
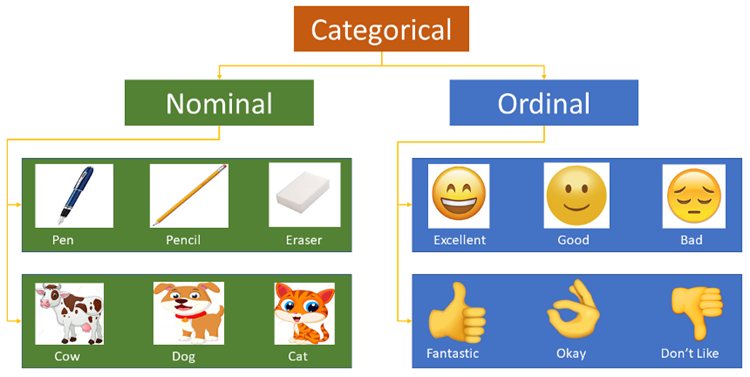
Categorical features refer to characteristics with values that fall within a finite set of categories, such as occupation and blood type.。它的原始輸入通常是字串形式,大多數演算法模型不接受數值型特徵的輸入,針對數值型的類別特徵會被當成數值型特徵,從而造成訓練的模型產生錯誤。
Label Encoding是使用字典的方式,將每個類別標籤與不斷增加的整數相關聯,即產生一個名為class _的實例數組的索引。
Scikit-learn中的LabelEncoder是用來對分類型特徵值進行編碼,也就是對不連續的數值或文字進行編碼。其中包含以下常用方法:
fit(y) :fit可看做一本空字典,y可看作要塞到字典中的字。
fit_transform(y):相當於先進行fit再進行transform,也就是把y塞到字典中去以後再進行transform得到索引值。
inverse_transform(y):根據索引值y取得原始資料。
transform(y) :將y轉換成索引值。
from sklearn.preprocessing import LabelEncoder le = LabelEncoder() city_list = ["paris", "paris", "tokyo", "amsterdam"] le.fit(city_list) print(le.classes_) # 输出为:['amsterdam' 'paris' 'tokyo'] city_list_le = le.transform(city_list) # 进行Encode print(city_list_le) # 输出为:[1 1 2 0] city_list_new = le.inverse_transform(city_list_le) # 进行decode print(city_list_new) # 输出为:['paris' 'paris' 'tokyo' 'amsterdam']
多列資料編碼方式:
import pandas as pd
from sklearn.preprocessing import LabelEncoder
df = pd.DataFrame({
'pets': ['cat', 'dog', 'cat', 'monkey', 'dog', 'dog'],
'owner': ['Champ', 'Ron', 'Brick', 'Champ', 'Veronica', 'Ron'],
'location': ['San_Diego', 'New_York', 'New_York', 'San_Diego', 'San_Diego',
'New_York']
})
d = {}
le = LabelEncoder()
cols_to_encode = ['pets', 'owner', 'location']
for col in cols_to_encode:
df_train[col] = le.fit_transform(df_train[col])
d[col] = le.classes_Pandas的factorize()可以將Series中的標稱型資料對應稱為一組數字,相同的標稱型映射為相同的數字。 The function factorize returns a tuple containing two elements.。第一個元素是一個array,其中的元素是標稱型元素映射為的數字;第二個元素是Index類型,其中的元素是所有標稱型元素,沒有重複。
import numpy as np import pandas as pd df = pd.DataFrame(['green','bule','red','bule','green'],columns=['color']) pd.factorize(df['color']) #(array([0, 1, 2, 1, 0], dtype=int64),Index(['green', 'bule', 'red'], dtype='object')) pd.factorize(df['color'])[0] #array([0, 1, 2, 1, 0], dtype=int64) pd.factorize(df['color'])[1] #Index(['green', 'bule', 'red'], dtype='object')
Label Encoding只是將文字轉換為數值,並沒有解決文字特徵的問題:所有的標籤都變成了數字,演算法模型直接將根據其距離來考慮相似的數字,而不考慮標籤的具體含義。經過此方法處理後的資料可適用於支援類別屬性的演算法模型,例如LightGBM。
Ordinal Encoding即最簡單的一種思路,對於一個具有m個category的Feature,我們將其對應地映射到[0,m-1 ] 的整數。當然 Ordinal Encoding 更適用於 Ordinal Feature,即各個特徵有內在的順序。例如對於”學歷”這樣的類別,”學士”、”碩士”、”博士” 可以很自然地編碼成 [0,2],因為它們內在就含有這樣的邏輯順序。但如果對於「顏色」這樣的類別,「藍色」、「綠色」、「紅色」分別編碼成[0,2]是不合理的,因為我們並沒有理由認為「藍色」和「綠色」的差距比「藍色」和「紅色」的差距對於特徵的影響是不同的。
ord_map = {'Gen 1': 1, 'Gen 2': 2, 'Gen 3': 3, 'Gen 4': 4, 'Gen 5': 5, 'Gen 6': 6}
df['GenerationLabel'] = df['Generation'].map(gord_map)在實際的機器學習的應用任務中,特徵有時候並不總是連續值,有可能是一些分類值,如性別可分為male和female。在機器學習任務中,對於這樣的特徵,通常我們需要對其進行特徵數字化,例如有以下三個特徵屬性:
性別:[“male”,”female” ]
地區:[“Europe”,”US”,”Asia”]
瀏覽器:[“Firefox”,”Chrome ”,”Safari”,“Internet Explorer”]
對於某一個樣本,如[“male”,”US”,“Internet Explorer”],我們需要將這個分類值的特徵數位化,最直接的方法,我們可以採用序列化的方式:[0,1,3]。儘管數據被轉換為數位形式,但我們的分類器仍無法直接使用上述數據。因為,分類器往往預設資料是連續的,而且是有序的。依照上述的表示,數字並不是有序的,而是隨機分配的。這樣的特徵處理並不能直接放入機器學習演算法中。
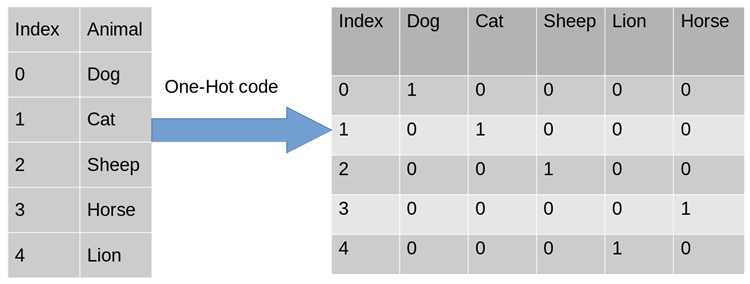
為了解決上述問題,採用獨熱編碼(One-Hot Encoding)是其中一個可能的解決方案。獨熱編碼,又稱為一位有效編碼。其方法是使用N位狀態暫存器來對N個狀態進行編碼,每個狀態都由他獨立的暫存器位,並且在任意時候,其中只有一位有效。獨熱編碼將每個特徵轉換成了m個二元特徵,其中m為該特徵的可能取值數量。並且,這些特徵互斥,每次只有一個啟動。因此,資料會變成稀疏的。
對於上述的問題,性別的屬性是二維的,同理,地區是三維的,瀏覽器則是四維的,這樣,我們可以採用One-Hot編碼的方式對上述的樣本[ “male”,”US”,“Internet Explorer”]編碼,male則對應[1,0],同理US對應[0,1,0],Internet Explorer對應[0,0,0,1 ]。則完整的特徵數位化的結果為:[1,0,0,1,0,0,0,0,1]。
為什麼可以使用One-Hot Encoding?
使用one-hot编码,将离散特征的取值扩展到了欧式空间,离散特征的某个取值就对应欧式空间的某个点。在回归,分类,聚类等机器学习算法中,特征之间距离的计算或相似度的计算是非常重要的,而我们常用的距离或相似度的计算都是在欧式空间的相似度计算,计算余弦相似性,也是基于的欧式空间。
使用One-Hot编码对离散型特征进行处理可以使得特征之间的距离计算更加准确。比如,有一个离散型特征,代表工作类型,该离散型特征,共有三个取值,不使用one-hot编码,计算出来的特征的距离是不合理。那如果使用one-hot编码,显得更合理。
独热编码优缺点
优点:独热编码解决了分类器不好处理属性数据的问题,在一定程度上也起到了扩充特征的作用。它的值只有0和1,不同的类型存储在垂直的空间。
缺点:当类别的数量很多时,特征空间会变得非常大。在这种情况下,一般可以用PCA(主成分分析)来减少维度。在实际应用中,One-Hot Encoding与PCA结合的方法也非常实用。
One-Hot Encoding的使用场景
独热编码用来解决类别型数据的离散值问题。将离散型特征进行one-hot编码的作用,是为了让距离计算更合理,但如果特征是离散的,并且不用one-hot编码就可以很合理的计算出距离,那么就没必要进行one-hot编码,比如,该离散特征共有1000个取值,我们分成两组,分别是400和600,两个小组之间的距离有合适的定义,组内的距离也有合适的定义,那就没必要用one-hot 编码。
树结构方法,如随机森林、Bagging和Boosting等,在特征处理方面不需要进行标准化操作。对于决策树来说,one-hot的本质是增加树的深度,决策树是没有特征大小的概念的,只有特征处于他分布的哪一部分的概念。
基于Scikit-learn 的one hot encoding
LabelBinarizer:将对应的数据转换为二进制型,类似于onehot编码,这里有几点不同:
可以处理数值型和类别型数据
输入必须为1D数组
可以自己设置正类和父类的表示方式
from sklearn.preprocessing import LabelBinarizer lb = LabelBinarizer() city_list = ["paris", "paris", "tokyo", "amsterdam"] lb.fit(city_list) print(lb.classes_) # 输出为:['amsterdam' 'paris' 'tokyo'] city_list_le = lb.transform(city_list) # 进行Encode print(city_list_le) # 输出为: # [[0 1 0] # [0 1 0] # [0 0 1] # [1 0 0]] city_list_new = lb.inverse_transform(city_list_le) # 进行decode print(city_list_new) # 输出为:['paris' 'paris' 'tokyo' 'amsterdam']
OneHotEncoder只能对数值型数据进行处理,需要先将文本转化为数值(Label encoding)后才能使用,只接受2D数组:
import pandas as pd
from sklearn.preprocessing import LabelEncoder
from sklearn.preprocessing import OneHotEncoder
def LabelOneHotEncoder(data, categorical_features):
d_num = np.array([])
for f in data.columns:
if f in categorical_features:
le, ohe = LabelEncoder(), OneHotEncoder()
data[f] = le.fit_transform(data[f])
if len(d_num) == 0:
d_num = np.array(ohe.fit_transform(data[[f]]))
else:
d_num = np.hstack((d_num, ohe.fit_transform(data[[f]]).A))
else:
if len(d_num) == 0:
d_num = np.array(data[[f]])
else:
d_num = np.hstack((d_num, data[[f]]))
return d_num
df = pd.DataFrame([
['green', 'Chevrolet', 2017],
['blue', 'BMW', 2015],
['yellow', 'Lexus', 2018],
])
df.columns = ['color', 'make', 'year']
df_new = LabelOneHotEncoder(df, ['color', 'make', 'year'])基于Pandas的one hot encoding
其实如果我们跳出 scikit-learn, 在 pandas 中可以很好地解决这个问题,用 pandas 自带的get_dummies函数即可
import pandas as pd
df = pd.DataFrame([
['green', 'Chevrolet', 2017],
['blue', 'BMW', 2015],
['yellow', 'Lexus', 2018],
])
df.columns = ['color', 'make', 'year']
df_processed = pd.get_dummies(df, prefix_sep="_", columns=df.columns[:-1])
print(df_processed)get_dummies的优势在于:
本身就是 pandas 的模块,所以对 DataFrame 类型兼容很好
不管你列是数值型还是字符串型,都可以进行二值化编码
能够根据指令,自动生成二值化编码后的变量名
get_dummies虽然有这么多优点,但毕竟不是 sklearn 里的transformer类型,所以得到的结果得手动输入到 sklearn 里的相应模块,也无法像 sklearn 的transformer一样可以输入到pipeline中进行流程化地机器学习过程。
将类别特征替换为训练集中的计数(一般是根据训练集来进行计数,属于统计编码的一种,统计编码,就是用类别的统计特征来代替原始类别,比如类别A在训练集中出现了100次则编码为100)。这个方法对离群值很敏感,所以结果可以归一化或者转换一下(例如使用对数变换)。未知类别可以替换为1。
频数编码使用频次替换类别。有些变量的频次可能是一样的,这将导致碰撞。尽管可能性不是非常大,没法说这是否会导致模型退化,不过原则上我们不希望出现这种情况。
import pandas as pd
data_count = data.groupby('城市')['城市'].agg({'频数':'size'}).reset_index()
data = pd.merge(data, data_count, on = '城市', how = 'left')目标编码(target encoding),亦称均值编码(mean encoding)、似然编码(likelihood encoding)、效应编码(impact encoding),是一种能够对高基数(high cardinality)自变量进行编码的方法 (Micci-Barreca 2001) 。
如果某一个特征是定性的(categorical),而这个特征的可能值非常多(高基数),那么目标编码(Target encoding)是一种高效的编码方式。在实际应用中,这类特征工程能极大提升模型的性能。
一般情况下,针对定性特征,我们只需要使用sklearn的OneHotEncoder或LabelEncoder进行编码。
LabelEncoder能夠接收不規則的特徵列,並將其轉換為從0到n-1的整數值(假設一共有n種不同的類別);OneHotEncoder則能透過啞編碼,製作出一個m*n的稀疏矩陣(假設資料一共有m行,具體的輸出矩陣格式是否稀疏可以由sparse參數控制)。
"Cardinality" of a qualitative characteristic refers to the total number of distinct possible values that the characteristic can take.。在高基數(high cardinality)的定性特徵面前,這些資料預處理的方法往往得不到令人滿意的結果。
高基數定性特徵的例子:IP位址、電子郵件網域名稱、城市名稱、家庭住址、街道、產品號碼。
主要原因:
LabelEncoder編碼高基數定性特徵,雖然只需要一列,但是每個自然數都有不同的重要意義,對於y而言線性不可分。使用簡單模型,容易欠擬合(underfit),無法完全捕捉不同類別之間的差異;使用複雜模型,容易在其他地方過度擬合(overfit)。
OneHotEncoder編碼高基數定性特徵,必然產生上萬列的稀疏矩陣,易消耗大量記憶體和訓練時間,除非演算法本身有相關最佳化(例:SVM)。
如果某個類別型特徵基數比較低(low-cardinality features),即該特徵的所有值去重後構成的集合元素個數比較少,一般利用One- hot編碼法將特徵轉為數值型。 One-hot編碼可以在資料預處理時完成,也可以在模型訓練的時候完成,從訓練時間的角度,後一種方法的實現更為高效,CatBoost對於基數較低的類別型特徵也是採用後一種實現。
顯然,在高基數類別型特徵(high cardinality features) 當中,例如 user ID,這種編碼方式會產生大量新的特徵,造成維度災難。一種折衷的辦法是可以將類別分組成有限個的群體再進行One-hot編碼。常用的方法是根據目標變數統計(Target Statistics,以下簡稱TS)進行分組,目標變數統計量用於估算每個類別的目標變數期望值。甚至有人直接用TS作為一個新的數值型變數來取代原來的類別型變數。重要的是,可以透過對TS數值型特徵的閾值設置,基於對數損失、基尼係數或者均方差,得到一個對於訓練集而言將類別一分為二的所有可能劃分當中最優的那個。在LightGBM當中,類別型特徵以每一步梯度提升時的梯度統計(Gradient Statistics,以下簡稱GS)來表示。雖然為建樹提供了重要的信息,但是這種方法有以下兩個缺點:
增加計算時間,因為需要對每一個類別型特徵,在迭代的每一步,都需要對GS進行計算
增加儲存需求,對於一個類別型變量,需要儲存每一次分離每個節點的類別
為了克服這些缺點,LightGBM以損失部分資訊為代價將所有的長尾類別歸為一類,作者聲稱這樣處理高基數類別型特徵時比One-hot編碼還是好不少。使用TS特徵的話,每個類別只需計算和儲存一個數字。因此,使用TS作為一種處理類別型特徵的新型數值型特徵,是最有效的,並且能夠最小化資訊損失。 TS也被廣泛應用在點擊預測任務當中,而這個場景當中的類別型特徵有使用者、地區、廣告、廣告發布者等。在接下來的討論中,我們會集中討論TS,並暫時將One-hot編碼和GS擱置一旁。
以下是計算公式:
其中n 代表的是該某個特徵取值的個數,
代表某個特徵取值下正Label的個數,mdl為一個最小閾值,樣本數量小於此值的特徵類別將被忽略,prior是Label的平均值。注意,如果是處理迴歸問題的話,可以處理成相應該特徵下label取值的average/max。對於k分類問題,會產生對應的k-1個特徵。
此方法同樣容易造成過擬合,以下方法用於防止過擬合:
增加正規項a的大小
在訓練集該列中加入雜訊
使用交叉驗證
目標編碼屬於有監督的編碼方式,如果運用得當則能夠有效地提高預測模型的準確性(Pargent, Bischl, and Thomas 2019) ;而這其中的關鍵,就是在編碼的過程中引入正則化,避免過擬合問題。
例如類別A對應的標籤1有200個,標籤2有300個,標籤3有500個,則可以編碼為:2/10,3/10,3/6。中間最重要的是如何避免過擬合(原始的target encoding直接對全部的訓練集資料和標籤進行編碼,會導致得到的編碼結果太過依賴與訓練集),常用的解決方法是使用2 levels of cross-validation求出target mean,思路如下:
把train data划分为20-folds (举例:infold: fold #2-20, out of fold: fold #1)
计算 10-folds的 inner out of folds值 (举例:使用inner_infold #2-10 的target的均值,来作为inner_oof #1的预测值)
对10个inner out of folds 值取平均,得到 inner_oof_mean
将每一个 infold (fold #2-20) 再次划分为10-folds (举例:inner_infold: fold #2-10, Inner_oof: fold #1)
计算oof_mean (举例:使用 infold #2-20的inner_oof_mean 来预测 out of fold #1的oof_mean
将train data 的 oof_mean 映射到test data完成编码
比如划分为10折,每次对9折进行标签编码然后用得到的标签编码模型预测第10折的特征得到结果,其实就是常说的均值编码。
目标编码尝试对分类特征中每个级别的目标总体平均值进行测量。当数据量较少时,每个级别的数据量减少意味着估计的均值与真实均值之间的差距增加,方差也会更大。
from category_encoders import TargetEncoder import pandas as pd from sklearn.datasets import load_boston # prepare some data bunch = load_boston() y_train = bunch.target[0:250] y_test = bunch.target[250:506] X_train = pd.DataFrame(bunch.data[0:250], columns=bunch.feature_names) X_test = pd.DataFrame(bunch.data[250:506], columns=bunch.feature_names) # use target encoding to encode two categorical features enc = TargetEncoder(cols=['CHAS', 'RAD']) # transform the datasets training_numeric_dataset = enc.fit_transform(X_train, y_train) testing_numeric_dataset = enc.transform(X_test)
Kaggle竞赛Avito Demand Prediction Challenge 第14名的solution分享:14th Place Solution: The Almost Golden Defenders。和target encoding 一样,beta target encoding 也采用 target mean value (among each category) 来给categorical feature做编码。不同之处在于,为了进一步减少target variable leak,beta target encoding发生在在5-fold CV内部,而不是在5-fold CV之前:
把train data划分为5-folds (5-fold cross validation)
target encoding based on infold data
train model
get out of fold prediction
同时beta target encoding 加入了smoothing term,用 bayesian mean 来代替mean。Bayesian mean (Bayesian average) 的思路:某一个category如果数据量较少( 另外,对于target encoding和beta target encoding,不一定要用target mean (or bayesian mean),也可以用其他的统计值包括 medium, frqequency, mode, variance, skewness, and kurtosis — 或任何与target有correlation的统计值。 M-Estimate Encoding 相当于 一个简化版的Target Encoding: 其中????+代表所有正Label的个数,m是一个调参的参数,m越大过拟合的程度就会越小,同样的在处理连续值时????+可以换成label的求和,????+换成所有label的求和。 一种基于目标的算法是 James-Stein 编码。算法的思想很简单,对于特征的每个取值 k 可以根据下面的公式获得: 其中B由以下公式估计: 但是它有一个要求是target必须符合正态分布,这对于分类问题是不可能的,因此可以把y先转化成概率的形式。在实际操作中,可以使用网格搜索方法来选择一个较优的B值。 Weight Of Evidence 同样是基于target的方法。 使用WOE作为变量,第i类的WOE等于: WOE特别合适逻辑回归,因为Logit=log(odds)。WOE编码的变量被编码为统一的维度(是一个被标准化过的值),变量之间直接比较系数即可。 这个方法类似于SUM的方法,只是在计算训练集每个样本的特征值转换时都要把该样本排除(消除特征某取值下样本太少导致的严重过拟合),在计算测试集每个样本特征值转换时与SUM相同。可见以下公式: 使用二进制编码对每一类进行编号,使用具有log2N维的向量对N类进行编码。以 (0,0) 为例,它表示第一类,而 (0,1) 表示第二类,(1,0) 表示第三类,(1,1) 则表示第四类 类似于One-hot encoding,但是通过hash函数映射到一个低维空间,并且使得两个类对应向量的空间距离基本保持一致。使用低维空间来降低了表示向量的维度。 特征哈希可能会导致要素之间发生冲突。一个哈希编码的好处是不需要指定或维护原变量与新变量之间的映射关系。因此,哈希编码器的大小及复杂程度不随数据类别的增多而增多。 和WOE相似,只是去掉了log,即: 對某一特徵進行求和編碼,方法是比較該特徵取值下標籤(或其他相關變數)的平均值與總體標籤的平均值之間的差異,以此來對特徵進行編碼。如果做不好細節,這個方法非常容易出現過擬合,所以需要配合留一法或五折交叉驗證進行特徵的編碼。還有根據方差加入懲罰項防止過度擬合的方法。 Helmert編碼通常在計量經濟學中使用。在Helmert編碼(分類特徵中的每個值對應於Helmert矩陣中的一行)之後,線性模型中編碼後的變數係數可以反映在給定該類別變數某一類別值的情形下因變數的平均值與給定該類別其他類別值的情形下因變數的平均值的差異。 Helmet編碼是僅次於One-Hot Encoding和Sum Encoder使用最廣泛的編碼方法,與Sum Encoder不同的是,它比較的是某一特徵取值下對應標籤(或其他相關變量)的平均值與他先前特徵的平均值之間的差異,而不是和所有特徵的平均值比較。這個特徵同樣容易出現過擬合的情況。 對於可取值的數量比獨熱最大量還要大的分類變量,CatBoost 使用了一個非常有效的編碼方法,這種方法和均值編碼類似,但可以降低過擬合情況。它的具體實作方法如下: 將輸入樣本集隨機排序,並產生多組隨機排列的情況。 將浮點型或屬性值標記轉換為整數。 將所有的分類特徵值結果都根據以下公式,轉換為數值結果。 其中 CountInClass 表示在目前分類特徵值中,有多少樣本的標記值是1;Prior 是分子的初始值,根據初始參數決定。 TotalCount 表示具有和目前樣本相同分類特徵值的所有樣本數量,包括目前樣本本身。 CatBoost處理Categorical features總結: #首先,他們會計算一些資料的statistics。計算某個category出現的頻率,加上超參數,產生新的numerical features。此策略要求同一標籤資料不能排列在一起(即先全是0之後全是1這種方式),訓練前需要打亂資料集。 第二,使用資料的不同排列(實際上是4個)。在每一輪建立樹之前,先丟一輪骰子,決定使用哪個排列來產生樹。 第三點是要考慮嘗試不同的categorical features組合。例如顏色和種類組合起來,可以構成類似blue dog這樣的feature。當需要組合的categorical features變多時,catboost只考慮一部分combinations。在選擇第一個節點時,只考慮選擇一個feature,例如A。在產生第二個節點時,考慮A和任意一個categorical feature的組合,選擇其中最好的。就這樣使用貪心演算法產生combinations。 第四,除非向gender這種維數很小的情況,不建議自己產生one-hot vectors,最好交給演算法處理。 以上是Python機器學習類別特徵的處理方法有哪些的詳細內容。更多資訊請關注PHP中文網其他相關文章!# train -> training dataframe
# test -> test dataframe
# N_min -> smoothing term, minimum sample size, if sample size is less than N_min, add up to N_min
# target_col -> target column
# cat_cols -> categorical colums
# Step 1: fill NA in train and test dataframe
# Step 2: 5-fold CV (beta target encoding within each fold)
kf = KFold(n_splits=5, shuffle=True, random_state=0)
for i, (dev_index, val_index) in enumerate(kf.split(train.index.values)):
# split data into dev set and validation set
dev = train.loc[dev_index].reset_index(drop=True)
val = train.loc[val_index].reset_index(drop=True)
feature_cols = []
for var_name in cat_cols:
feature_name = f'{var_name}_mean'
feature_cols.append(feature_name)
prior_mean = np.mean(dev[target_col])
stats = dev[[target_col, var_name]].groupby(var_name).agg(['sum', 'count'])[target_col].reset_index()
### beta target encoding by Bayesian average for dev set
df_stats = pd.merge(dev[[var_name]], stats, how='left')
df_stats['sum'].fillna(value = prior_mean, inplace = True)
df_stats['count'].fillna(value = 1.0, inplace = True)
N_prior = np.maximum(N_min - df_stats['count'].values, 0) # prior parameters
dev[feature_name] = (prior_mean * N_prior + df_stats['sum']) / (N_prior + df_stats['count']) # Bayesian mean
### beta target encoding by Bayesian average for val set
df_stats = pd.merge(val[[var_name]], stats, how='left')
df_stats['sum'].fillna(value = prior_mean, inplace = True)
df_stats['count'].fillna(value = 1.0, inplace = True)
N_prior = np.maximum(N_min - df_stats['count'].values, 0) # prior parameters
val[feature_name] = (prior_mean * N_prior + df_stats['sum']) / (N_prior + df_stats['count']) # Bayesian mean
### beta target encoding by Bayesian average for test set
df_stats = pd.merge(test[[var_name]], stats, how='left')
df_stats['sum'].fillna(value = prior_mean, inplace = True)
df_stats['count'].fillna(value = 1.0, inplace = True)
N_prior = np.maximum(N_min - df_stats['count'].values, 0) # prior parameters
test[feature_name] = (prior_mean * N_prior + df_stats['sum']) / (N_prior + df_stats['count']) # Bayesian mean
# Bayesian mean is equivalent to adding N_prior data points of value prior_mean to the data set.
del df_stats, stats
# Step 3: train model (K-fold CV), get oof predictioM-Estimate Encoding
James-Stein Encoding
Weight of Evidence Encoder
Leave-one-out Encoder (LOO or LOOE)
Binary Encoding
Hashing Encoding
Probability Ratio Encoding
Sum Encoder (Deviation Encoder, Effect Encoder)
Helmert Encoding
CatBoost Encoding





















