

Redis集群主從模式怎麼配置


一、為什麼需要叢集?
在我們的實際開發當中,只使用一台Redis運用於工程專案中是不可以的,原因如下:
(1)在結構方面,單一Redis伺服器存在單點故障的風險,且一台伺服器需要承擔所有請求的負載,壓力相對較大
(2)從容量上,單一Redis伺服器記憶體容量有限,就算一台Redis伺服器記憶體容量為256G,也不能將所有記憶體用作Redis儲存內存,一般來說,單一Redis最大使用記憶體不應該超過20G。
(3)單一Redis伺服器的讀寫效能有限,利用叢集可以提升讀寫能力。
二、主從模式
介紹
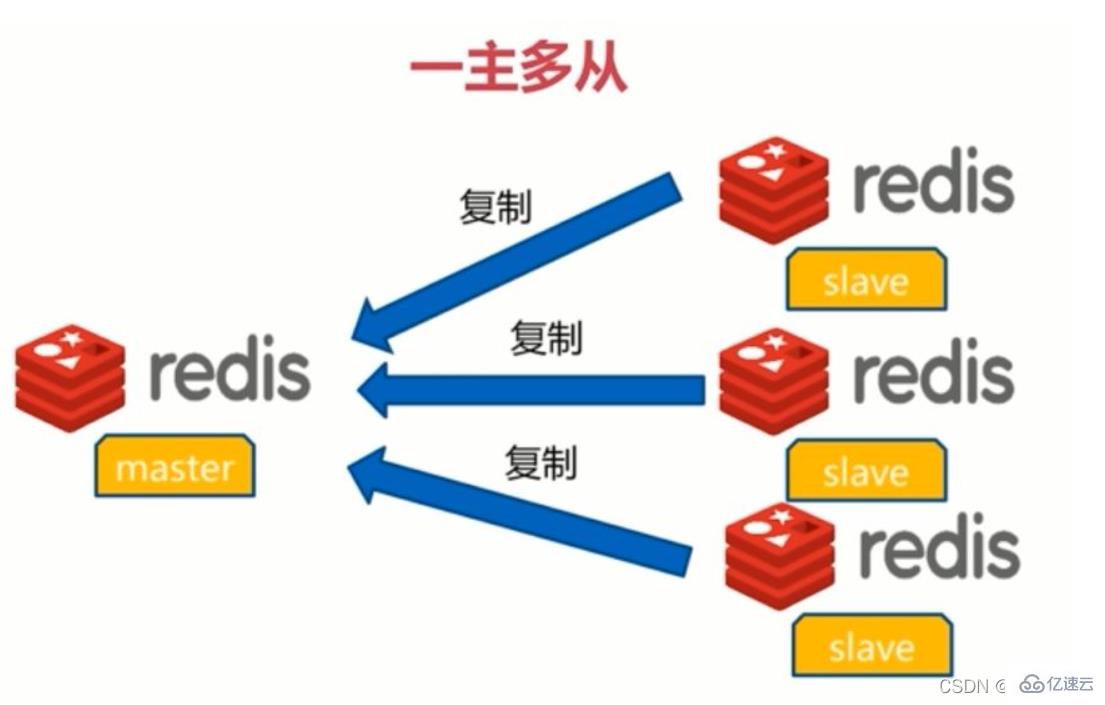
#目前,Redis有三種群集模式,分別是:主從模式,哨兵模式,Cluster模式;主從模式是三種模式中最簡單的,在主從複製中,是指將一台Redis伺服器的數據,複製到其他的Redis伺服器。第一個被稱為主節點(master/leader),而第二個被稱為從節點(slave/follower)。
注意:
#(1)資料的複製是單向的,只能由主節點到從節點。 Master以寫為主,Slave 以讀為主。
(2)預設情況下,每台Redis伺服器都是主節點;
(3)一個主節點可以有多個從節點(或沒有從節點),但一個從節點只能有一個主節點。
作用
1、資料冗餘:主從複製實現了資料的熱備份,是持久化以外的一種資料冗餘方式。
2、故障復原:當主節點出現問題時,可以由從節點提供服務,實現快速的故障復原;實際上是一種服務的冗餘。
3、高可用(叢集)基石:主從複製或哨兵和叢集能夠實施的基礎,因此說主從複製是Redis高可用的基礎。
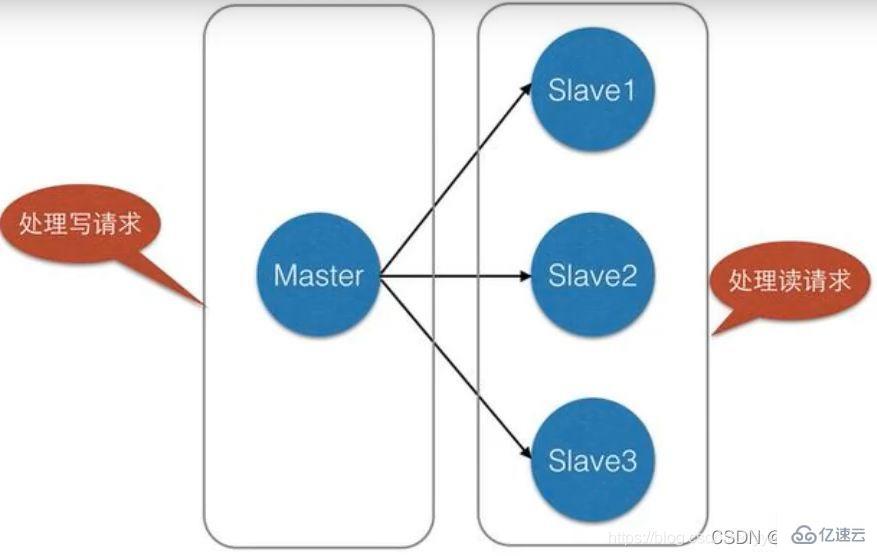
4、負載平衡:在主從複製的基礎上,配合讀寫分離,可以由主節點提供寫入服務,由從節點提供讀取服務(即寫Redis資料時應用連接主節點,讀Redis資料時應用連線從節點),分擔伺服器負載;尤其是在寫入少讀多的場景下,透過多個從節點分擔讀取負載,可以大幅提高Redis伺服器的並發量。
例如在我們的電商網站可以發現,對於一個商品只需要上傳一次,但其卻能夠被用戶瀏覽多次,也就是「寫少讀多」這種情況,我們可以利用主從複製進行讀寫分離,減緩伺服器的壓力:
三、建構主從集群
#3.1、準備工作
#1、複製三個設定檔(原名:redis.conf),並分別重新命名為:redis79.conf,redis80.conf,redis81.conf。

2、修改設定檔
#(1)修改redis79.conf
修改連接埠號碼
port 6379
設定為後台運行
daemonize:yes
設定日誌檔案的名字
logfile “6379.log"
設定db檔案名稱
dbfilename dump6379.rdb
(2)修改redis80.conf
修改連接埠號碼
port 6380
設定為後台運行
daemonize:yes
#設定記錄程序Id檔名
pidfile /var/run/redis_6380.pid
設定日誌檔的名字
logfile “6380.log"
設定db檔名稱
dbfilename dump6380.rdb
(3)修改redis81.conf
##修改連接埠號碼
port 6381
daemonize:yes
pidfile /var/run/redis_6381.pid
logfile “6381.log"
dbfilename dump6381.rdb
port:進程所佔用的連接埠號碼######
pid(port ID):記錄了進程的ID,檔案帶有鎖定。可以防止程式的多次啟動。
logfile:明確日誌檔案的位置dbfilename:dumpxxx.file #持久化檔案位置
3.2、搭建一主二从
启动Redis服务器
注意:默认情况下,每台Reids服务器都是主节点,而我们要搭建主从只需要在从机那本搭建即可。
现在分别启动redis79,redis80,redis81服务器。
redis-server redis79.conf redis-server redis80.conf redis-server redis81.conf
使用以下命令,查看是否启动成功:
ps -ef|grep redis

打开三个客户端窗口,分别对应操作三个Redis服务器。
输入命令:
注意要指定端口,才知道我们要打开哪一个Redis。
窗口一:
redis-cli -p 6379
窗口二:
redis-cli -p 6380
窗口三:
redis-cli -p 6381
设置主从关系
我们将redis79设置为主节点,而将redis80和redis81设置为从结点。
配置主机的IP地址和端口号,相当于想认其为自己的老大。
redis80:
#SLAVEOF IP地址 端口 127.0.0.1:6380> slaveof 127.0.0.1 6379 OK
redis81:
#SLAVEOF IP地址 端口 127.0.0.1:6381> slaveof 127.0.0.1 6379 OK
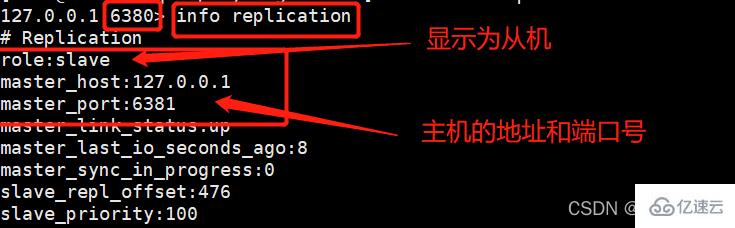
这个时候,我们在从机使用INFO命令就可以查看主从关系了:
info replication
而此时我们去主机redis79中使用同样的命令进行查看:
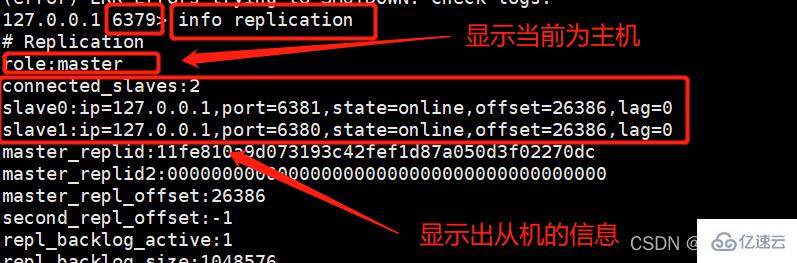
现在我们的一主二从的关系就成功搭建好了!
提示:如果要将从机变成主机,我们只需要在从机执行以下命令,即可让自己变为主机。
SLAVEOF no one
四、知识讲解
知识一
主机可以进行读写操作,而从机只能读操作。
注意:主机中的所有信息和数据,都会自动被从机保存。
主机:
127.0.0.1:6379> set key1 v1 OK 127.0.0.1:6379> get key1 "v1"
从机:
127.0.0.1:6380> get key1 "v1" 127.0.0.1:6380> set key2 v2 #进行写操作就会报错,提示从机只能进行读操作 (error) READONLY You can't write against a read only replica.
知识二
主机如果宕机了,从机依旧可以读取到主机宕机前的数据,但仍然没有写操作,如果主机恢复过来了,从机依旧可以获取到主机写的数据。
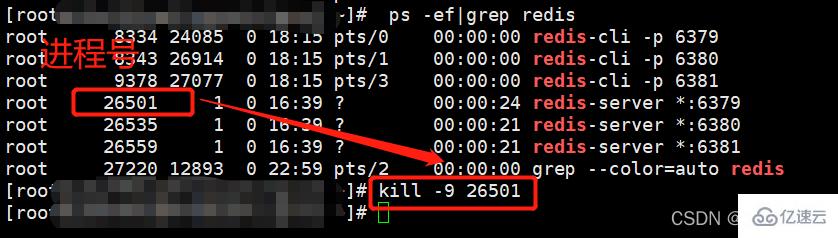
(1)停止主机进程(演示主机宕机了)
停止进程的命令:
kill -9 pid #pid为redis进程号
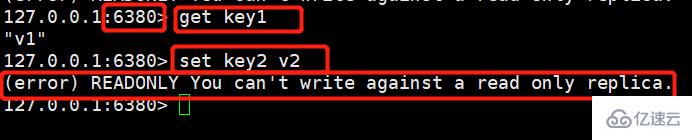
(2)从机获取宕机前主机写入的数据
可以发现,能够顺利拿到,但仍然是无法进行写操作的。
(3)恢复主机
redis-server redis79.conf
(4)主机重新写入数据,从机获取最新数据。
主机写入数据:
127.0.0.1:6379> set k2 yixin OK
从机读取最新数据:
127.0.0.1:6380> get k2 "yixin"
知识三
两种配置方式下的从机断开情况
a、命令行设置主从关系
从机断开了,其重新连接后变为主机,能拿到断开之前的数据,但拿不到主机新写入的值,如果重新设置主从关系,就可以拿到主机全部的数据了。
(1)停止从机进程。
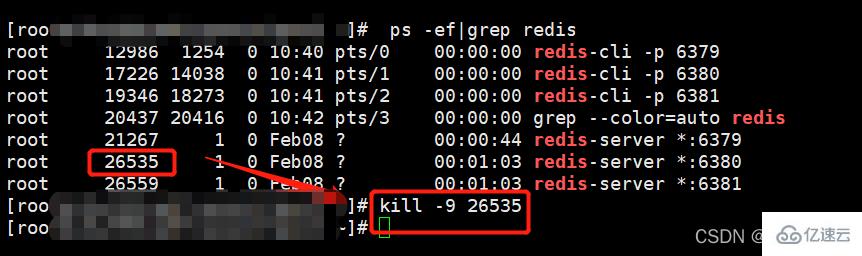
(2)主机写入新数据。
127.0.0.1:6379> set k3 new OK
(3)重新启动从机服务器。
redis-server redis80.conf
(4)尝试获取从机宕机前主机写入的数据,发现可以拿到。
127.0.0.1:6380> get k1 "v1"
(5)尝试获取从机宕机期间主机写入的数据,发现无法拿到了。
127.0.0.1:6380> get k3 (nil)
此次我们可以进行查看主从关系,由于是命令行配置的,所以重启之后又变回主机了。
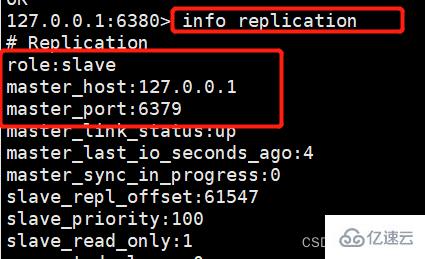
127.0.0.1:6380> info replication # Replication role:master connected_slaves:0
(6)如果要拿到主机的所有数据,只要执行以下命令重新配置主从关系就可以了。
slaveof 127.0.0.1 6379
b、配置文件设置的主从关系
从机断开后,重新连接,也是可以拿到主机的全部数据的。
(1)修改配置文件redis80.conf,添加主从关系。
#指定主机的ip与port slaveof 127.0.0.1 6379
(2)主机添加新数据
127.0.0.1:6379> set k5 hello OK
(3)重新启动redis80服务器。
redis-server redis80.conf
(4)获取从机宕机期间主机新写入的数据,发现现在可以顺利拿到了。
127.0.0.1:6380> get k5 "hello"
我们来查看6380的主从关系,可以发现在重启的时候就已经设置好主从关系了。
五、复制原理
(1)Slave 启动成功连接到 Master 后会发送一个sync同步命令
(2)Master 接到命令,启动后台的存盘进程,同时收集所有接收到的用于修改数据集命令,在后台进程执行完毕之后,master将传送整个数据文件到slave,并完成一次完全同步。
(3)全量复制:而slave服务在接收到数据库文件数据后,将其存盘并加载到内存中。
(4)增量复制:Master 继续将新的所有收集到的修改命令依次传给slave,完成同步。
注意:只要是重新连接master,一次完全同步(全量复制)将被自动执行! 我们的数据一定可以在从机中看到。
六、主从模式的优缺点
优点
(1)同一个Master可以同步多个Slaves。
(2)Slave同样可以接受其它Slaves的连接和同步请求,这样可以有效的分载Master的同步压力。因此我们可以将Redis的Replication架构视为图结构。
(3)Master Server是以非阻塞的方式为Slaves提供服务。所以在Master-Slave同步期间,客户端仍然可以提交查询或修改请求。
(4)Slave Server同样是以非阻塞的方式完成数据同步。在同步期间,如果有客户端提交查询请求,Redis则返回同步之前的数据。
(5)为了分载Master的读操作压力,Slave服务器可以为客户端提供只读操作的服务,写服务仍然必须由Master来完成。即便如此,系统的伸缩性还是得到了很大的提高。
(6)Master可以将数据保存操作交给Slaves完成,从而避免了在Master中要有独立的进程来完成此操作。
(7)支持主从复制,主机会自动将数据同步到从机,可以进行读写分离。
缺点
(1) Redis 主从模式不具备自动容错和恢复功能,如果主节点宕机,Redis 集群将无法工作,此时需要人为干预,将从节点提升为主节点。
(2) 如果主机宕机前有一部分数据未能及时同步到从机,即使切换主机后也会造成数据不一致的问题,从而降低了系统的可用性。
(3) 因为只有一个主节点,所以其写入能力和存储能力都受到一定程度地限制。
(4) 在进行数据全量同步时,若同步的数据量较大可能会造卡顿的现象。
以上是Redis集群主從模式怎麼配置的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 redis集群模式怎麼搭建
Apr 10, 2025 pm 10:15 PM
redis集群模式怎麼搭建
Apr 10, 2025 pm 10:15 PM
Redis集群模式通過分片將Redis實例部署到多個服務器,提高可擴展性和可用性。搭建步驟如下:創建奇數個Redis實例,端口不同;創建3個sentinel實例,監控Redis實例並進行故障轉移;配置sentinel配置文件,添加監控Redis實例信息和故障轉移設置;配置Redis實例配置文件,啟用集群模式並指定集群信息文件路徑;創建nodes.conf文件,包含各Redis實例的信息;啟動集群,執行create命令創建集群並指定副本數量;登錄集群執行CLUSTER INFO命令驗證集群狀態;使
 redis數據怎麼清空
Apr 10, 2025 pm 10:06 PM
redis數據怎麼清空
Apr 10, 2025 pm 10:06 PM
如何清空 Redis 數據:使用 FLUSHALL 命令清除所有鍵值。使用 FLUSHDB 命令清除當前選定數據庫的鍵值。使用 SELECT 切換數據庫,再使用 FLUSHDB 清除多個數據庫。使用 DEL 命令刪除特定鍵。使用 redis-cli 工具清空數據。
 redis怎麼讀取隊列
Apr 10, 2025 pm 10:12 PM
redis怎麼讀取隊列
Apr 10, 2025 pm 10:12 PM
要從 Redis 讀取隊列,需要獲取隊列名稱、使用 LPOP 命令讀取元素,並處理空隊列。具體步驟如下:獲取隊列名稱:以 "queue:" 前綴命名,如 "queue:my-queue"。使用 LPOP 命令:從隊列頭部彈出元素並返回其值,如 LPOP queue:my-queue。處理空隊列:如果隊列為空,LPOP 返回 nil,可先檢查隊列是否存在再讀取元素。
 centos redis如何配置Lua腳本執行時間
Apr 14, 2025 pm 02:12 PM
centos redis如何配置Lua腳本執行時間
Apr 14, 2025 pm 02:12 PM
在CentOS系統上,您可以通過修改Redis配置文件或使用Redis命令來限制Lua腳本的執行時間,從而防止惡意腳本佔用過多資源。方法一:修改Redis配置文件定位Redis配置文件:Redis配置文件通常位於/etc/redis/redis.conf。編輯配置文件:使用文本編輯器(例如vi或nano)打開配置文件:sudovi/etc/redis/redis.conf設置Lua腳本執行時間限制:在配置文件中添加或修改以下行,設置Lua腳本的最大執行時間(單位:毫秒)
 redis命令行怎麼用
Apr 10, 2025 pm 10:18 PM
redis命令行怎麼用
Apr 10, 2025 pm 10:18 PM
使用 Redis 命令行工具 (redis-cli) 可通過以下步驟管理和操作 Redis:連接到服務器,指定地址和端口。使用命令名稱和參數向服務器發送命令。使用 HELP 命令查看特定命令的幫助信息。使用 QUIT 命令退出命令行工具。
 redis計數器怎麼實現
Apr 10, 2025 pm 10:21 PM
redis計數器怎麼實現
Apr 10, 2025 pm 10:21 PM
Redis計數器是一種使用Redis鍵值對存儲來實現計數操作的機制,包含以下步驟:創建計數器鍵、增加計數、減少計數、重置計數和獲取計數。 Redis計數器的優勢包括速度快、高並發、持久性和簡單易用。它可用於用戶訪問計數、實時指標跟踪、遊戲分數和排名以及訂單處理計數等場景。
 redis過期策略怎麼設置
Apr 10, 2025 pm 10:03 PM
redis過期策略怎麼設置
Apr 10, 2025 pm 10:03 PM
Redis數據過期策略有兩種:定期刪除:定期掃描刪除過期鍵,可通過 expired-time-cap-remove-count、expired-time-cap-remove-delay 參數設置。惰性刪除:僅在讀取或寫入鍵時檢查刪除過期鍵,可通過 lazyfree-lazy-eviction、lazyfree-lazy-expire、lazyfree-lazy-user-del 參數設置。
 如何優化debian readdir的性能
Apr 13, 2025 am 08:48 AM
如何優化debian readdir的性能
Apr 13, 2025 am 08:48 AM
在Debian系統中,readdir系統調用用於讀取目錄內容。如果其性能表現不佳,可嘗試以下優化策略:精簡目錄文件數量:盡可能將大型目錄拆分成多個小型目錄,降低每次readdir調用處理的項目數量。啟用目錄內容緩存:構建緩存機制,定期或在目錄內容變更時更新緩存,減少對readdir的頻繁調用。內存緩存(如Memcached或Redis)或本地緩存(如文件或數據庫)均可考慮。採用高效數據結構:如果自行實現目錄遍歷,選擇更高效的數據結構(例如哈希表而非線性搜索)存儲和訪問目錄信
