

MySQL中如何使用開窗函數

(1)開窗函數的定義
開窗函數也叫OLAP函數(Online Analytical Processing,線上分析處理),主要用來即時分析處理資料。在MySQL的8.0版本之前,開窗函數是不被支援的,但從這個版本開始就提供了對開窗函數的支援。
# 开窗函数语法 func_name(<parameter>) OVER([PARTITION BY <part_by_condition>] [ORDER BY <order_by_list> ASC|DESC])
開窗函數語句解析:
函數分成兩部分,一部分是函數名稱,開窗函數的數量比較少,總共才11個開窗函數聚合函數(所有的聚合函數都可以用作開窗函數)。根據函數的性質,有的需要寫參數,有的不需要寫參數。
另一部分為over語句,over()是必須寫的,裡面的參數都是非必須參數,可以依照需求選擇性地使用:
第一個參數是partition by 字段,含義是根據此字段將資料集分成多份
第二個參數是order by 字段,每個視窗的資料依據此字段進行升序或降序排列
開窗函數與分組聚合函數比較相似,都是透過指定欄位將資料分成多份,差別在於:
SQL 標準允許將所有聚合函數用作開窗函數,並以OVER 關鍵字區分開窗函數和聚合函數。
聚合函數每組只傳回一個值,開窗函數每組可傳回多個值。
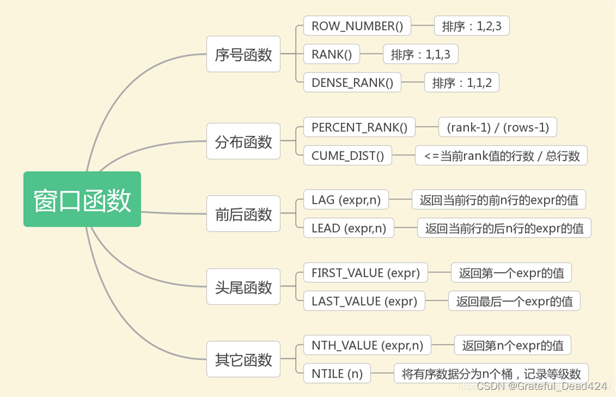
在這11個開窗函數中,實際工作中用的最多的當屬ROW_NUMBER()、RANK()、DENSE_RANK()這三個排序函數了。下面我們透過一個簡單的資料集來學習這三個開窗函數。
# 首先创建虚拟的业务员销售数据 CREATE TABLE Sales ( idate date, iname char(2), sales int ); # 向表中插入数据 INSERT INTO Sales VALUES ('2021/1/1', '丁一', 200), ('2021/2/1', '丁一', 180), ('2021/2/1', '李四', 100), ('2021/3/1', '李四', 150), ('2021/2/1', '刘猛', 180), ('2021/3/1', '刘猛', 150), ('2021/1/1', '王二', 200), ('2021/2/1', '王二', 180), ('2021/3/1', '王二', 300), ('2021/1/1', '张三', 300), ('2021/2/1', '张三', 280), ('2021/3/1', '张三', 280); # 数据查询 SELECT * FROM Sales; # 查询各月中销售业绩最差的业务员 SELECT month(idate),iname,sales, ROW_NUMBER() OVER(PARTITION BY month(idate) ORDER BY sales) as sales_order FROM Sales; SELECT * FROM (SELECT month(idate),iname,sales, ROW_NUMBER() OVER(PARTITION BY month(idate) ORDER BY sales) as sales_order FROM Sales) as t WHERE sales_order=1;

# ROW_NUMBER()、RANK()、DENSE_RANK()的区别 SELECT * FROM (SELECT month(idate) as imonth,iname,sales, ROW_NUMBER() OVER(PARTITION BY month(idate) ORDER BY sales) as row_order, RANK() OVER(PARTITION BY month(idate) ORDER BY sales) as rank_order, DENSE_RANK() OVER(PARTITION BY month(idate) ORDER BY sales) as dense_order FROM Sales) as t;
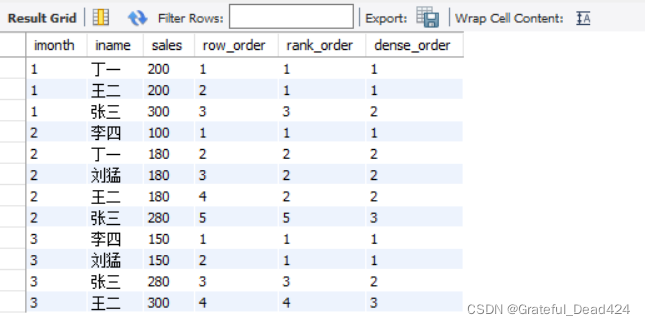
ROW_NUMBER():順序排序——1、2、3
#RANK():並列排序,跳過重複序號——1、1、3
DENSE_RANK():並列排序,不跳過重複序號——1、1、2
#(2)開窗函數的實際應用場景
在工作或面試中,可能會遇到需要求使用者連續登入天數或簽到天數的情況。下面就提供一個用開窗函數解決這類問題的思路。
# 首先创建虚拟的用户登录表,并插入数据 create table user_login ( user_id varchar(100), login_time datetime ); insert into user_login values (1,'2020-11-25 13:21:12'), (1,'2020-11-24 13:15:22'), (1,'2020-11-24 10:30:15'), (1,'2020-11-24 09:18:27'), (1,'2020-11-23 07:43:54'), (1,'2020-11-10 09:48:36'), (1,'2020-11-09 03:30:22'), (1,'2020-11-01 15:28:29'), (1,'2020-10-31 09:37:45'), (2,'2020-11-25 13:54:40'), (2,'2020-11-24 13:22:32'), (2,'2020-11-23 10:55:52'), (2,'2020-11-22 06:30:09'), (2,'2020-11-21 08:33:15'), (2,'2020-11-20 05:38:18'), (2,'2020-11-19 09:21:42'), (2,'2020-11-02 00:19:38'), (2,'2020-11-01 09:03:11'), (2,'2020-10-31 07:44:55'), (2,'2020-10-30 08:56:33'), (2,'2020-10-29 09:30:28'); # 查看数据 SELECT * FROM user_login;
計算連續登入天數通常會有以下三種情況:
#查看每位使用者連續登入的情況
查看每位使用者最大連續登入的天數
查看在某個時段連續登入天數超過N天的使用者
針對第一種情況:查看每位使用者連續登入的情況
根據實際經驗,我們知道在一段時間內,使用者可能會出現多次連續登錄,這些資訊我們都要輸出,所以最後結果輸出的欄位可以是使用者ID、首次登入日期、結束登入日期、連續登入天數這四個。
# 数据预处理:由于统计的窗口期是天数,所以可以对登录时间字段进行格式转换,将其变成日期格式然后再去重(去掉用户同一天内多次登录的情况)
# 为方便后续代码查看,将处理结果放置新表中,一步一步操作
create table user_login_date(
select distinct user_id, date(login_time) login_date from user_login);
# 处理后的数据如下:
select * from user_login_date;
# 第一种情况:查看每位用户连续登陆的情况
# 对用户登录数据进行排序
create table user_login_date_1(
select *,
rank() over(partition by user_id order by login_date) irank
from user_login_date);
#查看结果
select * from user_login_date_1;
# 增加辅助列,帮助判断用户是否连续登录
create table user_login_date_2(
select *,
date_sub(login_date, interval irank DAY) idate #data_sub从指定的日期减去指定的时间间隔
from user_login_date_1);
# 查看结果
select * from user_login_date_2;
# 计算每位用户连续登录天数
select user_id,
min(login_date) as start_date,
max(login_date) as end_date,
count(login_date) as days
from user_login_date_2
group by user_id,idate;
# ===============【整合代码,解决用户连续登录问题】===================
select user_id,
min(login_date) start_date,
max(login_date) end_date,
count(login_date) days
from (select *,date_sub(login_date, interval irank day) idate
from (select *,rank() over(partition by user_id order by login_date) irank
from (select distinct user_id, date(login_time) login_date from user_login) as a) as b) as c
group by user_id,idate;針對第二種情況:查看每位用戶最大連續登入的天數
# 计算每个用户最大连续登录天数 select user_id,max(days) from (select user_id, min(login_date) start_date, max(login_date) end_date, count(login_date) days from (select *,date_sub(login_date, interval irank day) idate from (select *,rank() over(partition by user_id order by login_date) irank from (select distinct user_id, date(login_time) login_date from user_login) as a) as b) as c group by user_id,idate) as d group by user_id;
#針對第三種情況:查看在某個時間段裡連續登入天數超過N天的用戶
如果我們需要查看在10月29日至11月25日連續登入5天或以上的用戶,如何實現? 。這個需求也可以用第一種情況查詢的結果來篩選。
# 查看在这段时间内连续登录天数≥5天的用户 select distinct user_id from (select user_id, min(login_date) start_date, max(login_date) end_date, count(login_date) days from (select *,date_sub(login_date, interval irank day) idate from (select *,rank() over(partition by user_id order by login_date) irank from (select distinct user_id, date(login_time) login_date from user_login) as a) as b) as c group by user_id,idate having days>=5 ) as d;
這種寫法是可以得出結果,但是針對這個問題來說有點麻煩了,下面介紹一個簡單的方法:引用一個新的靜態視窗函數lead()
select *, lead(login_date,4) over(partition by user_id order by login_date) as idate5 from user_login_date;
lead函數有三個參數,第一個參數是指定的列(這裡用登陸日期),第二個參數是當前行向後幾行的值,這裡用的是4,也就是第五次登入的日期,第三個參數是如果傳回的空值可以用指定值來替代,這裡沒有使用第三個參數。在over子句中,視窗依照user_id分組,每個視窗內的資料依照登入日期升序排列。
用第五次登入日期- login_date 1,如果等於5,表示是連續登入五天的,如果得到空值或大於5,表示沒有連續登入五天,程式碼和結果如下:
# 计算第5次登录日期与当天的差值 select *,datediff(idate5,login_date)+1 days from (select *,lead(login_date,4) over(partition by user_id order by login_date) idate5 from user_login_date) as a; # 找出相差天数为5的记录 select distinct user_id from (select *,datediff(idate5,login_date)+1 as days from (select *,lead(login_date,4) over(partition by user_id order by login_date) idate5 from user_logrin_date) as a)as b where days = 5;
【練習】美團外送平台資料分析面試題——SQL
現有交易資料表user_goods_table如下:

現在老闆想知道每個使用者購買的外送品類偏好分佈,並找出每個使用者購買最多的外帶類別是哪一個。
# 分析题目:要求输出字段为用户名user_name,该用户购买最多的外卖品类goods_kind # 解题思路:这是一个分组排序的问题,可以考虑窗口函数 # 第一步:使用窗口函数row_number(),对每个用户购买的外卖品类进行分组统计与排名 select user_name,goods_kind,count(goods_kind), rank() over (partition by user_name order by count(goods_kind) desc) as irank from user_goods_table group by user_name,goods_kind; # 第二步:筛选出每个用户排名第一的外卖品类 select user_id,goods_kind from (select user_name,goods_kind,count(goods_kind), rank() over (partition by user_name order by count(goods_kind) desc) as irank from user_goods_table group by user_name,goods_kind) as a where irank=1
以上是MySQL中如何使用開窗函數的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

AI Hentai Generator
免費產生 AI 無盡。

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)
熱門話題



 mysql:簡單的概念,用於輕鬆學習
Apr 10, 2025 am 09:29 AM
mysql:簡單的概念,用於輕鬆學習
Apr 10, 2025 am 09:29 AM
MySQL是一個開源的關係型數據庫管理系統。 1)創建數據庫和表:使用CREATEDATABASE和CREATETABLE命令。 2)基本操作:INSERT、UPDATE、DELETE和SELECT。 3)高級操作:JOIN、子查詢和事務處理。 4)調試技巧:檢查語法、數據類型和權限。 5)優化建議:使用索引、避免SELECT*和使用事務。
 phpmyadmin怎麼打開
Apr 10, 2025 pm 10:51 PM
phpmyadmin怎麼打開
Apr 10, 2025 pm 10:51 PM
可以通過以下步驟打開 phpMyAdmin:1. 登錄網站控制面板;2. 找到並點擊 phpMyAdmin 圖標;3. 輸入 MySQL 憑據;4. 點擊 "登錄"。
 navicat premium怎麼創建
Apr 09, 2025 am 07:09 AM
navicat premium怎麼創建
Apr 09, 2025 am 07:09 AM
使用 Navicat Premium 創建數據庫:連接到數據庫服務器並輸入連接參數。右鍵單擊服務器並選擇“創建數據庫”。輸入新數據庫的名稱和指定字符集和排序規則。連接到新數據庫並在“對象瀏覽器”中創建表。右鍵單擊表並選擇“插入數據”來插入數據。
 MySQL:世界上最受歡迎的數據庫的簡介
Apr 12, 2025 am 12:18 AM
MySQL:世界上最受歡迎的數據庫的簡介
Apr 12, 2025 am 12:18 AM
MySQL是一種開源的關係型數據庫管理系統,主要用於快速、可靠地存儲和檢索數據。其工作原理包括客戶端請求、查詢解析、執行查詢和返回結果。使用示例包括創建表、插入和查詢數據,以及高級功能如JOIN操作。常見錯誤涉及SQL語法、數據類型和權限問題,優化建議包括使用索引、優化查詢和分錶分區。
 為什麼要使用mysql?利益和優勢
Apr 12, 2025 am 12:17 AM
為什麼要使用mysql?利益和優勢
Apr 12, 2025 am 12:17 AM
選擇MySQL的原因是其性能、可靠性、易用性和社區支持。 1.MySQL提供高效的數據存儲和檢索功能,支持多種數據類型和高級查詢操作。 2.採用客戶端-服務器架構和多種存儲引擎,支持事務和查詢優化。 3.易於使用,支持多種操作系統和編程語言。 4.擁有強大的社區支持,提供豐富的資源和解決方案。
 navicat怎麼新建連接mysql
Apr 09, 2025 am 07:21 AM
navicat怎麼新建連接mysql
Apr 09, 2025 am 07:21 AM
可在 Navicat 中通過以下步驟新建 MySQL 連接:打開應用程序並選擇“新建連接”(Ctrl N)。選擇“MySQL”作為連接類型。輸入主機名/IP 地址、端口、用戶名和密碼。 (可選)配置高級選項。保存連接並輸入連接名稱。
 redis怎麼使用單線程
Apr 10, 2025 pm 07:12 PM
redis怎麼使用單線程
Apr 10, 2025 pm 07:12 PM
Redis 使用單線程架構,以提供高性能、簡單性和一致性。它利用 I/O 多路復用、事件循環、非阻塞 I/O 和共享內存來提高並發性,但同時存在並發性受限、單點故障和不適合寫密集型工作負載的局限性。
 MySQL和SQL:開發人員的基本技能
Apr 10, 2025 am 09:30 AM
MySQL和SQL:開發人員的基本技能
Apr 10, 2025 am 09:30 AM
MySQL和SQL是開發者必備技能。 1.MySQL是開源的關係型數據庫管理系統,SQL是用於管理和操作數據庫的標準語言。 2.MySQL通過高效的數據存儲和檢索功能支持多種存儲引擎,SQL通過簡單語句完成複雜數據操作。 3.使用示例包括基本查詢和高級查詢,如按條件過濾和排序。 4.常見錯誤包括語法錯誤和性能問題,可通過檢查SQL語句和使用EXPLAIN命令優化。 5.性能優化技巧包括使用索引、避免全表掃描、優化JOIN操作和提升代碼可讀性。
