

python如何實作決策樹分類演算法

前置訊息
1、決策樹
重寫後的句子: 在監督學習中,常用的一種分類演算法是決策樹,其基於一批樣本,每個樣本都包含一組屬性和對應的分類結果。利用這些樣本進行學習,演算法可以產生一棵決策樹,決策樹可以對新資料進行正確分類
2、樣本資料
假設現有用戶14名,其個人屬性及是否購買某一產品的資料如下:
| 編號 | #年齡 | ##工作性質#信用評級 | |||
|---|---|---|---|---|---|
| #01 | 高 | 不穩定 | 較差 | ||
| #02 | 高 | 不穩定 | 好 | ||
| #03 | 30-40 | 高 | 不穩定 | 較差 | |
| #04 | >40 | 中 | 不穩定 | 較差 | |
| #05 | >40 | 低 | 穩定 | 較差 | |
| 06 | #> 40 | 低 | 穩定 | 好 | |
| #07 | 30- 40 | 低 | 穩定 | 好 | |
| ##08 | 中等 | 不穩定 | 較差 | ||
| #09 | # | ||||
| 穩定 | 較差 | #是 | 10 | >40 | |
| 穩定 | 較差 | #是 | 11 | ||
| 穩定 | 好 | #是 | 12 | 30-40 | |
| 不穩定 | 好 | #是 | 13 | 30-40 | |
| 穩定 | 較差 | 是 | 14 | >40 |
策樹分類演算法
1、建立資料集
為了方便處理,對類比資料依下列規則轉換為數值型清單資料:
年齡:< ;30賦值為0;30-40賦值為1;>40賦值為2
收入:低為0;中為1;高為2
工作性質:不穩定為0;穩定為1
信用評級:差為0;好為1
#创建数据集
def createdataset():
dataSet=[[0,2,0,0,'N'],
[0,2,0,1,'N'],
[1,2,0,0,'Y'],
[2,1,0,0,'Y'],
[2,0,1,0,'Y'],
[2,0,1,1,'N'],
[1,0,1,1,'Y'],
[0,1,0,0,'N'],
[0,0,1,0,'Y'],
[2,1,1,0,'Y'],
[0,1,1,1,'Y'],
[1,1,0,1,'Y'],
[1,2,1,0,'Y'],
[2,1,0,1,'N'],]
labels=['age','income','job','credit']
return dataSet,labels呼叫函數,可取得資料:
ds1,lab = createdataset() print(ds1) print(lab)
[[0, 2 , 0, 0, ‘N’], [0, 2, 0, 1, ‘N’], [1, 2, 0, 0, ‘Y’], [2, 1, 0, 0, ‘Y’], [2, 0, 1, 0, ‘Y’], [2, 0, 1, 1, ‘N’], [1, 0, 1, 1, ‘Y’] , [0, 1, 0, 0, ‘N’], [0, 0, 1, 0, ‘Y’], [2, 1, 1, 0, ‘Y’], [0, 1 , 1, 1, ‘Y’], [1, 1, 0, 1, ‘Y’], [1, 2, 1, 0, ‘Y’], [2, 1, 0, 1, ‘N’]]
[‘age’, ‘income’, ‘job’, ‘credit’]
#2、資料集資訊熵
# #資訊熵也稱為香農熵,是隨機變數的期望。度量資訊的不確定程度。訊息的熵越大,訊息就越不容易搞清楚。處理資訊就是為了把資訊搞清楚,就是熵減少的過程。
def calcShannonEnt(dataSet):
numEntries = len(dataSet)
labelCounts = {}
for featVec in dataSet:
currentLabel = featVec[-1]
if currentLabel not in labelCounts.keys():
labelCounts[currentLabel] = 0
labelCounts[currentLabel] += 1
shannonEnt = 0.0
for key in labelCounts:
prob = float(labelCounts[key])/numEntries
shannonEnt -= prob*log(prob,2)
return shannonEnt樣本資料資訊熵:
shan = calcShannonEnt(ds1) print(shan)
0.9402859586706309
3、資訊增益
資訊增益:用於度量屬性A降低樣本集合X熵的貢獻大小。資訊增益越大,越適於對X分類。
def chooseBestFeatureToSplit(dataSet):
numFeatures = len(dataSet[0])-1
baseEntropy = calcShannonEnt(dataSet)
bestInfoGain = 0.0;bestFeature = -1
for i in range(numFeatures):
featList = [example[i] for example in dataSet]
uniqueVals = set(featList)
newEntroy = 0.0
for value in uniqueVals:
subDataSet = splitDataSet(dataSet, i, value)
prop = len(subDataSet)/float(len(dataSet))
newEntroy += prop * calcShannonEnt(subDataSet)
infoGain = baseEntropy - newEntroy
if(infoGain > bestInfoGain):
bestInfoGain = infoGain
bestFeature = i
return bestFeature以上程式碼實現了基於資訊熵增益的ID3決策樹學習演算法。其核心邏輯原理為:依序選取屬性集中的每一個屬性,將樣本集依此屬性的取值分割為若干個子集;對這些子集計算資訊熵,其與樣本的資訊熵的差,即為依照此屬性分割的資訊熵增益;找出所有增益中最大的那一個對應的屬性,就是用來分割樣本集的屬性。
計算樣本最佳的分割樣本屬性,結果顯示為第0列,即age屬性:
col = chooseBestFeatureToSplit(ds1) col
0
4、建構決策樹
def majorityCnt(classList):
classCount = {}
for vote in classList:
if vote not in classCount.keys():classCount[vote] = 0
classCount[vote] += 1
sortedClassCount = sorted(classList.iteritems(),key=operator.itemgetter(1),reverse=True)#利用operator操作键值排序字典
return sortedClassCount[0][0]
#创建树的函数
def createTree(dataSet,labels):
classList = [example[-1] for example in dataSet]
if classList.count(classList[0]) == len(classList):
return classList[0]
if len(dataSet[0]) == 1:
return majorityCnt(classList)
bestFeat = chooseBestFeatureToSplit(dataSet)
bestFeatLabel = labels[bestFeat]
myTree = {bestFeatLabel:{}}
del(labels[bestFeat])
featValues = [example[bestFeat] for example in dataSet]
uniqueVals = set(featValues)
for value in uniqueVals:
subLabels = labels[:]
myTree[bestFeatLabel][value] = createTree(splitDataSet(dataSet, bestFeat, value), subLabels)
return myTreemajorityCnt函數用來處理情況:當最終的理想決策樹應該沿著決策分支到達最底端時,所有的樣本應該都是相同的分類結果。但真實樣本中難免會出現所有屬性一致但分類結果不一樣的情況,此時majorityCnt將這類樣本的分類標籤都調整為出現次數最多的那一個分類結果。
createTree是核心任務函數,它對所有的屬性依序呼叫ID3資訊熵增益演算法進行計算處理,最終產生決策樹。
5、實例化建構決策樹
利用樣本資料建構決策樹:
Tree = createTree(ds1, lab)
print("样本数据决策树:")
print(Tree)樣本資料決策樹:
{‘age’: {0: {‘job’: {0: ‘N’, 1: ‘Y’}},
1: ‘Y’,
2: {‘credit’: {0: ‘Y’, 1: ‘N’}}}}
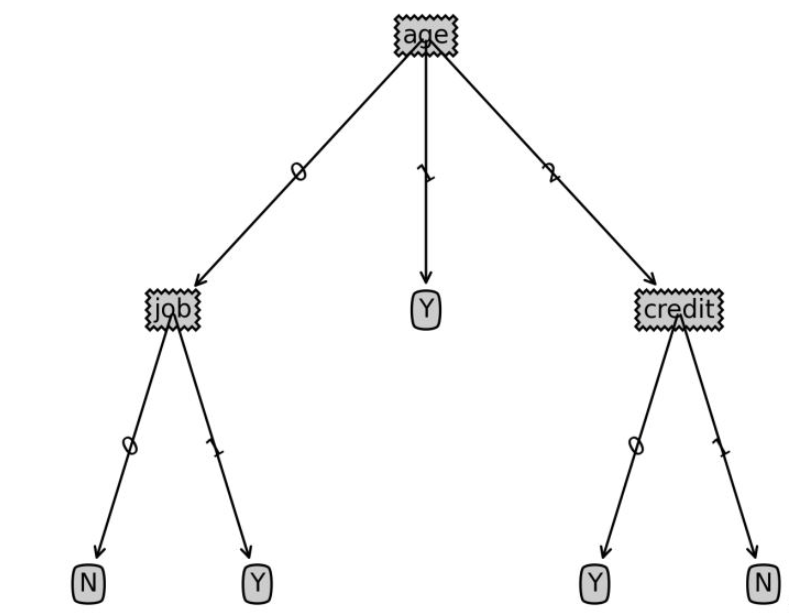
#6、測試樣本分類
##給予一個新的用戶訊息,判斷ta是否購買某一產品:| #收入範圍 | 工作性質 | #信用評級 | |
|---|---|---|---|
| 低 | #穩定 | 好 | |
| 高 | 不穩定 | 好 |
result: Y後置資訊:繪製決策樹程式碼#以下程式碼用於繪製決策樹圖形,非決策樹演算法重點,有興趣可參考學習result1: N
import matplotlib.pyplot as plt
decisionNode = dict(box, fc="0.8")
leafNode = dict(box, fc="0.8")
arrow_args = dict(arrow)
#获取叶节点的数目
def getNumLeafs(myTree):
numLeafs = 0
firstStr = list(myTree.keys())[0]
secondDict = myTree[firstStr]
for key in secondDict.keys():
if type(secondDict[key]).__name__=='dict':#测试节点的数据是否为字典,以此判断是否为叶节点
numLeafs += getNumLeafs(secondDict[key])
else: numLeafs +=1
return numLeafs
#获取树的层数
def getTreeDepth(myTree):
maxDepth = 0
firstStr = list(myTree.keys())[0]
secondDict = myTree[firstStr]
for key in secondDict.keys():
if type(secondDict[key]).__name__=='dict':#测试节点的数据是否为字典,以此判断是否为叶节点
thisDepth = 1 + getTreeDepth(secondDict[key])
else: thisDepth = 1
if thisDepth > maxDepth: maxDepth = thisDepth
return maxDepth
#绘制节点
def plotNode(nodeTxt, centerPt, parentPt, nodeType):
createPlot.ax1.annotate(nodeTxt, xy=parentPt, xycoords='axes fraction',
xytext=centerPt, textcoords='axes fraction',
va="center", ha="center", bbox=nodeType, arrowprops=arrow_args )
#绘制连接线
def plotMidText(cntrPt, parentPt, txtString):
xMid = (parentPt[0]-cntrPt[0])/2.0 + cntrPt[0]
yMid = (parentPt[1]-cntrPt[1])/2.0 + cntrPt[1]
createPlot.ax1.text(xMid, yMid, txtString, va="center", ha="center", rotation=30)
#绘制树结构
def plotTree(myTree, parentPt, nodeTxt):#if the first key tells you what feat was split on
numLeafs = getNumLeafs(myTree) #this determines the x width of this tree
depth = getTreeDepth(myTree)
firstStr = list(myTree.keys())[0] #the text label for this node should be this
cntrPt = (plotTree.xOff + (1.0 + float(numLeafs))/2.0/plotTree.totalW, plotTree.yOff)
plotMidText(cntrPt, parentPt, nodeTxt)
plotNode(firstStr, cntrPt, parentPt, decisionNode)
secondDict = myTree[firstStr]
plotTree.yOff = plotTree.yOff - 1.0/plotTree.totalD
for key in secondDict.keys():
if type(secondDict[key]).__name__=='dict':#test to see if the nodes are dictonaires, if not they are leaf nodes
plotTree(secondDict[key],cntrPt,str(key)) #recursion
else: #it's a leaf node print the leaf node
plotTree.xOff = plotTree.xOff + 1.0/plotTree.totalW
plotNode(secondDict[key], (plotTree.xOff, plotTree.yOff), cntrPt, leafNode)
plotMidText((plotTree.xOff, plotTree.yOff), cntrPt, str(key))
plotTree.yOff = plotTree.yOff + 1.0/plotTree.totalD
#创建决策树图形
def createPlot(inTree):
fig = plt.figure(1, facecolor='white')
fig.clf()
axprops = dict(xticks=[], yticks=[])
createPlot.ax1 = plt.subplot(111, frameon=False, **axprops) #no ticks
#createPlot.ax1 = plt.subplot(111, frameon=False) #ticks for demo puropses
plotTree.totalW = float(getNumLeafs(inTree))
plotTree.totalD = float(getTreeDepth(inTree))
plotTree.xOff = -0.5/plotTree.totalW; plotTree.yOff = 1.0;
plotTree(inTree, (0.5,1.0), '')
plt.savefig('决策树.png',dpi=300,bbox_inches='tight')
plt.show()以上是python如何實作決策樹分類演算法的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 PHP和Python:解釋了不同的範例
Apr 18, 2025 am 12:26 AM
PHP和Python:解釋了不同的範例
Apr 18, 2025 am 12:26 AM
PHP主要是過程式編程,但也支持面向對象編程(OOP);Python支持多種範式,包括OOP、函數式和過程式編程。 PHP適合web開發,Python適用於多種應用,如數據分析和機器學習。
 在PHP和Python之間進行選擇:指南
Apr 18, 2025 am 12:24 AM
在PHP和Python之間進行選擇:指南
Apr 18, 2025 am 12:24 AM
PHP適合網頁開發和快速原型開發,Python適用於數據科學和機器學習。 1.PHP用於動態網頁開發,語法簡單,適合快速開發。 2.Python語法簡潔,適用於多領域,庫生態系統強大。
 sublime怎麼運行代碼python
Apr 16, 2025 am 08:48 AM
sublime怎麼運行代碼python
Apr 16, 2025 am 08:48 AM
在 Sublime Text 中運行 Python 代碼,需先安裝 Python 插件,再創建 .py 文件並編寫代碼,最後按 Ctrl B 運行代碼,輸出會在控制台中顯示。
 Python vs. JavaScript:學習曲線和易用性
Apr 16, 2025 am 12:12 AM
Python vs. JavaScript:學習曲線和易用性
Apr 16, 2025 am 12:12 AM
Python更適合初學者,學習曲線平緩,語法簡潔;JavaScript適合前端開發,學習曲線較陡,語法靈活。 1.Python語法直觀,適用於數據科學和後端開發。 2.JavaScript靈活,廣泛用於前端和服務器端編程。
 PHP和Python:深入了解他們的歷史
Apr 18, 2025 am 12:25 AM
PHP和Python:深入了解他們的歷史
Apr 18, 2025 am 12:25 AM
PHP起源於1994年,由RasmusLerdorf開發,最初用於跟踪網站訪問者,逐漸演變為服務器端腳本語言,廣泛應用於網頁開發。 Python由GuidovanRossum於1980年代末開發,1991年首次發布,強調代碼可讀性和簡潔性,適用於科學計算、數據分析等領域。
 Golang vs. Python:性能和可伸縮性
Apr 19, 2025 am 12:18 AM
Golang vs. Python:性能和可伸縮性
Apr 19, 2025 am 12:18 AM
Golang在性能和可擴展性方面優於Python。 1)Golang的編譯型特性和高效並發模型使其在高並發場景下表現出色。 2)Python作為解釋型語言,執行速度較慢,但通過工具如Cython可優化性能。
 vscode在哪寫代碼
Apr 15, 2025 pm 09:54 PM
vscode在哪寫代碼
Apr 15, 2025 pm 09:54 PM
在 Visual Studio Code(VSCode)中編寫代碼簡單易行,只需安裝 VSCode、創建項目、選擇語言、創建文件、編寫代碼、保存並運行即可。 VSCode 的優點包括跨平台、免費開源、強大功能、擴展豐富,以及輕量快速。
 notepad 怎麼運行python
Apr 16, 2025 pm 07:33 PM
notepad 怎麼運行python
Apr 16, 2025 pm 07:33 PM
在 Notepad 中運行 Python 代碼需要安裝 Python 可執行文件和 NppExec 插件。安裝 Python 並為其添加 PATH 後,在 NppExec 插件中配置命令為“python”、參數為“{CURRENT_DIRECTORY}{FILE_NAME}”,即可在 Notepad 中通過快捷鍵“F6”運行 Python 代碼。
