

多路徑多領域通吃! GoogleAI發布多領域學習通用模型MDL

面向視覺任務(如圖像分類)的深度學習模型,通常使用來自單一視覺域(如自然圖像或電腦生成的圖像)的資料進行端到端的訓練。
一般情況下,一個為多個領域完成視覺任務的應用程式需要為每個單獨的領域建立多個模型,分別獨立訓練,不同領域之間不共享數據,在推理時,每個模型將處理特定領域的輸入資料。
即使是針對不同領域,這些模型之間的早期層的某些特徵都是相似的,所以,對這些模型進行聯合訓練的效率更高。這能減少延遲和功耗,降低儲存每個模型參數的記憶體成本,這種方法稱為多領域學習(MDL)。
此外,MDL模型也可以優於單領域模型,在一個領域上的額外訓練,可以提高模型在另一個領域上的性能,稱為“正向知識遷移」,但也可能產生負向知識轉移,這取決於訓練方法和特定的領域組合。 雖然先前關於MDL的工作已經證明了跨領域聯合學習任務的有效性,但它涉及到一個手工製作的模型架構,應用於其他工作的效率很低。

#論文連結:https://arxiv.org/pdf/2010.04904.pdf
為了解決這個問題,在「Multi-path Neural Networks for On-device Multi-domain Visual Classification」一文中,Google研究人員提出了一個通用MDL模型。
文章表示,該模型既可以有效地實現高精確度,減少負向知識遷移的同時,學習增強正向的知識遷移,在處理各種特定領域的困難時,可以有效地優化聯合模型。
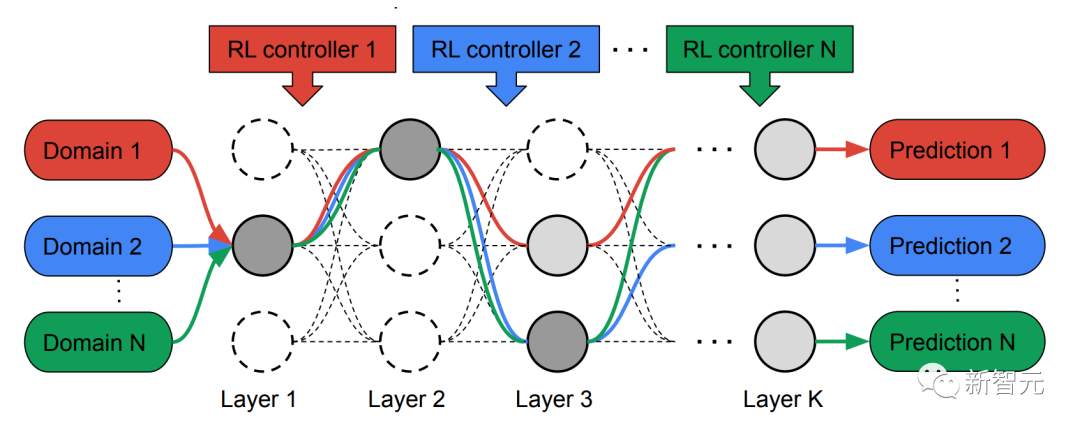
為此,研究人員提出了多路徑神經架構搜尋(MPNAS)方法,為多領域建立一個具有異質網路架構的統一模型。
此方法將高效率的神經結構搜尋(NAS)方法從單路徑搜尋擴展到多路徑搜索,為每個領域共同尋找一條最優路徑。同時引入一個新的損失函數,稱為自適應平衡域優先化(ABDP),它適應特定領域的困難,以幫助有效地訓練模型。由此產生的MPNAS方法是高效且可擴展的。
新模型在維持表現不下降的同時,與單一領域方法相比,模型大小和FLOPS分別減少了78%和32%。
多路徑神經結構搜尋
為了促進正向知識遷移,避免負向遷移,傳統的解決方案是,建立一個MDL模型,使各領域共享大部分的層,學習各域的共享特徵(稱為特徵提取),然後在上面建造一些特定域的層。 然而,這種特徵提取方法無法處理具有明顯不同特徵的領域(如自然圖像中的物件和藝術繪畫)。另一方面,為每個MDL模型建立統一的異質結構是很耗時的,而且需要特定領域的知識。
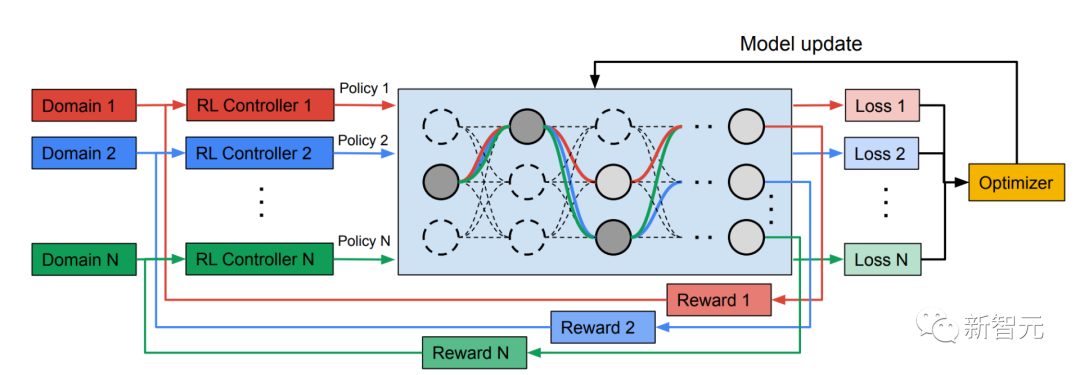
多路徑神經搜尋架構框架 NAS是一個自動設計深度學習架構的強大範式。它定義了一個搜尋空間,由可能成為最終模型一部分的各種潛在構建塊組成。
搜尋演算法從搜尋空間中找到最佳的候選架構,以最佳化模型目標,例如分類精確度。最近的NAS方法(如TuNAS)透過使用端到端的路徑採樣,提高了搜尋效率。
受TuNAS的啟發,MPNAS在兩個階段建立了MDL模型架構:搜尋與訓練。
#在搜尋階段,為了給每個領域共同找到一條最佳路徑,MPNAS為每個領域創建了一個單獨的強化學習(RL)控制器,它從超級網路(即由搜尋空間定義的候選節點之間所有可能的子網路的超集)中採樣端到端的路徑(從輸入層到輸出層)。
在多次迭代中,所有RL控制器更新路徑,以最佳化所有領域的RL獎勵。在搜尋階段結束時,我們為每個領域獲得一個子網路。 最後,所有的子網路被結合起來,為MDL模型建立一個異質結構,如下圖所示。
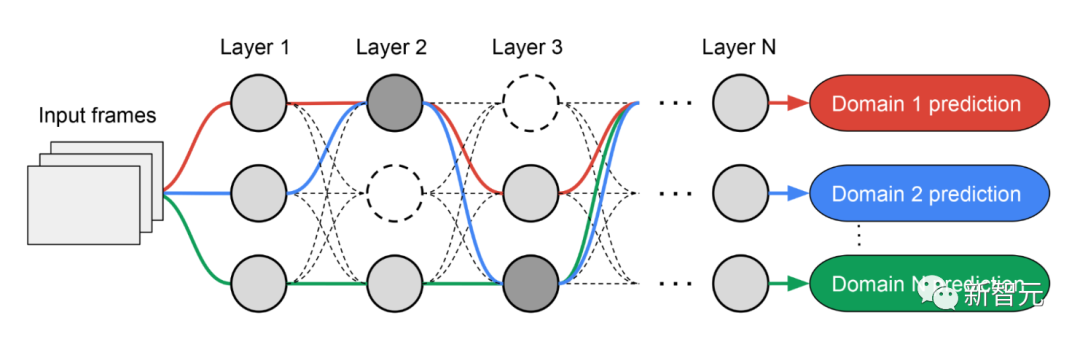
#由於每個領域的子網路是獨立搜尋的,所以每一層的構件可以被多個域共享(即深灰色節點),並被單一域使用(即淺灰色節點),或不被任何子網路使用(即點狀節點)。
每個網域的路徑在搜尋過程中也可以跳過任何一層。鑑於子網路可以以優化性能的方式自由選擇沿路使用的區塊,輸出網路既是異質的又是高效的。
下圖展示了Visual Domain Decathlon的其中兩個領域的搜尋架構。
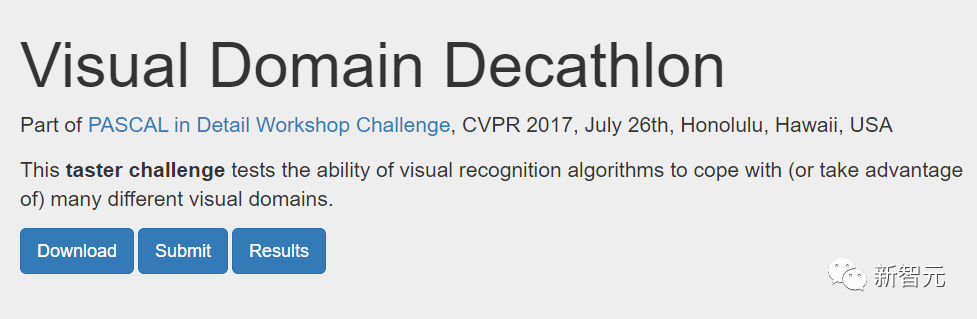
Visual Domain Decathlon是CVPR 2017中的PASCAL in Detail Workshop Challenge的一部分,測試了視覺識別演算法處理(或利用)許多不同視覺領域的能力。 可以看出,這兩個高度相關的域(一個紅色,另一個綠色)的子網,從它們的重疊路徑中共享了大部分構建塊,但它們之間仍然存在差異。
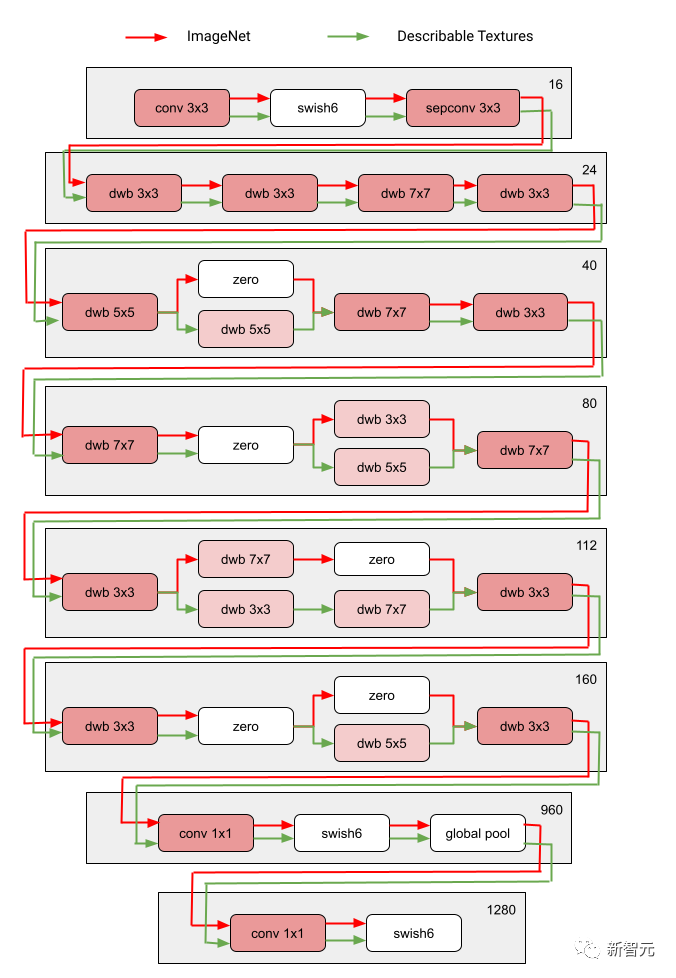
圖中紅色和綠色路徑分別代表ImageNet 和Describable Textures的子網絡,深粉紅色節點代表多個域共享的區塊,淺粉紅色節點代表每條路徑使用的區塊。圖中的“dwb”塊代表 dwbottleneck 塊。圖中的Zero區塊表示子網路跳過該區塊 下圖展示了上文提到的兩個領域的路徑相似性。 相似度透過每個領域的子網路之間的Jaccard相似度分數來衡量,其中越高意味著路徑越相似。

圖為十個領域的路徑之間的Jaccard相似度得分的混淆矩陣。分值範圍為0到1,分數越大表示兩條路徑共享的節點越多。
訓練異質多域模型
在第二階段,MPNAS 產生的模型將針對所有領域從頭開始訓練。 為此,有必要為所有領域定義一個統一的目標函數。 為了成功處理各種各樣的領域,研究人員設計了一種演算法,該演算法在整個學習過程中進行調整,以便在各個領域之間平衡損失,稱為自適應平衡領域優先級 (ABDP)。 下面展示了在不同設定下訓練的模型的準確率、模型大小和FLOPS。我們將MPNAS與其他三種方法進行比較:
獨立於領域的 NAS:分別為每個領域搜尋和訓練模型。
單路徑多頭:使用預訓練模型作為所有域的共享主幹,每個域都有單獨的分類頭。
多頭 NAS:為所有域搜尋統一的骨幹架構,每個域都有單獨的分類頭。
從結果中,我們可以觀察到NAS需要為每個領域建立一組模型,從而導致模型很大。 儘管單路徑多頭和多頭NAS可以顯著降低模型大小和FLOPS,但強制域共享相同的主幹會引入負面的知識轉移,從而降低整體準確性。

相較之下,MPNAS可建立小而有效率的模型,同時仍維持較高的整體精確度。 MPNAS的平均準確率甚至比領域獨立的NAS方法高1.9%,因為該模型能夠實現積極的知識轉移。 下圖比較了這些方法的每個域top-1準確度。
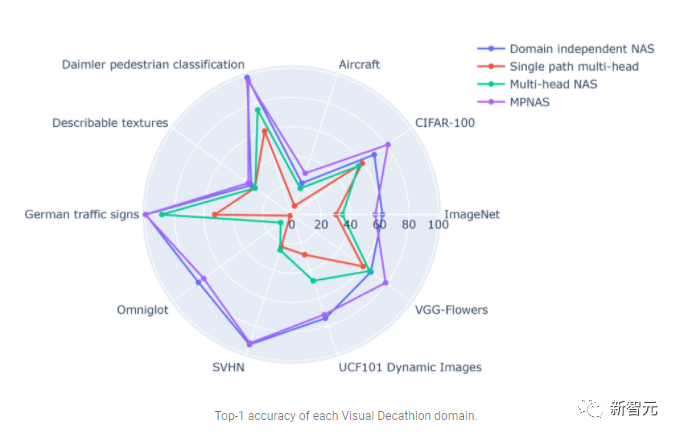
#評估表明,透過使用ABDP 作為搜尋和訓練階段的一部分,top-1的準確率從69.96% 提高到71.78%(增量: 1.81%)。
未來方向
MPNAS是建構異質網路以解決MDL中可能的參數共享策略的資料不平衡、域多樣性、負遷移、域可擴展性和大搜尋空間的有效解決方案。 透過使用類似MobileNet的搜尋空間,產生的模式也對行動裝置友善。 對於與現有搜尋演算法不相容的任務,研究人員正繼續擴展MPNAS用於多任務學習,並希望用MPNAS來建構統一的多域模型。
以上是多路徑多領域通吃! GoogleAI發布多領域學習通用模型MDL的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

AI Hentai Generator
免費產生 AI 無盡。

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)
熱門話題



 YOLO不死! YOLOv9出爐:性能速度SOTA~
Feb 26, 2024 am 11:31 AM
YOLO不死! YOLOv9出爐:性能速度SOTA~
Feb 26, 2024 am 11:31 AM
如今的深度學習方法專注於設計最適合的目標函數,以使模型的預測結果與實際情況最接近。同時,必須設計一個合適的架構,以便為預測取得足夠的資訊。現有方法忽略了一個事實,當輸入資料經過逐層特徵提取和空間變換時,大量資訊將會遺失。本文將深入探討資料透過深度網路傳輸時的重要問題,即資訊瓶頸和可逆函數。基於此提出了可編程梯度資訊(PGI)的概念,以應對深度網路實現多目標所需的各種變化。 PGI可以為目標任務提供完整的輸入訊息,以計算目標函數,從而獲得可靠的梯度資訊以更新網路權重。此外設計了一種新的輕量級網路架
 此「錯」並非真的錯:從四篇經典論文入手,理解Transformer架構圖「錯」在何處
Jun 14, 2023 pm 01:43 PM
此「錯」並非真的錯:從四篇經典論文入手,理解Transformer架構圖「錯」在何處
Jun 14, 2023 pm 01:43 PM
前段時間,一則指出Google大腦團隊論文《AttentionIsAllYouNeed》中Transformer架構圖與程式碼不一致的推文引發了大量的討論。對於Sebastian的這項發現,有人認為屬於無心之過,但同時也會令人感到奇怪。畢竟,考慮到Transformer論文的流行程度,這個不一致問題早就該被提及1000次。 SebastianRaschka在回答網友評論時說,「最最原始」的程式碼確實與架構圖一致,但2017年提交的程式碼版本進行了修改,但同時沒有更新架構圖。這也是造成「不一致」討論的根本原因。
 Spring Data JPA 的架構和工作原理是什麼?
Apr 17, 2024 pm 02:48 PM
Spring Data JPA 的架構和工作原理是什麼?
Apr 17, 2024 pm 02:48 PM
SpringDataJPA基於JPA架構,透過映射、ORM和事務管理與資料庫互動。其儲存庫提供CRUD操作,派生查詢簡化了資料庫存取。此外,它使用延遲加載,僅在必要時檢索數據,從而提高了效能。
 多路徑多領域通吃! GoogleAI發布多領域學習通用模型MDL
May 28, 2023 pm 02:12 PM
多路徑多領域通吃! GoogleAI發布多領域學習通用模型MDL
May 28, 2023 pm 02:12 PM
面向視覺任務(如影像分類)的深度學習模型,通常使用單一視覺域(如自然影像或電腦生成的影像)的資料進行端到端的訓練。一般情況下,一個為多個領域完成視覺任務的應用程式需要為每個單獨的領域建立多個模型,分別獨立訓練,不同領域之間不共享數據,在推理時,每個模型將處理特定領域的輸入資料。即使是面向不同領域,這些模型之間的早期層的有些特徵都是相似的,所以,對這些模型進行聯合訓練的效率更高。這能減少延遲和功耗,降低儲存每個模型參數的記憶體成本,這種方法稱為多領域學習(MDL)。此外,MDL模型也可以優於單
 1.3ms耗時!清華最新開源行動裝置神經網路架構 RepViT
Mar 11, 2024 pm 12:07 PM
1.3ms耗時!清華最新開源行動裝置神經網路架構 RepViT
Mar 11, 2024 pm 12:07 PM
论文地址:https://arxiv.org/abs/2307.09283代码地址:https://github.com/THU-MIG/RepViTRepViT在移动端ViT架构中表现出色,展现出显著的优势。接下来,我们将探讨本研究的贡献所在。文中提到,轻量级ViTs通常比轻量级CNNs在视觉任务上表现得更好,这主要归功于它们的多头自注意力模块(MSHA)可以让模型学习全局表示。然而,轻量级ViTs和轻量级CNNs之间的架构差异尚未得到充分研究。在这项研究中,作者们通过整合轻量级ViTs的有效
 golang框架架構的學習曲線有多陡峭?
Jun 05, 2024 pm 06:59 PM
golang框架架構的學習曲線有多陡峭?
Jun 05, 2024 pm 06:59 PM
Go框架架構的學習曲線取決於對Go語言和後端開發的熟悉程度以及所選框架的複雜性:對Go語言的基礎知識有較好的理解。具有後端開發經驗會有所幫助。複雜度不同的框架導致學習曲線差異。
 你知道程式設計師再過幾年會沒落?
Nov 08, 2023 am 11:17 AM
你知道程式設計師再過幾年會沒落?
Nov 08, 2023 am 11:17 AM
《ComputerWorld》雜誌曾經寫過一篇文章,說“編程到1960年就會消失”,因為IBM開發了一種新語言FORTRAN,這種新語言可以讓工程師寫出他們所需的數學公式,然後提交給電腦運行,所以程式設計就會終結。圖片又過了幾年,我們聽到了一種新說法:任何業務人員都可以使用業務術語來描述自己的問題,告訴電腦要做什麼,使用這種叫做COBOL的程式語言,公司不再需要程式設計師了。後來,據說IBM開發了一門名為RPG的新程式語言,可以讓員工填寫表格並產生報告,因此大部分企業的程式設計需求都可以透過它來完成圖
 探索使用對比損失的孿生網路進行影像相似性比較
Apr 02, 2024 am 11:37 AM
探索使用對比損失的孿生網路進行影像相似性比較
Apr 02, 2024 am 11:37 AM
簡介在電腦視覺領域,準確地測量影像相似性是一項關鍵任務,具有廣泛的實際應用。從圖像搜尋引擎到人臉辨識系統和基於內容的推薦系統,有效比較和尋找相似圖像的能力非常重要。 Siamese網路與對比損失相結合,為數據驅動方式學習影像相似性提供了強大的框架。在這篇文章中,我們將深入了解Siamese網路的細節,探討對比損失的概念,並探討這兩個組件如何共同運作以創建一個有效的圖像相似性模型。首先,Siamese網路由兩個相同的子網路組成,這兩個子網路共享相同的權重和參數。每個子網路將輸入圖像編碼為特徵向量,這
