

MySQL中的隨機抽取如何實現

1. 引言
現在有一個需求是從一個單字表每次隨機選取三個單字。
這個表的建表語句和如下所示:
mysql> Create table 'words'(
'id' int(11) not null auto_increment;
'word' varchar(64) default null;
primary key ('id')
) ENGINE=InnoDB;然後我們向其中插入10000行資料。接下來我們來看看如何從中隨機選出3個單字。
2. 記憶體臨時表
首先,我們通常會想到用order by rand()來實作這個邏輯:
mysql> select word from words order by rand() limit 3;
雖然這句話很簡單,但執行流程則比較複雜。我們使用explain來看看語句的執行情況:

Extra欄位中Using temporary表示需要使用臨時表,Using filesort表示需要進行排序。也就是需要進行排序操作。
對於InnoDB表來說,執行全字段排序能夠減少對於磁碟的訪問,所以會被優先選擇。
而對於記憶體表來說,回表過程只是簡單地根據資料行的位置,直接存取記憶體得到數據,根本不會導致多存取磁碟。所以這時MySQL會優選選擇rowid排序。
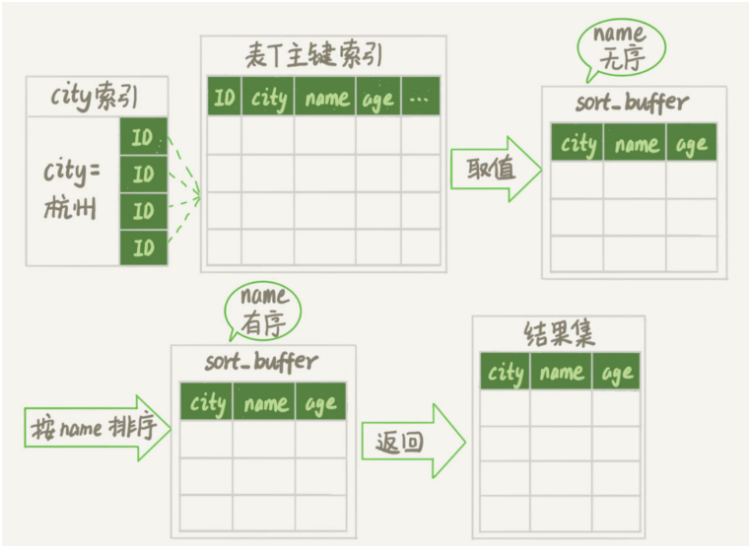
我們接下來再來梳理下這條語句的執行流程:
建立一個臨時表,這個表使用memory引擎,表裡有兩個字段,第一個字段是double類型,記為R,第二個字段是varchar(64)類型,記為W。而這個表沒有索引。
從words表中,按主鍵順序取出所有的word。對於每個word,呼叫rand()函數隨機產生一個大於0小於1的隨機小數,並將這個隨機小數和word分別存入臨時表的R和W欄位。
接下來就是依照欄位R進行排序
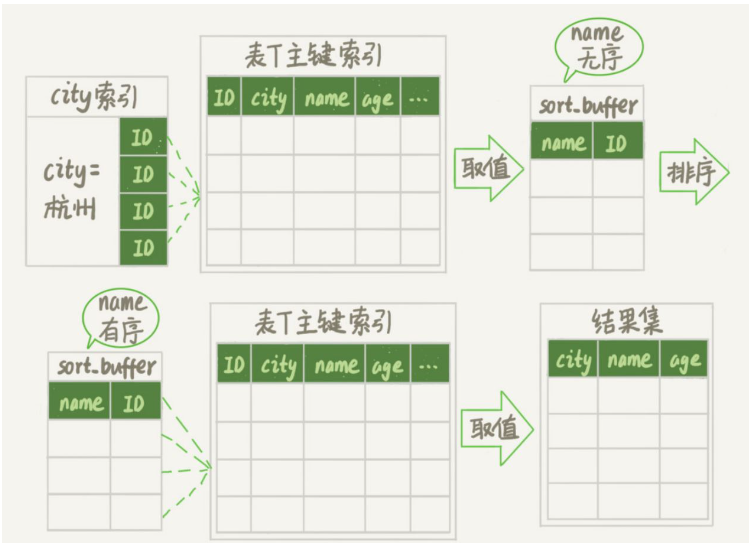
初始化sort_buffer。 sort_buffer包括一個double類型和一個整數欄位。
從記憶體臨時表中一行行取出R值和位置信息,分別存入sort_buffer的兩個欄位裡。
sort_buffer依照R值進行排序
#排序完成後,取出前三個結果的位置信息,到記憶體臨時表中取出相應的word,回傳給客戶端。
流程示意圖如下所示:
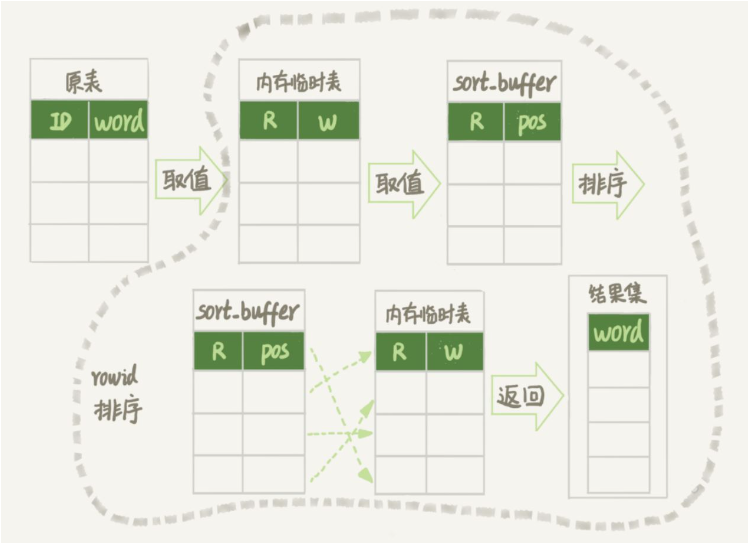
#上面講的位置信息,其實就是行所在的位置,也就是我們之前說的rowid。
#對於InnoDB引擎來說,對於有沒有主鍵表來說有兩種處理方式:
對於有主鍵的InnoDB表來說,這個rowid就是主鍵id
對於沒有主鍵的InnoDB表來說,這個rowid是由系統產生的,用來識別不同行。
因此,order by randn()使用了記憶體臨時表,記憶體臨時表的排序方法用的是rowid排序方法。
3. 磁碟臨時表
不是所有的臨時表都是記憶體臨時表。 tmp_table_size這個配置限制了記憶體臨時表的大小,如果超過了這個大小,就會使用磁碟臨時表。 InnoDB引擎就是預設使用磁碟暫存表。
4. 優先隊列排序演算法
在MySQL5.6之後,引入了優先隊列排序演算法,這種演算法是不需要使用臨時檔案的。而原本的歸併排序演算法則是需要使用臨時檔案。
因為當你使用歸併演算法的時候,其實你只需要得到前3,但是你是用完歸併排序,那已經整體有序了,造成了資源的浪費。
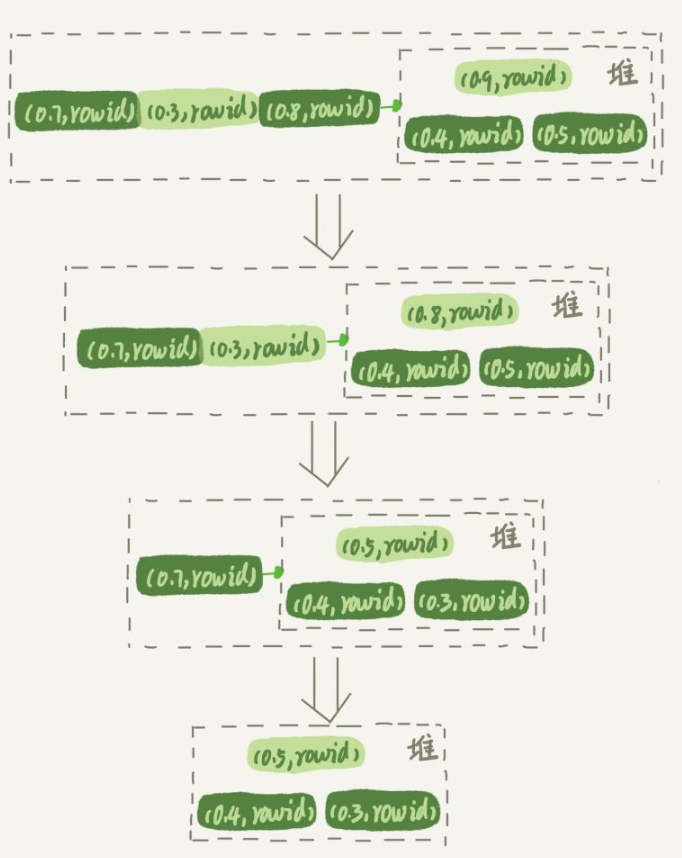
而優先佇列排序演算法則可以只取到前三,執行流程如下:
對於這10000個準備排序的(R,rowid),先取前三行,建構成一個堆,並且將最大的值放在堆頂;
取下一行(R’,rowid’),跟當前堆裡面最大的R比較,如果R’小於R,則把(R,rowid)從堆中去掉,換成(R’,rowid’)。
不斷重複上面的過程。
流程如下圖所示:
#但是當limit的數比較大時,維護堆比較困難,所以又會使用歸併排序演算法。
以上是MySQL中的隨機抽取如何實現的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

AI Hentai Generator
免費產生 AI 無盡。

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)
熱門話題



 mysql用戶和數據庫的關係
Apr 08, 2025 pm 07:15 PM
mysql用戶和數據庫的關係
Apr 08, 2025 pm 07:15 PM
MySQL 數據庫中,用戶和數據庫的關係通過權限和表定義。用戶擁有用戶名和密碼,用於訪問數據庫。權限通過 GRANT 命令授予,而表由 CREATE TABLE 命令創建。要建立用戶和數據庫之間的關係,需創建數據庫、創建用戶,然後授予權限。
 RDS MySQL 與 Redshift 零 ETL 集成
Apr 08, 2025 pm 07:06 PM
RDS MySQL 與 Redshift 零 ETL 集成
Apr 08, 2025 pm 07:06 PM
數據集成簡化:AmazonRDSMySQL與Redshift的零ETL集成高效的數據集成是數據驅動型組織的核心。傳統的ETL(提取、轉換、加載)流程複雜且耗時,尤其是在將數據庫(例如AmazonRDSMySQL)與數據倉庫(例如Redshift)集成時。然而,AWS提供的零ETL集成方案徹底改變了這一現狀,為從RDSMySQL到Redshift的數據遷移提供了簡化、近乎實時的解決方案。本文將深入探討RDSMySQL零ETL與Redshift集成,闡述其工作原理以及為數據工程師和開發者帶來的優勢。
 mysql 是否要付費
Apr 08, 2025 pm 05:36 PM
mysql 是否要付費
Apr 08, 2025 pm 05:36 PM
MySQL 有免費的社區版和收費的企業版。社區版可免費使用和修改,但支持有限,適合穩定性要求不高、技術能力強的應用。企業版提供全面商業支持,適合需要穩定可靠、高性能數據庫且願意為支持買單的應用。選擇版本時考慮的因素包括應用關鍵性、預算和技術技能。沒有完美的選項,只有最合適的方案,需根據具體情況謹慎選擇。
 如何針對高負載應用程序優化 MySQL 性能?
Apr 08, 2025 pm 06:03 PM
如何針對高負載應用程序優化 MySQL 性能?
Apr 08, 2025 pm 06:03 PM
MySQL數據庫性能優化指南在資源密集型應用中,MySQL數據庫扮演著至關重要的角色,負責管理海量事務。然而,隨著應用規模的擴大,數據庫性能瓶頸往往成為製約因素。本文將探討一系列行之有效的MySQL性能優化策略,確保您的應用在高負載下依然保持高效響應。我們將結合實際案例,深入講解索引、查詢優化、數據庫設計以及緩存等關鍵技術。 1.數據庫架構設計優化合理的數據庫架構是MySQL性能優化的基石。以下是一些核心原則:選擇合適的數據類型選擇最小的、符合需求的數據類型,既能節省存儲空間,又能提升數據處理速度
 MySQL 中的查詢優化對於提高數據庫性能至關重要,尤其是在處理大型數據集時
Apr 08, 2025 pm 07:12 PM
MySQL 中的查詢優化對於提高數據庫性能至關重要,尤其是在處理大型數據集時
Apr 08, 2025 pm 07:12 PM
1.使用正確的索引索引通過減少掃描的數據量來加速數據檢索select*fromemployeeswherelast_name='smith';如果多次查詢表的某一列,則為該列創建索引如果您或您的應用根據條件需要來自多個列的數據,則創建複合索引2.避免選擇*僅選擇那些需要的列,如果您選擇所有不需要的列,這只會消耗更多的服務器內存並導致服務器在高負載或頻率時間下變慢例如,您的表包含諸如created_at和updated_at以及時間戳之類的列,然後避免選擇*,因為它們在正常情況下不需要低效查詢se
 mysql怎麼複製粘貼
Apr 08, 2025 pm 07:18 PM
mysql怎麼複製粘貼
Apr 08, 2025 pm 07:18 PM
MySQL 中的複制粘貼包含以下步驟:選擇數據,使用 Ctrl C(Windows)或 Cmd C(Mac)複製;在目標位置右鍵單擊,選擇“粘貼”或使用 Ctrl V(Windows)或 Cmd V(Mac);複製的數據將插入到目標位置,或替換現有數據(取決於目標位置是否已存在數據)。
 mysql怎麼查看
Apr 08, 2025 pm 07:21 PM
mysql怎麼查看
Apr 08, 2025 pm 07:21 PM
通過以下命令查看 MySQL 數據庫:連接到服務器:mysql -u 用戶名 -p 密碼運行 SHOW DATABASES; 命令獲取所有現有數據庫選擇數據庫:USE 數據庫名;查看表:SHOW TABLES;查看表結構:DESCRIBE 表名;查看數據:SELECT * FROM 表名;
 了解 ACID 屬性:可靠數據庫的支柱
Apr 08, 2025 pm 06:33 PM
了解 ACID 屬性:可靠數據庫的支柱
Apr 08, 2025 pm 06:33 PM
數據庫ACID屬性詳解ACID屬性是確保數據庫事務可靠性和一致性的一組規則。它們規定了數據庫系統處理事務的方式,即使在系統崩潰、電源中斷或多用戶並發訪問的情況下,也能保證數據的完整性和準確性。 ACID屬性概述原子性(Atomicity):事務被視為一個不可分割的單元。任何部分失敗,整個事務回滾,數據庫不保留任何更改。例如,銀行轉賬,如果從一個賬戶扣款但未向另一個賬戶加款,則整個操作撤銷。 begintransaction;updateaccountssetbalance=balance-100wh
