

MySQL調優之SQL查詢深度分頁問題怎麼解決

一、問題引入
例如目前存在一張表test_user,然後往這個表裡面插入3百萬的資料:
CREATE TABLE `test_user` ( `id` int(11) NOT NULL AUTO_INCREMENT COMMENT '主键id', `user_id` varchar(36) NOT NULL COMMENT '用户id', `user_name` varchar(30) NOT NULL COMMENT '用户名称', `phone` varchar(20) NOT NULL COMMENT '手机号码', `lan_id` int(9) NOT NULL COMMENT '本地网', `region_id` int(9) NOT NULL COMMENT '区域', `create_time` datetime NOT NULL COMMENT '创建时间', PRIMARY KEY (`id`), KEY `idx_user_id` (`user_id`) ) ENGINE=InnoDB AUTO_INCREMENT;
在資料庫開發過程中我們常常會使用分頁,核心技術是使用用 limit start, count 分頁語句進行資料的讀取。
我們分別看下從0、10000、100000、500000、1000000、1800000開始分頁的執行時長(每頁取100條)。
SELECT * FROM test_user LIMIT 0,100; # 0.031 SELECT * FROM test_user LIMIT 10000,100; # 0.047 SELECT * FROM test_user LIMIT 100000,100; # 0.109 SELECT * FROM test_user LIMIT 500000,100; # 0.219 SELECT * FROM test_user LIMIT 1000000,100; # 0.547s SELECT * FROM test_user LIMIT 1800000,100; # 1.625s
我們已經看出隨著起始記錄的增加,時間也隨著增加。改變起始記錄為290萬後,我們可以看到分頁語句中的limit和起始頁碼之間存在很大的關聯
SELECT * FROM test_user LIMIT 2900000,100; # 3.062s
我們驚訝的發現MySQL在資料量大的情況下分頁起點越大,查詢速度越慢!
那麼為什麼會出現上述這種情況呢?
答案: 因為 limit 2900000,100 的語法其實是mysql掃描到前2900100條數據,之後丟棄前面的3000000行,這個步驟其實是浪費掉的。
從中我們也能總結出以下兩件事:
limit語句的查詢時間與起始記錄的位置成正比。
mysql的limit語句是很方便,但是對記錄很多的表並不適合直接使用。
二、MySQL中的limit用法
limit子句可以用來強制select語句傳回指定的記錄數,其語法格式如下:
SELECT * FROM 表名 limit m,n; SELECT * FROM table LIMIT [offset,] rows;
limit接受一個或兩個數字參數,參數必須是一個整數常數,如果給定兩個參數:
第一個參數指定第一個傳回記錄行的偏移量
第二個參數指定傳回記錄行的最大數目
2.1 m代表從m 1筆記錄行開始檢索,n代表取出n筆資料。 (m可設為0)
SELECT * FROM 表名 limit 6,5;
上述SQL表示從第7筆記錄行開始算,取出5筆資料
2.2 值得注意的是,n可以設定為-1,當n為-1時,表示從m 1行開始檢索,直到取出最後一條資料
SELECT * FROM 表名 limit 6,-1;
上述SQL表示取出第6筆記錄行以後的所有資料
2.3 若只給m,則表示從第1筆記錄行開始算一共取出m條
SELECT * FROM 表名 limit 6;
2.4 以年齡倒序後取出前3行
select * from student order by age desc limit 3;
2.5 跳過前3行後再2取行
select * from student order by age desc limit 3,2;
三、深度分頁最佳化策略
方法一:用主鍵id或唯一索引優化
即先找到上次分頁的最大id,然後利用id上的索引來查詢:
SELECT * FROM test_user WHERE id>1000000 LIMIT 100; # 0.047秒
使用此最佳化SQL比起前面的查詢速度已經快了11倍。除了使用主鍵ID,還可以運用唯一索引來快速定位特定數據,從而避免全表掃描。以下是對應的SQL最佳化程式碼,讀取唯一鍵(pk)在1000至1019範圍內的資料:
SELECT * FROM 表名称 WHERE pk>=1000 ORDER BY pk ASC LIMIT 0,20
原因:索引掃描,速度會很快。
適用場景:如果資料查詢出來是按照pk或id進行排序,而全部資料沒有缺少的話則可以這樣優化,否則分頁操作會遺漏資料。
方法二:利用索引覆蓋優化
我們都知道,利用了索引查詢的語句中如果只包含了那個索引列(也就是索引覆蓋),那麼這種情況就會查詢很快。
為什麼索引覆蓋查詢會很快呢?
答案:因為利用索引來找出有最佳化演算法,且資料就在查詢索引上面,不用再去找相關的資料位址了,這樣節省了很多時間。當並發量較高時,Mysql也提供了與索引相關聯的緩存,充分利用此緩存可以獲得更佳的效果。
由於在我們的測試表test_user中,id欄位是主鍵,因此預設包含了主鍵索引。現在讓我們看看利用覆蓋索引的查詢效果如何。
這次我們查詢第1000001到1000100行的資料(利用覆蓋索引,只包含id列):
SELECT id FROM test_user LIMIT 1000000,100; # 0.843秒
從這個結果發現查詢速度比全表掃描速度還要慢(當然在重複執行這條SQL,多次查詢之後速度還是變快了很多,幾乎省了一半時間,這是由於緩存的原因), 接著使用explain命令來查看該SQL的執行計劃,發現該SQL執行採用的普通索引 idx_user_id:
EXPLAIN SELECT id FROM test_user LIMIT 1000000,100;
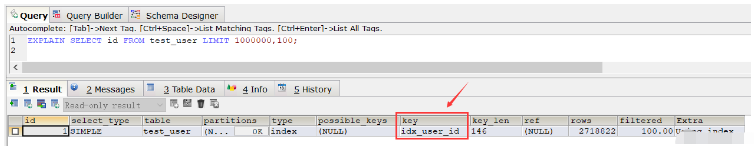
#如果我們刪除普通索引,執行上述SQL時會使用主鍵索引。那如果不刪除普通索引的話,針對這種情況,我們要讓上述SQL走主鍵索引的話,則可以使用order by語句:
SELECT id FROM test_user ORDER BY id ASC LIMIT 1000000,100; # 0.250秒
那麼如果我們也要查詢所有列,有兩種方法,一種是id>=的形式,另一種就是利用join。
第一種寫法:
SELECT * FROM test_user WHERE ID >= (SELECT id FROM test_user ORDER BY id ASC LIMIT 1000000,1) LIMIT 100;
上述SQL查詢時間為0.281秒
第二種寫法:
SELECT * FROM (SELECT id FROM test_user ORDER BY id ASC LIMIT 1000000,100) a LEFT JOIN test_user b ON a.id = b.id;
上述SQL查詢時間為0.252秒
方法三:基於索引再排序
其中pageNum表示頁碼,其取值從0開始;pageSize表示指的是每頁多少條資料。
SELECT * FROM 表名称 WHERE id_pk > (pageNum*pageSize) ORDER BY id_pk ASC LIMIT pageSize;
适应场景:
适用于数据量多的情况
最好ORDER BY后的列对象是主键或唯一索引
id数据没有缺失,可以作为序号使用
使用ORDER BY操作能利用索引被消除,但结果集是稳定的
原因:
索引扫描,速度会很快
但MySQL的排序操作,只有ASC没有DESC。在MySQL中,索引的存储顺序是升序ASC,没有降序DESC的索引。这就是为什么默认情况下,order by 是按照升序排序的原因
方法四:基于索引使用prepare
PREPARE预编译一个SQL语句,并为其分配一个名称 stmt_name,以便以后引用该语句,预编译好的语句用EXECUTE执行。
PREPARE stmt_name FROM 'SELECT * FROM test_user WHERE id > ? ORDER BY id ASC LIMIT ?'; SET @a = 1000000; SET @b = 100; EXECUTE stmt_name USING @a, @b;;

上述SQL查询时间为0.047秒。
对于定义好的PREPARE预编译语句,我们可以使用下述命令来释放该预编译语句:
DEALLOCATE PREPARE stmt_name;
原因:
索引扫描,速度会很快.
prepare语句又比一般的查询语句快一点。
方法五:利用"子查询+索引"快速定位数据
其中page表示页码,其取值从0开始;pagesize表示指的是每页多少条数据。
SELECT * FROM your_table WHERE id <= (SELECT id FROM your_table ORDER BY id DESC LIMIT ($page-1)*$pagesize ORDER BY id DESC LIMIT $pagesize);
方法六:利用复合索引进行优化
假设数据表 collect ( id, title ,info ,vtype) 就这4个字段,其中id是主键自增,title用定长,info用text, vtype是tinyint,vtype是一个普通索引。
现在往里面填充数据,填充10万条记录,数据库表占用硬1.6G。
select id,title from collect limit 1000,10;
执行上述SQL速度很快,基本上0.01秒就OK。
select id,title from collect limit 90000,10;
然后再执行上述SQL,就发现非常慢,基本上平均8~9秒完成。
这个时候如果我们执行下述,我们会发现速度又变的很快,0.04秒就OK。
select id from collect order by id limit 90000,10;
那么这个现象的原因是什么?
答案:因为用了id主键做索引, 这里实现了索引覆盖,当然快。
所以如果想一起查询其它列的话,可以按照索引覆盖进行优化,具体如下:
select id,title from collect where id >= (select id from collect order by id limit 90000,1) limit 10;
再看下面的语句,带上where 条件:
select id from collect where vtype=1 order by id limit 90000,10;
可以发现这个速度上也是很慢的,用了8~9秒!
这里有一个疑惑:vtype 做了索引了啊?怎么会慢呢?
vtype做了索引是不错,如果直接对vtype进行过滤:
select id from collect where vtype=1 limit 1000,10;
可以看到速度还是很快的,基本上0.05秒,如果从9万开始,那就是0.05*90=4.5秒的速度了。
其实加了 order by id 就不走索引,这样做还是全表扫描,解决的办法是:复合索引!
因此针对下述SQL深度分页优化时可以加一个search_index(vtype,id)复合索引:
select id from collect where vtype=1 order by id limit 90000,10;
综上:
在进行SQL查询深度分页优化时,如果对于有where条件,又想走索引用limit的,必须设计一个索引,将where放第一位,limit用到的主键放第二位,而且只能select 主键。
最后根据查询出的主键走一级索引找到对应的数据。
按这样的逻辑,百万级的limit 在0.0x秒就可以分完,完美解决了分页问题。
以上是MySQL調優之SQL查詢深度分頁問題怎麼解決的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

AI Hentai Generator
免費產生 AI 無盡。

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)
熱門話題



 MySQL:初學者的數據管理易用性
Apr 09, 2025 am 12:07 AM
MySQL:初學者的數據管理易用性
Apr 09, 2025 am 12:07 AM
MySQL適合初學者使用,因為它安裝簡單、功能強大且易於管理數據。 1.安裝和配置簡單,適用於多種操作系統。 2.支持基本操作如創建數據庫和表、插入、查詢、更新和刪除數據。 3.提供高級功能如JOIN操作和子查詢。 4.可以通過索引、查詢優化和分錶分區來提升性能。 5.支持備份、恢復和安全措施,確保數據的安全和一致性。
 phpmyadmin怎麼打開
Apr 10, 2025 pm 10:51 PM
phpmyadmin怎麼打開
Apr 10, 2025 pm 10:51 PM
可以通過以下步驟打開 phpMyAdmin:1. 登錄網站控制面板;2. 找到並點擊 phpMyAdmin 圖標;3. 輸入 MySQL 憑據;4. 點擊 "登錄"。
 MySQL和SQL:開發人員的基本技能
Apr 10, 2025 am 09:30 AM
MySQL和SQL:開發人員的基本技能
Apr 10, 2025 am 09:30 AM
MySQL和SQL是開發者必備技能。 1.MySQL是開源的關係型數據庫管理系統,SQL是用於管理和操作數據庫的標準語言。 2.MySQL通過高效的數據存儲和檢索功能支持多種存儲引擎,SQL通過簡單語句完成複雜數據操作。 3.使用示例包括基本查詢和高級查詢,如按條件過濾和排序。 4.常見錯誤包括語法錯誤和性能問題,可通過檢查SQL語句和使用EXPLAIN命令優化。 5.性能優化技巧包括使用索引、避免全表掃描、優化JOIN操作和提升代碼可讀性。
 navicat premium怎麼創建
Apr 09, 2025 am 07:09 AM
navicat premium怎麼創建
Apr 09, 2025 am 07:09 AM
使用 Navicat Premium 創建數據庫:連接到數據庫服務器並輸入連接參數。右鍵單擊服務器並選擇“創建數據庫”。輸入新數據庫的名稱和指定字符集和排序規則。連接到新數據庫並在“對象瀏覽器”中創建表。右鍵單擊表並選擇“插入數據”來插入數據。
 mysql:簡單的概念,用於輕鬆學習
Apr 10, 2025 am 09:29 AM
mysql:簡單的概念,用於輕鬆學習
Apr 10, 2025 am 09:29 AM
MySQL是一個開源的關係型數據庫管理系統。 1)創建數據庫和表:使用CREATEDATABASE和CREATETABLE命令。 2)基本操作:INSERT、UPDATE、DELETE和SELECT。 3)高級操作:JOIN、子查詢和事務處理。 4)調試技巧:檢查語法、數據類型和權限。 5)優化建議:使用索引、避免SELECT*和使用事務。
 navicat怎麼新建連接mysql
Apr 09, 2025 am 07:21 AM
navicat怎麼新建連接mysql
Apr 09, 2025 am 07:21 AM
可在 Navicat 中通過以下步驟新建 MySQL 連接:打開應用程序並選擇“新建連接”(Ctrl N)。選擇“MySQL”作為連接類型。輸入主機名/IP 地址、端口、用戶名和密碼。 (可選)配置高級選項。保存連接並輸入連接名稱。
 如何將 AWS Glue 爬網程序與 Amazon Athena 結合使用
Apr 09, 2025 pm 03:09 PM
如何將 AWS Glue 爬網程序與 Amazon Athena 結合使用
Apr 09, 2025 pm 03:09 PM
作為數據專業人員,您需要處理來自各種來源的大量數據。這可能會給數據管理和分析帶來挑戰。幸運的是,兩項 AWS 服務可以提供幫助:AWS Glue 和 Amazon Athena。
 navicat如何執行sql
Apr 08, 2025 pm 11:42 PM
navicat如何執行sql
Apr 08, 2025 pm 11:42 PM
在 Navicat 中執行 SQL 的步驟:連接到數據庫。創建 SQL 編輯器窗口。編寫 SQL 查詢或腳本。單擊“運行”按鈕執行查詢或腳本。查看結果(如果執行查詢的話)。
