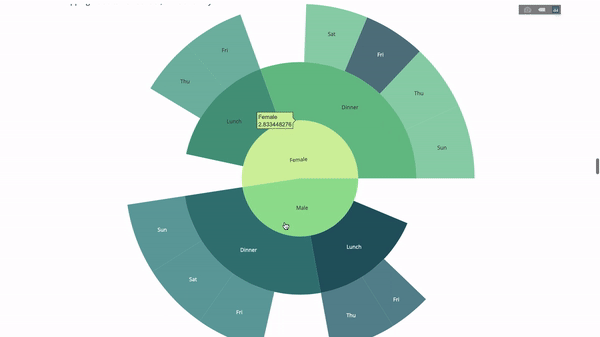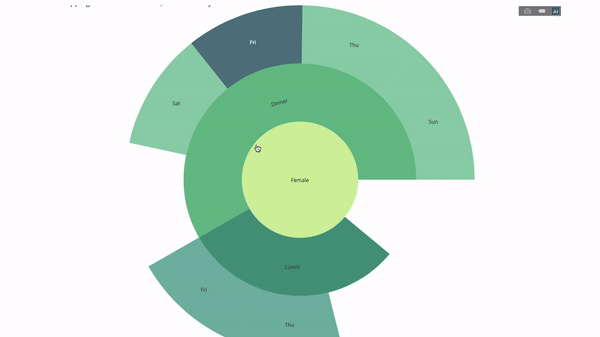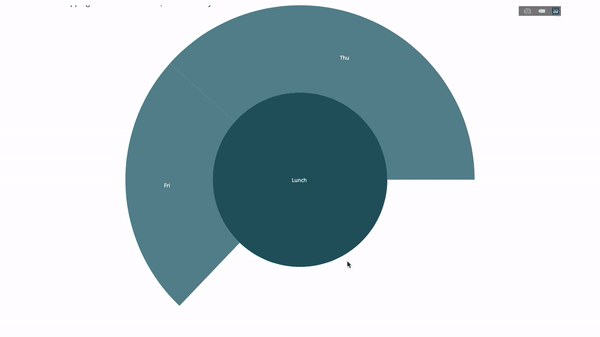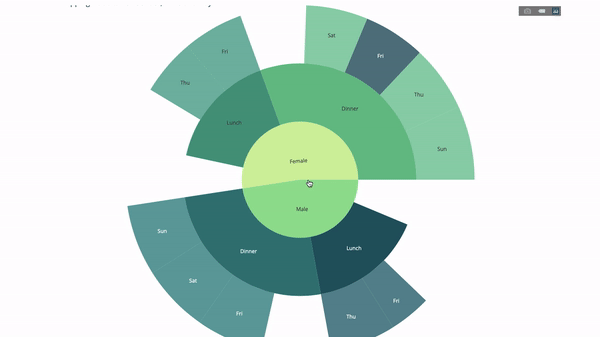
太陽圖(sunburst chart)是一種視覺化group by語句的好方法。如果你想透過一個或多個類別變數來分解一個給定的量,那就用太陽圖。
假設我們想根據性別和每天的時間分解平均小費數據,那麼相較於表格,這種雙重group by語句可以透過視覺化來更有效地展示。
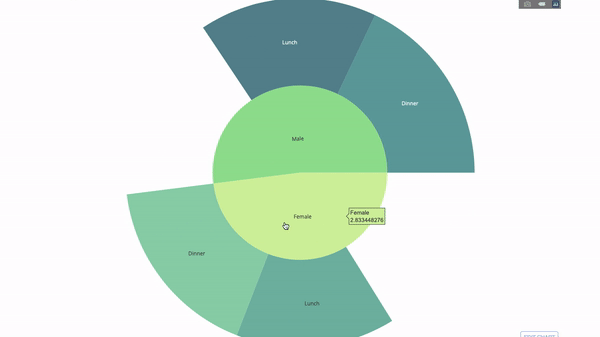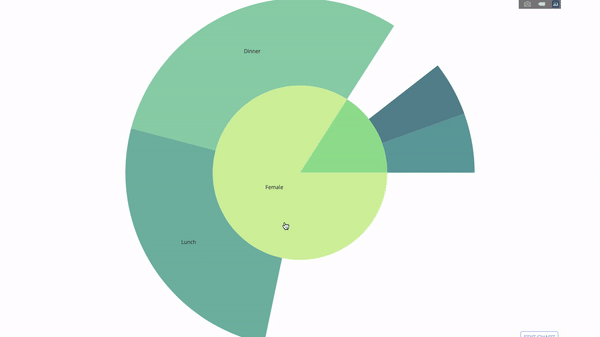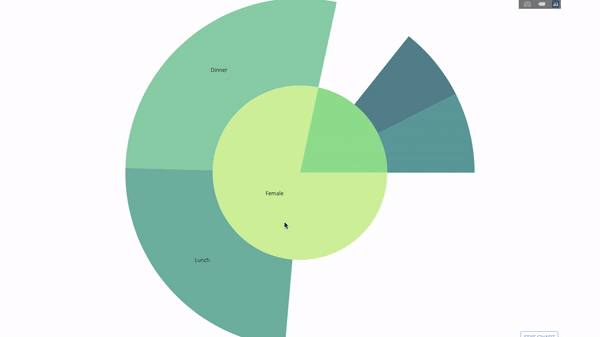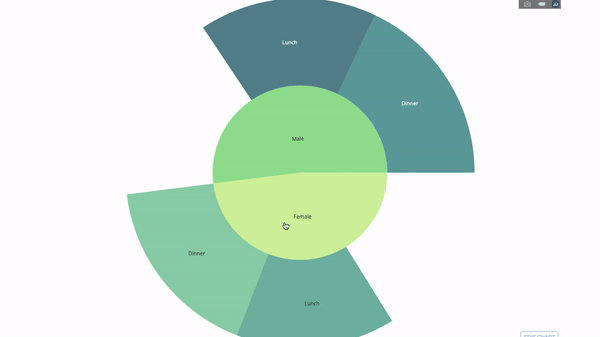
這個圖表是互動式的,讓你可以自己點擊並探索各個類別。你只需要定義你的所有類別,並聲明它們之間的層次結構(請參閱以下程式碼中的parents參數)並指派對應的值即可,這在我們案例中即為group by語句的輸出。
import plotly.graph_objects as go
import plotly.express as px
import numpy as np
import pandas as pd
df = px.data.tips()
fig = go.Figure(go.Sunburst(
labels=["Female", "Male", "Dinner", "Lunch", 'Dinner ', 'Lunch '],
parents=["", "", "Female", "Female", 'Male', 'Male'],
values=np.append(
df.groupby('sex').tip.mean().values,
df.groupby(['sex', 'time']).tip.mean().values),
marker=dict(colors=px.colors.sequential.Emrld)),
layout=go.Layout(paper_bgcolor='rgba(0,0,0,0)',
plot_bgcolor='rgba(0,0,0,0)'))
fig.update_layout(margin=dict(t=0, l=0, r=0, b=0),
title_text='Tipping Habbits Per Gender, Time and Day')
fig.show()
現在我們再向這個層次結構再增加一層:
為此,我們再加入另一個涉及三個類別變數的group by語句的值。
import plotly.graph_objects as go
import plotly.express as px
import pandas as pd
import numpy as np
df = px.data.tips()
fig = go.Figure(go.Sunburst(labels=[
"Female", "Male", "Dinner", "Lunch", 'Dinner ', 'Lunch ', 'Fri', 'Sat',
'Sun', 'Thu', 'Fri ', 'Thu ', 'Fri', 'Sat', 'Sun', 'Fri ', 'Thu '
],
parents=[
"", "", "Female", "Female", 'Male', 'Male',
'Dinner', 'Dinner', 'Dinner', 'Dinner',
'Lunch', 'Lunch', 'Dinner ', 'Dinner ',
'Dinner ', 'Lunch ', 'Lunch '
],
values=np.append(
np.append(
df.groupby('sex').tip.mean().values,
df.groupby(['sex',
'time']).tip.mean().values,
),
df.groupby(['sex', 'time',
'day']).tip.mean().values),
marker=dict(colors=px.colors.sequential.Emrld)),
layout=go.Layout(paper_bgcolor='rgba(0,0,0,0)',
plot_bgcolor='rgba(0,0,0,0)'))
fig.update_layout(margin=dict(t=0, l=0, r=0, b=0),
title_text='Tipping Habbits Per Gender, Time and Day')
fig.show()
指標圖只是為了好看。在報告 KPI 等成功指標並展示其與您的目標的距離時,可以使用這種圖表。
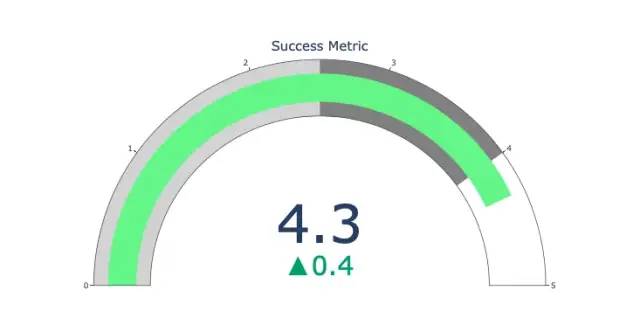
import plotly.graph_objects as go
fig = go.Figure(go.Indicator(
domain = {'x': [0, 1], 'y': [0, 1]},
value = 4.3,
mode = "gauge+number+delta",
title = {'text': "Success Metric"},
delta = {'reference': 3.9},
gauge = {'bar': {'color': "lightgreen"},
'axis': {'range': [None, 5]},
'steps' : [
{'range': [0, 2.5], 'color': "lightgray"},
{'range': [2.5, 4], 'color': "gray"}],
}))
fig.show()
另一種探索類別變數之間關係的方法是以下這種平行座標圖。你可以隨時拖放、高亮和瀏覽值,非常適合演示時使用。
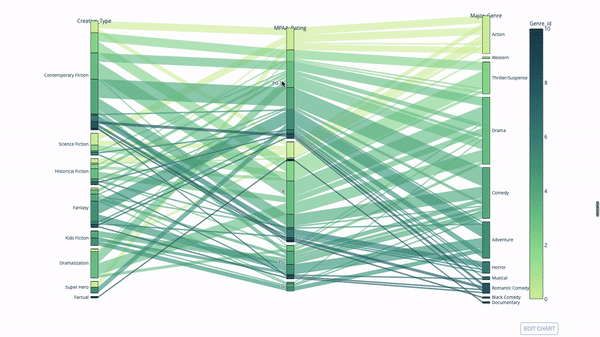
程式碼如下:
import plotly.express as px from vega_datasets import data import pandas as pd df = data.movies() df = df.dropna() df['Genre_id'] = df.Major_Genre.factorize()[0] fig = px.parallel_categories( df, dimensions=['MPAA_Rating', 'Creative_Type', 'Major_Genre'], color="Genre_id", color_continuous_scale=px.colors.sequential.Emrld, ) fig.show()
平行座標圖是上面的圖表的衍生版本。這裡,每一根弦都代表單一觀察。這是一種可用於識別離群值(遠離其它資料的單條線)、聚類、趨勢和冗餘變數(例如如果兩個變數在每個觀察值上的值都相近,那麼它們將位於同一水平線上,表示存在冗餘)的好用工具。
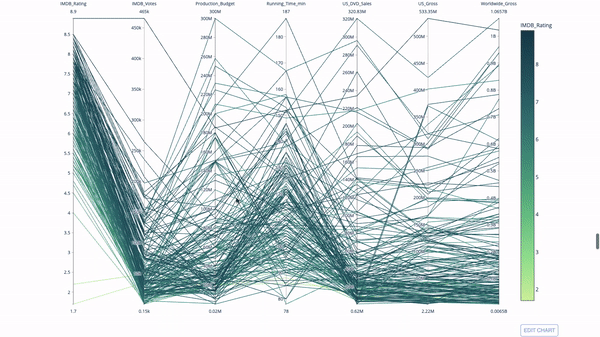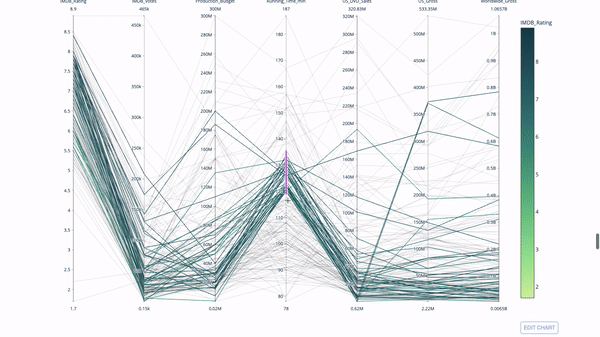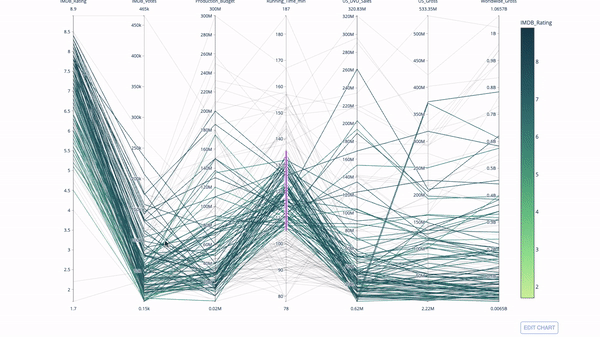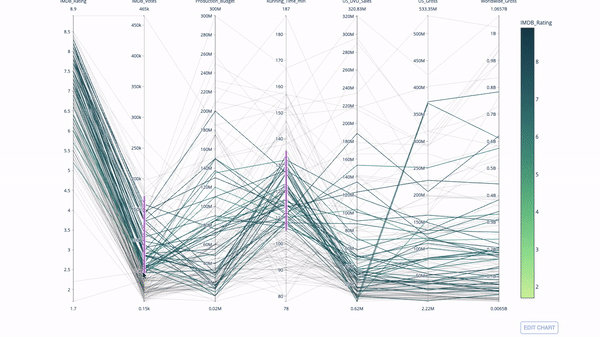
程式碼如下:
import plotly.express as px from vega_datasets import data import pandas as pd df = data.movies() df = df.dropna() df['Genre_id'] = df.Major_Genre.factorize()[0] fig = px.parallel_coordinates( df, dimensions=[ 'IMDB_Rating', 'IMDB_Votes', 'Production_Budget', 'Running_Time_min', 'US_Gross', 'Worldwide_Gross', 'US_DVD_Sales' ], color='IMDB_Rating', color_continuous_scale=px.colors.sequential.Emrld) fig.show()
以上是用 Python 繪製動態視覺化圖表,太酷了!的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















