

GPT-4推理提升1750%!普林斯頓清華姚班校友提出全新「思維樹ToT」框架,讓LLM反覆思考

2022年,前谷歌大脑华人科学家Jason Wei在一篇思维链的开山之作中首次提出,CoT可以增强LLM的推理能力。
但即便有了思维链,LLM有时也会在非常简单的问题上犯错。
最近,来自普林斯顿大学和Google DeepMind研究人员提出了一种全新的语言模型推理框架——「思维树」(ToT)。
ToT将当前流行的「思维链」方法泛化到引导语言模型,并通过探索文本(思维)的连贯单元来解决问题的中间步骤。

论文地址:https://arxiv.org/abs/2305.10601
项目地址:https://github.com/kyegomez/tree-of-thoughts
简单来说,「思维树」可以让LLM:
· 自己给出多条不同的推理路径
· 分别进行评估后,决定下一步的行动方案
· 在必要时向前或向后追溯,以便实现进行全局的决策
论文实验结果显示,ToT显著提高了LLM在三个新任务(24点游戏,创意写作,迷你填字游戏)中的问题解决能力。
比如,在24点游戏中,GPT-4只解决了4%的任务,但ToT方法的成功率达到了74%。
让LLM「反复思考」
用于生成文本的大语言模型GPT、PaLM,现已经证明能够执行各种广泛的任务。
所有这些模型取得进步的基础仍是最初用于生成文本的「自回归机制」,以从左到右的方式一个接一个地进行token级的决策。

那么,这样一个简单的机制能否足以建立一个通向「解决通用问题的语言模型」?如果不是,哪些问题会挑战当前的范式,真正的替代机制应该是什么?
恰恰关于「人类认知」的文献为这个问题提供了一些线索。
「双重过程」模型的研究表明,人类有两种决策模式:快速、自动、无意识模式——「系统1」和缓慢、深思熟虑、有意识模式——「系统2」。
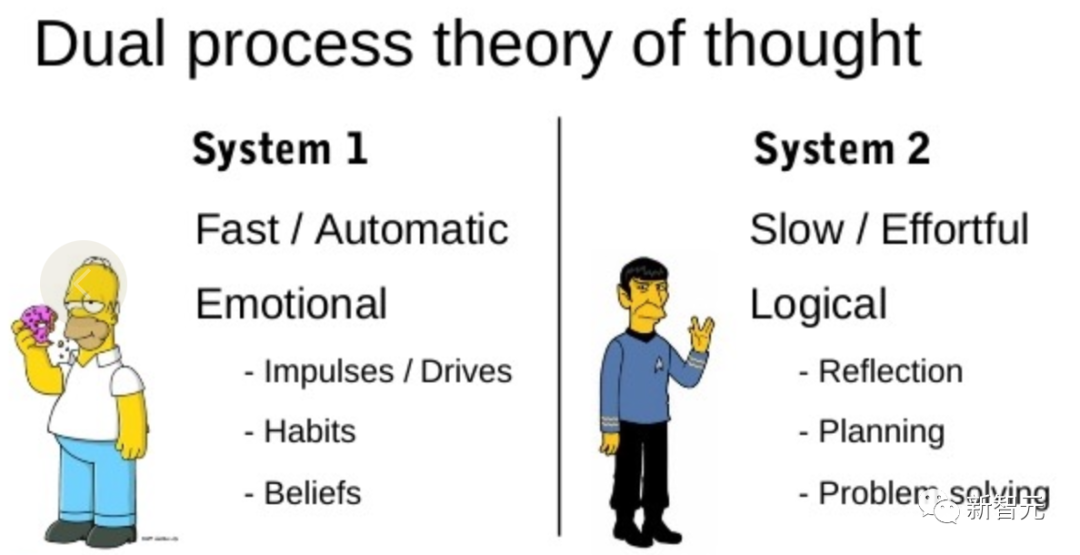
语言模型简单关联token级选择可以让人联想到「系统1」,因此这种能力可能会从「系统2」规划过程中增强。
「系统1」可以让LLM保持和探索当前选择的多种替代方案,而不仅仅是选择一个,而「系统2」评估其当前状态,并积极地预见、回溯以做出更全局的决策。
为了设计这样一个规划过程,研究者便追溯到人工智能和认知科学的起源,从科学家Newell、Shaw和Simon在20世纪50年代开始探索的规划过程中汲取灵感。
Newell及其同事将问题解决描述为「通过组合问题空间进行搜索」,表示为一棵树。
在解決問題的過程中,需要反覆利用現有資訊進行探索,以此獲得更多的信息,直到最終找到解決方案。

這個觀點突顯了現有使用LLM解決通用問題方法的2個主要缺點:
1. 局部來看,LLM並沒有探索思考過程中的不同延續-樹的分支。
2. 總的來看,LLM不包含任何類型的計畫、前瞻或回溯,來幫助評估這些不同的選擇。
為了解決這些問題,研究者提出了用語言模型解決通用問題的思考樹框架(ToT),讓LLM可以探索多種思考推理路徑。
ToT四步法
當前,現有的方法,如IO、CoT、CoT-SC,透過取樣連續的語言序列進行問題解決。
而ToT主動維護了一個「思考樹」。每個矩形框代表一個思維,每個思維都是一個連貫的語言序列,作為解決問題的中間步驟。
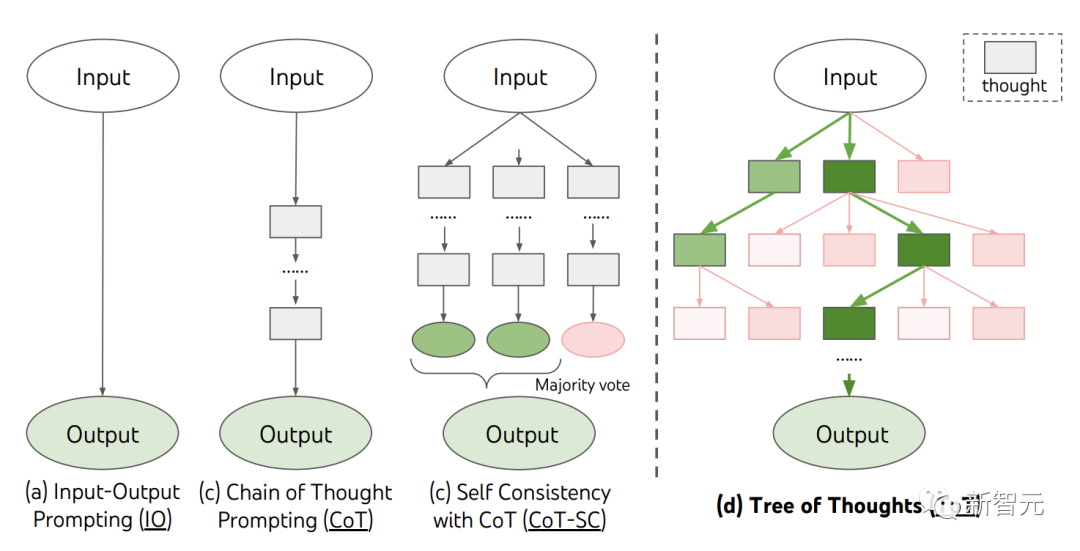
ToT將任何問題定義為在樹上進行搜索,其中每個節點都是一個狀態,表示到目前為止輸入和思維序列的部分解。
ToT執行一個特定任務時需要回答4個問題:
如何將中間過程分解為思考步驟;如何從每個狀態產生潛在的想法;如何啟發性地評估狀態;使用什麼搜尋演算法。
1. 思維分解
CoT在沒有明確分解的情況下連貫抽樣思維,而ToT則利用問題的屬性來設計和分解中間的思維步驟。
根據不同的問題,一個想法可以是幾個單字(填字遊戲) ,一條方程式(24點) ,或是一整段寫作計畫(創意寫作)。
一般來說,一個想法應該足夠「小」,以便LLM能夠產生有意義、多樣化的樣本。例如,生成一本完整的書通常太“大”而無法連貫 。
但一個想法也應該「大」,足以讓LLM能夠評估其解決問題的前景。例如,產生一個token通常太“小”而無法評估。
2. 思維產生器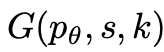
給定樹狀態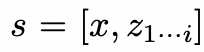 ,透過2種策略來為下一個思考步驟產生k個候選者。
,透過2種策略來為下一個思考步驟產生k個候選者。
(a)從一個CoT提示取樣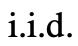 思考:
思考:
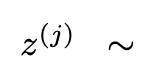
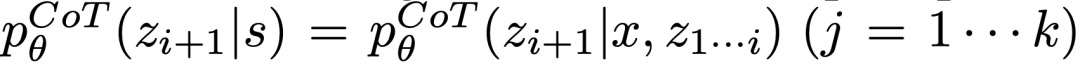
在思維空間豐富(例如每個想法都是一個段落),並且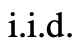 #導致多樣性時,效果更好。
#導致多樣性時,效果更好。
(b)使用「proposal prompt」依序提出想法: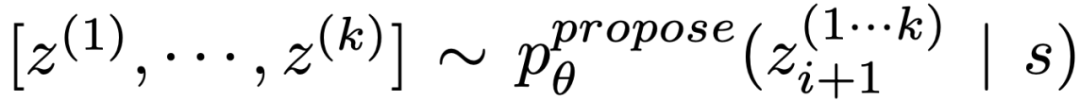
。這在思考空間受限(例如每個思維只是一個字或一行)時效果更好,因此在同一上下文中提出不同的想法可以避免重複。
3. 狀態求值器
給定不同狀態的前沿,狀態評估器評估它們解決問題的進展,作為搜尋演算法的啟發式演算法,以確定哪些狀態需要繼續探索,以及以何種順序探索。
雖然啟發式演算法是解決搜尋問題的標準方法,但它們通常是已編程的(DeepBlue)或學習的(AlphaGo)。這裡,研究者提出了第三種選擇,透過LLM有意識地推理狀態。
在適用的情況下,這種深思熟慮的啟發式方法可以比程式規則更靈活,比學習模型更有效率。與思維生成器,研究人員也考慮2種策略來獨立或一起評估狀態:對每個狀態獨立賦值;跨狀態投票。
4. 搜尋演算法
#最後,在ToT框架中,人們可以根據樹的結構,即插即用不同的搜尋演算法。
研究人員在此探索了2個相對簡單的搜尋演算法:
演算法1-廣度優先搜尋(BFS),每一步維護一組b最有希望的狀態。
演算法2-深度優先搜尋(DFS),首先探索最有希望的狀態,直到達到最終的輸出,或者狀態評估器認為不可能從目前的為閾值解決問題。在這兩種情況下,DFS都會回溯到s的父親狀態以繼續探索。

由上,LLM透過自我評估和有意識的決策,來實現啟發式搜尋的方法是新穎的。
實驗
為此,團隊提出了三個任務用於測試——即使是最先進的語言模型GPT-4,在標準的IO提示或思維鏈(CoT)提示下,都是非常富有挑戰的。

24點(Game of 24)
24點是一個數學推理遊戲,目標是使用4個數字和基本算術運算( -*/)來得到24。
例如,給定輸入「4 9 10 13」,答案的輸出可能是「(10-4)*(13-9)=24」。
ToT設定
#團隊將模型的思考過程分解為3個步驟,每個步驟都是一個中間方程式。
如圖2(a)所示,在每個節點上,提取「左邊」的數字並提示LLM產生可能的下一步。 (每一步給出的「提議提示」都相同)
其中,團隊在ToT中進行寬度優先搜尋(BFS),並在每一步保留最好的b= 5個候選項。
如圖2(b)所示,提示LLM評估每個思考候選項是「肯定/可能/不可能」達到24。基於「過大/過小」的常識消除不可能的部分解決方案,保留剩下的「可能」項。
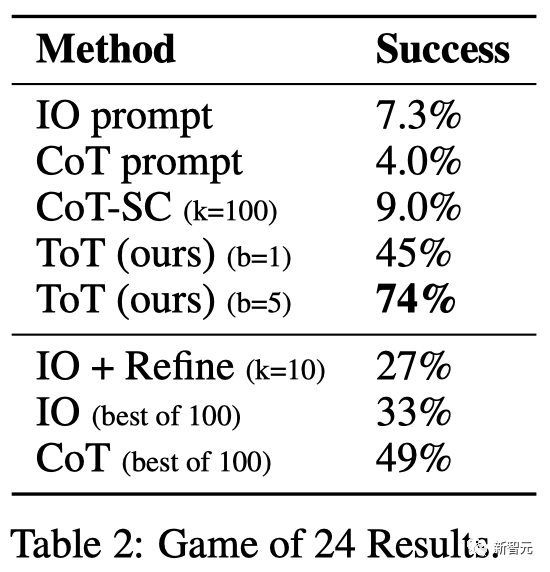
#如表2所示,IO,CoT和CoT-SC提示法在任務上的表現不佳,成功率僅7.3%,4.0%和9.0%。相較之下,ToT在廣度為b=1時已經達到了45%的成功率,而在b=5時達到了74%。
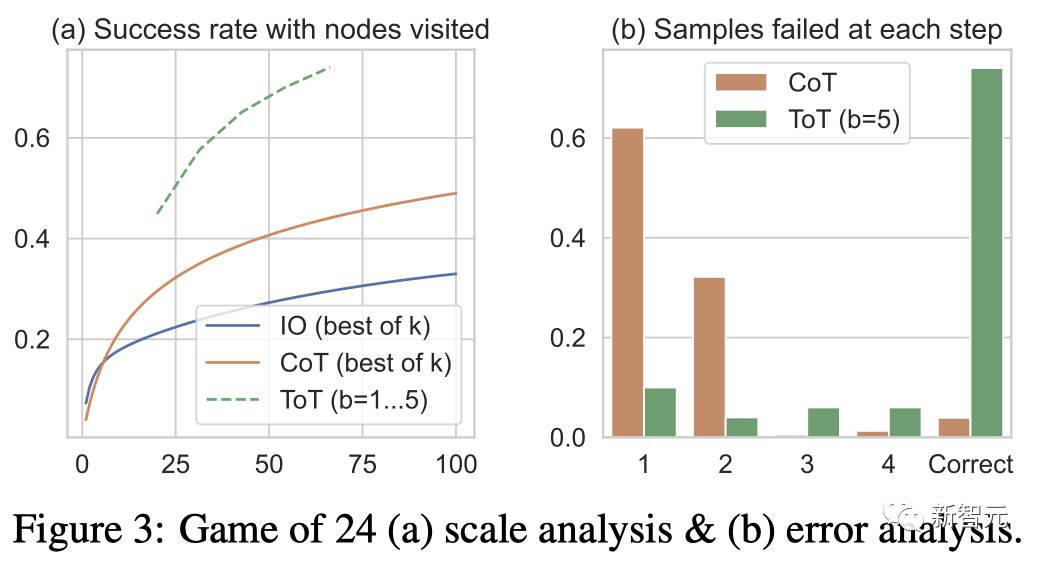
團隊也考慮了IO/CoT的預測設置,透過使用最佳的k個樣本(1≤k≤100)來計算成功率,並在圖3(a)中繪出5個成功率。
不出所料,CoT比IO擴展得更好,最佳的100個CoT樣本達到了49%的成功率,但仍然比在ToT中探索更多節點( b>1)要差。
錯誤分析
圖3( b)分析了CoT和ToT樣本在哪一步失敗了任務,即思維(在CoT中)或所有b個思維(在ToT中)都是無效的或無法達到24。
值得注意的是,大約60%的CoT樣本在第一步就已經失敗了,或者說,是前三個字(例如「4 9」)。
創意寫作
接下來,團隊設計了一個創意寫作任務。
其中,輸入是四個隨機句子,輸出應該是一個連貫的段落,每段都以四個輸入句子分別結束。這樣的任務開放且富有探索性,挑戰創造性思考以及高階規劃。
值得注意的是,團隊還在每個任務的隨機IO樣本上使用迭代-優化(k≤5)方法,其中LLM基於輸入限制和最後生成的段落來判斷段落是否已經「完全連貫」,如果不是,就產生一個優化後的。
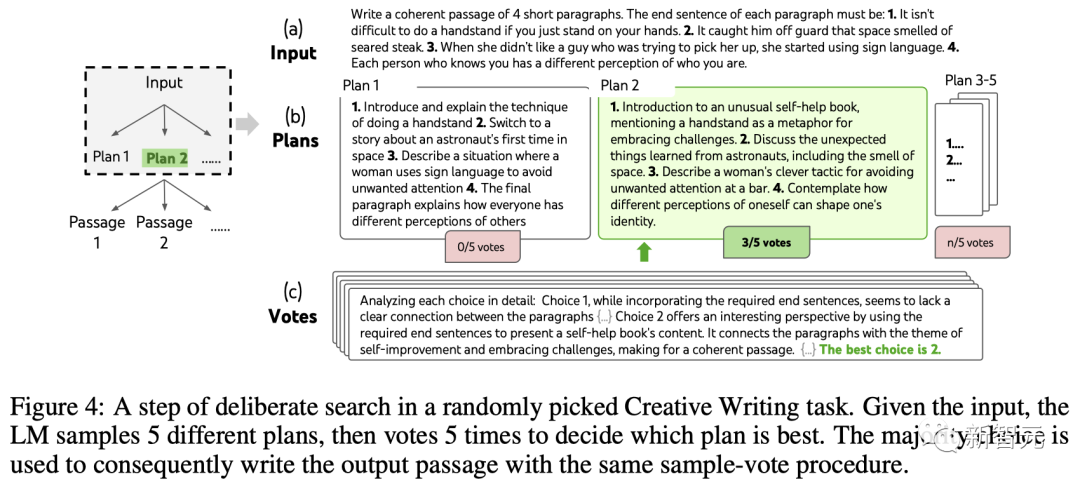
ToT設定
團隊建構了一個深度為2(只有1個中間思維步驟)的ToT。
LLM首先產生k=5的計劃並投票選擇最佳的一個(圖4),然後根據最佳計劃產生k=5的段落,然後投票選擇最佳的一個。
一個簡單的zero-shot投票提示(「分析以下選擇,然後得出哪個最有可能實現指令」)被用來在兩個步驟中抽出5票。
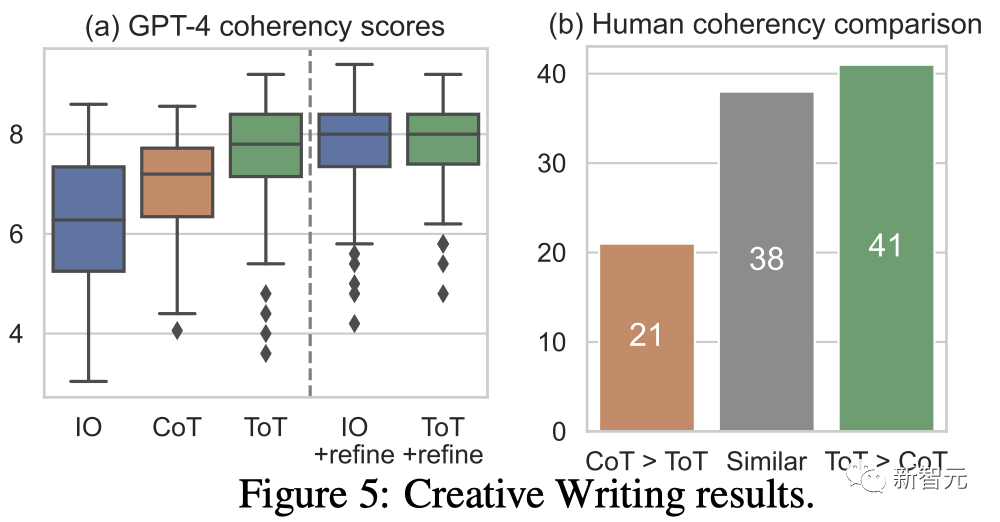
結果
#圖5(a)顯示了100個任務中的GPT-4平均分數,其中ToT(7.56)被認為比IO(6.19)和CoT(6.93)平均產生更連貫的段落。
雖然這樣的自動評測可能會有噪音,但圖5(b)透過顯示人類在100個段落對中有41個更喜歡ToT而只有21個更喜歡CoT (其他38對被認為「同樣連貫」)來確認這項發現。
最後,迭代優化在這個自然語言任務上更有效-將IO連貫性分數從6.19提高到7.67,將ToT連貫性分數從7.56提高到7.91。
團隊認為它可以被看作是在ToT框架下生成思維的第三種方法,新的思維可以透過優化舊的思維而產生,而不是i.i.d.或順序生成。
迷你填字遊戲
在24點遊戲和創意寫作中,ToT相對較淺-最多需要3個思考步驟就能完成輸出。
最後,團隊決定透過5×5的迷你填字遊戲,來設定一個更難的問題。
同樣,目標不只是解決任務,而是研究LLM作為一個通用問題解決者的極限。透過窺視自己的思維,以有目的性的推理作為啟發,來引導自己的探索。
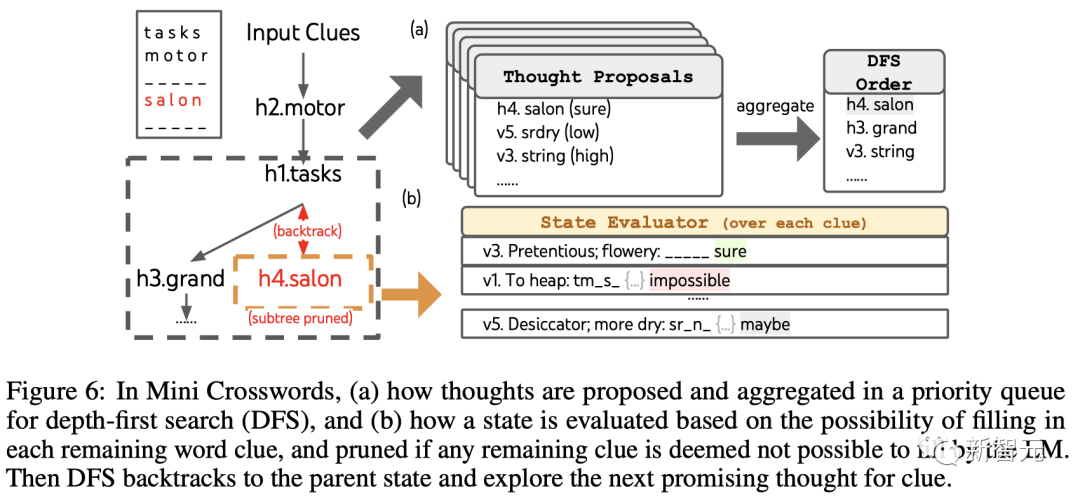
ToT設定
團隊利用深度優先搜尋保持探索最有可能成功的後續單字線索,直到狀態不再有希望,然後回溯到父狀態以探索替代的思維。
為了讓搜尋可行,後續的思維被限制不改變任何已填寫的單字或字母,這樣ToT最多有10個中間步驟。
對於思維生成,團隊在每個狀態下將所有現有的思維(例如,「h2.motor; h1.tasks」對於圖6(a)的狀態)轉換為剩餘線索的字母限制(例如,「v1.To heap: tm___;...」),從而得到下一個單字填入位置和內容的候選。
重要的是,團隊也提示LLM給出不同思維的置信度,並在提案中匯總這些以獲得下一個要探索的思維的排序列表(圖6(a ))。
對於狀態評估,團隊類似地將每個狀態轉換為剩餘線索的字母限制,然後評估每個線索是否可能在給定限制下填寫。
如果任何剩餘的線索被認為是「不可能」的(例如,「v1. To heap: tm_s_」),那麼該狀態的子樹的探索就被剪枝,並且DFS回溯到其父節點來探索下一個可能的候選。
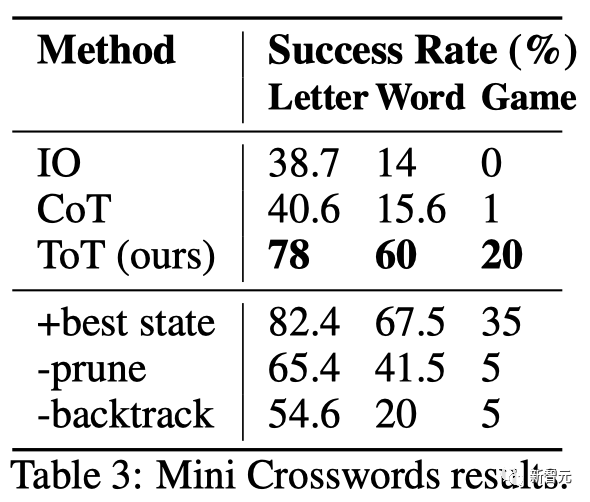
#如表3所示,IO和CoT的提示方法在單字級成功率上表現不佳,低於16%,而ToT顯著改善了所有指標,實現了60%的單字級成功率,並解決了20個遊戲中的4個。
鑑於IO和CoT缺乏嘗試不同線索、改變決策或回溯的機制,這種改善並不令人驚訝。
限制與結論
ToT是讓LLM可以更自主、更聰明地做決策和解決問題的框架。
它提高了模型決策的可解釋性以及與人類對齊的機會,因為ToT所產生的表徵表形式是可讀的、高級的語言推理,而不是隱式的、低階的token值。
對於那些GPT-4已經十分擅長的任務來說,ToT可能並且是不必要的。
此外,像ToT這樣的搜尋方法需要更多的資源(如GPT-4 API成本)來提高任務效能,但ToT的模組化彈性讓使用者可以自訂這種性能-成本平衡。
不過,隨著LLM被用於更多真實世界的決策應用(如程式設計、資料分析、機器人技術等),ToT可以為研究那些即將出現的更為複雜的任務,提供新的機會。
作者介紹
Shunyu Yao(姚順雨)

##論文一作Shunyu Yao是普林斯頓大學的四年級博士生,先前畢業於清華大學的姚班。
他的研究方向是在語言智能體與世界之間建立互動,例如玩文字遊戲(CALM),網上購物(WebShop),瀏覽維基百科進行推理(ReAct) ,或者,基於同樣的想法,用任何工具來完成任何任務。
在人生中,他喜歡閱讀、籃球、桌球、旅行和饒舌。
Dian Yu

Dian Yu是Google DeepMind的一名研究科學家。此前,他在加州大學戴維斯分校獲得了博士學位,並在紐約大學獲得了學士學位,雙主修電腦科學和金融(還有一點表演)。
他的研究興趣是語言的屬性表徵,以及多語言和多模態的理解,主要專注於對話研究(包括開放領域和任務導向)。
Yuan Cao
#Yuan Cao也是Google DeepMind的研究科學家。此前,他在上海交通大學獲得了學士和碩士學位,並在約翰斯霍普金斯大學獲得了博士學位。也曾擔任過百度的首席架構師。
#Jeffrey Zhao

Jeffrey Zhao是Google DeepMind的軟體工程師。此前,他在卡內基美隆大學獲得了學士和碩士學位。
以上是GPT-4推理提升1750%!普林斯頓清華姚班校友提出全新「思維樹ToT」框架,讓LLM反覆思考的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

AI Hentai Generator
免費產生 AI 無盡。

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)
熱門話題



 Debian郵件服務器防火牆配置技巧
Apr 13, 2025 am 11:42 AM
Debian郵件服務器防火牆配置技巧
Apr 13, 2025 am 11:42 AM
配置Debian郵件服務器的防火牆是確保服務器安全性的重要步驟。以下是幾種常用的防火牆配置方法,包括iptables和firewalld的使用。使用iptables配置防火牆安裝iptables(如果尚未安裝):sudoapt-getupdatesudoapt-getinstalliptables查看當前iptables規則:sudoiptables-L配置
 debian readdir如何與其他工具集成
Apr 13, 2025 am 09:42 AM
debian readdir如何與其他工具集成
Apr 13, 2025 am 09:42 AM
Debian系統中的readdir函數是用於讀取目錄內容的系統調用,常用於C語言編程。本文將介紹如何將readdir與其他工具集成,以增強其功能。方法一:C語言程序與管道結合首先,編寫一個C程序調用readdir函數並輸出結果:#include#include#includeintmain(intargc,char*argv[]){DIR*dir;structdirent*entry;if(argc!=2){
 debian readdir如何實現文件排序
Apr 13, 2025 am 09:06 AM
debian readdir如何實現文件排序
Apr 13, 2025 am 09:06 AM
在Debian系統中,readdir函數用於讀取目錄內容,但其返回的順序並非預先定義的。要對目錄中的文件進行排序,需要先讀取所有文件,再利用qsort函數進行排序。以下代碼演示瞭如何在Debian系統中使用readdir和qsort對目錄文件進行排序:#include#include#include#include//自定義比較函數,用於qsortintcompare(constvoid*a,constvoid*b){returnstrcmp(*(
 Debian郵件服務器SSL證書安裝方法
Apr 13, 2025 am 11:39 AM
Debian郵件服務器SSL證書安裝方法
Apr 13, 2025 am 11:39 AM
在Debian郵件服務器上安裝SSL證書的步驟如下:1.安裝OpenSSL工具包首先,確保你的系統上已經安裝了OpenSSL工具包。如果沒有安裝,可以使用以下命令進行安裝:sudoapt-getupdatesudoapt-getinstallopenssl2.生成私鑰和證書請求接下來,使用OpenSSL生成一個2048位的RSA私鑰和一個證書請求(CSR):openss
 Debian OpenSSL如何進行數字簽名驗證
Apr 13, 2025 am 11:09 AM
Debian OpenSSL如何進行數字簽名驗證
Apr 13, 2025 am 11:09 AM
在Debian系統上使用OpenSSL進行數字簽名驗證,可以按照以下步驟操作:準備工作安裝OpenSSL:確保你的Debian系統已經安裝了OpenSSL。如果沒有安裝,可以使用以下命令進行安裝:sudoaptupdatesudoaptinstallopenssl獲取公鑰:數字簽名驗證需要使用簽名者的公鑰。通常,公鑰會以文件的形式提供,例如public_key.pe
 Debian OpenSSL如何防止中間人攻擊
Apr 13, 2025 am 10:30 AM
Debian OpenSSL如何防止中間人攻擊
Apr 13, 2025 am 10:30 AM
在Debian系統中,OpenSSL是一個重要的庫,用於加密、解密和證書管理。為了防止中間人攻擊(MITM),可以採取以下措施:使用HTTPS:確保所有網絡請求使用HTTPS協議,而不是HTTP。 HTTPS使用TLS(傳輸層安全協議)加密通信數據,確保數據在傳輸過程中不會被竊取或篡改。驗證服務器證書:在客戶端手動驗證服務器證書,確保其可信。可以通過URLSession的委託方法來手動驗證服務器
 Debian Hadoop日誌管理怎麼做
Apr 13, 2025 am 10:45 AM
Debian Hadoop日誌管理怎麼做
Apr 13, 2025 am 10:45 AM
在Debian上管理Hadoop日誌,可以遵循以下步驟和最佳實踐:日誌聚合啟用日誌聚合:在yarn-site.xml文件中設置yarn.log-aggregation-enable為true,以啟用日誌聚合功能。配置日誌保留策略:設置yarn.log-aggregation.retain-seconds來定義日誌的保留時間,例如保留172800秒(2天)。指定日誌存儲路徑:通過yarn.n
 centos關機命令行
Apr 14, 2025 pm 09:12 PM
centos關機命令行
Apr 14, 2025 pm 09:12 PM
CentOS 關機命令為 shutdown,語法為 shutdown [選項] 時間 [信息]。選項包括:-h 立即停止系統;-P 關機後關電源;-r 重新啟動;-t 等待時間。時間可指定為立即 (now)、分鐘數 ( minutes) 或特定時間 (hh:mm)。可添加信息在系統消息中顯示。
