
1、概念
快取穿透的概念很簡單,使用者想要查詢一個數據,發現redis記憶體資料庫沒有,也就是快取沒有命中,於是向持久層資料庫查詢。發現也沒有,於是本次查詢失敗。當使用者很多的時候,快取都沒有命中,於是都去請求了持久層資料庫。當發生快取穿透時,持久層資料庫會承受巨大的負擔。
這裡需要注意和緩存擊穿的區別,緩存擊穿,是指一個key非常熱點,在不停的扛著大並發,大並發集中對這一個點進行訪問,當這個key在失效的瞬間,持續的大並發就穿破緩存,直接請求資料庫,就像在一個屏障上鑿開了一個洞。
為了避免快取穿透其實有很多種解決方案。下面介紹幾種。
2、解決方案
(1)布隆過濾器
據統計,全世界垃圾網站和正常網站加起來數量達到數十億個,而布隆過濾器是一種可以應用於這種資料規模的資料結構。使用布隆過濾器可以避免網警需要逐一比較資料庫中的垃圾網站。假設我們儲存一億個垃圾網站位址。
可以先有一億個二進位位元,然後網警用八個不同的隨機數產生器(F1,F2, …,F8) 產生八個資訊指紋(f1, f2, …, f8) 。接下來用一個隨機數產生器 G 把這八個資訊指紋映射到 1 到1億中的八個自然數 g1, g2, …,g8。最後把這八個位置的二進位全部設定為一。過程如下:
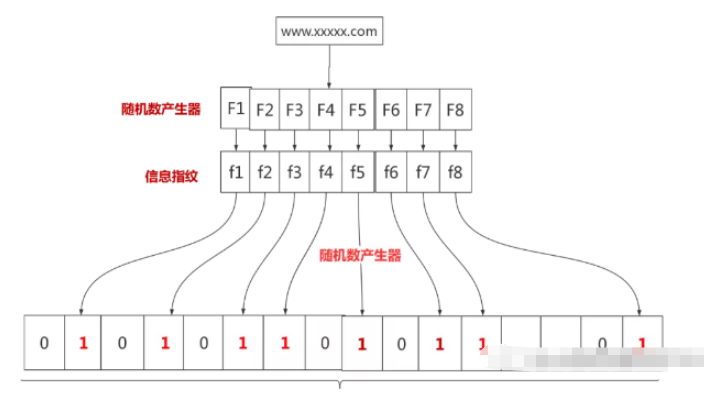
有一天網警查到了一個可疑的網站,想判斷一下是否是XX網站,首先將可疑網站通過哈希映射到1億個比特位數組上的8個點。如果有一個點不為1,那麼就可以確定該元素不在集合中。
那這個布隆過濾器是如何解決redis中的快取穿透呢?很簡單首先也是對所有可能查詢的參數以hash形式存儲,當用戶想要查詢的時候,使用布隆過濾器發現不在集合中,就直接丟棄,不再對持久層查詢。
這個形式很簡單。
2、快取空物件
當儲存層不命中後,即使傳回的空物件也將其快取起來,同時會設定一個過期時間,之後再存取這個資料將會從快取中獲取,保護了後端資料來源
但是這個方法會有兩個問題:
由於空值可能會佔據快取中很多的鍵位,所以快取需要更大的空間來儲存更多的鍵值對
即使對空值設定了過期時間,還是會存在快取層和儲存層的資料會有一段時間視窗的不一致,這對於需要保持一致性的業務會有影響。
1、概念
快取雪崩是指,快取層出現了錯誤,無法正常運作了。因此,所有請求都會被傳送到儲存層,導致儲存層的呼叫量急劇增加並可能導致其崩潰。
2、解決方案
#(1)redis高可用
這個想法的意思是,既然redis有可能掛掉,那我多增設幾台redis,這樣一台掛掉之後其他的還可以繼續工作,其實就是搭建的集群。
(2)限流降級
這個方案的想法是透過鎖定或佇列的方法來控制在快取失效後讀取資料庫並寫入快取的線程數量。例如,只允許一個執行緒查詢資料和寫入快取來操作某個key,其餘執行緒需要等待。
(3)資料預熱
資料加熱的含義就是在正式部署之前,我先把可能的資料先預先訪問一遍,這樣部分可能會大量訪問的資料就會載入到快取中。手動觸發不同key的快取加載,並為其設定不同的過期時間,以盡量均衡快取失效的時間,預防大量存取同時發生。
以上是Redis緩存穿透和緩存雪崩的概念是什麼的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















