
資料庫架構演進
剛開始多數項目用單機資料庫就夠了,隨著伺服器流量越來越大,面對的請求也越來越多,我們做了資料庫讀寫分離, 使用多個從函式庫副本(Slave)負責讀,使用主函式庫(Master)負責寫,master和slave透過主從複製實現資料同步更新,保持資料一致。 slave 從庫可以水平擴展,所以更多的讀取請求不成問題
但是當用戶量級上升,寫請求越來越多,怎麼保證資料庫的負載足夠?增加一個Master是不能解決問題的, 因為資料要保存一致性,寫入操作需要2個master之間同步,相當於重複了,而且架構設計更複雜
這時需要用到分庫分表(sharding),把庫和表格存放在不同的MySQL Server上,每台伺服器可以均衡寫入請求的次數
單庫太大:單庫處理能力有限、所在伺服器上的磁碟空間不足、遇到IO瓶頸,需要把單庫切分成更多更小的庫
單表太大:CURD效率都很低、資料量太大導致索引檔案過大,磁碟IO載入索引花費時間,導致查詢逾時。所以只用索引還是不行的,需要把單表切分成多個資料集更小的表。 MyCat提供的分錶演算法都在rule.xml,可以根據不同的分錶演算法進行拆分,例如根據時間拆分、一致性雜湊、直接用主鍵對分錶的個數取模等
分割策略
單一函式庫太大,先考慮是表多還是資料多:
如果因為表格多而造成資料過多,則使用垂直拆分,即根據業務拆分成不同的庫
#如果因為單張表的資料量太大,則使用水平拆分,也就是把表的資料依照某種規則(rule.xml定義的分錶演算法)拆分成多張表
分庫分錶的原則應該是先考慮垂直拆分,再考慮水平拆分
分庫分錶和讀寫分離可以共同進行
server.xml
<user name="root"> <property name="password">123456</property> <property name="schemas">USERDB1,USERDB2</property> </user>
設定了USERDB1、USERDB2這兩個邏輯庫
schema.xml
<?xml version="1.0"?> <!DOCTYPE mycat:schema SYSTEM "schema.dtd"> <mycat:schema xmlns:mycat="http://io.mycat/"> <!-- 逻辑数据库 --> <schema name="USERDB1" checkSQLschema="false" sqlMaxLimit="100" dataNode="dn1" /> <!-- 两个逻辑库对应两个不同的数据节点 --> <schema name="USERDB2" checkSQLschema="false" sqlMaxLimit="100"dataNode="dn2" /> <!-- 存储节点 --> <dataNode name="dn1" dataHost="node1" database="mytest1" /> <!-- 两个数据节点对应两个不同的物理机器 --> <dataNode name="dn2" dataHost="node2" database="mytest2" /> <!-- USERDB1对应mytest1,USERDB2对应mytest2 --> <!-- 数据库主机 --> <dataHost name="node1" maxCon="1000" minCon="10" balance="0" writeType="0" dbType="mysql" dbDriver="native"> <heartbeat>select user()</heartbeat> <writeHost host="192.168.131.129" url="192.168.131.129:3306" user="root" password="123456" /> </dataHost> <dataHost name="node2" maxCon="1000" minCon="10" balance="0"writeType="0" dbType="mysql" dbDriver="native"> <heartbeat>select user()</heartbeat> <writeHost host="192.168.0.6" url="192.168.0.6:3306" user="root" password="123456" /> </dataHost> </mycat:schema>
兩個邏輯庫對應兩個不同的資料節點,兩個資料節點對應兩個不同的實體機器
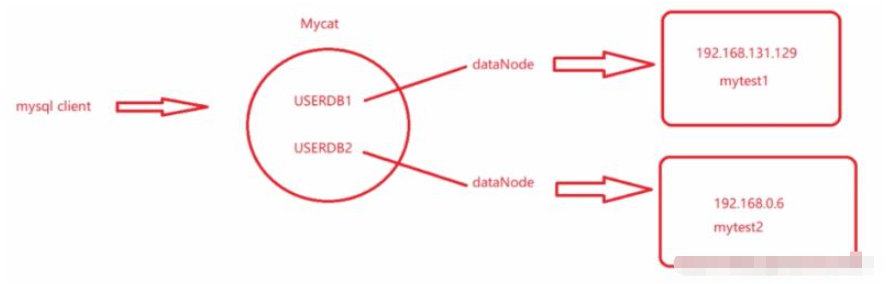
mytest1和mytest2分成了不同機器上的不同的函式庫,各包含一部分表,它們原來是合在一塊的,在一台機器上,現在做了垂直的拆分。
客戶端就需要去連接不同的邏輯庫了,根據業務操作不同的邏輯庫

#然後配置了兩個寫庫,兩台機器把庫平分了,分擔了原來單機的壓力。分庫伴隨著分錶,從業務上對錶拆分
垂直分錶,基於列字段進行。一般是針對幾百列的這種大表,也避免查詢時,資料量太大造成的「跨頁」問題。
一般是表格中的欄位較多,將不常用的, 資料較大,長度較長(如text類型欄位)的分割到擴充表。訪問頻率較高的欄位單獨放在一張表
針對資料量龐大的單張表(如訂單表),依照某種規則( RANGE、HASH取模等),切分到多張表裡面去。不建議使用,因為這些表仍然在同一個資料庫中,因此執行針對整個資料庫的操作可能存在IO瓶頸
將單一表的資料分佈到多個伺服器上,每個伺服器擁有一部分錶和庫,只不過表中的資料集合不同。分庫分錶技術的應用可以有效地緩解單機和單庫在性能方面的瓶頸和壓力,同時也能夠突破與IO、連接數、硬體資源等相關的限制
#分庫分錶可以和主從複製同時進行,但不基於主從複製;讀寫分離才基於主從複製
server.xml
<user name="root"> <property name="password">123456</property> <property name="schemas">USERDB</property> </user>
schema.xml
<?xml version="1.0"?> <!DOCTYPE mycat:schema SYSTEM "schema.dtd"> <mycat:schema xmlns:mycat="http://io.mycat/"> <!-- 逻辑数据库 --> <schema name="USERDB" checkSQLschema="false" sqlMaxLimit="100"> <table name="user" dataNode="dn1" /> <!-- 这里的user和student都是实际存在的物理表名 --> <table name="student" primaryKey="id" autoIncrement="true" dataNode="dn1,dn2" rule="mod-long"/> </schema> <!-- 存储节点 --> <dataNode name="dn1" dataHost="node1" database="mytest1" /> <dataNode name="dn2" dataHost="node2" database="mytest2" /> <!-- 数据库主机 --> <dataHost name="node1" maxCon="1000" minCon="10" balance="0" writeType="0" dbType="mysql" dbDriver="native"> <heartbeat>select user()</heartbeat> <writeHost host="192.168.131.129" url="192.168.131.129:3306" user="root" password="123456" /> </dataHost> <dataHost name="node2" maxCon="1000" minCon="10" balance="0" writeType="0" dbType="mysql" dbDriver="native"> <heartbeat>select user()</heartbeat> <writeHost host="192.168.0.6" url="192.168.0.6:3306" user="root" password="123456" /> </dataHost> </mycat:schema>
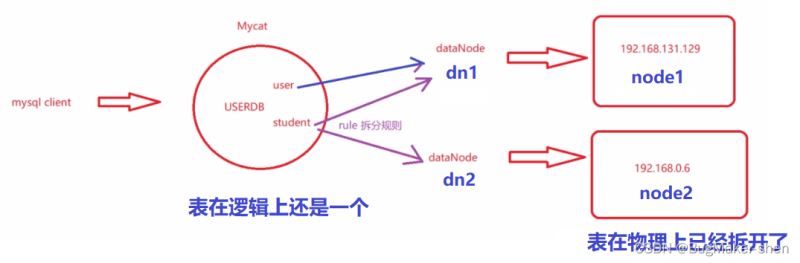
user表示一個普通的表,直接放在資料節點dn1上,放在一台機器上,這張表不用進行拆分
student表的primaryKey是id,根據id拆分,放在dn1和dn2上,最終這個表要分在兩台機器上,在物理上分開了,但是在邏輯上還是一個,往哪張表裡增加,在2台機器上查詢然後如何合併這些操作都是由mycat完成的
拆分的規則是取模(mod - long),每次插入用id模上存在的機器數(2)
此外還需要在rule.xml中配置以下分割演算法
找到演算法mod-long,因為我們將邏輯表student分開映射到兩台主機上,所以修改資料節點的數量為2

2.測試水平分錶
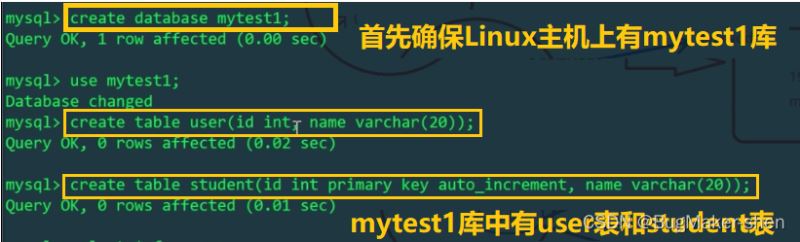
Linux主機
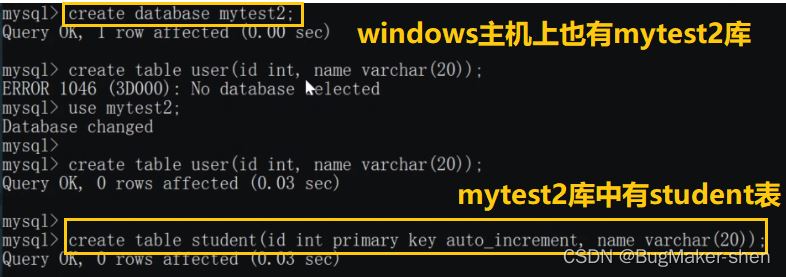
Windows主機
登入mycat的8066埠
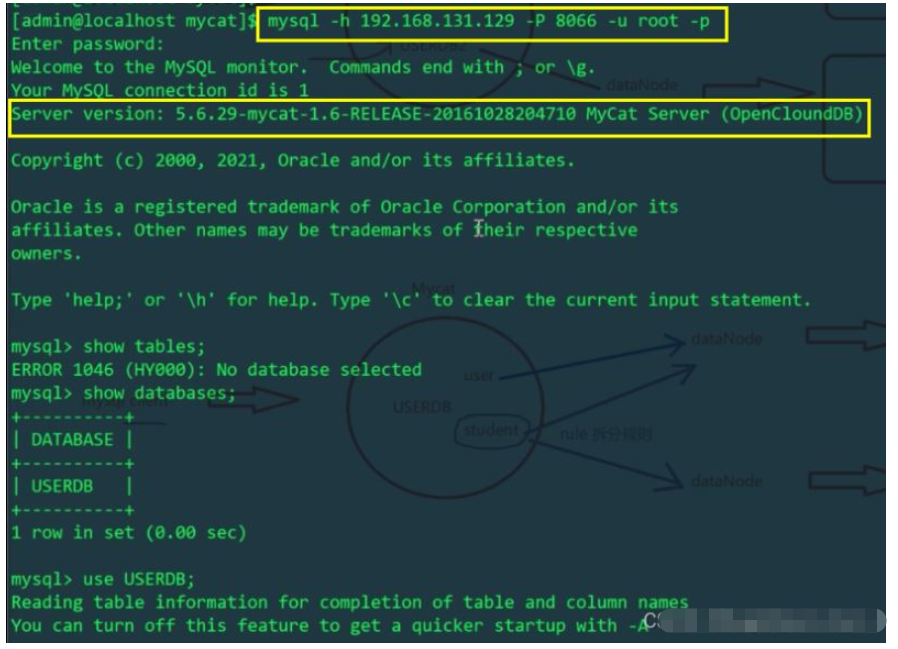
使用MyCat給user表插入兩個資料

#由於schema.xml設定檔中,邏輯表user只在Linux主機的mytest1庫中存在,mycat操作的邏輯表user會影響Linux主機上的實體表,而不會影響Windows主機上的表。我們各自查看Linux和Windows主機的使用者表:
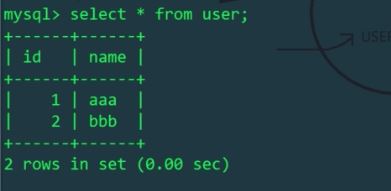

#我們再透過MyCat給student表插入兩個資料

我們知道schema.xml設定檔中,邏輯表student對應兩台主機上的兩個庫mytest1、mytest2中的兩個表,所以對邏輯表插入的兩條數據,會實際影響兩張實體表(用id%機器數,決定插入哪張物理表)。我們分別查看Linux和Windows主機的student表:
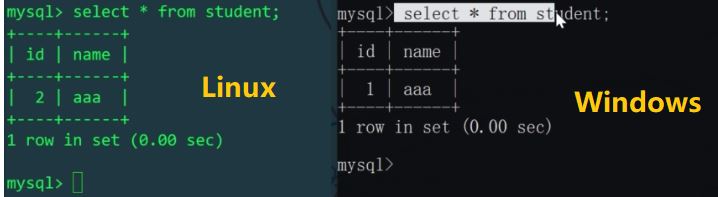
再透過MyCat插入id=3和id=4的數據,應該插入不同主機上的不同實體表
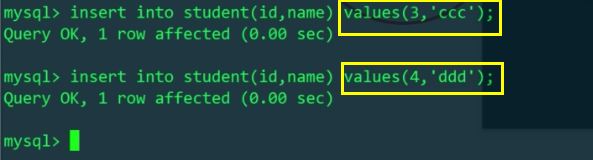
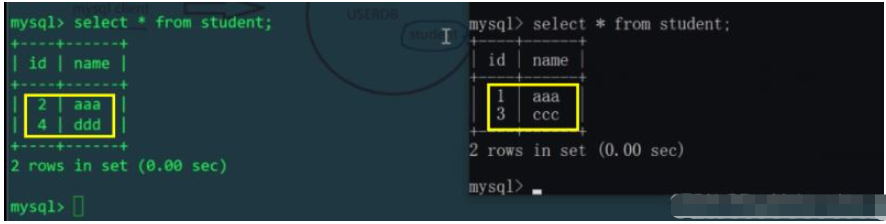
這就相當於把student表進行水平拆分了
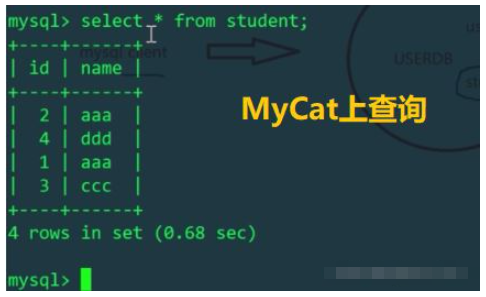
透過MyCat查詢的時候只需要正常輸入就行,我們配置的是表格拆分後放在這2個資料節點上,MyCat會根據配置在兩個庫上查詢並進行資料合併
以上是MySQL分庫分錶實例分析的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















