

CVPR 2023論文總結! CV最熱領域頒給多模態、擴散模型

一年一度的CVPR即將在6月18-22日加拿大溫哥華正式開幕。
每年,來自世界各地的成千上萬的CV研究人員和工程師聚集在一起參加頂會。這個久負盛名的會議可以追溯到1983年,它代表了電腦視覺發展的巔峰。
目前,CVPR的h5指數所有會議或出版品中排名第四,僅次於《自然》、《科學》和《新英格蘭醫學雜誌》。

前段時間,CVPR公佈了論文接收結果。根據官網上統計數據,共接受論文9155篇,錄取2359篇,接受率為25.8%。
此外,也公佈了12篇獲獎候選論文。

那麼,今年的CVPR有哪些亮點呢?從錄用論文中我們又能看到CV領域有哪些趨勢?
接下來一併揭曉。
CVPR一覽
新創公司Voxel51就所有被接收論文清單中進行了分析。
先來整體看一張論文標題的總圖,每個字的大小與資料集中出現的頻率成正比。

簡單說明
- 2359篇論文被接收(9155份論文提交)
- 1724篇Arxiv論文
- 68份文件提交到其他地址
每篇論文的作者
- CVPR論文的平均作者約為5.4人
- 論文當中作者最多的是: “Why is the winner the best?”有125位作者
- 有13篇論文只有一個作者。
主要Arxiv分類
#在1724篇Arxiv論文中,有1545篇,或接近90%的論文將cs.CV列為主要類別。
cs.LG排名第二,有101篇。 eess.IV (26)和 cs.RO (16)也分得一杯羹。
CVPR 論文的其他類別包括: cs.HC,cs.CV,cs.AR,cs.DC,cs.NE,cs.SD,cs.CL,cs.IT ,cs.CR,cs.AI,cs.MM,cs.GR,eess.SP,eess.AS,math.OC,math.NT,physics.data-an和stat.ML。
「Meta」資料
- 「資料集」與「模型」這2個字共同出現在567篇摘要中。 「資料集」在265篇論文摘要中單獨出現,而「模型」則單獨出現了613次。只有16.2%的 CVPR接收論文沒有包含這兩個字。
- 根據CVPR論文摘要,今年最受歡迎的資料集是ImageNet(105),COCO(94),KITTI(55)和CIFAR(36)。
- 28篇論文提出了一個新的「基準」。
縮寫詞比比皆是
#似乎沒有首字母縮寫就沒有機器學習項目。 2359篇論文中,1487篇的標題有多個大寫字母的縮寫或複合詞,佔63%。
這些首字母縮寫詞中有一些很容易記住,甚至可以脫口而出:
- CLAMP: Prompt-based Contrastive Learning for Connecting Language and Animal PoseCLAMP
- PATS: Patch Area Transportation with Subdivision for Local Feature Matching
- CIRCLE: Capture In Rich Contextual Environments
- CIRCLE: Capture In Rich Contextual Environments
##幫助有些則複雜得多:
- SIEDOB: Semantic Image Editing by Disentangling Object and Background
- FJMP : Factorized Joint Multi-Agent Motion Prediction over Learned Directed Acyclic Interaction GraphsFJMP
##他們中的一些人似乎在首字母縮略詞構建上借鑒了別人的創意:##他們中的一些人似乎在首字母縮略詞構建上借鑒了別人的創意:
- SCOTCH and SODA: A Transformer Video Shadow Detection Framework(荷蘭流行潮牌Scotch & Soda)
- EXCALIBUR: Encouraging and Evaluating Embodied Exploration(Ex咖哩棒,笑)什麼最熱?
除了2023年的論文標題,我們抓取了2022年所有接受的論文標題。從這兩個清單中,我們計算了各種關鍵字的相對頻率,從讓大家對什麼是上升趨勢、什麼是下降趨勢有更深入的了解。
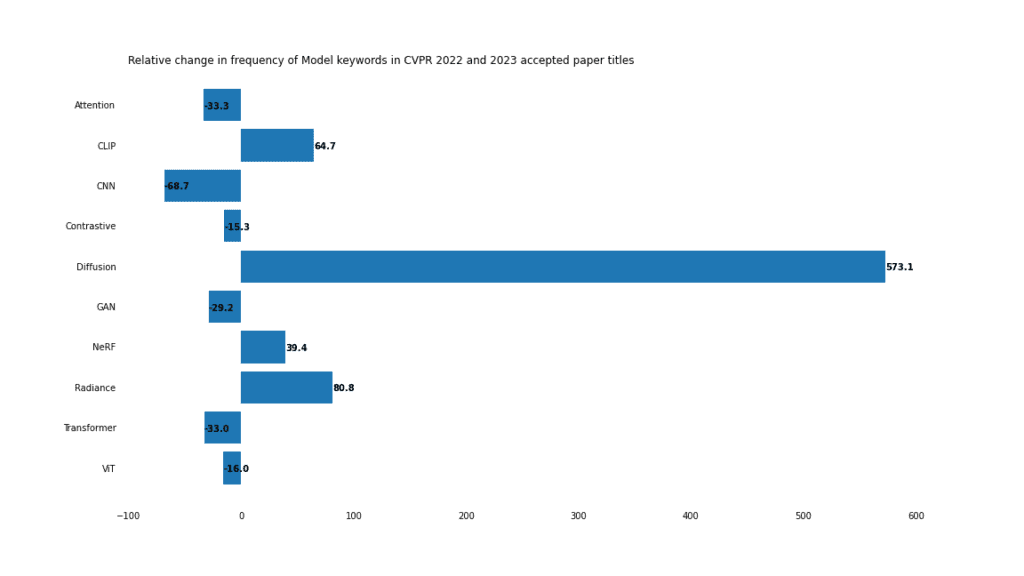
模型2023年,擴散模型(Diffusion models)佔據了主導地位。
。擴散模型
隨著Stable Diffusion和Midjourney等影像生成模型的走紅,擴散模型發展的火熱趨勢也就不足為奇了。
擴散模型在去雜訊、影像編輯和風格轉換方面也有應用。把所有這些加起來,到目前為止,它是所有類別中最大的贏家,比去年同期增長了573% 。
 輻射場
輻射場
#神經輻射場(NERF)也越來越受歡迎,論文中使用單字“ radiance」增加了80% ,「NERF」增加了39% 。 NeRF已經從概念驗證轉向編輯、應用和訓練流程最佳化。
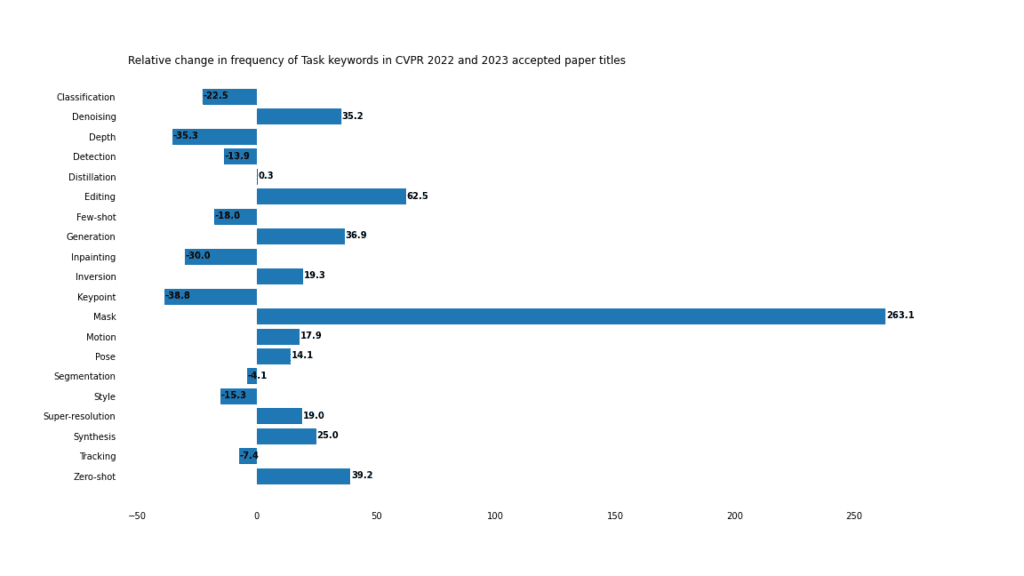
######Transformers################「Transformer」和「ViT」的使用率下降並不意味著Transformer模型過時,而是反映了這些模型在2022年的主導地位。 2021年,「Transformer」這個字只出現在37篇論文中。 2022年,這個數字飆升至201。 Transformer不會很快消失。 ###############CNN################CNN曾經是電腦視覺的寵兒,到了2023年,似乎失去了它們的優勢,使用率下降了68%。許多提到 CNN 的標題也提到了其他模型。例如,這些論文提到了CNN和Transformer:############- Lite-Mono: A Lightweight CNN and Transformer Architecture for Self-Supervised Monocular Depth EstimationLite-Mono######### ####- Learned Image Compression with Mixed Transformer-CNN Architectures############任務############掩碼任務和掩碼圖像建模相結合,在CVPR中佔據了主導地位。 ############################################################################傳統的判別任務,如檢測、分類和分割並沒有失寵,但是由於生成應用的一系列進步,它們在CV的份額正在縮小,包括“編輯”、“合成”以及“生成”的上升就證明這一點。
掩碼
#關鍵字「mask」比去年同期成長了263% ,在2023年被接收的論文中出現了92次,有時在一個標題中出現了2次。
- SIM: Semantic-aware Instance Mask Generation for Box-Supervised Instance SegmentationSIM
#- DynaMask: Dynamic Mask Selection for Instance SegmentationDynaMask#mentationDynaMask
##但大多數(64%)實際上指的是「掩碼」任務,包括8個「掩碼影像建模」和15個「掩碼自動編碼器」任務。此外,還有8篇出現「掩碼」。
同樣值得注意的是,3篇帶有單字「mask」的論文標題實際上指的是「無掩碼」任務。
零樣本vs小樣本
#隨著遷移學習、產生方法、提示和通用模型的興起, 「零樣本」學習正在獲得關注。同時,「小樣本」學習比去年有所下降。然而,就原始數字而言,至少目前而言,「小樣本」(45)比「零樣本」(35)略有優勢。
模數
2023年,多模態與跨模態應用加速發展。
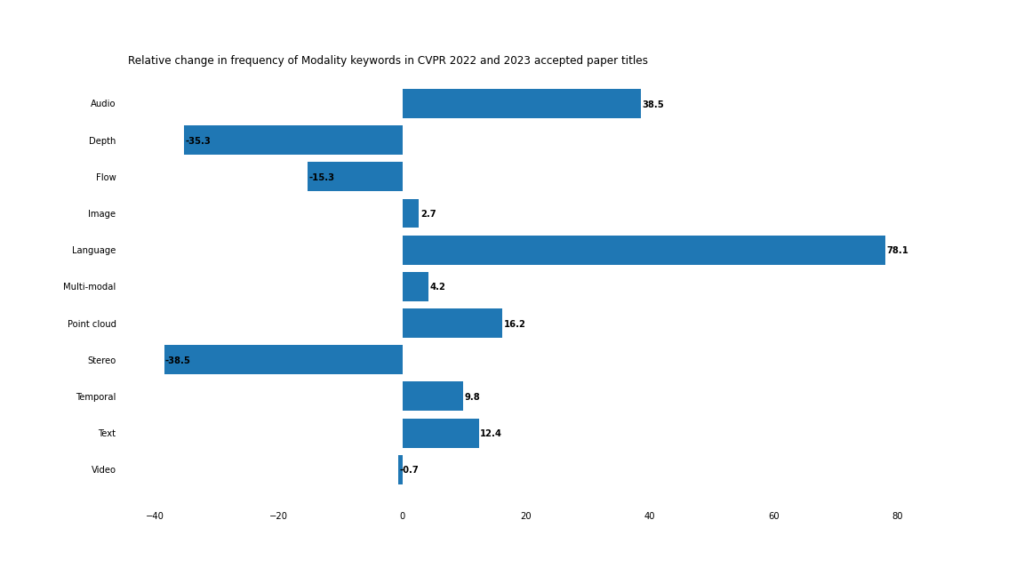
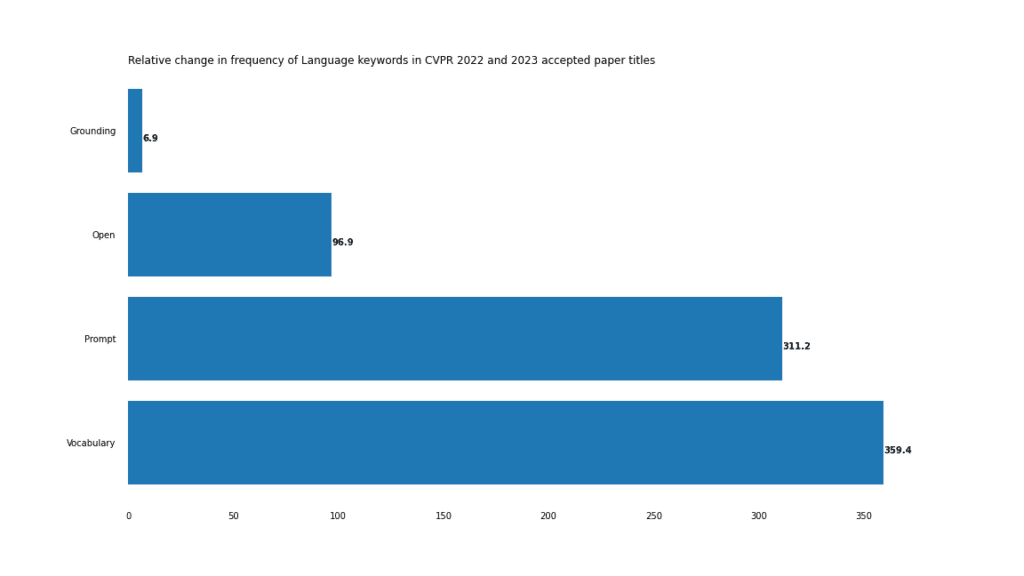
即使「多模態」這個詞本身沒有在論文標題中出現,也很難否認電腦視覺正在走向多模態的未來。
這在視覺語言任務中尤其明顯,正如「開放」、「提示」和「詞彙」的急劇上升所顯示的。
這種情況最極端的例子是「開放詞彙」這個複合詞,它在2022年只出現了3次,但在2023年出現了18次。
深入研究CVPR 2023論文標題中的關鍵字
點雲9
三維電腦視覺應用正在從以二維影像推斷3D資訊(「深度」和「立體」)轉向直接在3D點雲資料上進行工作的電腦視覺系統。
######CV標題的創造力#########如果不將ChatGPT納入其中,2023年任何與機器學習相關的全面報導都是不完整的。我們決定讓事情變得有趣,並使用ChatGPT來尋找CVPR 2023中最有創意的標題。 ############對於每一篇上傳到Arxiv的論文,我們抓取了摘要,並要求 ChatGPT (GPT-3.5 API)為相應的CVPR論文產生一個標題。 ############然後,我們將這些由ChatGPT產生的標題和實際的論文標題,使用OpenAI的text-embedding-ada-002模型產生嵌入向量,並計算ChatGPT產生的標題和作者產生的標題之間的餘弦相似度。 ############這可以告訴我們什麼? ChatGPT越接近實際的論文標題,這個標題就越可預測。換句話說,ChatGPT的預測越「偏」,作者為論文命名的「創造性」就越強。 ######嵌入和餘弦相似度為我們提供了一個有趣的,儘管遠非完美的,量化方法。
我們依照這個指標對論文進行了排序。話不多說,以下是最具創意的標題:
實際的標題:Tracking Every Thing in the Wild
預測的標題:Disentangling Classification from Tracking: Introducing TETA for Comprehensive Benchmarking of Multi-Category Multiple Object Tracking
實際的標題:Learning to Bootstrap for Combating Label Noise
預測的標題:Learnable Loss Objective for Joint Instance and Label Reweighting in Deep Neural Networks
實際的標題:Seeing a Rose in Five Thousand Ways
實際的標題:Seeing a Rose in Five Thousand Ways
預測的標題:Learning Object Intrinsics from Single Internet Images for Superior Visual Rendering and Synthesis
實際的標題:Why is the winner the best?
####預測的標題:Analyzing Winning Strategies in International Benchmarking Competitions for Image Analysis: Insights from a Multi-Center Study of IEEE ISBI and MICCAI 2021#######以上是CVPR 2023論文總結! CV最熱領域頒給多模態、擴散模型的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

AI Hentai Generator
免費產生 AI 無盡。

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)
熱門話題



 Stable Diffusion 3論文終於發布,架構細節大揭秘,對復現Sora有幫助?
Mar 06, 2024 pm 05:34 PM
Stable Diffusion 3論文終於發布,架構細節大揭秘,對復現Sora有幫助?
Mar 06, 2024 pm 05:34 PM
StableDiffusion3的论文终于来了!这个模型于两周前发布,采用了与Sora相同的DiT(DiffusionTransformer)架构,一经发布就引起了不小的轰动。与之前版本相比,StableDiffusion3生成的图质量有了显著提升,现在支持多主题提示,并且文字书写效果也得到了改善,不再出现乱码情况。StabilityAI指出,StableDiffusion3是一个系列模型,其参数量从800M到8B不等。这一参数范围意味着该模型可以在许多便携设备上直接运行,从而显著降低了使用AI
 ICCV'23論文頒獎「神仙打架」! Meta分割一切和ControlNet共同入選,還有一篇讓評審很驚訝
Oct 04, 2023 pm 08:37 PM
ICCV'23論文頒獎「神仙打架」! Meta分割一切和ControlNet共同入選,還有一篇讓評審很驚訝
Oct 04, 2023 pm 08:37 PM
在法國巴黎舉行的電腦視覺頂峰大會ICCV2023剛結束!今年的最佳論文獎,簡直是「神仙打架」。例如,兩篇獲得最佳論文獎的論文中,就包括顛覆文生圖AI領域的著作-ControlNet。自從開源以來,ControlNet已經在GitHub上獲得了24k個星星。無論是對於擴散模型還是整個電腦視覺領域來說,這篇論文的獲獎都是實至名歸的而最佳論文獎榮譽提名,則頒給了另一篇同樣出名的論文,Meta的「分割一切”模型SAM。自推出以來,“分割一切”已經成為了各種圖像分割AI模型的“標竿”,包括後來居上的
 NeRF與自動駕駛的前世今生,近10篇論文總結!
Nov 14, 2023 pm 03:09 PM
NeRF與自動駕駛的前世今生,近10篇論文總結!
Nov 14, 2023 pm 03:09 PM
神經輻射場(NeuralRadianceFields)自2020年被提出以來,相關論文數量呈指數增長,不僅成為了三維重建的重要分支方向,也逐漸作為自動駕駛重要工具活躍在研究前沿。 NeRF這兩年異軍突起,主要因為它跳過了傳統CV重建pipeline的特徵點提取和匹配、對極幾何與三角化、PnP加BundleAdjustment等步驟,甚至跳過mesh的重建、貼圖和光追,直接從2D輸入影像學習一個輻射場,然後從輻射場輸出逼近真實照片的渲染影像。也就是說,讓一個基於神經網路的隱式三維模型,去擬合指定視角
 聊天截圖曝出AI頂會審稿潛規則! AAAI 3000塊即可strong accept?
Apr 12, 2023 am 08:34 AM
聊天截圖曝出AI頂會審稿潛規則! AAAI 3000塊即可strong accept?
Apr 12, 2023 am 08:34 AM
正值AAAI 2023論文截止提交之際,知乎上突然出現了一張AI投稿群的匿名聊天截圖。其中有人聲稱,自己可以提供「3000塊一個strong accept」的服務。爆料一出,頓時引起了網友的公憤。不過,先不要急。知乎大佬「微調」表示,這大機率只是「口嗨」而已。根據「微調」透露,打招呼和團體犯案這個是任何領域都不能避免的問題。隨著openreview的興起,cmt的各種缺點也越來越清楚,未來留給小圈子操作的空間會變小,但永遠會有空間。因為這是個人的問題,不是投稿系統和機制的問題。引入open r
 論文插圖也能自動生成了,用到了擴散模型,還被ICLR接收
Jun 27, 2023 pm 05:46 PM
論文插圖也能自動生成了,用到了擴散模型,還被ICLR接收
Jun 27, 2023 pm 05:46 PM
生成式AI已經風靡了人工智慧社區,無論是個人還是企業,都開始熱衷於創建相關的模態轉換應用,例如文生圖、文生影片、文生音樂等等。最近呢,來自ServiceNowResearch、LIVIA等科研機構的幾位研究者嘗試以文字描述來產生論文中的圖表。為此,他們提出了一種FigGen的新方法,相關論文也被ICLR2023收錄為了TinyPaper。圖片論文網址:https://arxiv.org/pdf/2306.00800.pdf也許有人會問了,產生論文中的圖表有什麼難的呢?這樣做對科學研究又有哪些幫助呢
 華人團隊斬獲最佳論文、最佳系統論文獎項,CoRL研究成果獲獎公佈
Nov 10, 2023 pm 02:21 PM
華人團隊斬獲最佳論文、最佳系統論文獎項,CoRL研究成果獲獎公佈
Nov 10, 2023 pm 02:21 PM
自2017年首次舉辦以來,CoRL已成為了機器人學與機器學習交叉領域的全球頂級學術會議之一。 CoRL是機器人學習研究的單一主題會議,涵蓋了機器人學、機器學習和控制等多個主題,包括理論與應用2023年的CoRL大會將於11月6日至9日在美國亞特蘭大舉行。根據官方數據透露,今年有來自25個國家的199篇論文入選CoRL。熱門主題包括操作、強化學習等。雖然相較於AAAI、CVPR等大型AI學術會議,CoRL的規模較小,但隨著今年大模型、具身智能、人形機器人等概念的熱度上升,值得關注的相關研究也會
 CVPR 2023放榜,錄取率25.78%! 2360篇論文被接收,提交量暴漲至9155篇
Apr 13, 2023 am 09:37 AM
CVPR 2023放榜,錄取率25.78%! 2360篇論文被接收,提交量暴漲至9155篇
Apr 13, 2023 am 09:37 AM
剛剛,CVPR 2023發文表示:今年,我們收到了創紀錄的9155份論文(比CVPR2022增加了12%),並錄用了2360篇論文,接收率為25.78%。根據統計,CVPR的投稿量在2010-2016的7年間僅從1724增加到2145。在2017年後則迅速飆升,進入快速增長期,2019年首度突破5000,至2022年投稿數已達8,161份。可以看到,今年提交了共9155份論文確實創下了最高紀錄。疫情放開後,今年的CVPR頂將在加拿大舉行。今年採用單軌會議的形式,並取消了傳統Oral的評選。谷歌研究
 華人團隊打造的通用分割模型SEEM,將一次性分割推向新高度
Apr 26, 2023 pm 10:07 PM
華人團隊打造的通用分割模型SEEM,將一次性分割推向新高度
Apr 26, 2023 pm 10:07 PM
本月初,Meta發布「分割一切」AI模型-SegmentAnythingModel(SAM)。 SAM被認為是通用的影像分割基礎模型,它學會了關於物體的一般概念,可以為任何影像或影片中的任何物體產生mask,包括在訓練過程中沒有遇到過的物體和影像類型。這種「零樣本遷移」的能力令人驚嘆,甚至有人稱CV領域迎來了「GPT-3時刻」。最近,一篇「一次性分割一切」的新論文《SegmentEverythingEverywhereAllatOnce》再次引起關注。在該論文中,來自威斯康辛大學麥迪遜分校、
