

十分鐘理解ChatGPT的技術邏輯及演進(前世、今生)

0、 前言
11月30日,OpenAI推出了一個名為ChatGPT的AI聊天機器人,可以供公眾免費測試,短短幾天就火爆全網。
從頭條、公眾號上多個宣傳來看,它既能寫代碼、查BUG,還能寫小說、寫遊戲策劃,包括向學校寫申請書等,似乎無所不能。
本著科(好)學(奇)的精神,抽了一些時間對ChatGPT進行了測試驗證,並且 **梳理了一下ChatGPT為什麼能這麼"強"**。
由於筆者並沒有專業學過AI,同時精力受限,所以 短時間內就不會再有AI-003類似更深入到技術的篇章了,了解001、002就已經超出普通吃瓜群眾的範疇了。
本篇會有較多技術名詞,我會盡量降低其理解難度。
同時,由於非AI專業出身,如有錯漏、敬請指出。
致謝:非常感謝X同學、Z同學兩位大牛的審稿,尤其感謝X同學的專業性堪誤
1、什麼是GPT
ChatGPT裡面有兩個字,一個是Chat,指的是可以對話聊天。另外一個詞,就是GPT。
GPT的全名,是Generative Pre-Trained Transformer(生成式預訓練Transfomer模型)。
可以看到裡面一共3個單字,Generative生成式、Pre-Trained預訓練、和Transformer。
有讀者可能會注意到,我上面沒有給Transformer翻譯中文。
因為Transformer是一個技術專有名詞,如果硬翻譯 ,就是變壓器。但是會容易失去本意,不如不翻譯。
在下面第3章節會再講解Transformer。
2、GPT之技術演進時間線
GPT從開始至今,其發展歷程如下:
2017年6月,Google發布論文《Attention is all you need 》,首次提出Transformer模型,成為GPT發展的基礎。論文地址: https://arxiv.org/abs/1706.03762
2018年6月,OpenAI 發布論文《Improving Language Understanding by Generative Pre-Training》(透過生成式預訓練提升語言理解能力) ,首次提出GPT模型(Generative Pre-Training)。論文地址: https://paperswithcode.com/method/gpt 。
2019年2月,OpenAI 發布論文《Language Models are Unsupervised Multitask Learners》(語言模型應該是無監督多任務學習者),提出GPT-2模型。論文地址: https://paperswithcode.com/method/gpt-2
2020年5月,OpenAI 發布論文《Language Models are Few-Shot Learners》(語言模型應該是少量樣本(few- shot)學習者,提出GPT-3模型。論文地址: https://paperswithcode.com/method/gpt-3
2022年2月底,OpenAI 發布論文《Training language models to follow instructions with human feedback》(使用人類回饋指令流來訓練語言模型),公佈Instruction GPT模型。論文地址: https://arxiv.org/abs/2203.02155
2022 年11月30日,OpenAI推出ChatGPT模型,並提供試用,全網火爆。見:AI-001-火爆全網的聊天機器人ChatGPT能做什麼
3、GPT之T-Transformer(2017)
在第1小節中,我們說到Transformer是沒有合適的翻譯的。
但是Transfomer卻是GPT(Generative Pre-Training Transfomer)中最重要、最基礎的關鍵字。
(註:GPT的Transformer相比google論文原版Transformer是簡化過的,只保留了Decoder部分,見本文4.3小節)
3.1、重點在好,還是重點在人?
就像好人,最關鍵的是好,還是人?
讀者們,是好嗎?
一個稍穩的答覆是:既不是好,也不是人;既是好,也是人。
唔,有點繞,那麼說人話一點,展開: 語意上,重點在好; 基礎和前提上,重點在人。
3.2、對不起,你是個好人
再延展一下,那"對不起,你是個好人"呢?
語義的重點,變成是對不起。但是語義的前提,還是人。
3.3、回歸正題,Transfomer是什麼
這篇《十分鐘理解Transfomer》( https://zhuanlan.zhihu.com/p/82312421 ) 可以看一下。
#看懂了可以忽略我接下來關於Transfomer的內容,直接跳到第4章。如果沒太看懂,可以看下我的理解,對你或許有一定參考作用。
3.3.1、上一代RNN模型的重大缺陷
#在Transformer模型出來前,RNN模型(循環神經網路)是典型的NLP模型架構,基於RNN還有其他一些變種模型(忽略其名字,Transformer出來後,已經不再重要了),但是都存在相同的問題,並沒能很好解決。
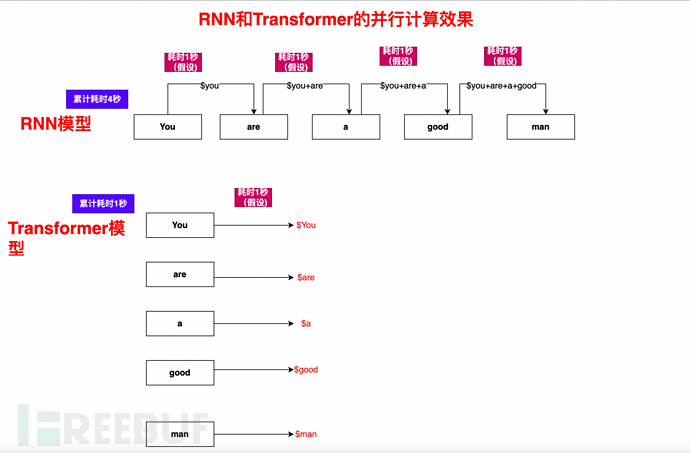
RNN的基本原理是,從左到右瀏覽每個單字向量(比如說this is a dog),保留每個單字的數據,後面的每個單詞,都依賴前面的單字。
RNN的關鍵問題:前後需要順序、依序計算。可以想像一下,一本書、一篇文章,裡面是有大量單字的,而又因為順序依賴性,不能並行,所以效率很低。
這樣說可能大家還是不容易理解,我舉一個例子(簡化理解,和實際有一定出入):
在RNN循環中,You are a good man這句話,需要如何計算呢?
1)、You和You are a good man計算,得到結果集$You
2)、基於$You的基礎上,再使用Are和You are a good man ,計算出$Are
3)、基於$You、$Are的基礎,繼續計算$a
4)、依此類推,計算$is、$good、$ man,最終完成You are a good man的所有元素的完整計算
可以看到,計算過程是一個一個、順次計算,單一流水線,後面的工序依賴前面的工序,所以非常慢
3.3.2、Transformer之All in Attention
前面我們提到,2017年6月,Google發布論文《Attention is all you need》,首次提出Transformer模型,成為GPT發展的基礎。論文地址: https://arxiv.org/abs/1706.03762
從其標題《Attention is all you need》你就能知道,Transfomer其實主張是"All in Attention"。
那麼什麼是Attention(注意力)呢?
在《Attention is all you need》論文中,可以看到其定義如下:
自我注意(self-Attention),有時稱為內部注意,是一種將單一序列的不同位置連結起來的注意力機制,以便計算序列的表示。自我注意已成功地應用於閱讀理解、抽象概括、語篇包含和學習任務無關的句子表示等多種任務中

簡單理解,就是字與字之間的關聯度,透過注意力(Attention) 這個向量來描述。
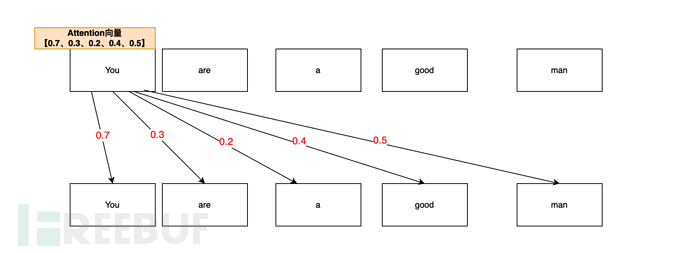
比如說You are a good man(你是個好人),AI在分析You的注意力向量時,可能是這麼分析的:
從Your are a good man這句話中,透過注意力機制進行測算,You和You(自身)的注意力關聯機率最高(0.7,70%),畢竟 你(you)首先是你(you);於是You,You的注意力向量是0.7
You和man(人)的注意力關聯其次(0.5,50%),你(you)是個人(man),,於是You,man的注意力向量是0.5
You和good(好)的注意力關聯度再次(0.4,40%),你在人的基礎上,還是一個好(good)人。於是You,good的注意力向量值是0.4
You,are向量值是 0.3;You,a的向量值是0.2。
於是最終You的注意力向量清單是【0.7 、 0.3、0.2、0.4、0.5】(僅本文舉例)。
3.4、論文中對attention和Transfomer的價值描述
在論文中,google對於attention和transfomer的描述,主要強調了傳統模型對順序依賴存在,Transformer模型可以取代目前的遞歸模型,消減對輸入輸出的順序依賴。


3.5、Transformer機制的深遠意義
Transformer問世後,迅速取代循環神經網路RNN的系列變種,成為主流的模型架構基礎。
如果說 可以並行、速度更快都是技術特徵,讓行外人士、普羅大眾還不夠直觀,那麼從 當前ChatGPT的震憾效果就可以窺知一二。
**Transformer從根本上解決了兩個關鍵障礙,其推出是變革性的、革命性的**。
3.5.1、擺脫了人工標註資料集(大幅降低人工數量)
這個關鍵障礙就是:過往訓練我們要訓練一個深度學習模型,必須使用大規模的標記好的資料集合(Data set)來訓練,這些資料集合需要人工標註,成本極高。
打個比方,就是機器學習需要大量教材,大量輸入、輸出的樣本,讓機器去學習、訓練。這個教材需要量身製定,而且需求數量極大。
好比 以前要10,000、10萬名老師寫教材,現在只需要10人,降低成千上萬倍。
那麼這塊是怎麼解決的呢?簡單描述一下,就是透過Mask機制,遮蔽已有文章中的句段,讓AI去填空。
好比是一篇已有的文章、詩句,擋住其中一句,讓機器根據學習到的模型,依據上一句,去填補下一句。
如下圖範例:


這樣,很多現成的文章、網頁、知乎問答、百度知道等,就是天然的標註資料集了(一個字,超省錢)。
3.5.2、化順序計算為平行計算,巨幅降低訓練時間
除了人工標註之外,在3.3.1小節中提到RNN的重大缺陷,就是順序計算,單一管線的問題。
Self-Attention機制,結合mask機制與演算法最佳化,讓 一篇文章、一句話、一段話能夠並行計算。
還是以You are a good man舉例,可以看到,電腦有多少,Transformer就能有多快:


4、GPT(Generative Pre-Training)-2018年6月
接下來,就到了ChatGPT的前世-GPT(1)了。
2018年6月,OpenAI 發布論文Improving Language Understanding by Generative Pre-Training》(透過生成式預訓練提升語言理解能力),首次提出GPT模型(Generative Pre-Training)。論文地址: https://paperswithcode.com/method/gpt 。
4.1、GPT模型的核心主張1-預訓練(pre-training)
GPT模型依託於Transformer解除了順序關聯和依賴性的前提,提出一個建設性的主張。
先通過大量的無監督預訓練(Unsupervised pre-training),
註:無監督是指不需要人介入,不需要標註資料集(不需要教材和老師)的預訓練。
再透過少量有監督微調(Supervised fine-tunning),來修正其理解能力。

4.1.1、打個比方
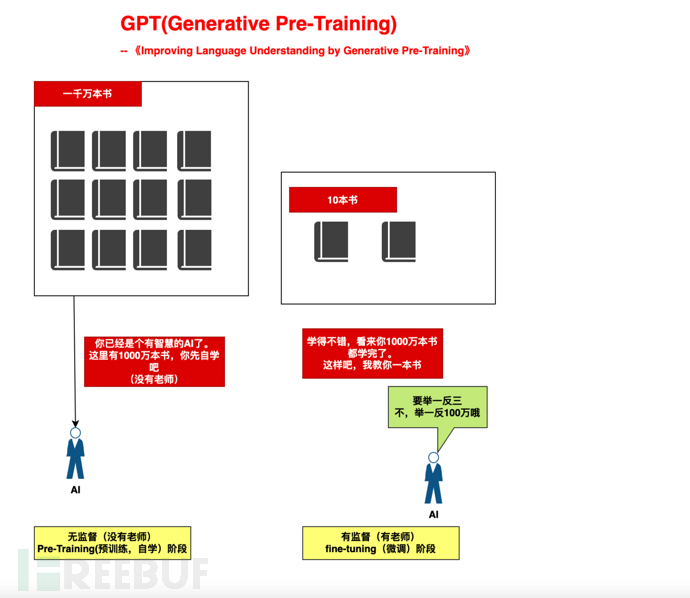
打個比方,就好像我們培養一個小孩,分了兩個階段:
1)、大規模自學階段(自學1000萬本書,沒有老師):提供AI充足的算力,讓其基於Attention機制,自學。
2)、小規模指導階段(教10本書):依據10本書,舉一反"三"

4.1.2、論文開頭的描述
所謂開宗明義,從開篇introduction中,也可看到GPT模型對於監督學習、手動標註資料的說明。

4.2、GPT模型的核心主張2-生成式(Generative)
在機器學習裡,有判別式模式(discriminative model)和生成式模式(Generative model)兩種區別。
GPT(Generative Pre-Training)顧名思義,採用了生成式模型。
生成式模型相比判別式模型更適合大數據學習 ,後者更適合精確樣本(人工標註的有效資料集)。要**更好實現預訓練(Pre-Training)**,生成式模式會比較合適。
註:本小節重點在於上面一句話(更適合大數據學習),如果覺得理解複雜,本小節下面可不看。
在wiki生成式模式的資料裡( https://en.wiki敏pedia感.org/wiki/Generative_model ) ,舉了一個如下說明兩者的差異:

單看上面可能不容易看懂,這裡補充解釋下。
上面的意思是說,假設有4個樣本:
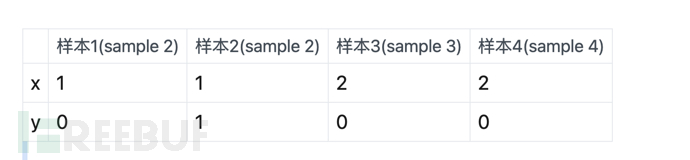
那麼生成式(Generative Model)的特徵就是機率不分組(計算樣本內機率,除以樣本總和),以上表為例,發現x=1,y=0的總共有1個,所以會認為x=1,y=0的幾率為1/4(樣本總數為4)。
同樣的,x=2,y=0的總共有2個,則x=2,y=0的機率為2/4.

而判別式(Discriminative Model)的特徵則是**機率分組計算(計算組內機率,除以組內總和)**。以上表為例,x=1,y=0總共共有1個,同時x=1的分組共有2個sample,所以其機率為 1/2。
同樣的,x=2,y=0的總共有2個。且同時x=2的分組共有2個sample,則x=2,y=0的機率 為2/2=1(即100%)。

4.3、GPT相比原版Transfomer的模型改進
下面是GPT的模型說明,GPT訓練了一個12層僅decoder的解碼器( decoder-only,沒有encoder),使得模型更為簡單。
註1:google論文《Attention is all you need》原版Transformer中,包含Encoder和Decoder兩部分,前者(Encoder)對應的是 翻譯,後者(Decoder)對應的是 生成。
註2:google以Encoder為核心,建構了一個BERT(Bidirectional Encoder Representations from Transformers,雙向編碼產生Transformer)模型。裡面的雙向(Bidirectional),是指BERT是同時使用上文和下文預測單詞,因此 BERT 更擅長處理自然語言理解任務 (NLU)。
註3:本小節要點,GPT基於Transformer,但是相比Transformer又簡化了模型,去掉了Encoder,只保留了Decoder。同時,相較於BERT的上下文預測(雙向),GPT主張僅使用單字的上文預測單字(單向),從而使模型更簡單、計算更快,更適合於極致的生成,並因此GPT更擅長處理自然語言生成任務(NLG),也就是我們在AI-001-火爆全網的聊天機器人ChatGPT能做什麼發現的,ChatGPT很擅長寫"作文"、編瞎話。理解本段後,本小節後面的可不看。
註4:從模擬人類來看,GPT的機制得更像真實人類。因為人類也是根據上文(前面說的)來推測下文(即說後面的),所謂說出去的話就像潑出去的水,人類也是沒辦法根據後面說的話,來調整前面說的話的,即使說錯了,惡語傷人心,也只能基說出去的話(上文)補救、解釋。

4.3.1、架構圖比較
下圖為Transfomer模型架構與GPT模型架構的比較(分別來自論文《Attention is all you need》和《Improving Language Understanding by Generative Pre-Training》)
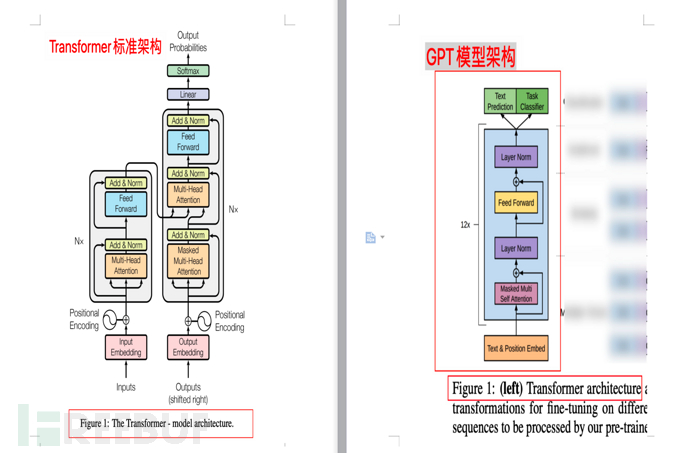
4.4、GPT模型的訓練規模
#在前面提到生成式模式更有利於大數據集的Pre-Training預訓練,那麼GPT使用了多大規模的data set(資料集)呢?
論文中有提到,它採用了一個名為BooksCorpus的資料集,包含了超過7000本未發表書籍。

5、GPT-2(2019年2月)
2019年2月,OpenAI 發布論文《Language Models are Unsupervised Multitask Learners》(語言模型應該是無監督多任務學習者),提出GPT-2模型。論文地址: https://paperswithcode.com/method/gpt-2
5.1、GPT-2模型相比GPT-1的核心變化
前面提到,GPT的核心主張有Generative(生成式)、Pre-Training。同時,GPT訓練有兩步:
1)、大規模自學階段(Pre-Training預訓練,自學1000萬本書,沒有老師):給AI充足的算力,讓其基於Attention機制,自學。
2)、小規模指導階段(fine-tuning微調,教10本書):依據10本書,舉一反"三"
GPT-2的時候,OpenAI將有監督fine-tuning微調階段給直接去掉了,將其變成了一個無監督的模型。
同時,增加了一個關鍵字**多任務(multitask)**,這點從其論文名稱《Language Models are Unsupervised Multitask Learners》(語言模型應該是一個無監督多任務學習者)也可看出。

5.2、為什麼這麼調整?試圖解決zero-shot問題
GPT-2為什麼這麼調整?從論文描述來看,是為了嘗試解決**zero-shot(零次學習問題)**。
zero-shot(零次學習)是一個什麼問題呢?簡單可理解為推理能力。就是指面對未知事物時,AI也能自動認識它,即具備推理能力。
比如說,在去動物園前,我們告訴小朋友,像熊貓一樣,是黑白色,並且呈黑白條紋的類馬動物就是斑馬,小朋友根據這個提示,能夠正確找到斑馬。
5.3、multitask多任務如何理解?
傳統ML中,如果要訓練一個模型,就需要一個專門的標註資料集,訓練一個專門的AI。
比如說,要訓練一個能認出狗狗圖像的機器人,就需要一個標註了狗狗的100萬張圖片,訓練後,AI就能認出狗狗。這個AI,是專用AI,也叫single task。
而multitask多任務,就是主張不要訓練專用AI,而是餵取了海量資料後,任意任務都可完成。
5.4、GPT-2的資料和訓練規模
資料集增加到800萬網頁,40GB大小。

而模型自身,也達到最大15億參數、Transfomer堆疊至48層。簡單類比,就像是模擬人類15億神經元(僅舉例,不完全等同)。

6、GPT-3(2020年5月)
2020年5月,OpenAI 發布論文《Language Models are Few-Shot Learners》(語言模型應該是一個少量樣本(few-shot)學習者),提出GPT-3模型。論文地址: https://paperswithcode.com/method/gpt-3
6.1、GPT-3的突破式效果進展
論文中對於效果是這麼描述的:
1、GPT-3在翻譯、問題回答和完形填空中表現出強大的性能,同時能夠解讀單字、句子中使用新單字或執行3位數算訂。
2、GPT-3可以產生新聞文章的樣本,人類已然區分不出來。
如下圖:

6.2、GPT-3比較GPT-2的核心變化
前面提到GPT-2在追求無監督、zero-shot(零次學習),但其實在GPT-2論文中,OpenAI也提出結果不達預期。這顯然是需要調整的,於是GPT-3就做了相關調整。從標題《Language Models are Few-Shot Learners》(語言模型應該是少量樣本(few-shot)學習者)也可看出。
說穿了,zero-shot(零次學習)不靠譜。

並且,在訓練過程中會對比Zero-shot零次學習;One-shot(單一樣本學習)、Few-shot(少量樣本學習),以及fine-tuning人工微調的方式。
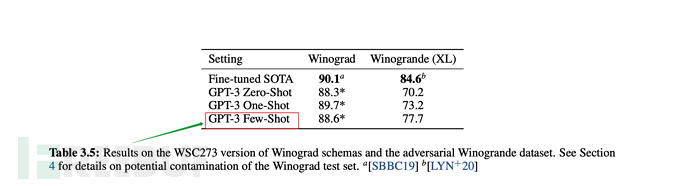
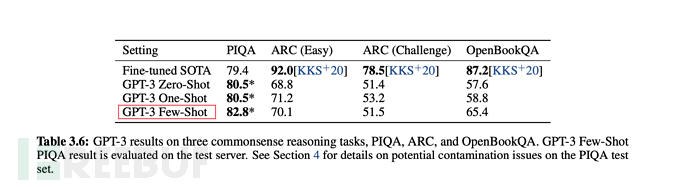
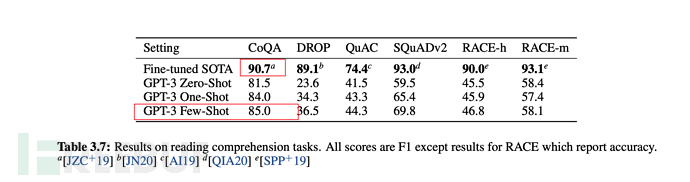
最後在多數情況下,few-shot(少量樣本)的綜合表現,是在無監督模式下最優的,但稍弱於fine-tuning微調模式。
從下述論文表格、圖形中,也可看出few-shot是綜合表現僅弱於fine-tuning微調的。
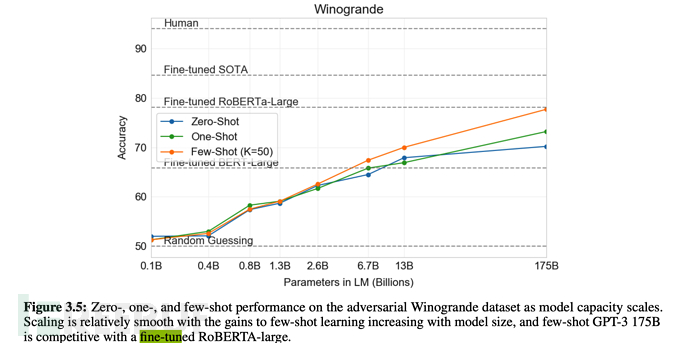
#6.3、GPT-3的訓練規模
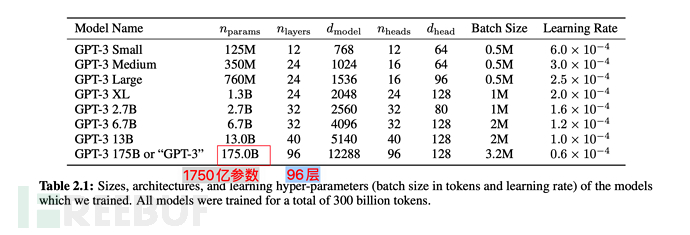
GPT-3採用了過濾前45TB的壓縮文本,過濾後也仍有570GB的海量資料。

在模型參數上,從GPT-2的15億,提升到1750億,翻了110倍以上;Transformer Layer也從48提升到96。
7、Instruction GPT(2022年2月)
2022年2月底,OpenAI 發布論文《Training language models to follow instructions with human feedback》(使用人類回饋指令流來訓練語言模型),公佈Instruction GPT模型。論文地址: https://arxiv.org/abs/2203.02155
7.1、Instruction GPT相比GPT-3的核心變化
Instruction GPT是基於GPT-3的一輪增強優化,所以也稱為GPT-3.5。
前面提到,GPT-3主張few-shot少樣本學習,同時堅持無監督學習。
但是事實上,few-shot的效果,顯然是差於fine-tuning監督微調的方式的。
那麼怎麼辦呢?走回fine-tuning監督微調?顯然不是。
OpenAI給出新的答案: 在GPT-3的基礎上,基於人工回饋(RHLF)訓練一個reward model(獎勵模型),再用reward model(獎勵模型,RM)去訓練學習模型。
天啦嚕,夭壽了。 。要用機器(AI)來訓練機器(AI)了。 。

7.2、Insctruction GPT的核心訓練步驟
Instruction GPT一共有3步:
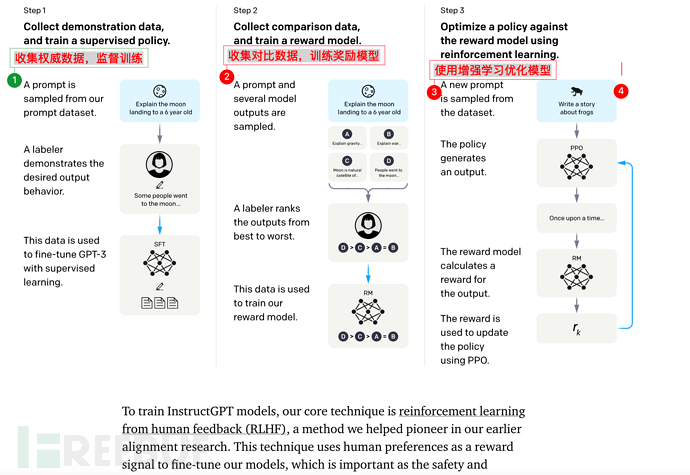
1)、對GPT-3進行**fine-tuning(監督微調)**。
2)、再訓練一個Reward Model(獎勵模型,RM)
3)、最後透過增強學習優化SFT


值得注意的是,第2步、第3步是完全可以迭代、循環多次進行的。
7.3、Instruction GPT的訓練規模
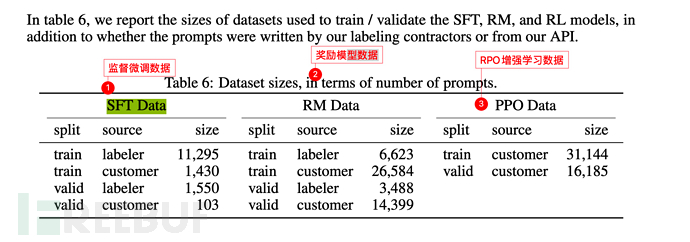
基礎資料規模同GPT-3(見6.3小節),只是在其基礎上增加了3個步驟(監督微調SFT、獎勵模型訓練Reward Model,增強學習優化RPO)。
下圖labeler是指OpenAI僱用或有相關關係的**標註人員(labler)**。
而customer則是指GPT-3 API的呼叫使用者(即其他一些機器學習研究者、程式設計師等)。
這次ChatGPT上線後據說有百萬以上的用戶,我們每個人都是其customer,所以可以預見,未來GPT-4發佈時,其customer規模至少是百萬起。
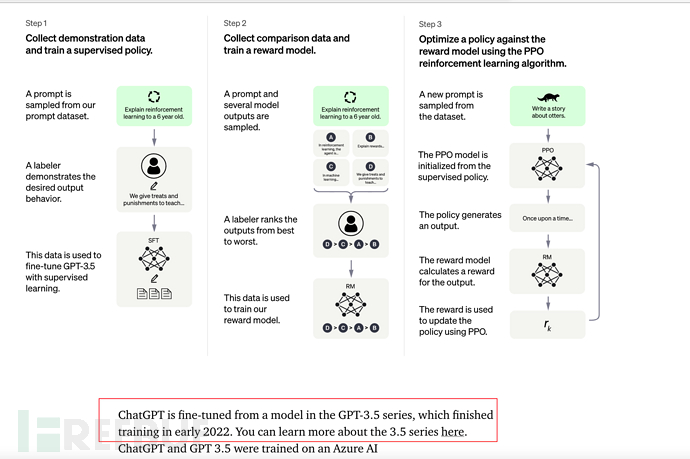
8、ChatGPT(2022年11月)
2022年11月30日,OpenAI推出ChatGPT模型,並提供試用,全網火熱。
見:AI-001-火爆全網的聊天機器人ChatGPT能做什麼
8.1、ChatGPT和Instruction GPT
ChatGPT和InstructionGPT本質上是同一世代的,只是在InstructionGPT的基礎上,增加了Chat功能,同時開放到公眾測試訓練,以便產生更多有效標註資料。
8.2、【重要,建議瀏覽下面推薦的影片】從人的直覺理解上,補充解釋一下ChatGPT的核心原理
可參考 台大教授李宏毅的影片《ChatGPT是怎麼煉成的? GPT社會化過程》,講得很好。
https://www.inside.com.tw/article/30032-chatgpt-possible-4-steps-training
GPT是單向生成,即根據上文產生下文。
比如說有一句話:
給GPT模型給輸入 你好,下面一個字是接你好嗎?你好帥?你好高?你好美?等等,GPT會計算出一個機率,給出最高的那個機率作為答案。
依此類推,如果給予一個指令(或稱為Prompt),ChatGPT也會依據上文(prompt)進行推論下文(回答),同時選擇一個最大機率的上文來回答。
如下圖:
#9、小結
總結:
1)、2017年,谷歌发布论文《Attention is all you need》,提出Transformer模型,为GPT铺就了前提。
2)、2018年6月,OpenAI发布了GPT生成式预训练模型,通过BooksCorpus大数据集(7000本书)进行训练,并主张通过大规模、无监督预训练(pre-training) 有监督微调(fine-tuning)进行模型构建。
3)、2019年2月,OpenAI发布GPT-2模型,进一步扩大了训练规模(使用了40GB数据集,最大15亿参数(parameters))。同时在思路上,去掉了fine-tuning微调过程,强调zero-shot(零次学习)和multitask(多任务)。但是最终zero-shot效果显著比不上fine-tuning微调。
4)、2020年5月,OpenAI发布GPT-3模型,进一步扩大了**训练规模(使用了570GB数据集,和1750亿参数)**。同时采取了few-shot(少量样本)学习的模式,取得了优异效果。 当然,在实验中同步对比了fine-tuning,比fine-tuning效果略差。
5)、2022年2月,OpenAI发布Instruction GPT模型,此次主要是在GPT-3的基础上,增加了监督微调(Supervised Fine-tuning)环节,并且基于此,进一步加入了Reward Model奖励模型,通过RM训练模型来对学习模型进行RPO增强学习优化。
6)、2022年11月30日,OpenAI发布ChatGPT模型,可以理解为一个多轮迭代训练后的InstructionGPT,并在此基础上增加了Chat对话聊天功能。
10、未来将来(GPT-4 or ?)
从种种迹象来看,GPT-4或许将于2023年亮相?它会有多强大呢?
同时ChatGPT的效果,牵引了业界众多目光,想必接下来更多基于GPT的训练模型及其应用,会更加百花齐放。
未来将来,拭目以待。
部分参考资料
ai.googleblog.com/2017/08/transformer-novel-neural-network.html
https://arxiv.org/abs/1706.03762
https://paperswithcode.com/method/gpt
https://paperswithcode.com/method/gpt-2
https://paperswithcode.com/method/gpt-3
https://arxiv.org/abs/2203.02155
https://zhuanlan.zhihu.com/p/464520503
https://zhuanlan.zhihu.com/p/82312421
https://cloud.tencent.com/developer/article/1656975
https://cloud.tencent.com/developer/article/1848106
https://zhuanlan.zhihu.com/p/353423931
https://zhuanlan.zhihu.com/p/353350370
https://juejin.cn/post/6969394206414471175
https://zhuanlan.zhihu.com/p/266202548
https://en.wiki敏pedia感.org/wiki/Generative_model
https://zhuanlan.zhihu.com/p/67119176
https://zhuanlan.zhihu.com/p/365554706
https://cloud.tencent.com/developer/article/1877406
https://zhuanlan.zhihu.com/p/34656727
https://zhuanlan.zhihu.com/p/590311003
以上是十分鐘理解ChatGPT的技術邏輯及演進(前世、今生)的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 ChatGPT 現在允許免費用戶使用 DALL-E 3 產生每日限制的圖像
Aug 09, 2024 pm 09:37 PM
ChatGPT 現在允許免費用戶使用 DALL-E 3 產生每日限制的圖像
Aug 09, 2024 pm 09:37 PM
DALL-E 3 於 2023 年 9 月正式推出,是比其前身大幅改進的車型。它被認為是迄今為止最好的人工智慧圖像生成器之一,能夠創建具有複雜細節的圖像。然而,在推出時,它不包括
 手機怎麼安裝chatgpt
Mar 05, 2024 pm 02:31 PM
手機怎麼安裝chatgpt
Mar 05, 2024 pm 02:31 PM
安裝步驟:1、在ChatGTP官網或手機商店下載ChatGTP軟體;2、開啟後在設定介面中,選擇語言為中文;3、在對局介面中,選擇人機對局並設定中文相譜;4 、開始後在聊天視窗中輸入指令,即可與軟體互動。
 Stable Diffusion 3論文終於發布,架構細節大揭秘,對復現Sora有幫助?
Mar 06, 2024 pm 05:34 PM
Stable Diffusion 3論文終於發布,架構細節大揭秘,對復現Sora有幫助?
Mar 06, 2024 pm 05:34 PM
StableDiffusion3的论文终于来了!这个模型于两周前发布,采用了与Sora相同的DiT(DiffusionTransformer)架构,一经发布就引起了不小的轰动。与之前版本相比,StableDiffusion3生成的图质量有了显著提升,现在支持多主题提示,并且文字书写效果也得到了改善,不再出现乱码情况。StabilityAI指出,StableDiffusion3是一个系列模型,其参数量从800M到8B不等。这一参数范围意味着该模型可以在许多便携设备上直接运行,从而显著降低了使用AI
 DualBEV:大幅超越BEVFormer、BEVDet4D,開卷!
Mar 21, 2024 pm 05:21 PM
DualBEV:大幅超越BEVFormer、BEVDet4D,開卷!
Mar 21, 2024 pm 05:21 PM
這篇論文探討了在自動駕駛中,從不同視角(如透視圖和鳥瞰圖)準確檢測物體的問題,特別是如何有效地從透視圖(PV)到鳥瞰圖(BEV)空間轉換特徵,這一轉換是透過視覺轉換(VT)模組實施的。現有的方法大致分為兩種策略:2D到3D和3D到2D轉換。 2D到3D的方法透過預測深度機率來提升密集的2D特徵,但深度預測的固有不確定性,尤其是在遠處區域,可能會引入不準確性。而3D到2D的方法通常使用3D查詢來採樣2D特徵,並透過Transformer學習3D和2D特徵之間對應關係的注意力權重,這增加了計算和部署的
 自動駕駛與軌跡預測看這篇就夠了!
Feb 28, 2024 pm 07:20 PM
自動駕駛與軌跡預測看這篇就夠了!
Feb 28, 2024 pm 07:20 PM
軌跡預測在自動駕駛中承擔著重要的角色,自動駕駛軌跡預測是指透過分析車輛行駛過程中的各種數據,預測車輛未來的行駛軌跡。作為自動駕駛的核心模組,軌跡預測的品質對於下游的規劃控制至關重要。軌跡預測任務技術堆疊豐富,需熟悉自動駕駛動/靜態感知、高精地圖、車道線、神經網路架構(CNN&GNN&Transformer)技能等,入門難度很高!許多粉絲期望能夠盡快上手軌跡預測,少踩坑,今天就為大家盤點下軌跡預測常見的一些問題和入門學習方法!入門相關知識1.預習的論文有沒有切入順序? A:先看survey,p
 綜述!深度模型融合(LLM/基礎模型/聯邦學習/微調等)
Apr 18, 2024 pm 09:43 PM
綜述!深度模型融合(LLM/基礎模型/聯邦學習/微調等)
Apr 18, 2024 pm 09:43 PM
23年9月國防科大、京東和北理工的論文「DeepModelFusion:ASurvey」。深度模型整合/合併是一種新興技術,它將多個深度學習模型的參數或預測合併為一個模型。它結合了不同模型的能力來彌補單一模型的偏差和錯誤,以獲得更好的性能。而大規模深度學習模型(例如LLM和基礎模型)上的深度模型整合面臨一些挑戰,包括高運算成本、高維度參數空間、不同異質模型之間的干擾等。本文將現有的深度模型融合方法分為四類:(1)“模式連接”,透過一條損失減少的路徑將權重空間中的解連接起來,以獲得更好的模型融合初
 不只3D高斯!最新綜述一覽最先進的3D重建技術
Jun 02, 2024 pm 06:57 PM
不只3D高斯!最新綜述一覽最先進的3D重建技術
Jun 02, 2024 pm 06:57 PM
寫在前面&筆者的個人理解基於圖像的3D重建是一項具有挑戰性的任務,涉及從一組輸入圖像推斷目標或場景的3D形狀。基於學習的方法因其直接估計3D形狀的能力而受到關注。這篇綜述論文的重點是最先進的3D重建技術,包括產生新穎的、看不見的視野。概述了高斯飛濺方法的最新發展,包括輸入類型、模型結構、輸出表示和訓練策略。也討論了尚未解決的挑戰和未來的方向。鑑於該領域的快速進展以及增強3D重建方法的眾多機會,對演算法進行全面檢查似乎至關重要。因此,本研究對高斯散射的最新進展進行了全面的概述。 (大拇指往上滑
 chatgpt國內可以使用嗎
Mar 05, 2024 pm 03:05 PM
chatgpt國內可以使用嗎
Mar 05, 2024 pm 03:05 PM
chatgpt在國內可以使用,但不能註冊,港澳也不行,用戶想要註冊的話,可以使用國外的手機號碼進行註冊,注意註冊過程中要將網路環境切換成國外ip。
