

Redis快取空間怎麼優化

場景設定
1、我們需要將POJO儲存到快取中,該類別定義如下
public class TestPOJO implements Serializable {
private String testStatus;
private String userPin;
private String investor;
private Date testQueryTime;
private Date createTime;
private String bizInfo;
private Date otherTime;
private BigDecimal userAmount;
private BigDecimal userRate;
private BigDecimal applyAmount;
private String type;
private String checkTime;
private String preTestStatus;
public Object[] toValueArray(){
Object[] array = {testStatus, userPin, investor, testQueryTime,
createTime, bizInfo, otherTime, userAmount,
userRate, applyAmount, type, checkTime, preTestStatus};
return array;
}
public CreditRecord fromValueArray(Object[] valueArray){
//具体的数据类型会丢失,需要做处理
}
}2、用下面的實例作為測試資料
TestPOJO pojo = new TestPOJO();
pojo.setApplyAmount(new BigDecimal("200.11"));
pojo.setBizInfo("XX");
pojo.setUserAmount(new BigDecimal("1000.00"));
pojo.setTestStatus("SUCCESS");
pojo.setCheckTime("2023-02-02");
pojo.setInvestor("ABCD");
pojo.setUserRate(new BigDecimal("0.002"));
pojo.setTestQueryTime(new Date());
pojo.setOtherTime(new Date());
pojo.setPreTestStatus("PROCESSING");
pojo.setUserPin("ABCDEFGHIJ");
pojo.setType("Y");常規做法
System.out.println(JSON.toJSONString(pojo).length());
使用JSON直接序列化、列印length=284**,**這種方式是最簡單的方式,也是最常用的方式,具體數據如下:
{"applyAmount":200.11,"bizInfo":"XX","checkTime":"2023-02-02","investor":"ABCD ","otherTime":"2023-04-10 17:45:17.717","preCheckStatus":"PROCESSING","testQueryTime":"2023-04-10 17:45:17.717","testStatus":"SUCCESS ","type":"Y","userAmount":1000.00,"userPin":"ABCDEFGHIJ","userRate":0.002}
我們發現,以上包含了大量無用的數據,其中屬性名是沒有必要儲存的。
改進1-去掉屬性名
System.out.println(JSON.toJSONString(pojo.toValueArray()).length());
透過選擇陣列結構取代物件結構,去掉了屬性名,列印length=144,將資料大小降低了50%,具體數據如下:
["SUCCESS","ABCDEFGHIJ","ABCD","2023-04-10 17:45:17.717",null,"XX"," 2023-04-10 17:45:17.717",1000.00,0.002,200.11,"Y","2023-02-02","PROCESSING"]
#我們發現,null是沒有必要儲存的,時間的格式被序列化為字串,不合理的序列化結果,導致了資料的膨脹,所以我們應該選用更好的序列化工具。
改進2-使用更好的序列化工具
//我们仍然选取JSON格式,但使用了第三方序列化工具 System.out.println(new ObjectMapper(new MessagePackFactory()).writeValueAsBytes(pojo.toValueArray()).length);
選取更好的序列化工具,實現欄位的壓縮和合理的資料格式,列印** length=92,**空間比上一步又降低了40%。
這是一份二進位數據,需要以二進位操作Redis,將二進位轉為字串後,列印如下:
��SUCCESS�ABCDEFGHIJ�ABCD� �j�6� ��XX� �j�6�� ��?`bM����@i � �Q�Y�2023-02-02�PROCESSING
##順著這個思路再深挖,我們發現,可以透過手動選擇資料類型,實現更極致的最佳化效果,選擇使用較小的資料類型,會獲得進一步的提升。改進3-最佳化資料類型
在上述用例中,testStatus、preCheckStatus、investor這3個字段,實際上是枚舉字串類型,如果能夠使用更簡單資料類型(例如byte或int等)取代string,還可以進一步節省空間。可以使用Long型別來取代字串來表示checkTime,這樣序列化工具輸出的位元組數會更少。public Object[] toValueArray(){
Object[] array = {toInt(testStatus), userPin, toInt(investor), testQueryTime,
createTime, bizInfo, otherTime, userAmount,
userRate, applyAmount, type, toLong(checkTime), toInt(preTestStatus)};
return array;
}length=69
改進4-考慮ZIP壓縮
除了以上的幾點之外,還可以考慮使用ZIP壓縮方式獲取更小的體積,在內容較大或重複性較多的情況下,ZIP壓縮的效果明顯,如果存儲的內容是TestPOJO的數組,可能適合使用ZIP壓縮。 對於小於30個位元組的文件,ZIP壓縮可能增加檔案大小,不一定能減少檔案體積。在重複性內容較少的情況下,無法獲得明顯提升。且存在CPU開銷。 在經過以上最佳化之後,ZIP壓縮不再是必選項,需要依照實際資料做測試才能分辨到ZIP的壓縮效果。最終落地
上面的幾個改進步驟體現了優化的思路,但是反序列化的過程會導致類型的丟失,處理起來比較繁瑣,所以我們還需要考慮反序列化的問題。 在快取物件被預先定義的情況下,我們完全可以手動處理每個字段,所以在實戰中,推薦使用手動序列化達到上述目的,實現精細化的控制,達到最好的壓縮效果和最小的性能開銷。 可以參考以下msgpack的實作程式碼,以下為測試程式碼,請自行封裝更好的Packer和UnPacker等工具:<dependency>
<groupId>org.msgpack</groupId>
<artifactId>msgpack-core</artifactId>
<version>0.9.3</version>
</dependency> public byte[] toByteArray() throws Exception {
MessageBufferPacker packer = MessagePack.newDefaultBufferPacker();
toByteArray(packer);
packer.close();
return packer.toByteArray();
}
public void toByteArray(MessageBufferPacker packer) throws Exception {
if (testStatus == null) {
packer.packNil();
}else{
packer.packString(testStatus);
}
if (userPin == null) {
packer.packNil();
}else{
packer.packString(userPin);
}
if (investor == null) {
packer.packNil();
}else{
packer.packString(investor);
}
if (testQueryTime == null) {
packer.packNil();
}else{
packer.packLong(testQueryTime.getTime());
}
if (createTime == null) {
packer.packNil();
}else{
packer.packLong(createTime.getTime());
}
if (bizInfo == null) {
packer.packNil();
}else{
packer.packString(bizInfo);
}
if (otherTime == null) {
packer.packNil();
}else{
packer.packLong(otherTime.getTime());
}
if (userAmount == null) {
packer.packNil();
}else{
packer.packString(userAmount.toString());
}
if (userRate == null) {
packer.packNil();
}else{
packer.packString(userRate.toString());
}
if (applyAmount == null) {
packer.packNil();
}else{
packer.packString(applyAmount.toString());
}
if (type == null) {
packer.packNil();
}else{
packer.packString(type);
}
if (checkTime == null) {
packer.packNil();
}else{
packer.packString(checkTime);
}
if (preTestStatus == null) {
packer.packNil();
}else{
packer.packString(preTestStatus);
}
}
public void fromByteArray(byte[] byteArray) throws Exception {
MessageUnpacker unpacker = MessagePack.newDefaultUnpacker(byteArray);
fromByteArray(unpacker);
unpacker.close();
}
public void fromByteArray(MessageUnpacker unpacker) throws Exception {
if (!unpacker.tryUnpackNil()){
this.setTestStatus(unpacker.unpackString());
}
if (!unpacker.tryUnpackNil()){
this.setUserPin(unpacker.unpackString());
}
if (!unpacker.tryUnpackNil()){
this.setInvestor(unpacker.unpackString());
}
if (!unpacker.tryUnpackNil()){
this.setTestQueryTime(new Date(unpacker.unpackLong()));
}
if (!unpacker.tryUnpackNil()){
this.setCreateTime(new Date(unpacker.unpackLong()));
}
if (!unpacker.tryUnpackNil()){
this.setBizInfo(unpacker.unpackString());
}
if (!unpacker.tryUnpackNil()){
this.setOtherTime(new Date(unpacker.unpackLong()));
}
if (!unpacker.tryUnpackNil()){
this.setUserAmount(new BigDecimal(unpacker.unpackString()));
}
if (!unpacker.tryUnpackNil()){
this.setUserRate(new BigDecimal(unpacker.unpackString()));
}
if (!unpacker.tryUnpackNil()){
this.setApplyAmount(new BigDecimal(unpacker.unpackString()));
}
if (!unpacker.tryUnpackNil()){
this.setType(unpacker.unpackString());
}
if (!unpacker.tryUnpackNil()){
this.setCheckTime(unpacker.unpackString());
}
if (!unpacker.tryUnpackNil()){
this.setPreTestStatus(unpacker.unpackString());
}
}場景延伸
#假設,我們為2億用戶儲存數據,每個用戶包含40個字段,字段key的長度是6個字節,字段是分別管理的。 正常情況下,我們會想到hash結構,而hash結構儲存了key的信息,會佔用額外資源,字段key屬於不必要數據,按照上述思路,可以使用list替代hash結構。 透過Redis官方工具測試,使用list結構需要144G的空間,而使用hash結構需要245G的空間**(當50%以上的屬性為空時,需要進行測試,是否仍然適用)* *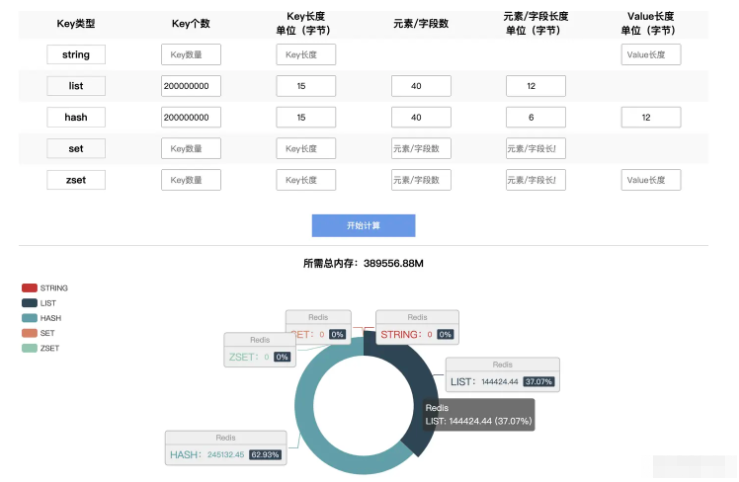
• 使用陣列替代物件(如果大量欄位為空,需配合序列化工具對null進行壓縮)
• 使用更好的序列化工具
• 使用更小的資料類型
• 考慮使用ZIP壓縮
• 使用list取代hash結構(如果大量欄位為空,需要進行測試對比)
以上是Redis快取空間怎麼優化的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 redis集群模式怎麼搭建
Apr 10, 2025 pm 10:15 PM
redis集群模式怎麼搭建
Apr 10, 2025 pm 10:15 PM
Redis集群模式通過分片將Redis實例部署到多個服務器,提高可擴展性和可用性。搭建步驟如下:創建奇數個Redis實例,端口不同;創建3個sentinel實例,監控Redis實例並進行故障轉移;配置sentinel配置文件,添加監控Redis實例信息和故障轉移設置;配置Redis實例配置文件,啟用集群模式並指定集群信息文件路徑;創建nodes.conf文件,包含各Redis實例的信息;啟動集群,執行create命令創建集群並指定副本數量;登錄集群執行CLUSTER INFO命令驗證集群狀態;使
 redis數據怎麼清空
Apr 10, 2025 pm 10:06 PM
redis數據怎麼清空
Apr 10, 2025 pm 10:06 PM
如何清空 Redis 數據:使用 FLUSHALL 命令清除所有鍵值。使用 FLUSHDB 命令清除當前選定數據庫的鍵值。使用 SELECT 切換數據庫,再使用 FLUSHDB 清除多個數據庫。使用 DEL 命令刪除特定鍵。使用 redis-cli 工具清空數據。
 redis怎麼讀取隊列
Apr 10, 2025 pm 10:12 PM
redis怎麼讀取隊列
Apr 10, 2025 pm 10:12 PM
要從 Redis 讀取隊列,需要獲取隊列名稱、使用 LPOP 命令讀取元素,並處理空隊列。具體步驟如下:獲取隊列名稱:以 "queue:" 前綴命名,如 "queue:my-queue"。使用 LPOP 命令:從隊列頭部彈出元素並返回其值,如 LPOP queue:my-queue。處理空隊列:如果隊列為空,LPOP 返回 nil,可先檢查隊列是否存在再讀取元素。
 centos redis如何配置Lua腳本執行時間
Apr 14, 2025 pm 02:12 PM
centos redis如何配置Lua腳本執行時間
Apr 14, 2025 pm 02:12 PM
在CentOS系統上,您可以通過修改Redis配置文件或使用Redis命令來限制Lua腳本的執行時間,從而防止惡意腳本佔用過多資源。方法一:修改Redis配置文件定位Redis配置文件:Redis配置文件通常位於/etc/redis/redis.conf。編輯配置文件:使用文本編輯器(例如vi或nano)打開配置文件:sudovi/etc/redis/redis.conf設置Lua腳本執行時間限制:在配置文件中添加或修改以下行,設置Lua腳本的最大執行時間(單位:毫秒)
 redis命令行怎麼用
Apr 10, 2025 pm 10:18 PM
redis命令行怎麼用
Apr 10, 2025 pm 10:18 PM
使用 Redis 命令行工具 (redis-cli) 可通過以下步驟管理和操作 Redis:連接到服務器,指定地址和端口。使用命令名稱和參數向服務器發送命令。使用 HELP 命令查看特定命令的幫助信息。使用 QUIT 命令退出命令行工具。
 redis計數器怎麼實現
Apr 10, 2025 pm 10:21 PM
redis計數器怎麼實現
Apr 10, 2025 pm 10:21 PM
Redis計數器是一種使用Redis鍵值對存儲來實現計數操作的機制,包含以下步驟:創建計數器鍵、增加計數、減少計數、重置計數和獲取計數。 Redis計數器的優勢包括速度快、高並發、持久性和簡單易用。它可用於用戶訪問計數、實時指標跟踪、遊戲分數和排名以及訂單處理計數等場景。
 redis過期策略怎麼設置
Apr 10, 2025 pm 10:03 PM
redis過期策略怎麼設置
Apr 10, 2025 pm 10:03 PM
Redis數據過期策略有兩種:定期刪除:定期掃描刪除過期鍵,可通過 expired-time-cap-remove-count、expired-time-cap-remove-delay 參數設置。惰性刪除:僅在讀取或寫入鍵時檢查刪除過期鍵,可通過 lazyfree-lazy-eviction、lazyfree-lazy-expire、lazyfree-lazy-user-del 參數設置。
 如何優化debian readdir的性能
Apr 13, 2025 am 08:48 AM
如何優化debian readdir的性能
Apr 13, 2025 am 08:48 AM
在Debian系統中,readdir系統調用用於讀取目錄內容。如果其性能表現不佳,可嘗試以下優化策略:精簡目錄文件數量:盡可能將大型目錄拆分成多個小型目錄,降低每次readdir調用處理的項目數量。啟用目錄內容緩存:構建緩存機制,定期或在目錄內容變更時更新緩存,減少對readdir的頻繁調用。內存緩存(如Memcached或Redis)或本地緩存(如文件或數據庫)均可考慮。採用高效數據結構:如果自行實現目錄遍歷,選擇更高效的數據結構(例如哈希表而非線性搜索)存儲和訪問目錄信
