

芯東西(公眾號:aichip001)
#作者 | ZeR0
#編輯 | 漠影
#一種重寫方式是:AI大模型競賽正掀起前所未有的熱潮,根據5月30日芯東西報道,ChatGPT的崛起是此次競賽的關鍵驅動力。在這場競賽中,速度是搶得先發優勢的關鍵,從模型訓練到落地部署,都對更高效能的AI晶片提出迫切需求。
今年3月,AI視覺感知晶片研發及基礎算力平台公司愛芯元智推出了第三代高算力、高能效比的SoC晶片AX650N。愛芯元智聯合創始人、副總裁劉建偉在近日接受芯東西等媒體採訪時談道,AX650N晶片在跑Transformer時優勢明顯,而Transformer是當前大模型普遍採用的結構。
Transformer最初被用來處理自然語言處理領域的任務,逐漸向電腦視覺領域拓展,並展現出在越來越多視覺任務中取代傳統主流電腦視覺演算法CNN的潛能。如何在端側、邊緣側高效部署Transformer,隨之成為越來越多有大模型部署需求的使用者選擇平台的核心考量。
相比在雲端使用GPU部署Transformer大模型,愛芯元智認為,在邊緣側、端側部署Transformer的最大挑戰來自功耗,這使得愛芯元智兼具高性能和低功耗的混合精度NPU成為端側和邊緣側部署Transformer的首選平台。
數據顯示,在愛芯元智AX650N平台上運行主流的視覺模型Swin Transformer(SwinT),性能高達361FPS,精度高達80.45%,而功耗低至199FPS/W,這在落地部署中很有競爭力。
一、兼具高算力與高能效比,已適配多種Transformer模型
#AX650N晶片是繼AX620、AX630系列後,愛芯元智推出的另一款高性能智慧視覺晶片。
這款SoC採用異構多核心設計,整合了8核心A55 CPU、43.2TOPs@INT4或10.8TOPs@INT8高算力的NPU、支援8K@30fps的ISP,以及H.264、H.265編解碼的VPU。
介面方面,AX650N支援64bit LPDDR4x,多路MIPI輸入,千兆Ethernet、USB以及HDMI 2.0b輸出,並支援32路1080p@30fps解碼。
針對大模型在邊緣側、端側的部署,AX650N具有高效能、高精度、低功耗、易部署的優勢。
具體來看,愛芯元智AX650N在運行SwinT時,361幀的高性能可媲美汽車自動駕駛領域基於GPU的高端域控SoC;80.45%的高精度高於市面平均水平;199FPS/W速度反映出低功耗,比目前基於GPU的高階域控SoC有著數倍的優勢。

愛芯元智解釋說,早期邊緣側、端側客戶比較看重算力有多少T,但這是一個間接數據,用戶最終關心的是在實際業務中模型能跑得多快,以及部署成本和使用成本有多低。
對此,AX650N支援低位元混合精度,使用者如果採用INT4,則可以大幅減少記憶體和頻寬佔用率,有效控制端側邊緣側部署的成本。
目前AX650N已適配ViT/DeiT、Swin/SwinV2、DETR等Transformer模型,在DINOv2也能跑到30幀以上,這使得用戶進行檢測、分類、分割等操作更加方便。 AX650N-based products have already been applied in important computer vision scenarios such as smart cities, smart education, and intelligent manufacturing.。

二、部署大模型易上手,可運行GitHub原版模型
愛芯元智也打造了新一代AI工具鏈Pulsar2。此工具鏈包含模型轉換、離線量化、模型編譯、異構調度四合一功能,進一步強化了網路模型高效部署的需求,在針對NPU架構進行了深度最佳化的同時,也擴展了算子&模型支持的能力及範圍,以及對Transformer結構網路的支援。
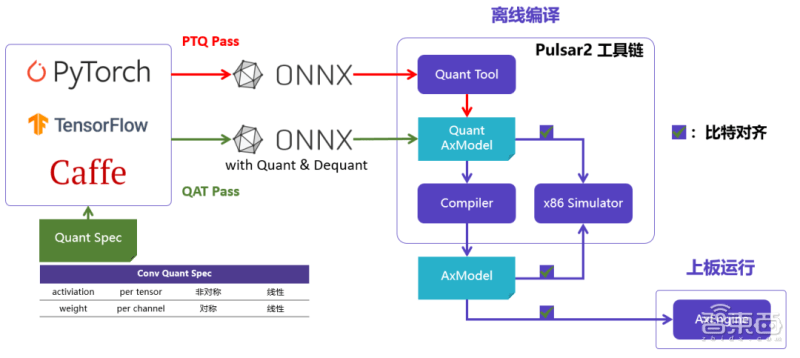
愛芯元智在實務上發現,市面上宣傳晶片能跑SwinT的公司,通常需要對模型做一些修改,修改後可能會引發一系列問題,給用戶帶來更多的不便。
先前類似於SwinT的視覺類Transformer模型大多部署在雲端伺服器上,原因是GPU對於MHA結構運算支援更友好,反而邊緣側/端側AI晶片由於其架構限制,為了確保CNN結構的模型效率更好,基本上沒有對MHA結構做過太多效能優化,甚至需要修改網路結構才能勉強部署。
而AX650N具有部署方便的特性。您可以在愛芯元智平台上有效地運行GitHub上的原版模型,無需對其進行修改,也不需要進行QAT重新訓練。
「我們的用戶回饋,我們的平台是目前看到對Transformer支援最好的一個平台,也看到在我們這個平台來落地大模型的可能性。」劉建偉談道,客戶能夠體會到AX650N作為AI算力平台,最終落地效果更好用、更易用,對場景的適應性較強,上手速度也比較快,大幅提升了用戶的效率,縮短量產週期。
愛芯元智收集到的客戶回饋顯示,拿到愛芯元智的開發板和文件後,基本上1小時就能完成demo的複現以及運行私有網絡模型。
AX650N晶片能夠迅速適應新出現的網路結構,這要歸功於在硬體和軟體設計方面的一定靈活性和可編程性的保持。接下來,愛芯元智AX650N將針對Transformer結構進行持續最佳化,探索多模態大模型等較多的Transformer大模型。
愛芯元智也將基於AX650N推出AXera-Pi Pro開發板,並在GitHub放上更豐富的資料及AI範例,以便開發者快速探索更豐富的產品應用。
三、視覺類別應用場景已對Transformer模型產生迫切需求
在愛芯元智看來,在邊緣側或端側部署視覺大模型,有助於解決長尾場景下AI智能應用投入太高的問題。
以前的河道垃圾監測方式是發現河道上的垃圾後,需要先進行資料收集、標註,然後進行模型訓練。如果新垃圾出現在河道中,而這種垃圾之前沒有被資料標註和訓練模型覆蓋,那麼模型就可能無法辨識它。從頭重新訓練又費時耗力。
而Transformer大模型具備語意理解能力,擁有比傳統CNN模型更強的通用性,不需要預先知道所有的複雜視覺場景,就能理解並執行更廣泛的下游任務。使用無監督訓練的預訓練大模型,可以辨識出以前從未見過的新垃圾。
愛芯元智告訴芯東西,目前凡是用攝影機去捕捉畫面的應用場景,都已經開始對Transformer大模型產生比較迫切的需求,具體落地速度則取決於各細分領域客戶自身的研發及資源投入狀況。
從晶片架構設計角度來看,要讓Transformer模型更快部署在邊緣側或端側,一方面要設法降低大模型頻寬的使用情況,另一方面需針對Transformer的結構進行最佳化。愛芯元智相關負責人稱,AX650N在實際部署中累積的工程經驗將迭代到下一代晶片平台中,讓Transformer模型跑得更快更好,相比其他同行有一定先發優勢。
「這也是為什麼說愛芯的晶片平台是Transformer落地的最佳選擇,因為大家在做模型變小的過程中,一定是想看在端側跑的效果,我們有這樣的平台可以做這樣閉環的試驗。
為了進一步優化Transformer推理效果,愛芯元智將聚焦於如何讓硬體高效讀取離散數據,以及讓配套的計算能夠和數據讀取匹配起來。此外,愛芯元智也正在嘗試用4bit來解決模型參數量大的問題,並探索一些稀疏化或混合專家系統(MOE、Mixture of Experts)模型的支援。
結語:高效能AI晶片鑄就大模型部署基石
#從2020年實現首顆高性能AI視覺晶片AX630A量產,2021年點亮第二代自研邊緣側智慧晶片AX620A,再到最新發布的第三代AX650N晶片,愛芯元智透過持續推出高算力、高能效比的AI視覺晶片,滿足端側與邊緣側的AI應用需求。
愛芯元智創辦人、董事長兼執行長仇肖莘博士說,人工智慧技術發展不斷催生新機遇,此前的幾波技術浪潮曾推動愛芯元智在視覺處理、汽車電子等晶片技術上的進展,近期大模型的爆發則為愛芯過去幾年在端側、邊緣側的堅持探索創造了新機會。
而愛芯相關研發和落地規劃都劍指一個目標,即用戶或潛在用戶一想到Transformer,就能想到愛芯元智,進而在愛芯元智的AI算力平台上開發更多基於Transformer模型的應用,最終加速大模型及智慧應用在端側和邊緣側落地的節奏。
反過來,更多部署經驗的沉澱,也會推動愛芯元智的晶片與軟體持續進化,透過提供更高性能、更好用易用的工具,助力演算法工程師進一步推開Transformer模型創新應用的想像力之門。
以上是把大模型裝進攝影機,需要怎樣的AI晶片?愛芯元智的答案是AX650N的詳細內容。更多資訊請關注PHP中文網其他相關文章!






















