

Python Redis資料處理的方法

1. 前言
Redis:Remote Dictionary Server,即:遠端字典服務,Redis 底層使用C 語言編寫,是一款開源的、基於記憶體的 NoSql 資料庫
#由於Redis效能遠超其他資料庫,並且支援叢集、分散式及主從同步等優勢,所以常用於 快取資料、高速讀寫 等場景
2. 準備
我們以在雲端伺服器Centos 7.8 安裝Redis-Server 為例
首先,安裝在雲端伺服器上Redis 資料庫
# 下载epel仓库 yum install epel-release # 安装redis yum install redis
然後,透過vim 指令修改Redis 設定文件,開啟遠端連接,設定連接密碼
設定檔目錄:/etc/redis.conf
bind 改為0.0.0.0,容許外網存取
requirepass設定一個存取密碼
# vim /etc/redis.conf # 1、bing从127.0.0.1修改为:0.0.0.0,开放远程连接 bind 0.0.0.0 # 2、设置密码 requirepass 123456
需要指出的是,為了確保雲端伺服器資料安全,Redis 開放遠端存取的時候,一定要加強密碼
接著,啟動Redis服務,開啟防火牆和端口,配置雲端伺服器安全群組
預設情況下,Redis 服務使用的連接埠號碼是 6379
另外,需要在雲端伺服器安全群組進行配置,確保Redis 資料庫能正常連線
# 启动Redis服务,默认redis端口号是6379 systemctl start redis # 打开防火墙 systemctl start firewalld.service # 开放6379端口 firewall-cmd --zone=public --add-port=6379/tcp --permanent # 配置立即生效 firewall-cmd --reload
完成以上操作,我們就可以透過Redis-CLI 或Redis 用戶端工具進行連接了
最後,要使用Python 操作 Redis,我們需要使用pip 安裝一個依賴
# 安装依赖,便于操作redis pip3 install redis
3. 實戰
在操作Redis 中的資料之前,我們需要利用 Host、連接埠號碼、密碼實例化一個Redis 連線物件
from redis import Redis
class RedisF(object):
def __init__(self):
# 实例化Redis对象
# decode_responses=True,如果不加则写入的为字节类型
# host:远程连接地址
# port:Redis端口号
# password:Redis授权密码
self.redis_obj = Redis(host='139.199.**.**',port=6379,password='123456',decode_responses=True,charset='UTF-8', encoding='UTF-8')接下來我們以操作字串、清單、set 集合、zset 集合、雜湊表、事務為例,講講Python 操作這些資料的方法
1、字串運算
操作字串有兩種方式,操作方法分別是:set() 和 mset()
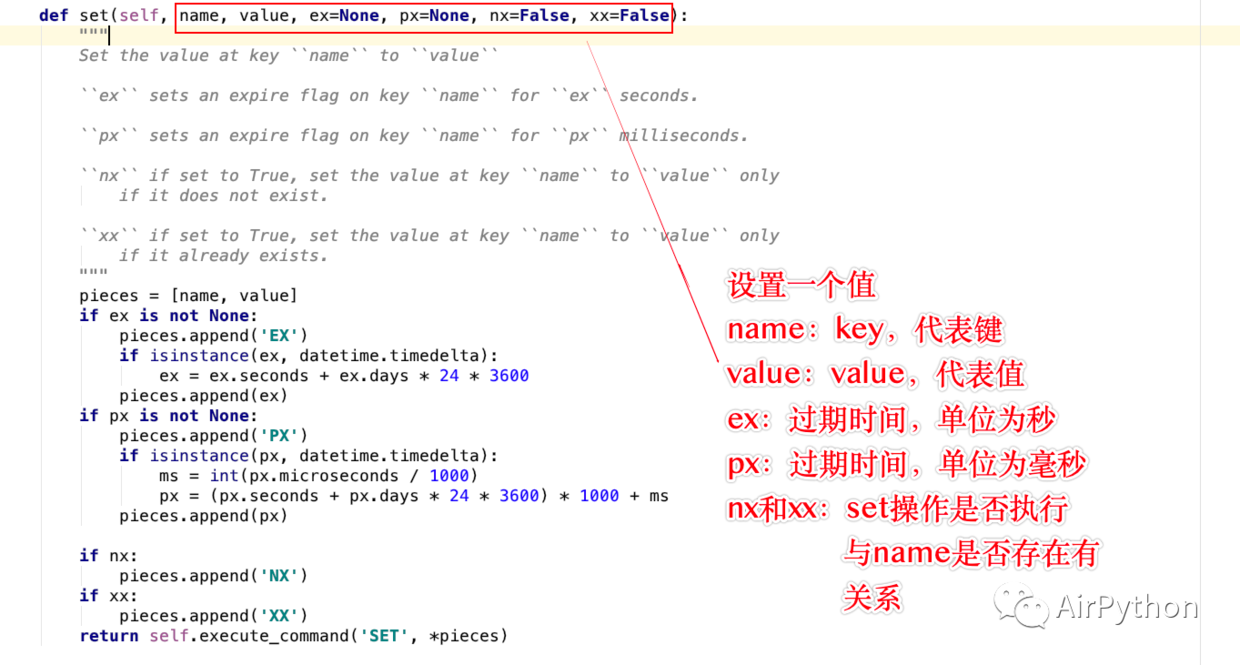
其中:set() 一次只能儲存一個值,參數意義如下
name: key,代表鍵
value:value,待保存的值
ex:過期時間,以秒為單位,如果不設定,則永久不過期;否則,過期則刪除
px:過期時間,以毫秒為單位
nx/xx:set 運算是否執行與name 鍵是否存在有關
取得值與刪除值的操作方法分別為:get(Key)、 delete(Key or Keys)
# set():单字符串操作 # 添加一个值,并设置超时时间为120s self.redis_obj.set('name', 'airpython', ex=120) # get():获取这个值 print(self.redis_obj.get('name')) # delete():删除一个值或多个值 self.redis_obj.delete('name') print(self.redis_obj.get('name'))
對於多值資料的設置,只需要調用mset() 方法,將待插入的資料以鍵值對組成一個字典作為參數即可
同理,Redis 提供了mget()方法,可以一次獲取多個鍵的值
# mset():设置多个值
self.redis_obj.mset({"foo": "foo1", "zoo": "zoo1"})
# mget():获取多个值
result = self.redis_obj.mget("foo", "zoo")
print(result)2、列表操作
Redis 提供了很多方法用於操作列表,其中比較常見的如下:
lpush/rpush:將一個值或多個值插入到列表頭部或尾部,其中,lpush 代表頭部插入;rpush 代表尾部插入資料
lset:透過索引,將值插入到清單對應的位置
linsert:在清單元素前面或後面插入資料
- ##lindex :透過索引取得清單中的某一個元素,其中,0 代表第一個元素;-1 代表最後一個元素
- lrange:透過制定起始位置和結束位置,從清單中取得指定區域的值
- llen:取得清單的長度,如果Key 對應的清單不存在,回傳0 ##lpop:移除並傳回清單中的第一個元素
- rpop:移除並傳回清單中的最後一個元素
- 實例程式碼如下:
def manage_list(self):
"""
操作列表
:return:
"""
# 1、新增一个列表,并左边插入一个数据
# 注意:可以一次加入多个元素,也可以一个个元素的加入
self.redis_obj.lpush('company', '阿里', '腾讯', '百度')
# 2、移除第一个元素
self.redis_obj.lpop("company")
# 3、右边插入数据
self.redis_obj.rpush('company', '字节跳动', '小米')
# 4、移除最后一个元素
self.redis_obj.rpop("company")
# 5、获取列表的长度
self.redis_obj.llen("company")
# 6、通过索引,获取列表中的某一个元素(第二个元素)
print('列表中第二个元素是:', self.redis_obj.lindex("company", 1))
# 7、根据范围,查看列表中所有的值
print(self.redis_obj.lrange('company', 0, -1))3、運算Set 集合
Set 是無序的元素集合,集合中的元素不能重複,Redis 同樣提供了許多方法,以便操作Set 集合
#其中,比較常用的方法如下:
- sadd:新增元素到集合中,已經存在集合中的元素將被忽略,如果集合不存在,則新建一個集合
- scard:傳回集合元素的數量
- smembers:傳回集合中所有元素
- srem :移除集合中一個或多個元素,如果元素不存在則忽略
- sinter:傳回兩個集合的交集,結果仍然是一個集合
- #sunion:傳回兩個集合的並集
- sdiff:以第一個集合參數為標準,傳回兩個集合的差集
- #sunionstore:計算兩個集合的並集,儲存到一個新的集合中
- #sismember:判斷集合中是否存在某個元素
- spop:隨機刪除集合中的一個元素,並傳回
- #具體實例程式碼如下:
def manage_set(self):
"""
操作set集合
:return:
"""
self.redis_obj.delete("fruit")
# 1、sadd:新增元素到集合中
# 添加一个元素:香蕉
self.redis_obj.sadd('fruit', '香蕉')
# 再添加两个元素
self.redis_obj.sadd('fruit', '苹果', '桔子')
# 2、集合元素的数量
print('集合元素数量:', self.redis_obj.scard('fruit'))
# 3、移除一个元素
self.redis_obj.srem("fruit", "桔子")
# 再定义一个集合
self.redis_obj.sadd("fruit_other", "香蕉", "葡萄", "柚子")
# 4、获取两个集合的交集
result = self.redis_obj.sinter("fruit", "fruit_other")
print(type(result))
print('交集为:', result)
# 5、获取两个集合的并集
result = self.redis_obj.sunion("fruit", "fruit_other")
print(type(result))
print('并集为:', result)
# 6、差集,以第一个集合为标准
result = self.redis_obj.sdiff("fruit", "fruit_other")
print(type(result))
print('差集为:', result)
# 7、合并保存到新的集合中
self.redis_obj.sunionstore("fruit_new", "fruit", "fruit_other")
print('新的集合为:', self.redis_obj.smembers('fruit_new'))
# 8、判断元素是否存在集合中
result = self.redis_obj.sismember("fruit", "苹果")
print('苹果是否存在于集合中', result)
# 9、随机从集合中删除一个元素,然后返回
result = self.redis_obj.spop("fruit")
print('删除的元素是:', result)
# 3、集合中所有元素
result = self.redis_obj.smembers('fruit')
print("最后fruit集合包含的元素是:", result)4、操作zset 集合
zset 集合比較普通set 集合,是有序的,zset 集合中的元素包含:值和分數,其中分數用於排序
其中,比较常用的方法如下:
zadd:往集合中新增元素,如果集合不存在,则新建一个集合,然后再插入数据
zrange:通过起始点和结束点,返回集合中的元素值(不包含分数);如果设置withscores=True,则返回结果会带上分数
zscore:获取某一个元素对应的分数
zcard:获取集合中元素个数
zrank:获取元素在集合中的索引
zrem:删除集合中的元素
zcount:通过最小值和最大值,判断分数在这个范围内的元素个数
实践代码如下:
def manage_zset(self):
"""
操作zset集合
:return:
"""
self.redis_obj.delete("fruit")
# 往集合中新增元素:zadd()
# 三个元素分别是:"banana", 1/"apple", 2/"pear", 3
self.redis_obj.zadd("fruit", "banana", 1, "apple", 2, "pear", 3)
# 查看集合中所有元素(不带分数)
result = self.redis_obj.zrange("fruit", 0, -1)
# ['banana', 'apple', 'pear']
print('集合中的元素(不带分数)有:', result)
# 查看集合中所有元素(带分数)
result = self.redis_obj.zrange("fruit", 0, -1, withscores=True)
# [('banana', 1.0), ('apple', 2.0), ('pear', 3.0)]
print('集合中的元素(带分数)有:', result)
# 获取集合中某一个元素的分数
result = self.redis_obj.zscore("fruit", "apple")
print("apple对应的分数为:", result)
# 通过最小值和最大值,判断分数在这个范围内的元素个数
result = self.redis_obj.zcount("fruit", 1, 2)
print("集合中分数大于1,小于2的元素个数有:", result)
# 获取集合中元素个数
count = self.redis_obj.zcard("fruit")
print('集合元素格式:', count)
# 获取元素的值获取索引号
index = self.redis_obj.zrank("fruit", "apple")
print('apple元素的索引为:', index)
# 删除集合中的元素:zrem
self.redis_obj.zrem("fruit", "apple")
print('删除apple元素后,剩余元素为:', self.redis_obj.zrange("fruit", 0, -1))4、操作哈希
哈希表中包含很多键值对,并且每一个键都是唯一的
Redis 操作哈希表,下面这些方法比较常用:
hset:往哈希表中添加一个键值对值
hmset:往哈希表中添加多个键值对值
hget:获取哈希表中单个键的值
hmget:获取哈希表中多个键的值列表
hgetall:获取哈希表中种所有的键值对
hkeys:获取哈希表中所有的键列表
hvals:获取哈表表中所有的值列表
hexists:判断哈希表中,某个键是否存在
hdel:删除哈希表中某一个键值对
hlen:返回哈希表中键值对个数
对应的操作代码如下:
def manage_hash(self):
"""
操作哈希表
哈希:一个键对应一个值,并且键不容许重复
:return:
"""
self.redis_obj.delete("website")
# 1、新建一个key为website的哈希表
# 往里面加入数据:baidu(field),www.baidu.com(value)
self.redis_obj.hset('website', 'baidu', 'www.alibababaidu.com')
self.redis_obj.hset('website', 'google', 'www.google.com')
# 2、往哈希表中添加多个键值对
self.redis_obj.hmset("website", {"tencent": "www.qq.com", "alibaba": "www.taobao.com"})
# 3、获取某一个键的值
result = self.redis_obj.hget("website", 'baidu')
print("键为baidu的值为:", result)
# 4、获取多个键的值
result = self.redis_obj.hmget("website", "baidu", "alibaba")
print("多个键的值为:", result)
# 5、查看hash表中的所有值
result = self.redis_obj.hgetall('website')
print("哈希表中所有的键值对为:", result)
# 6、哈希表中所有键列表
# ['baidu', 'google', 'tencent', 'alibaba']
result = self.redis_obj.hkeys("website")
print("哈希表,所有的键(列表)为:", result)
# 7、哈希表中所有的值列表
# ['www.alibababaidu.com', 'www.google.com', 'www.qq.com', 'www.taobao.com']
result = self.redis_obj.hvals("website")
print("哈希表,所有的值(列表)为:", result)
# 8、判断某一个键是否存在
result = self.redis_obj.hexists("website", "alibaba")
print('alibaba这个键是否存在:', result)
# 9、删除某一个键值对
self.redis_obj.hdel("website", 'baidu')
print('删除baidu键值对后,哈希表的数据包含:', self.redis_obj.hgetall('website'))
# 10、哈希表中键值对个数
count = self.redis_obj.hlen("website")
print('哈希表键值对一共有:', count)5、操作事务管道
Redis 支持事务管道操作,能够将几个操作统一提交执行
操作步骤是:
首先,定义一个事务管道
然后通过事务对象去执行一系列操作
提交事务操作,结束事务操作
下面通过一个简单的例子来说明:
def manage_steps(self):
"""
执行事务操作
:return:
"""
# 1、定义一个事务管道
self.pip = self.redis_obj.pipeline()
# 定义一系列操作
self.pip.set('age', 18)
# 增加一岁
self.pip.incr('age')
# 减少一岁
self.pip.decr('age')
# 执行上面定义3个步骤的事务操作
self.pip.execute()
# 判断
print('通过上面一些列操作,年龄变成:', self.redis_obj.get('age'))以上是Python Redis資料處理的方法的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 PHP和Python:解釋了不同的範例
Apr 18, 2025 am 12:26 AM
PHP和Python:解釋了不同的範例
Apr 18, 2025 am 12:26 AM
PHP主要是過程式編程,但也支持面向對象編程(OOP);Python支持多種範式,包括OOP、函數式和過程式編程。 PHP適合web開發,Python適用於多種應用,如數據分析和機器學習。
 在PHP和Python之間進行選擇:指南
Apr 18, 2025 am 12:24 AM
在PHP和Python之間進行選擇:指南
Apr 18, 2025 am 12:24 AM
PHP適合網頁開發和快速原型開發,Python適用於數據科學和機器學習。 1.PHP用於動態網頁開發,語法簡單,適合快速開發。 2.Python語法簡潔,適用於多領域,庫生態系統強大。
 PHP和Python:深入了解他們的歷史
Apr 18, 2025 am 12:25 AM
PHP和Python:深入了解他們的歷史
Apr 18, 2025 am 12:25 AM
PHP起源於1994年,由RasmusLerdorf開發,最初用於跟踪網站訪問者,逐漸演變為服務器端腳本語言,廣泛應用於網頁開發。 Python由GuidovanRossum於1980年代末開發,1991年首次發布,強調代碼可讀性和簡潔性,適用於科學計算、數據分析等領域。
 sublime怎麼運行代碼python
Apr 16, 2025 am 08:48 AM
sublime怎麼運行代碼python
Apr 16, 2025 am 08:48 AM
在 Sublime Text 中運行 Python 代碼,需先安裝 Python 插件,再創建 .py 文件並編寫代碼,最後按 Ctrl B 運行代碼,輸出會在控制台中顯示。
 notepad 怎麼運行python
Apr 16, 2025 pm 07:33 PM
notepad 怎麼運行python
Apr 16, 2025 pm 07:33 PM
在 Notepad 中運行 Python 代碼需要安裝 Python 可執行文件和 NppExec 插件。安裝 Python 並為其添加 PATH 後,在 NppExec 插件中配置命令為“python”、參數為“{CURRENT_DIRECTORY}{FILE_NAME}”,即可在 Notepad 中通過快捷鍵“F6”運行 Python 代碼。
 Golang vs. Python:性能和可伸縮性
Apr 19, 2025 am 12:18 AM
Golang vs. Python:性能和可伸縮性
Apr 19, 2025 am 12:18 AM
Golang在性能和可擴展性方面優於Python。 1)Golang的編譯型特性和高效並發模型使其在高並發場景下表現出色。 2)Python作為解釋型語言,執行速度較慢,但通過工具如Cython可優化性能。
 Python與C:學習曲線和易用性
Apr 19, 2025 am 12:20 AM
Python與C:學習曲線和易用性
Apr 19, 2025 am 12:20 AM
Python更易學且易用,C 則更強大但複雜。 1.Python語法簡潔,適合初學者,動態類型和自動內存管理使其易用,但可能導致運行時錯誤。 2.C 提供低級控制和高級特性,適合高性能應用,但學習門檻高,需手動管理內存和類型安全。
 Golang vs. Python:主要差異和相似之處
Apr 17, 2025 am 12:15 AM
Golang vs. Python:主要差異和相似之處
Apr 17, 2025 am 12:15 AM
Golang和Python各有优势:Golang适合高性能和并发编程,Python适用于数据科学和Web开发。Golang以其并发模型和高效性能著称,Python则以简洁语法和丰富库生态系统著称。
