

Redis整數集合的使用方法有哪些

一、集合概述
對於集合,STL 的 set 相信大家都不陌生,它的底層實作是紅黑樹。無論插入、刪除、查找都是 O(log n) 的時間複雜度。當然,如果用哈希表來實現集合,插入、刪除、查找都可以達到 O(1)。那為什麼集合要用紅黑樹和沒有用哈希表呢?我想,最大的可能是基於集合本身的特性,集合有它獨特的操作:求交、求並、求差。這三個操作對於雜湊表來說都是 O(n) 的。相較於無序的哈希表,採用有序的紅黑樹會更加適宜,因為這一點很重要。
二、Redis 整數集合(intset)
今天要講的整數集合,又稱為 intset,是 Redis 獨特的資料結構。它的實作既不是紅黑樹,也不是哈希表。就是簡單的陣列加上記憶體編碼。當儲存元素較少( 元素個數上限定義在server.h 的 OBJ_SET_MAX_INTSET_ENTRIES 巨集定義值為512)且皆為整數時,才會使用到整數集合。它的查找是 O(log n) 的,插入和刪除都是 O(n) 的。但是由於儲存元素相對較少的時候,O(log n) 和 O(n) 差距不是很大,但是用Redis 的這種整數集合,相比紅黑樹和哈希表來說,可以大大減少內存。
所以,Redis 的 整數集合 intset 的存在主要還是為了節省記憶體。
1、intset 結構定義
intset 結構定義在intset.h 中:
#define INTSET_ENC_INT16 (sizeof(int16_t))
#define INTSET_ENC_INT32 (sizeof(int32_t))
#define INTSET_ENC_INT64 (sizeof(int64_t))
typedef struct intset {
uint32_t encoding; /* a */
uint32_t length; /* b */
int8_t contents[]; /* c */
} intset; a) encoding 指定了編碼方式,總共有三種INTSET_ENC_INT16、 a) encoding 指定了編碼方式,總共有三種INTSET_ENC_INT16. 。從宏定義可以看出,這三個值分別為 2、4、8。從字面意思可以看出三者能表示的範圍是 16位元整數、32位元整數 以及 64位元整數。
b) length 儲存了整數集合的元素數量。
c) contents 為整數集合的柔性數組,元素類型並不一定是 int8_t 類型的。 contents 不會佔用結構體的大小,它只作為整數集合資料的首指標。整數集合中的元素按照從小到大的順序在 contents 中排列起來。
2、編碼方式
首先,我們來理解編碼方式 encoding 的意思。需要明確的一點是,對於一個整數集合來說,所有的元素的編碼一定是一致的(否則每個數都得存一個編碼,而不是將它存在intset 結構體內了),那麼整個整數集合的編碼取決於集合中「絕對值」最大的那個數(之所以是絕對值,因為整數包含正數和負數)。
透過那個絕對值最大的整數來取得編碼,實作如下:
static uint8_t _intsetValueEncoding(int64_t v) {
if (v < INT32_MIN || v > INT32_MAX)
return INTSET_ENC_INT64;
else if (v < INT16_MIN || v > INT16_MAX)
return INTSET_ENC_INT32;
else
return INTSET_ENC_INT16;
} 這段程式碼的意思是,如果整數v 不能用32位元整數表示,那麼就需要用 INTSET_ENC_INT64 編碼如果不能用32位元整數表示,那麼就需要用 INTSET_ENC_INT64 編碼用16位元整數表示,那麼就需要用 INTSET_ENC_INT32 編碼;否則,採用 INTSET_ENC_INT16 編碼就行。核心就是:能用2個位元組表示就不用4個字節,能用4個位元組表示就不用8個字節,能省則省。
幾個巨集定義在 stdint.h 中,如下:
/* Minimum of signed integral types. */ # define INT16_MIN (-32767-1) # define INT32_MIN (-2147483647-1) /* Maximum of signed integral types. */ # define INT16_MAX (32767) # define INT32_MAX (2147483647)
3、編碼升級
當程式編碼方式不足以儲存更大位數的整數時,需要升級編碼。舉個例子,下圖所示的四個數字都在 [ -32768, 32767 ] 範圍內,所以採用 INTSET_ENC_INT16 編碼即可。 contents 的陣列長度為 sizeof(int16_t) * 4 = 2 * 4 = 8 個位元組 ( 即64個二進位位元 )。
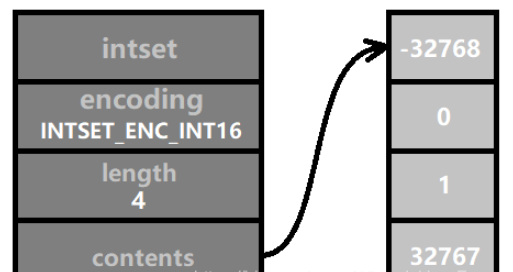
接著我們插入一個數,它的值為32768,比INT16_MAX 大1,所以它需要採用INTSET_ENC_INT32 編碼,而整數集合中所有的數的編碼需要維持一致。因此,要將所有數字的編碼轉換為 INTSET_ENC_INT32 編碼。這就是 “升級”。如圖所示:
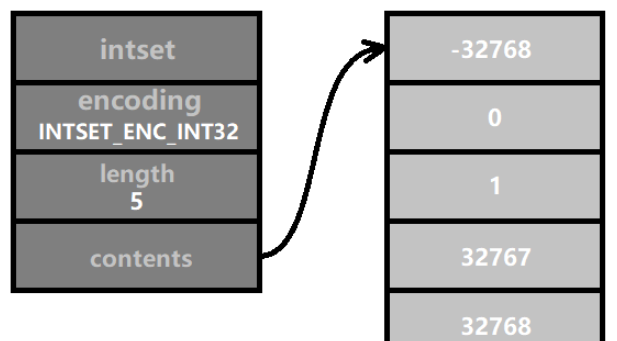
升級後,contents 陣列的長度變成sizeof(int32_t) * 5 = 4 * 5 = 20 個位元組( 即160個二進位位元).而且每個元素佔用的記憶體都擴大一倍,所在的相對位置也發生了變化,導致所有的元素都需要遷移到高位記憶體。
那我們一開始就把所有的整數集合都用 INTSET_ENC_INT64 來編碼不就好了,還省得麻煩。原因是 Redis 設計 intset 的初衷還是為了節省內存,設想一個集合的元素永遠都不會超過 16位 整數,那麼用 64位整數的話,相當於浪費了 3倍 的內存。
三、整数集合常用操作
1、创建集合
创建一个整数集合 intsetNew,实现在 intset.c 中:
intset *intsetNew(void) {
intset *is = zmalloc(sizeof(intset));
is->encoding = intrev32ifbe(INTSET_ENC_INT16);
is->length = 0;
return is;
} 初始创建的整数集合为空集合,用 zmalloc 进行内存分配后,定义编码为 INTSET_ENC_INT16,这样可以使内存尽量小。这里需要注意的是,intset 的存储直接涉及到内存编码,所以需要考虑主机的字节序问题(相关资料请参阅:字节序)。
intrev32ifbe 的意思是 int32 reversal if big endian。即 如果当前主机字节序为大端序,那么将它的内存存储进行翻转操作。简言之,intset 的所有成员存储方式都采用小端序。所以创建一个空的整数集合,内存分布如下:

了解了整数集合的内存编码以后,我们来看看它的 设置 (set)和 获取(get)。
2、元素设置
设置 的含义就是给定整数集合以及一个位置和值,将值设置到这个整数集合的对应位置上。_intsetSet 实现如下:
static void _intsetSet(intset *is, int pos, int64_t value) {
uint32_t encoding = intrev32ifbe(is->encoding); /* a */
if (encoding == INTSET_ENC_INT64) {
((int64_t*)is->contents)[pos] = value; /* b */
memrev64ifbe(((int64_t*)is->contents)+pos); /* c */
} else if (encoding == INTSET_ENC_INT32) {
((int32_t*)is->contents)[pos] = value;
memrev32ifbe(((int32_t*)is->contents)+pos);
} else {
((int16_t*)is->contents)[pos] = value;
memrev16ifbe(((int16_t*)is->contents)+pos);
}
} a) 大端序和小端序只是存储方式,encoding 在存储的时候进行了一次 intrev32ifbe 转换,取出来用的时候需要再进行一次 intrev32ifbe 转换(其实就是序列化和反序列化)。
b) 根据 encoding 的类型,将 contents 转换成指定类型的指针,然后用 pos 进行索引找到对应的内存位置,然后将 value 的值设置到对应的内存中。
c) memrev64ifbe 的实现参见 字节序 的 memrev64 函数,即将对应内存的值转换成小端序存储。
3、元素获取
获取 的含义就是给定整数集合以及一个位置,返回给定位置的元素的值。_intsetGet 实现如下:
static int64_t _intsetGetEncoded(intset *is, int pos, uint8_t enc) {
int64_t v64;
int32_t v32;
int16_t v16;
if (enc == INTSET_ENC_INT64) {
memcpy(&v64,((int64_t*)is->contents)+pos,sizeof(v64)); /* a */
memrev64ifbe(&v64); /* b */
return v64;
} else if (enc == INTSET_ENC_INT32) {
memcpy(&v32,((int32_t*)is->contents)+pos,sizeof(v32));
memrev32ifbe(&v32);
return v32;
} else {
memcpy(&v16,((int16_t*)is->contents)+pos,sizeof(v16));
memrev16ifbe(&v16);
return v16;
}
}
static int64_t _intsetGet(intset *is, int pos) {
return _intsetGetEncoded(is,pos,intrev32ifbe(is->encoding));
} a) 根据 encoding 的类型,将 contents 转换成指定类型的指针,然后用 pos 进行索引找到对应的内存位置,将内存位置上的值拷贝到临时变量中;
b) 由于是直接的内存拷贝,所以取出来的值还是小端序的,那么在大端序的主机上得到的值是不对的,所以需要再做一次 memrev64ifbe 转换将值还原。
4、元素查找
由于整数集合是有序集合,所以查找某个元素是否在整数集合中,Redis 采用的是二分查找。intsetSearch 实现如下:
static uint8_t intsetSearch(intset *is, int64_t value, uint32_t *pos) {
int min = 0, max = intrev32ifbe(is->length)-1, mid = -1;
int64_t cur = -1;
if (intrev32ifbe(is->length) == 0) {
if (pos) *pos = 0; /* a */
return 0;
} else { /* b */
if (value > _intsetGet(is,intrev32ifbe(is->length)-1)) {
if (pos) *pos = intrev32ifbe(is->length);
return 0;
} else if (value < _intsetGet(is,0)) {
if (pos) *pos = 0;
return 0;
}
}
while(max >= min) {
mid = ((unsigned int)min + (unsigned int)max) >> 1; /* c */
cur = _intsetGet(is,mid);
if (value > cur) {
min = mid+1;
} else if (value < cur) {
max = mid-1;
} else {
break;
}
}
if (value == cur) { /* d */
if (pos) *pos = mid;
return 1;
} else {
if (pos) *pos = min;
return 0;
}
} a) 整数集合为空,返回0表示查找失败;
b) value 的值比整数集合中的最大值还大,或者比最小值还小,则返回0表示查找失败;
c) 执行二分查找,将找到的值存在 cur 中;
d) 如果找到则返回1,表示查找成功,并且将 pos 设置为 mid 并返回;如果没找到则返回一个需要插入的位置。
5、内存重分配
由于 contents 的内存是动态分配的,所以每次进行元素插入或者删除的时候,都需要重新分配内存,这个实现放在 intsetResize 中,实现如下:
static intset *intsetResize(intset *is, uint32_t len) {
uint32_t size = len*intrev32ifbe(is->encoding);
is = zrealloc(is,sizeof(intset)+size);
return is;
} encoding 本身表示字节个数,所以乘上集合个数 len 就是 contents 数组需要的总字节数了,调用 zrealloc 进行内存重分配,然后返回重新分配后的地址。
注意:zrealloc 的返回值必须返回出去,因为 intset 在进行内存重分配以后,地址可能就变了。即 is = zrealloc(is, ...) 中,此 is 非彼 is。所以,所有调用 intsetResize 的函数都需要连带的返回新的 intset 指针。
6、编码升级
编码升级一定发生在元素插入,并且插入的元素的绝对值比整数集合中的元素都大的时候,所以我们把升级后的元素插入和编码升级放在一个函数实现,名曰 intsetUpgradeAndAdd,实现如下:
static intset *intsetUpgradeAndAdd(intset *is, int64_t value) {
uint8_t curenc = intrev32ifbe(is->encoding);
uint8_t newenc = _intsetValueEncoding(value);
int length = intrev32ifbe(is->length);
int prepend = value < 0 ? 1 : 0; /* a */
is->encoding = intrev32ifbe(newenc);
is = intsetResize(is,intrev32ifbe(is->length)+1); /* b */
while(length--)
_intsetSet(is,length+prepend,_intsetGetEncoded(is,length,curenc)); /* c */
if (prepend)
_intsetSet(is,0,value);
else
_intsetSet(is,intrev32ifbe(is->length),value); /* d */
is->length = intrev32ifbe(intrev32ifbe(is->length)+1);
return is;
} a) curenc 记录升级前的编码,newenc 记录升级后的编码;
b) 将整数集合 is 的编码设置成新的编码后,进行内存重分配;
c) 获取原先内存中的数据,设置到新内存中(注意:由于两段内存空间是重叠的,而且新内存的长度一定大于原先内存,所以需要从后往前进行拷贝);
d) 当插入的值 value 为负数的时候,为了保证集合的有序性,需要插入到 contents 的头部;反之,插入到尾部;当 value 为负数时 prepend 为1,这样就可以保证在内存拷贝的时候将第 0 个位置留空。
如图展示了一个 (-32768, 0, 1, 32767) 的整数集合在插入数字 32768 后的升级的完整过程:
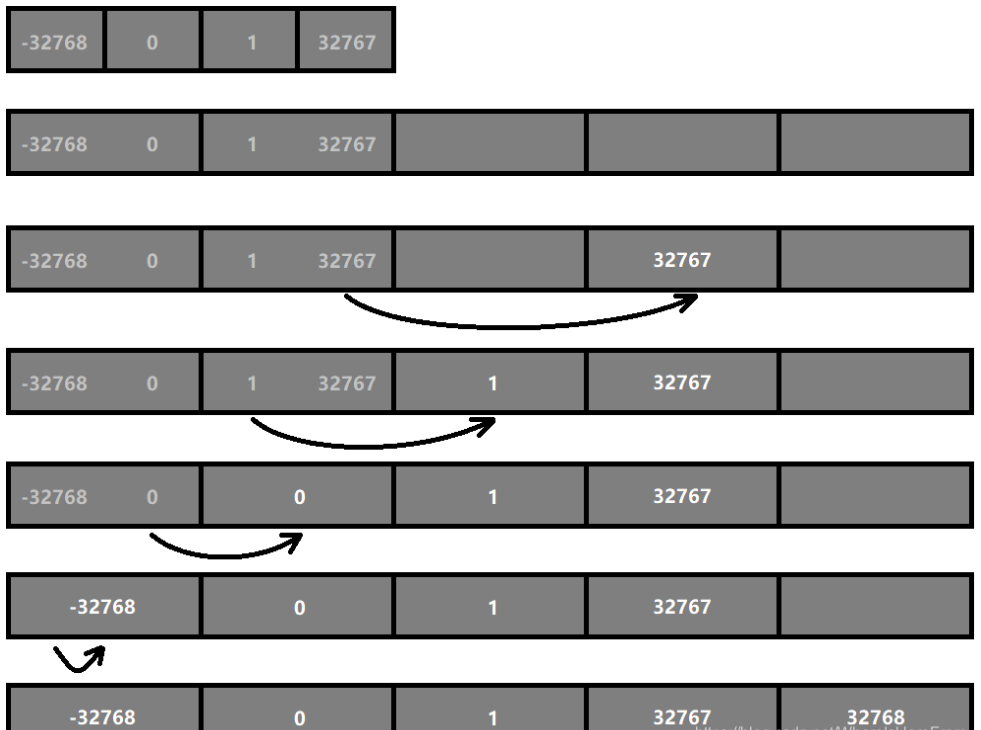
整数集合升级的时间复杂度是 O(n) 的,但是在整数集合的生命期内,升级最多发生两次(从 INTSET_ENC_INT16 到 INTSET_ENC_INT32 以及 从 INTSET_ENC_INT32 到 INTSET_ENC_INT64)。
7、内存迁移
绝大多数情况都是在执行 插入 、删除 、查找 操作。插入 和 删除 会涉及到连续内存的移动。为了实现内存移动,Redis内部实现包括intsetMoveTail函数。
static void intsetMoveTail(intset *is, uint32_t from, uint32_t to) {
void *src, *dst;
uint32_t bytes = intrev32ifbe(is->length)-from; /* a */
uint32_t encoding = intrev32ifbe(is->encoding);
if (encoding == INTSET_ENC_INT64) {
src = (int64_t*)is->contents+from;
dst = (int64_t*)is->contents+to;
bytes *= sizeof(int64_t); /* b */
} else if (encoding == INTSET_ENC_INT32) {
src = (int32_t*)is->contents+from;
dst = (int32_t*)is->contents+to;
bytes *= sizeof(int32_t);
} else {
src = (int16_t*)is->contents+from;
dst = (int16_t*)is->contents+to;
bytes *= sizeof(int16_t);
}
memmove(dst,src,bytes); /* c */
} a) 统计从 from 到结尾,有多少个元素;
b) 根据不同的编码,计算出需要拷贝的内存字节数 bytes,以及拷贝源位置 src,拷贝目标位置 dst;
c) memmove 是 string.h 中的函数:src指向的内存区域拷贝 bytes 个字节到 dst 所指向的内存区域,这个函数是支持内存重叠的;
8、元素插入
最后,讲整数集合的插入和删除,插入调用的是 intsetAdd,在 intset.c 中实现:
intset *intsetAdd(intset *is, int64_t value, uint8_t *success) {
uint8_t valenc = _intsetValueEncoding(value);
uint32_t pos;
if (success) *success = 1;
if (valenc > intrev32ifbe(is->encoding)) { /* a */
return intsetUpgradeAndAdd(is,value);
} else {
if (intsetSearch(is,value,&pos)) {
if (success) *success = 0; /* b */
return is;
}
is = intsetResize(is,intrev32ifbe(is->length)+1); /* c */
if (pos < intrev32ifbe(is->length)) intsetMoveTail(is,pos,pos+1); /* d */
}
_intsetSet(is,pos,value);
is->length = intrev32ifbe(intrev32ifbe(is->length)+1); /* e */
return is;
} a) 插入的数值 value 的内存编码大于现有集合的编码,直接调用 intsetUpgradeAndAdd 进行编码升级;
b) 集合元素是不重复的,如果 intsetSearch 能够找到,则将 success 置为0,表示此次插入失败;
c) 如果 intsetSearch 找不到,将 intset 进行内存重分配,即 长度 加 1。
d) pos 为 intsetSearch 过程中找到的 value 将要插入的位置,我们将 pos 以后的内存向后移动1个单位 (这里的1个单位可能是2个字节、4个字节或者8个字节,取决于当前整数集合的内存编码)。
e) 调用 _intsetSet 将 value 的值设置到 pos 的位置上,然后给成员变量 length 加 1。最后返回 intset 指针首地址,因为其间进行了 intsetResize,传入的 intset 指针和返回的有可能不是同一个了。
9、元素删除
删除元素调用的是 intsetRemove ,实现如下:
intset *intsetRemove(intset *is, int64_t value, int *success) {
uint8_t valenc = _intsetValueEncoding(value);
uint32_t pos;
if (success) *success = 0;
if (valenc <= intrev32ifbe(is->encoding) && intsetSearch(is,value,&pos)) { /* a */
uint32_t len = intrev32ifbe(is->length);
if (success) *success = 1;
if (pos < (len-1)) intsetMoveTail(is,pos+1,pos); /* b */
is = intsetResize(is,len-1); /* c */
is->length = intrev32ifbe(len-1);
}
return is;
} a) 当整数集合中存在 value 这个元素时才能执行删除操作;
b) 如果能通过 intsetSearch 找到元素,那么它的位置就在 pos 上,这是通过 intsetMoveTail 将内存往前挪;
c) intsetResize 重新分配内存,并且将集合长度减1;
以上是Redis整數集合的使用方法有哪些的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

AI Hentai Generator
免費產生 AI 無盡。

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)
熱門話題



 redis集群模式怎麼搭建
Apr 10, 2025 pm 10:15 PM
redis集群模式怎麼搭建
Apr 10, 2025 pm 10:15 PM
Redis集群模式通過分片將Redis實例部署到多個服務器,提高可擴展性和可用性。搭建步驟如下:創建奇數個Redis實例,端口不同;創建3個sentinel實例,監控Redis實例並進行故障轉移;配置sentinel配置文件,添加監控Redis實例信息和故障轉移設置;配置Redis實例配置文件,啟用集群模式並指定集群信息文件路徑;創建nodes.conf文件,包含各Redis實例的信息;啟動集群,執行create命令創建集群並指定副本數量;登錄集群執行CLUSTER INFO命令驗證集群狀態;使
 redis數據怎麼清空
Apr 10, 2025 pm 10:06 PM
redis數據怎麼清空
Apr 10, 2025 pm 10:06 PM
如何清空 Redis 數據:使用 FLUSHALL 命令清除所有鍵值。使用 FLUSHDB 命令清除當前選定數據庫的鍵值。使用 SELECT 切換數據庫,再使用 FLUSHDB 清除多個數據庫。使用 DEL 命令刪除特定鍵。使用 redis-cli 工具清空數據。
 redis指令怎麼用
Apr 10, 2025 pm 08:45 PM
redis指令怎麼用
Apr 10, 2025 pm 08:45 PM
使用 Redis 指令需要以下步驟:打開 Redis 客戶端。輸入指令(動詞 鍵 值)。提供所需參數(因指令而異)。按 Enter 執行指令。 Redis 返迴響應,指示操作結果(通常為 OK 或 -ERR)。
 redis怎麼使用鎖
Apr 10, 2025 pm 08:39 PM
redis怎麼使用鎖
Apr 10, 2025 pm 08:39 PM
使用Redis進行鎖操作需要通過SETNX命令獲取鎖,然後使用EXPIRE命令設置過期時間。具體步驟為:(1) 使用SETNX命令嘗試設置一個鍵值對;(2) 使用EXPIRE命令為鎖設置過期時間;(3) 當不再需要鎖時,使用DEL命令刪除該鎖。
 redis怎麼讀取隊列
Apr 10, 2025 pm 10:12 PM
redis怎麼讀取隊列
Apr 10, 2025 pm 10:12 PM
要從 Redis 讀取隊列,需要獲取隊列名稱、使用 LPOP 命令讀取元素,並處理空隊列。具體步驟如下:獲取隊列名稱:以 "queue:" 前綴命名,如 "queue:my-queue"。使用 LPOP 命令:從隊列頭部彈出元素並返回其值,如 LPOP queue:my-queue。處理空隊列:如果隊列為空,LPOP 返回 nil,可先檢查隊列是否存在再讀取元素。
 redis底層怎麼實現
Apr 10, 2025 pm 07:21 PM
redis底層怎麼實現
Apr 10, 2025 pm 07:21 PM
Redis 使用哈希表存儲數據,支持字符串、列表、哈希表、集合和有序集合等數據結構。 Redis 通過快照 (RDB) 和追加只寫 (AOF) 機制持久化數據。 Redis 使用主從復制來提高數據可用性。 Redis 使用單線程事件循環處理連接和命令,保證數據原子性和一致性。 Redis 為鍵設置過期時間,並使用 lazy 刪除機制刪除過期鍵。
 redis怎麼讀源碼
Apr 10, 2025 pm 08:27 PM
redis怎麼讀源碼
Apr 10, 2025 pm 08:27 PM
理解 Redis 源碼的最佳方法是逐步進行:熟悉 Redis 基礎知識。選擇一個特定的模塊或功能作為起點。從模塊或功能的入口點開始,逐行查看代碼。通過函數調用鏈查看代碼。熟悉 Redis 使用的底層數據結構。識別 Redis 使用的算法。
 redis怎麼做消息中間件
Apr 10, 2025 pm 07:51 PM
redis怎麼做消息中間件
Apr 10, 2025 pm 07:51 PM
Redis 作為消息中間件,支持生產-消費模型,可持久化消息並保證可靠交付。使用 Redis 作為消息中間件可實現低延遲、可靠和可擴展的消息傳遞。
