

xPath注入的基礎語法有哪些

首先什麼是xPath:xPath是一種在xml中尋找資訊的語言
xPath中包含七種類型的節點: 元素、屬性、文字、命名空間、處理指令、註解及文檔根節點。 xml文檔是依照文檔樹的結構進行解析的,文檔樹的根稱為文檔節點或根節點。

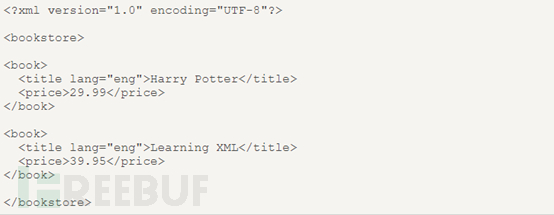
這是一份基本的xml文件的源碼,從這份xml源碼可以看出,bookstore為文檔節點(根節點),book、 title、author、year、price是元素節點。其中book節點有四個子元素節點:title、author、year、price,title節點有三個同胞:author、year、price。 title這個元素節點擁有一個屬性和文字節點,屬性節點是lang,值為en,文字節點的值是HarryPotter。
下面還有一些xml節點關係的描述(類似資料結構中的樹):
父:book節點的父為bookstore,book節點是title、author、year、price節點的父。 (每個節點只能有一個父)。
子:book是bookstore的子,book節點的子是title、author、year、price的子。
(元素節點可以有零個、一個或多個子)。
標題的同級元素包括作者、年份和價格,這些元素具有相同的父節點,類似於樹狀結構中的兄弟節點。 (節點可以有零個、一個或多個同胞)。
先輩:節點的父、父的父、父的父的父(無限循環),title元素節點的先輩就是book、bookstore。
後代:節點的子、子的子、子的子的子(無線循環),bookstore文檔節點的後代就是book、title、author、year、price、lang。
知道了xml的節點關係還不夠,還需要知道它是如何進行查詢的,xPath透過路徑表達式來選取文件中的節點或節點集。節點是沿著路徑或步驟選取的。
XPath 使用路徑運算式在 XML 文件中選取節點。節點是透過沿著路徑或 step 來選取的。下面列出了最有用的路徑表達式:
nodename:選取此節點的所有接待你
/:從根節點選取
//:從符合選擇的目前節點選擇文件中的節點,而不考慮它們的位置
.:選取目前節點
..:選取目前節點的父節點
@:選取屬性
下面直接來透過js使用xpath查詢語法來進行查詢
先寫一份關於xpath呼叫的html(呼叫的程式碼寫到js中)檔案模板,然後準備好一份xml檔案用來查詢。
js模板的原始碼如下:
https://www.runoob.com/try/try.php?filename=try_xpath_select_cdnodes
挨個看一下這份html檔案中的js程式碼(因為只有js程式碼)
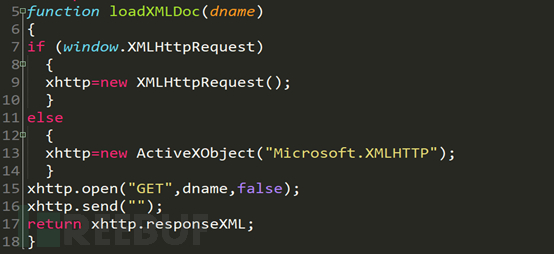
這是js的一個非同步呼叫函數,重要的程式碼在第15行和第17行,第15行由函數傳入的dname函數是xml的路徑,第17行回傳得到的xml檔。
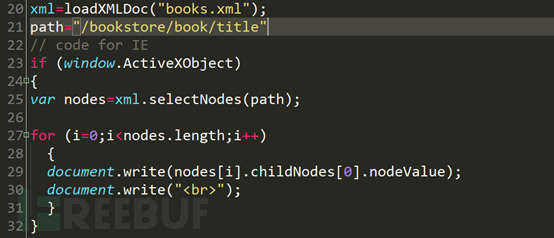
請參考第20行,變數xml取得了執行loadXMLDOC函數後所得到的XML檔。 21行path變數為xpath的查詢語法。第一個if語句,判斷是否為IE6及以下瀏覽器,如果是IE6或以下瀏覽器,獲得對應的查詢的到的節點數組之後,將數組中的值遍歷輸出到頁面中。
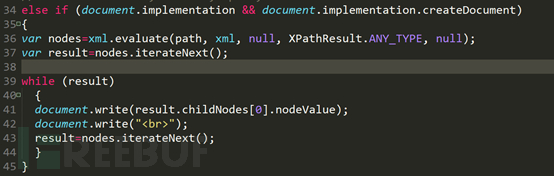
第二個if語句對於非IE6及以下瀏覽器,執行的過程一樣,只是語法稍有不同,非IE6及以下瀏覽器透過evaluate函數進行查詢,格式基本上固定,實作剛才的幾個語法。
查詢語法的替換只需要修改path的值就行。

先列出需要查詢的語法:
註:假如路徑起始於正斜線( / ),則此路徑始終代表到某元素的絕對路徑!
bookstore:選取 bookstore 元素的所有子節點。
/bookstore:選取根元素 bookstore。
bookstore/book:選取所有屬於 bookstore 的子元素的 book 元素。
//book:選取所有 book 子元素,而不管它們在文件中的位置。
bookstore//book:選擇屬於 bookstore 元素的後代的所有 book 元素,而不管它們位於 bookstore:底下的什麼位置。
//@lang:選取名為 lang 的所有屬性。
只使用這些單一查詢可能無法取得預期結果,需要將它們與其他查詢語句組合。以下是一些需要配合的語法:
謂語(用方括號,為了得到更精確的查詢結果):
選取bookstore 元素的第一個子元素book 的路徑為/bookstore /book[1]。
/bookstore/book[last()]:選取最後一個屬於 bookstore 子元素的 book 元素。
/bookstore/book[last()-1]:選取屬於 bookstore 子元素的倒數第二個 book 元素。
/bookstore/book[position()
//title[@lang]:選取所有擁有名為 lang 的屬性的 title 元素。
//title[@lang='eng']:選取所有 title 元素,且這些元素擁有值為 eng 的 lang 屬性。
/bookstore/book[price>35.00]:所有選取 bookstore 元素的 book 元素,且其中的 price 元素的值須大於 35.00。
/bookstore/book[price>35.00]/title:選取 bookstore 元素中的 book 元素的所有 title 元素,且其中的 price 元素的值須大於 35.00。
選取未知節點:
*:符合任何元素節點。
@*:符合任何屬性節點。
node():符合任何類型的節點。
例如:
/bookstore/*:選取 bookstore 元素的所有子元素。
//*:選取文件中的所有元素。
//title[@*]:選取所有帶有屬性的 title 元素。
選取若干路徑:
//book/title | //book/price:選取 book 元素的所有 title 和price 元素。
//title | //price:選取文件中的所有 title 和 price 元素。
/bookstore/book/title | //price:選取所有屬於bookstore 元素的book 元素的所有title 元素,以及所有在文件中的price 元素
看幾個查詢的範例:
查詢第二個book的title值:/bookstore/book[1]/title

#查詢所有book的title的值:/ bookstore/book//title

查詢所有帶有lang屬性的title的值:/bookstore/book//title[@lang]
# 
以上是xPath注入的基礎語法有哪些的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

AI Hentai Generator
免費產生 AI 無盡。

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)
熱門話題



 如何使用 PHP 和 XPath 解析 HTML 內容
Jun 17, 2023 am 11:17 AM
如何使用 PHP 和 XPath 解析 HTML 內容
Jun 17, 2023 am 11:17 AM
隨著Web技術不斷發展,Web頁面的內容也越來越複雜。我們常常需要從HTML頁面中抽取資訊以進行進一步的處理和分析,如爬蟲、資料探勘等。本文將介紹如何使用PHP和XPath解析HTML內容,方便快速地取得我們需要的資訊。 PHPSimpleHTMLDOMParserPHPSimpleHTMLDOMParser是一個開源的
 PHP 實戰:使用 XPath 從 XML 文件中提取數據
Jun 13, 2023 pm 10:03 PM
PHP 實戰:使用 XPath 從 XML 文件中提取數據
Jun 13, 2023 pm 10:03 PM
在使用PHP處理XML資料時,XPath是一種非常有用的工具。 XPath是一種用於在XML文件中定位元素的語言。它可以幫助開發人員快速、簡單地從XML文件中提取所需的資料。在本文中,我們將介紹XPath的基本概念,並詳細說明如何在PHP中使用XPath。我們將示範如何使用XPath從XML文件中提取數據,並建立一個簡單的
 PHP XPath 函數使用詳解:XPath提供XML和HTML檔案搜尋和查詢功能
Jun 27, 2023 pm 01:04 PM
PHP XPath 函數使用詳解:XPath提供XML和HTML檔案搜尋和查詢功能
Jun 27, 2023 pm 01:04 PM
XPath是一種查詢和定位XML和HTML文件中特定節點的語言。作為一種路徑表達式語言,XPath在許多程式語言中廣泛使用,其中包括PHP。在本文中,我們將深入了解PHPXPath函數的使用方法,以便您可以輕鬆地在您的專案中使用XPath來搜尋和查詢XML和HTML檔案。什麼是XPath? XPath是一種查詢和定位XML和HTML文件中特定節點的語言,它是
 xPath注入的基礎語法有哪些
May 26, 2023 pm 12:01 PM
xPath注入的基礎語法有哪些
May 26, 2023 pm 12:01 PM
首先什麼是xPath:xPath是一種在xml中尋找資訊的語言在xPath中,有七種元素的節點:元素、屬性、文字、命名空間、處理指令、註解以及文件(根節點)。 xml文檔被當作文檔樹來解析,樹的根稱為文檔節點或根節點。這是一份基本的xml文件的源碼,從這份xml源碼可以看出,bookstore為文檔節點(根節點),book、title、author、year、price是元素節點。其中book節點有四個子元素節點:title、author、year、price,title節點有三個同胞:au
 如何使用 Python 實作 xpath、JsonPath 和 bs4?
May 09, 2023 pm 09:04 PM
如何使用 Python 實作 xpath、JsonPath 和 bs4?
May 09, 2023 pm 09:04 PM
1.xpath1.1xpath使用google提前安裝xpath插件,按ctrl+shift+x出現小黑框安裝lxml庫pipinstalllxml‐ihttps://pypi.douban.com/simple導入lxml.etreefromlxmlimportetreeetree.parse()解析本地文件html_tree =etree.parse('XX.html')etree.HTML()伺服器回應檔html_tree=etree.HTML(respon
 PHP中的DOM與XPath技術
May 11, 2023 pm 04:04 PM
PHP中的DOM與XPath技術
May 11, 2023 pm 04:04 PM
近年來,隨著網路的不斷發展,Web開發技術也不斷的更新迭代。其中,PHP語言因其易學易用、運行速度快、跨平台特性被廣泛應用於Web開發領域。在PHP中,DOM和XPath技術是開發Web應用時常用到的技術,本文將詳細介紹這兩項技術的基礎知識和應用場景。一、DOM技術DOM(文件物件模型,DocumentObjectModel)是一種處理XML或HTM
 使用XPATH搜尋包含 的文本
Sep 10, 2023 am 11:33 AM
使用XPATH搜尋包含 的文本
Sep 10, 2023 am 11:33 AM
我們可以使用定位器xpath來識別具有搜尋文字的元素帶有或空格。讓我們先檢查一個web元素的html程式碼尾隨和前導空格。在下圖中,文字JAVABASICS帶有如html程式碼中所反映的,標記名Strong包含空格。如果元素的文字或任何屬性的值中有空格,則建立對於這樣一個元素的xpath,我們必須使用標準化空間函數。它從字串中刪除所有尾隨和前導空格。它還刪除了每個新的標籤或字串中已存在的行。 Syntax//tagname[normalize-space(@attribute/functio
 JavaScript選擇器的類型和用途的深入研究
Dec 26, 2023 pm 12:38 PM
JavaScript選擇器的類型和用途的深入研究
Dec 26, 2023 pm 12:38 PM
深入探索JavaScript選擇器的不同類型和用途引言:JavaScript是一種強大的腳本語言,廣泛應用於網頁開發。在開發過程中,我們經常需要透過選擇器來取得或操作HTML元素。 JavaScript提供了不同類型的選擇器,能夠滿足不同的需求。本文將深入探索JavaScript選擇器的不同類型和用途,並提供具體的程式碼範例。一、getElementById選
