

#首先來分享相關背景。
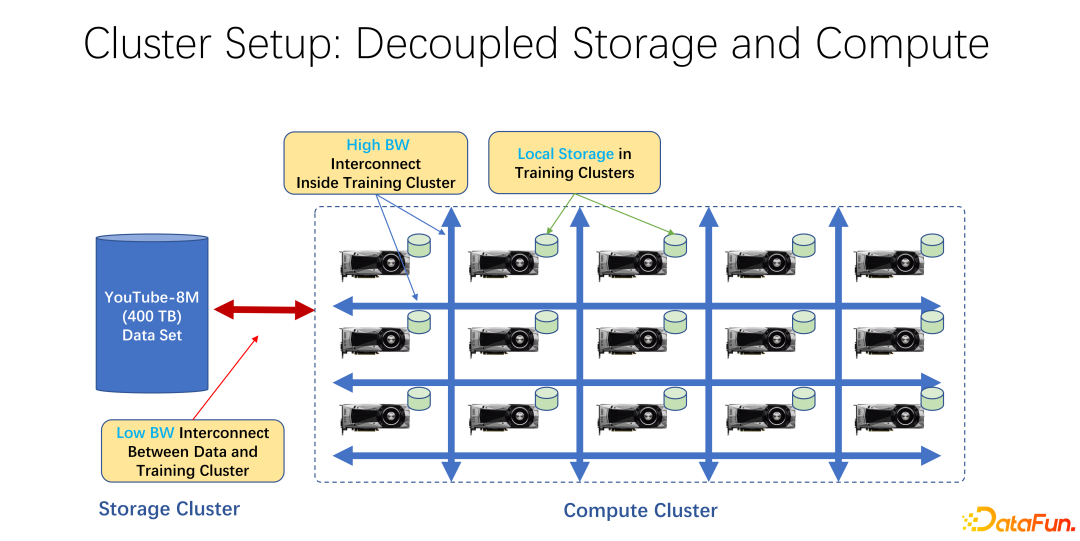
#近年來,AI 訓練應用越來越廣泛。從基礎架構角度來看,無論是大數據或 AI 訓練叢集中,大多使用儲存與運算分離的架構。例如很多 GPU 的陣列放到一個很大的運算叢集中,另外一個叢集是儲存。也可能是使用的一些雲端存儲,像微軟的 Azure 或是亞馬遜的 S3 等。
這樣的基礎架構的特點是,首先,計算叢集中有很多非常昂貴的GPU,每台 GPU 往往有一定的本地存儲,例如SSD這樣的幾十TB 的儲存。這樣一個機器組成的陣列中,往往是用高速網路去連接遠端,例如 Coco、 image net、YouTube 8M 之類的非常大規模的訓練資料是以網路進行連接的。
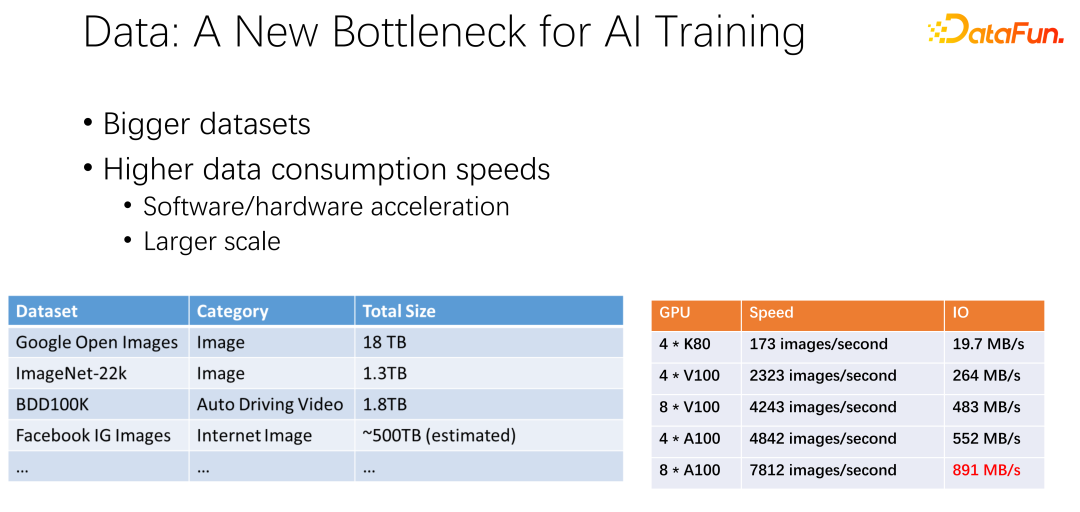
如上圖所示,資料有可能會成為下一個 AI 訓練的瓶頸。我們觀察到資料集越來越大,隨著 AI 應用更加廣泛,也累積更多的訓練資料。同時 GPU 賽道是非常捲的。例如 AMD、TPU 等廠商,花了大量精力去優化硬體和軟體,使得加速器,類似 GPU、TPU這些硬體越來越快。隨著公司內加速器的應用非常廣泛之後,集群部署也越來越大。這裡的兩個表呈現了關於資料集以及 GPU 速度的一些變化。之前的 K80 到 V100、 P100、 A100,速度是非常迅速的。但是,隨著速度越來越快,GPU 變得越來越昂貴。我們的數據,例如 IO 速度能否跟上 GPU 的速度,是一個很大的挑戰。

如上圖所示,在許多大公司的應用中,我們觀察到這樣一個現象:在讀取遠端資料的時候,GPU 是空閒的。因為 GPU 在等待遠端資料讀取,這也意味著 IO 成為了一個瓶頸,造成了昂貴的 GPU 被浪費。有很多工作在進行最佳化來緩解這一瓶頸,快取就是其中很重要的一個最佳化方向。這裡介紹兩種方式。

第一種,在許多應用場景中,尤其是以K8s 加Docker 這樣的基礎AI 訓練架構中,用了很多本地磁碟。前文提到 GPU 機器是有一定的本地儲存的,可以用本地磁碟去做一些緩存,把資料先緩存起來。
啟動了一個GPU 的Docker 之後,不是馬上啟動GPU 的AI 訓練,而是先去下載數據,把數據從遠端下載到Docker 內部,也可以是掛載等方式。下載到 Docker 內部之後再開始訓練。這樣盡可能的把後邊的訓練的資料讀取都變成本地的資料讀取。本地 IO 的性能目前來看是足夠支撐 GPU 的訓練的。 VLDB 2020 上面,有一篇 paper,CoorDL,是基於 DALI 進行資料快取。
#這方式也帶來了許多問題。首先,本地的空間是有限的,這意味著快取的資料也是有限的,當資料集越來越大的時候,很難快取到所有資料。另外,AI 場景與大數據場景有一個很大的差異是,AI 場景中的資料集是比較有限的。不像大數據場景中有很多的表,有各種各樣的業務,每個業務的數據表的內容差距是非常大的。在 AI 場景中,資料集的規模、資料集的數量遠小於大數據場景。所以常常會發現,公司提交的任務很多都是讀取同一個資料。如果每個人下載資料到自己本地,其實是不能共享的,會有非常多份資料被重複儲存到本地機器上。這種方式顯然存在著許多問題,也不夠有效率。
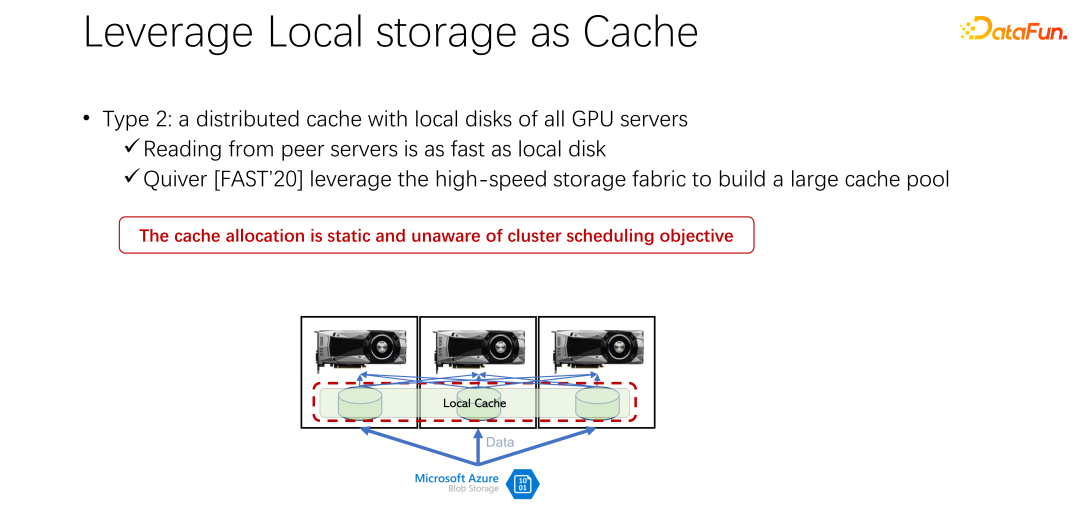
接下來介紹第二種方式。既然本地的儲存不太好,那麼,是否可以使用像 Alluxio 這樣一個分散式快取來緩解剛才的問題,分散式快取有非常大的容量來裝載資料。另外,Alluxio 作為一個分散式緩存,很容易進行共享。資料下載到 Alluxio 中,其他的客戶端,也可以從快取中讀取這份資料。這樣看來,使用 Alluxio 可以輕鬆解決上面提到的問題,為 AI 訓練性能帶來很大的提升。微軟印度研究院在 FAST2020 發表的名為 Quiver 的一篇論文,就提到了這樣的解決想法。但我們分析發現,這樣看似完美的分配方案,還是比較靜態的,並不有效率。同時,採用什麼樣的 cache 淘汰演算法,也是一個很值得討論的問題。
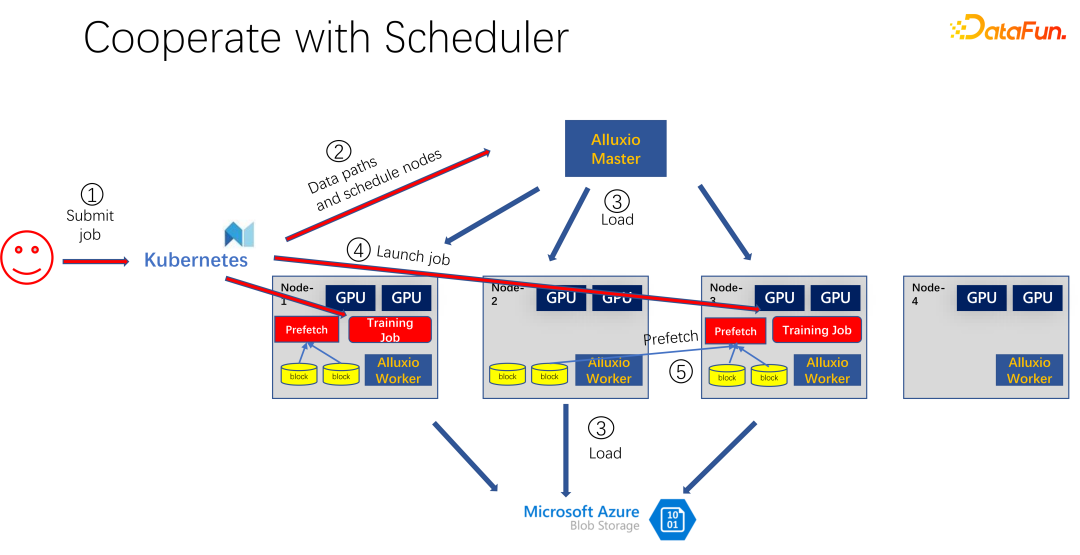
#如上圖所示,是使用 Alluxio 作為 AI 訓練的快取的一個應用。使用 K8s 做整個叢集任務的調度和對 GPU、CPU、記憶體等資源的管理。當有使用者提交任務到 K8s 時,K8s 首先會做一個插件,通知 Alluxio 的 master,讓它去下載這部分資料。也就是先進行一些熱身,把作業可能需要的任務,盡量先快取一些。當然不一定要快取完,因為Alluxio 是有多少數據,就使用多少數據。剩下的,如果還來不及緩存,就從遠端讀取。另外,Alluxio master 得到這樣的指令之後,就可以讓調度它的 worker 去遠端。可能是雲端存儲,也可能是 Hadoop 叢集把資料下載下來。這時候,K8s 也會把作業調度到 GPU 叢集。例如上圖中,在這樣一個叢集中,它選擇第一個節點和第三個節點啟動訓練任務。啟動訓練任務之後,需要進行資料的讀取。在現在主流的像 PyTorch、Tensorflow 等框架中,也內建了 Prefetch,也就是會進行資料預讀取。它會讀取已經提前快取的 Alluxio 中的快取數據,為訓練數據 IO 提供支援。當然,如果發現有些資料是沒有讀到的,Alluxio 也可以透過遠端讀取。 Alluxio 作為一個統一的介面是非常好的。同時它也可以進行資料的跨作業間的共用。
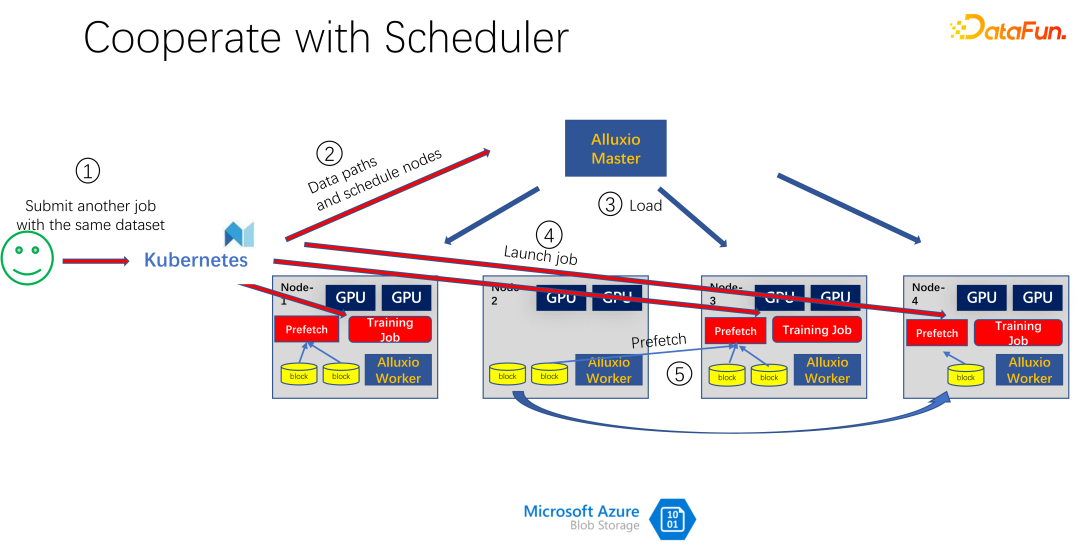
如上圖所示,例如又有一個人提交了同樣資料的另一個作業,消耗的是同一個資料集,這時候,提交作業到K8s 的時候,Alluxio 就知道已經有這部分資料了。如果 Alluxio 想做的更好,甚至是可以知道,資料即將會調度到哪台機器上。例如這個時候調度到 node 1、node 3 和 node 4 上。 node 4 的數據,甚至可以做一些副本進行拷貝。這樣所有的數據,即使是 Alluxio 內部,都不用跨機器讀,都是本地的讀取。所以看起來 Alluxio 對 AI 訓練的 IO 問題有了很大的緩解和優化。但是如果仔細觀察,就會發現兩個問題。

第一個問題就是快取的淘汰演算法非常低效,因為在 AI 場景中,存取資料的模式跟以往有很大區別。第二個問題是,快取作為一種資源,與頻寬(即遠端儲存的讀取速度)是一個對立的關係。如果快取大,那麼從遠端讀取資料的機會就小。如果快取很小,則很多資料都得從遠端讀取。如何很好地調度分配這些資源也是一個需要考慮的問題。
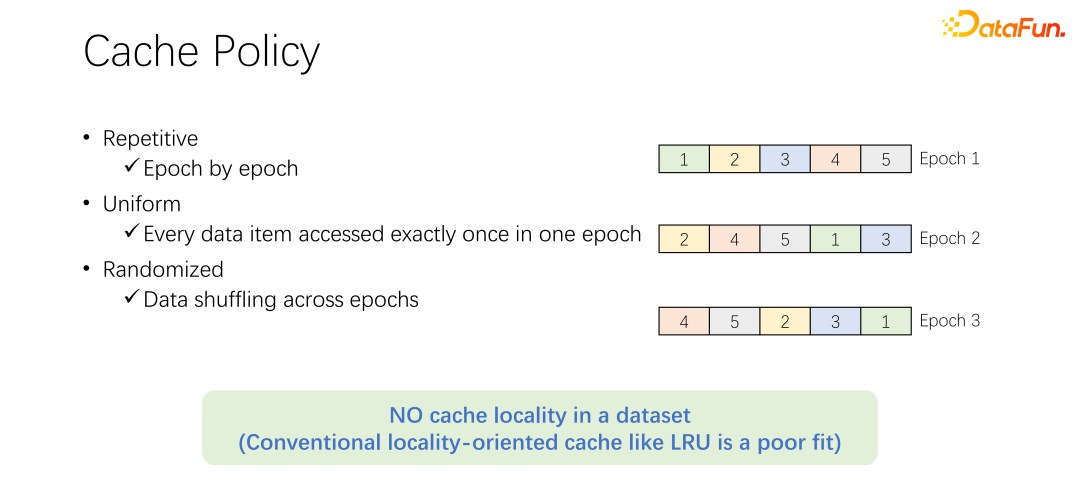
在討論快取的淘汰演算法之前,先來看看 AI 訓練中資料存取的過程。在 AI 訓練中,會分成很多 epoch,不斷迭代地去訓練。每一個訓練 epoch,都會讀取每一個數據,並且只讀一次。為了防止訓練的過擬合,在每一次 epoch 結束之後,下一個 epoch 的時候,讀取順序會變化,會進行一個 shuffle。也就是每次每個 epoch 都會把所有資料都讀一次,但順序卻不一樣。
Alluxio 中預設的 LRU 淘汰演算法,顯然不能很好地應用到AI訓練場景中。因為 LRU 是利用快取的本地性。本地性分為兩方面,首先是時間本地性,也就是現在存取的數據,馬上可能還會即將存取。這一點,在 AI 訓練中並不存在。因為現在訪問的數據,在下一輪的時候才會訪問,而且下一輪的時候都會訪問。沒有一個特殊的機率,一定是比其他資料更容易被存取。另一方面是資料本地性,還有空間本地性。也就是,為什麼 Alluxio 用比較大的 block 快取數據,是因為某條數據讀取了,可能周圍的數據也會被讀取。例如大數據場景中,OLAP 的應用,經常會進行表格的掃描,這意味著周圍的資料馬上也會被存取。但在 AI 訓練場景中是不能被應用的。因為每次都會 shuffle,每次讀取的順序都是不一樣的。因此 LRU 這種淘汰演算法並不適用於 AI 訓練場景。

#不只是LRU,像LFU 等主流的淘汰演算法,都存在這樣一個問題。因為整個 AI 訓練對資料的存取是非常均等的。所以,可以採用最簡單的快取演算法,只要快取一部分資料就可以,永遠不用動。在一個作業來了以後,永遠只快取一部分資料。永遠不要淘汰它。不需要任何的淘汰演算法。這可能是目前最好的淘汰機制。
如上圖的範例。上面是 LRU 演算法,下面是均等方法。在開始只能快取兩條資料。我們把問題簡單一些,它的容量只有兩條,快取 D 和 B 這兩條數據,中間就是存取的序列。例如命中第一個訪問的是 B,如果是 LRU,B 存在的快取中就命中了。下一條訪問的是 C,C 並不在 D 和 B,LRU 的快取中,所以基於 LRU 策略,會把 D 替換掉,C 保留下來。也就是這個時候快取是 C 和 B。下一個訪問的是 A,A 也不在 C 和 B 中。所以會把B 淘汰掉,換成 C 和 A。下一個是 D,D 也不在快取中,所以換成 D 和 A。以此類推,會發現所有後面的訪問,都不會再命中快取。原因是在進行 LRU 快取的時候,把它替換出來,但其實在一個 epoch 中已經被訪問一次,這個 epoch 中就永遠不會再被訪問到了。 LRU 倒把它進行緩存了,LRU 不但沒有幫助,反倒是變得更糟了。不如使用 uniform,例如下面這種方式。
下面這種 uniform 的方式,永遠在快取中快取 D 和 B,永遠不做任何的替換。在這樣情況下,你會發現至少有 50% 的命中率。所以可以看到,快取的演算法不用搞得很複雜,只要使用 uniform 就可以了,不要用 LRU、LFU 這類演算法。
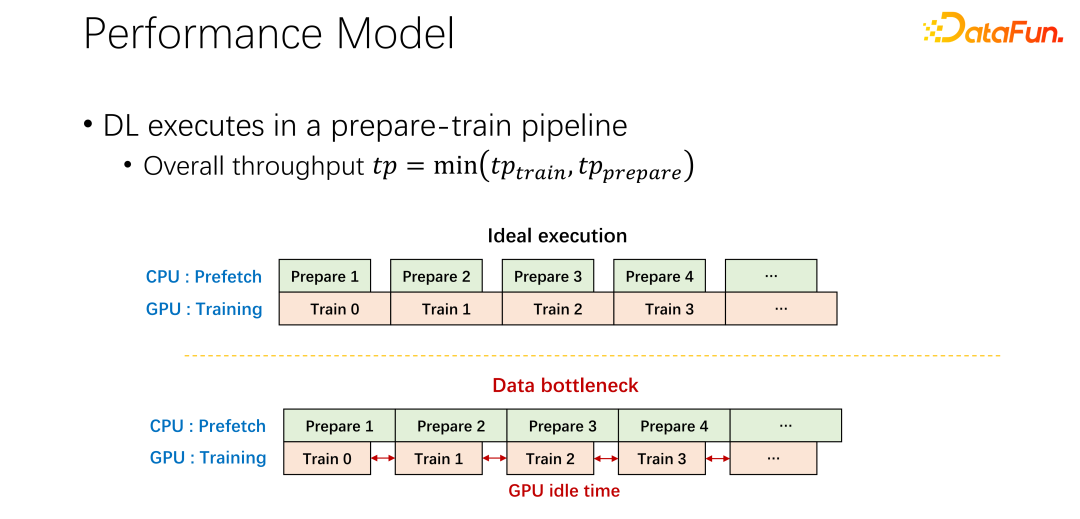
對於第二個問題,也就是關於快取和遠端頻寬之間關係的問題。現在所有主流的 AI 框架中都內建了資料預讀,防止 GPU 等待資料。所以當 GPU 做訓練的時候,其實是觸發了 CPU 預先取下一輪可能用到的資料。這樣可以充分利用 GPU 的算力。但當遠端儲存的 IO 成為瓶頸的時候,就意味著 GPU 要等待 CPU 了。所以 GPU 會有很多的空閒時間,造成了資源的浪費。希望可以有比較好的調度管理方式,緩解 IO 的問題。

快取和遠端 IO 對整個作業的吞吐是有很大的影響。所以除了 GPU、CPU 和內存,快取和網路也是需要調度的。在以往大數據的發展過程中,像是 Hadoop、yarn、my source、K8s 等,主要都是調度 CPU、記憶體、GPU。對於網絡,尤其對於快取的控制都不是很好。所以,我們認為,在 AI 場景中,需要很好的調度和分配它們,來達到整個叢集的最優。

#在EuroSys 2023 發表了這樣一篇文章,它是一個統一的框架,來調度運算資源和儲存資源。
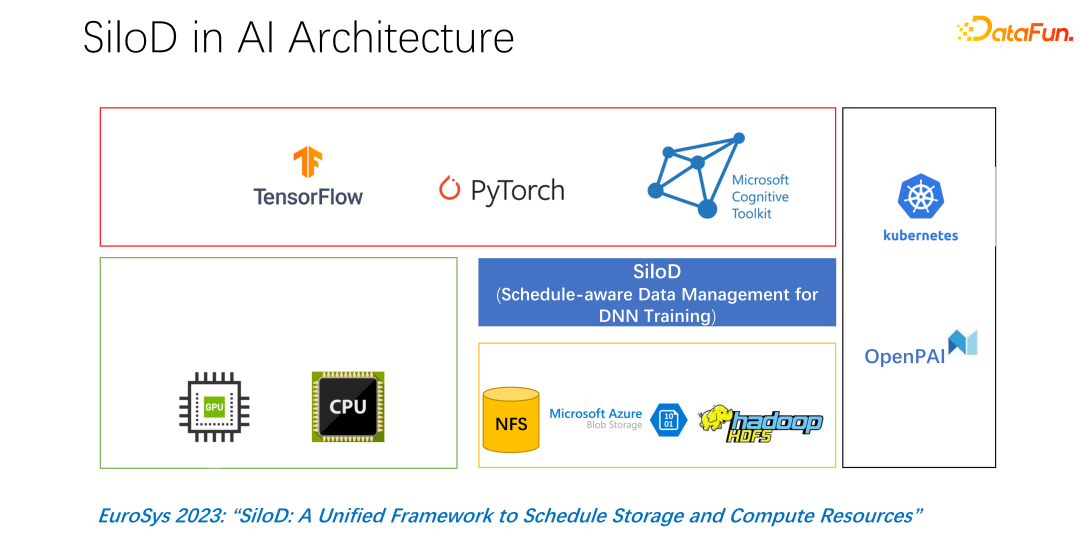
整體架構如上圖所示。左下角是叢集中的 CPU 和 GPU 硬體運算資源,以及儲存資源,如 NFS、雲端儲存 HDFS 等。在上層有一些 AI 的訓練框架 TensorFlow、PyTorch 等。我們認為需要加入一個統一管理和分配運算和儲存資源的插件,也就是我們提出的 SiloD。
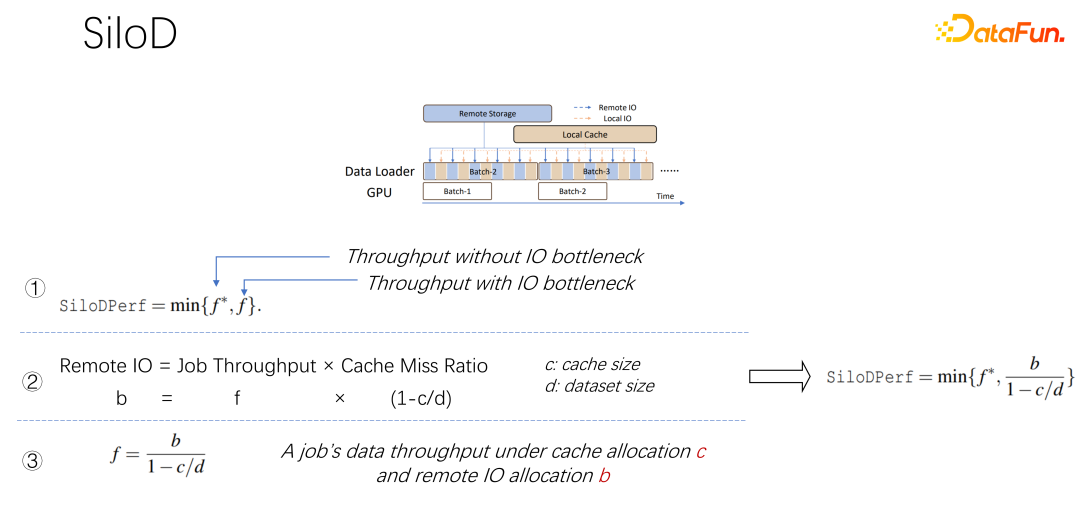
如上圖所示,一個作業可以達到什麼樣的吞吐和效能,是由GPU 和IO 的最小值決定的。使用多少個遠端 IO,就會使用多少遠端的 networking。可以透過這樣一個公式算出訪問速度。作業速度乘以快取未命中率,也就是(1-c/d)。其中 c 是快取的大小,d 就是資料集。這也意味著資料只考慮 IO 可能成為瓶頸的時候,大概的吞吐量是等於(b/(1-c/d)),b 就是遠端的頻寬。結合以上三個公式,可以推出右邊的公式,也就是一個作業最終想達到什麼樣的效能,可以這樣透過公式去計算沒有IO 瓶頸時的效能,和有IO 瓶頸時的效能,取二者中的最小值。
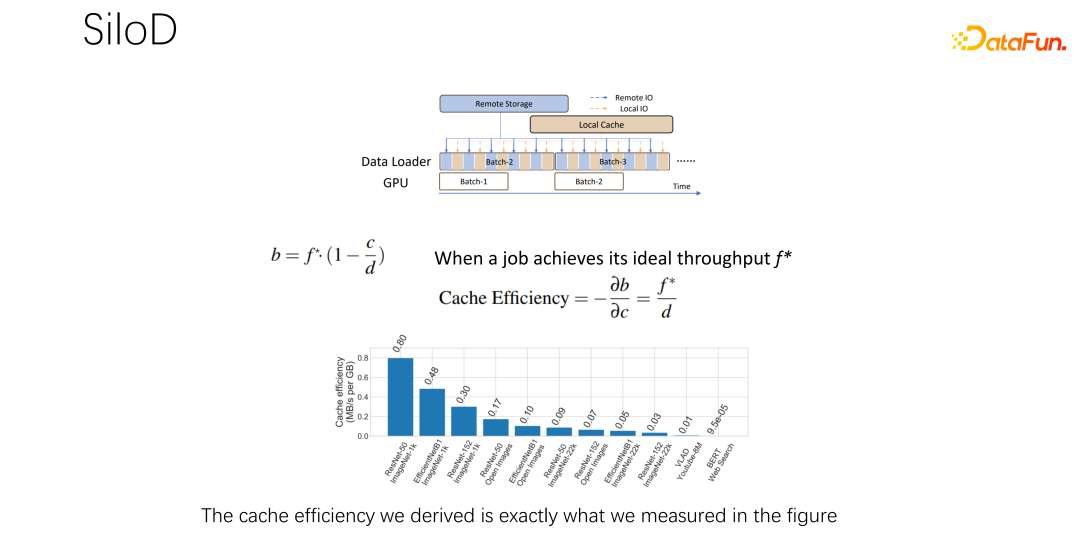
#得到上面的公式之後,把它微分一下,就可以得到快取的有效性,或者叫做快取效率。即雖然作業很多,但在分配快取的時候不能一視同仁。每一個作業,基於資料集的不同,速度的不同,快取分配多少是很有講究的。這裡舉一個例子,就以這個公式為例,如果發現一個作業,速度非常快,訓練起來非常快,同時資料集很小,這時候就意味著分配更大的緩存,收益會更大。
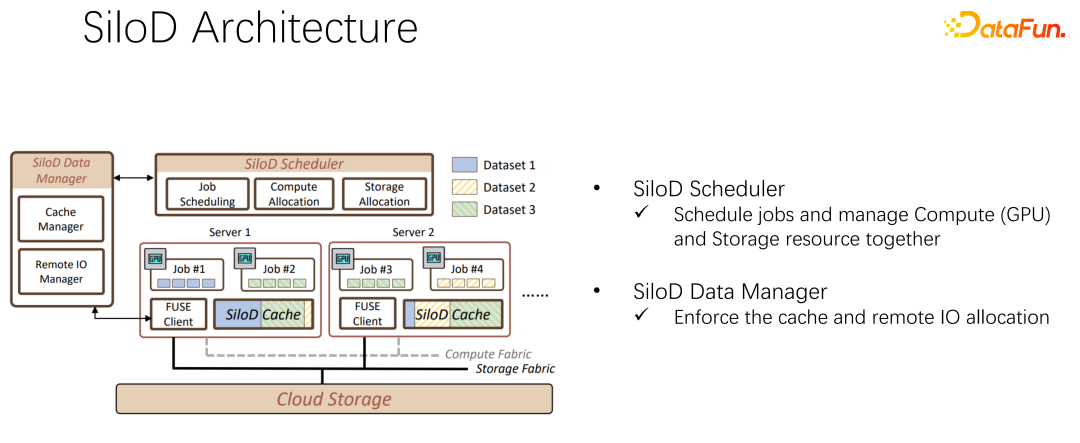
基於上述觀察,可以使用 SiloD,進行快取和網路的分配。而且快取的大小,是針對每個作業的速度,以及資料集整個的大小來進行分配的。網路也是如此。所以整個架構是這樣的:除了主流的像 K8s 等作業調度之外,還有資料管理。在圖左邊,例如快取的管理,要統計或監控分配整個叢集中快取的大小,每個作業快取的大小,以及每個作業使用到的遠端 IO 的大小。底下的作業,和 Alluxio 方式很像,都可以都使用 API 進行資料的訓練。每個 worker 上使用快取對於本機的 job 進行快取支援。當然它也可以在一個叢集中跨節點,也可以進行共享。
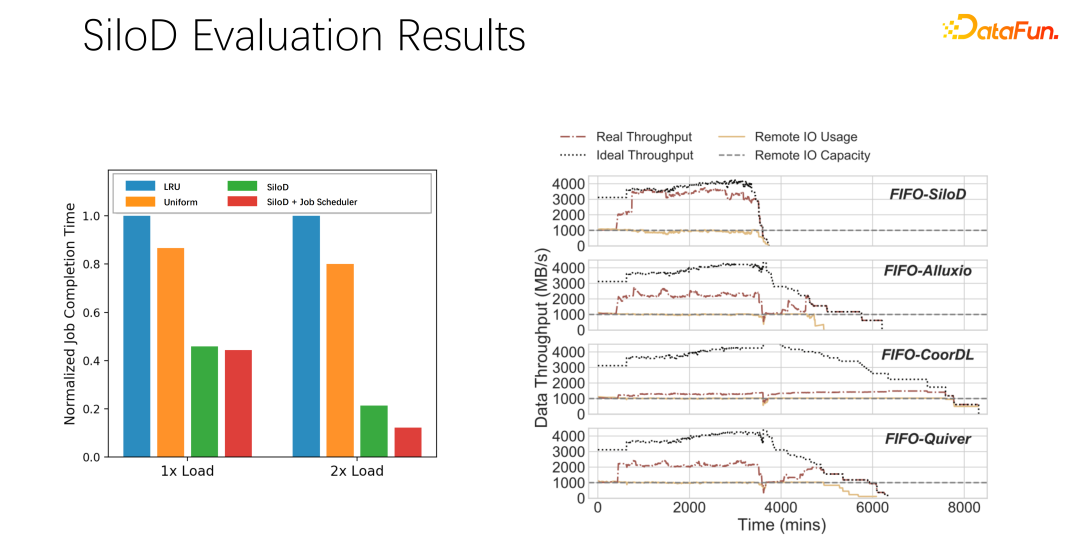
經過初步測試和實驗,發現這樣一個分配方式可以讓整個叢集的使用率和吞吐量都得到非常明顯的提升,最高可以達到8 倍的性能上的提升。可以很明顯的緩解作業等待、GPU 空閒的狀態。

#對上述介紹進行總結:
第一,在AI 或深度學習訓練場景中,傳統的LRU、LFU 等快取策略並不適合,不如直接使用uniform。
第二,#快取和遠端頻寬,是一對夥伴,對整體效能起到了非常大的作用。
第三,#像是 K8s、yarn 等主流調度框架,可以輕易繼承到 SiloD。
最後,我們在paper 中做了一些實驗,不同的調度策略,都可以帶來很明顯的吞吐量的提升。
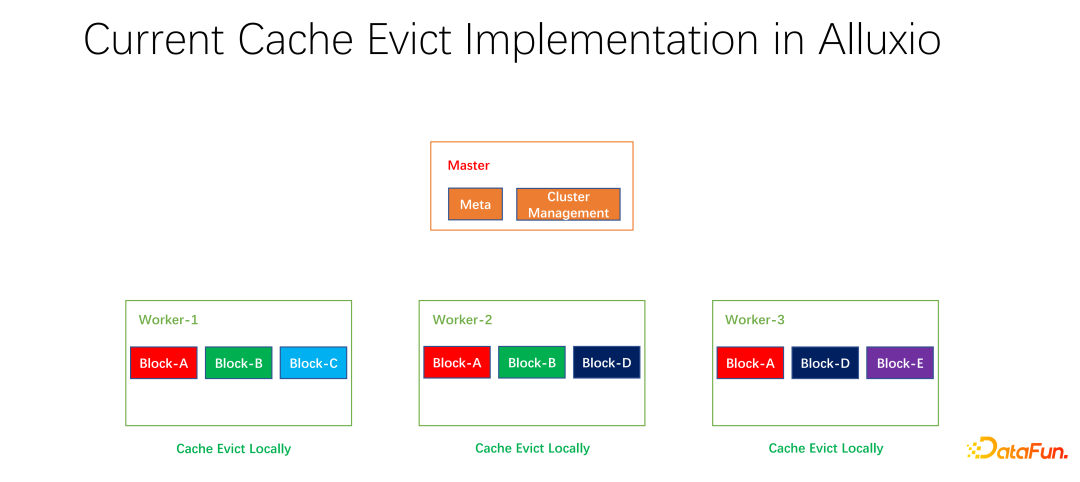
我們也做了一些開源的工作。分散式快取策略以及副本管理這項工作,已經提交給社區,現在處於 PR 階段。 Alluxio master 主要做 Meta 的管理和整個 worker 叢集的管理。真正快取資料的是 worker。上面有很多以 block 為單位的區塊兒去快取資料。存在的一個問題是,現階段的快取策略都是單一 worker 的,worker 內部的每個資料在進行是否淘汰的計算時,只需要在一個 worker 上進行計算,是本地化的。
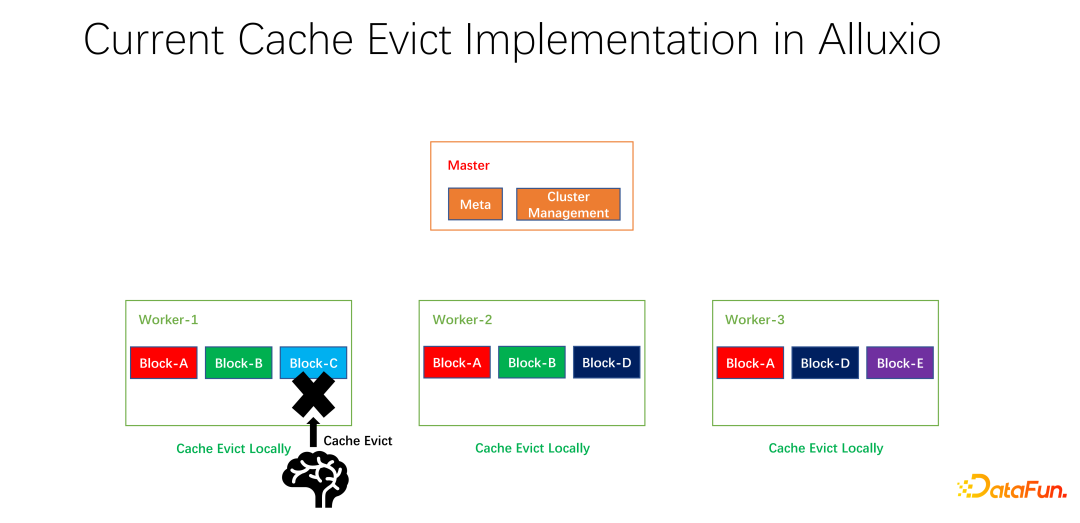
#如上圖所示的例子,如果worker 1 上有block A, block B和block C,基於LRU 算出來block C 是最長沒有使用的,就會把block C淘汰。如果看一下全局的情況,就會發現這樣並不好。因為 block C 在整個叢集中只有一個副本。把它淘汰之後,如果下面還有人要存取 block C,只能從遠端拉取數據,就會帶來效能和成本的損失。我們提出做一個全域的淘汰策略。在這種情況下,不應該淘汰 block C,而應該淘汰副本比較多的。在這個例子中,應該淘汰 block A,因為它在其它的節點上仍然有兩個副本,無論是成本還是效能都要更好。
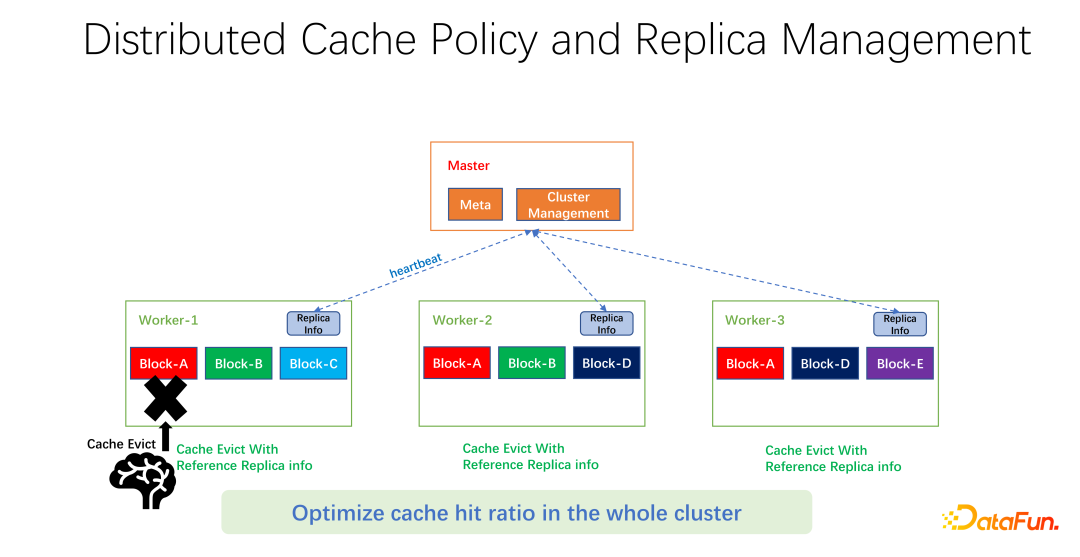
如上圖所示,我們所做的工作是在每個 worker 上維護副本資訊。當某一個 worker,例如加了一個副本,或是減了一個副本,首先會向 master 匯報,而 master 會把這個資訊作為心跳返回值,返回給其它相關的 worker。其它 worker 就可以知道整個全域副本的即時變化。同時,更新副本資訊。所以當進行 worker 內部的淘汰時,可以知道每一個 worker 在整個全域有多少個副本,就可以設計一些權重。例如仍然使用 LRU,但會加上副本個數的權重,綜合考量淘汰和替換哪些資料。
經過我們初步的測試,在許多領域,無論是 big data,AI training 中都可以帶來很大的提升。所以不僅僅是優化一台機器上一個 worker 的快取命中。我們的目標是使得整個叢集的快取命中率都得到提升。

#最後,先總結全文。首先,在 AI 的訓練場景中,uniform 快取淘汰演算法比傳統的 LRU、LFU 更好。第二,快取和遠端的 networking 也是一個需要被分配和調度的資源。第三,在進行快取最佳化時,不要只侷限在一個作業或一個 worker 上,應該統攬整個端對端全域的參數,才能使得整個叢集的效率和效能有更好的提升。
以上是面向大規模深度學習訓練的快取優化實踐的詳細內容。更多資訊請關注PHP中文網其他相關文章!






















