

吳恩達ChatGPT課爆火:AI放棄了倒寫單詞,但理解了整個世界

沒想到時至今日,ChatGPT竟然會犯下低階錯誤?
吳恩達大神最新開課就指出來了:
ChatGPT不會反轉單字!
例如讓它反轉下lollipop這個詞,輸出是pilollol,完全混亂。

哦豁,這確實有點大跌眼鏡。
以至於聽課網友在Reddit上發文後,立刻引來大量圍觀,貼文熱度火速衝到6k。
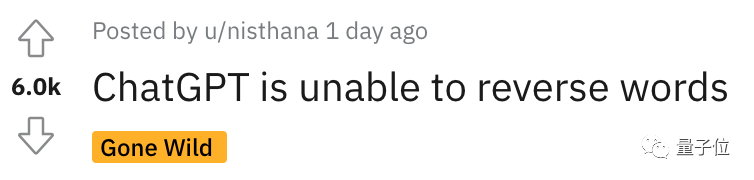
而且這不是偶然bug,網友們發現ChatGPT確實無法完成這個任務,我們親測結果也是如此。

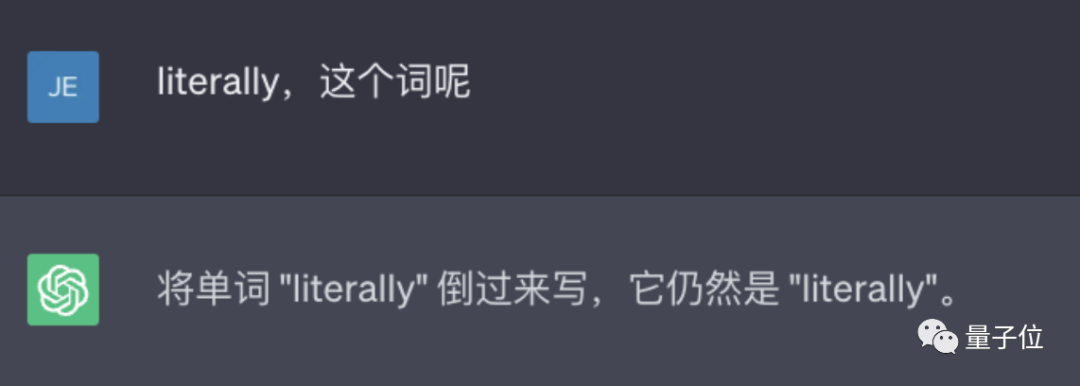
#△實測ChatGPT(GPT-3.5)
#甚至包括Bard、Bing、文心一言在內等一眾產品都不行。
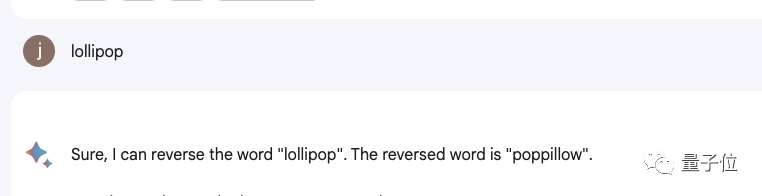
△實測Bard

#△實測文心一言
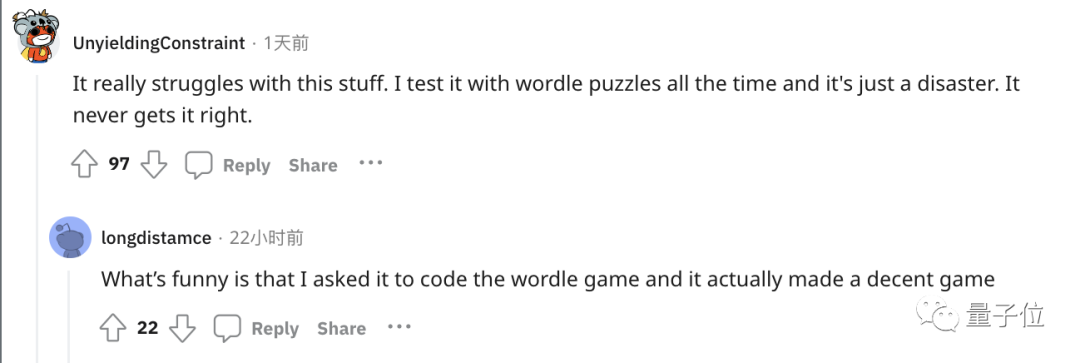
還有人緊跟著吐槽, ChatGPT在處理這些簡單的單字任務就是很糟糕。
例如玩先前曾經爆火的文字遊戲Wordle簡直就是一場災難,從來沒有做對過。
誒?這到底是為啥?
關鍵在於token
之所以有這樣的現象,關鍵在於token。大型模型通常使用token來處理文本,因為token是文本中最常見的字元序列。
它可以是整個單字,也可以是單字一個片段。大型模型熟悉這些 Token 之間的統計關係,並能夠熟練地產生下一個 Token。
因此在處理單字反轉這個小任務時,它可能只是將每個token翻轉過來,而不是字母。

這點放在中文語境下體現就更為明顯:一個字是一個token,也可能是一個字是一個token。

針對開頭的例子,有人嘗試了解下ChatGPT的推理過程。
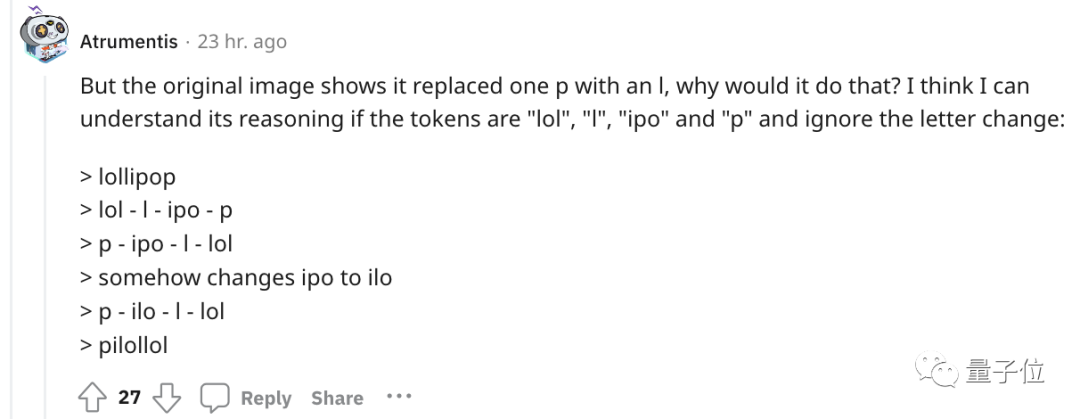
為了更直覺的了解,OpenAI甚至還出了個GPT-3的Tokenizer。
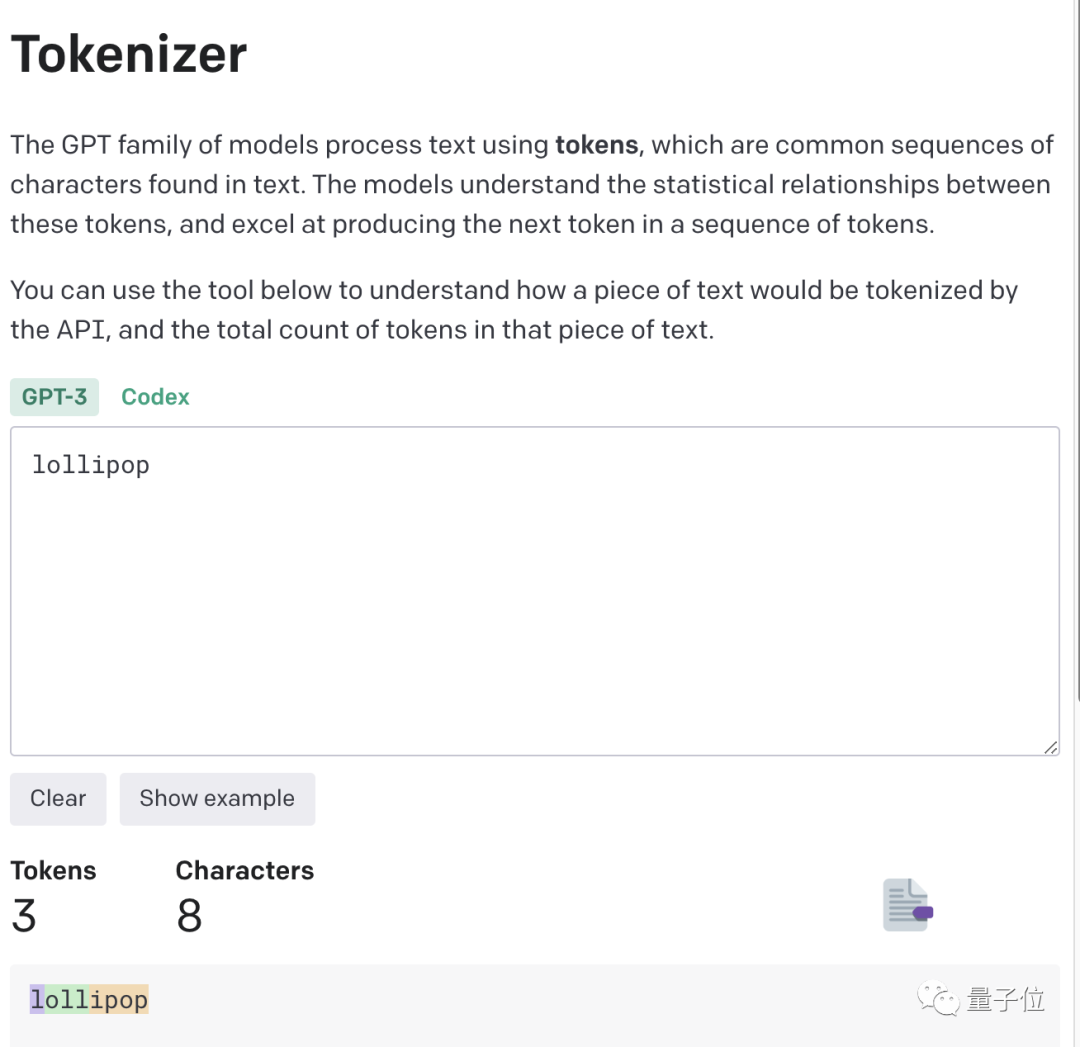
例如像lollipop這個詞,GPT-3會將其理解成I、oll、ipop這三個部分。
根據經驗總結,也就誕生出這樣一些不成文法。
- 1個token≈4個英文字元≈四分之三個字;
- 100個token≈75個單字;
- 1-2句話≈30個token;
- 一段話≈100個token,1500個單字≈2048個token;
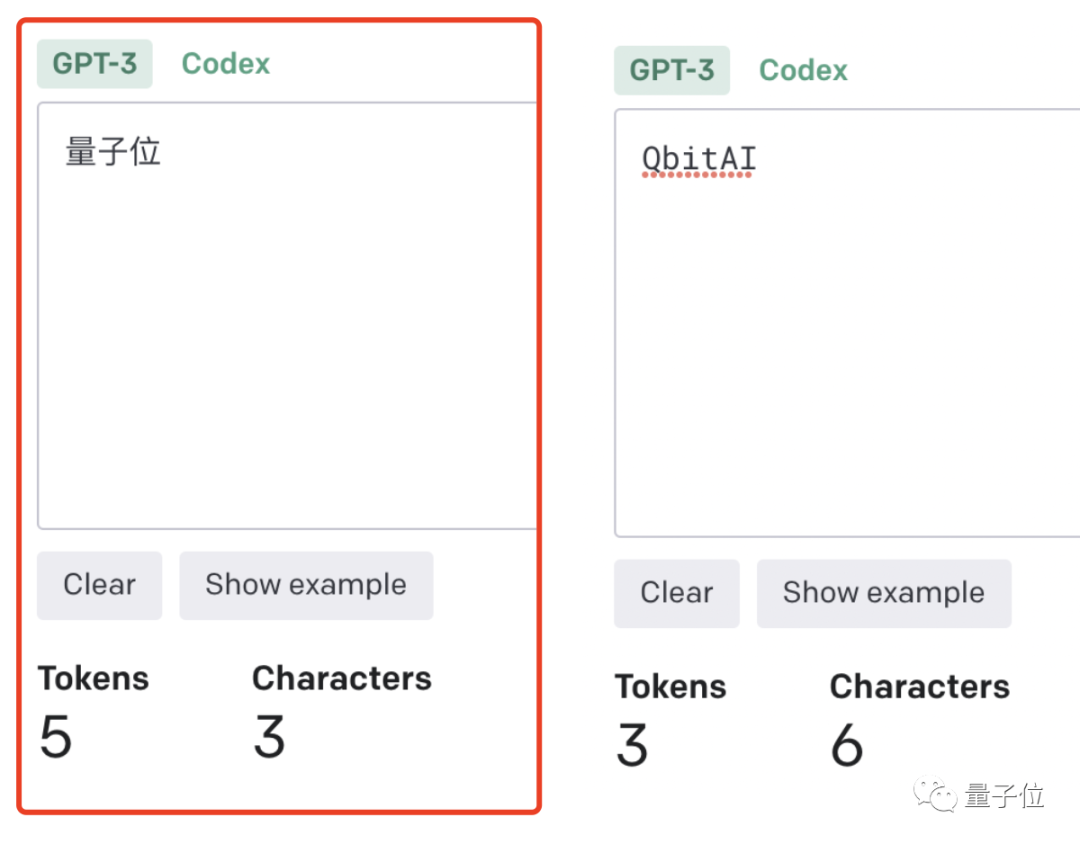
token-to-char(token到單字)比例越高,處理成本也越高。因此處理中文tokenize要比英文更貴。
可以這樣理解,token是大模型認識理解人類現實世界的方式。它非常簡單,還能大幅降低記憶體和時間複雜度。
但將單字token化有一個問題,就會使模型很難學習到有意義的輸入表示,最直觀的表示就是不能理解單字的意思。
當時Transformers有做過相應優化,例如一個複雜、不常見的單字分成一個有意義的token和一個獨立token。
就如同 "annoyingly" 被分成 "annoying" 和 "ly" 兩個部分一樣,前一個保留了其本身的意義,而後一個則更加常見。
這也成就瞭如今ChatGPT及其他大模型產品的驚艷效果,能很好地理解人類的語言。
至於無法處理單字反轉這樣一個小任務,自然也有解決之道。
最簡單直接的,就是你先自己把單字分開嘍~

#或者也可以讓ChatGPT一步一步來,先tokenize每個字母。

又或讓它寫一個反轉字母的程序,然後程式的結果對了。 (狗頭)

不過也可以使用GPT-4,實測沒有這樣的問題。

△實測GPT-4
總之,token就是AI理解自然語言的基石。
而作為AI理解人類自然語言的橋樑,token的重要性也越來越明顯。
它已經成為AI模型表現優劣的關鍵決定因素,還是大模型的計費標準。
甚至有了token文學
如前文所言,token能方便模型捕捉到更細緻的語意訊息,如詞義、詞序、語法結構等。在序列建模任務(如語言建模、機器翻譯、文字生成等)中,位置和順序對於模型的建立非常重要。
模型只有在準確了解每個token在序列中的位置和上下文情況,才能更好正確預測內容,給出合理輸出。
因此,token的品質、數量對模型效果有直接影響。
今年開始,越來越多大模型發佈時,都會著重強調token數量,例如GooglePaLM 2曝光細節中提到,它訓練用到了3.6萬億個token。
以及許多業界大佬也紛紛表示,token真的很關鍵!
今年從特斯拉跳槽到OpenAI的AI科學家安德烈·卡帕斯(Andrej Karpathy)就曾在演講中表示:
更多token能讓模型更好思考。

而且他強調,模型的效能並不只由參數規模來決定。
例如LLaMA的參數規模遠小於GPT-3(65B vs 175B),但由於它用更多token進行訓練(1.4T vs 300B),所以LLaMA更強大。
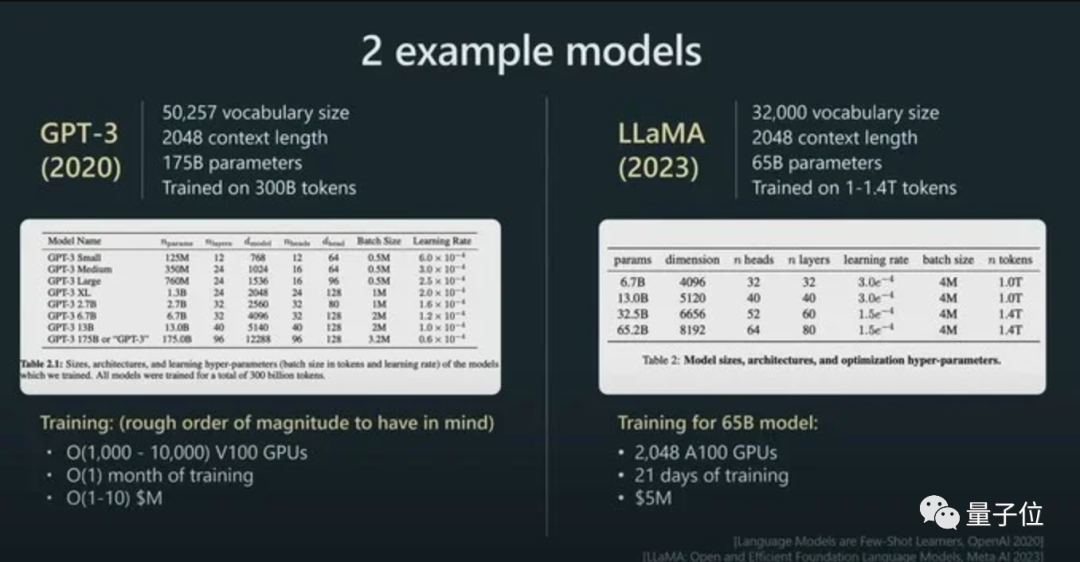
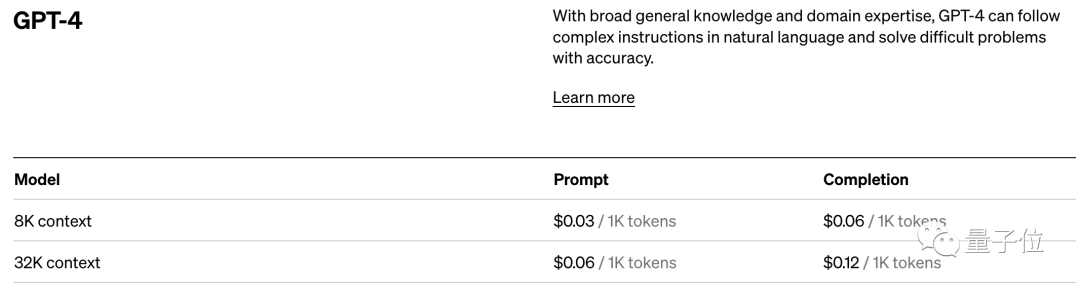
而憑藉著對模型表現的直接影響,token還是AI模型的計費標準。
以OpenAI的定價標準為例,他們以1K個token為單位進行計費,不同模型、不同類型的token價格不同。
總之,踏進AI大模型領域的大門後,就會發現token是繞不開的知識點。
嗯,甚至衍生出了token文學……
不過值得一提的是,token在中文世界裡到底該翻譯成啥,現在還沒有完全定下來。
直譯「令牌」總是有點怪怪的。
GPT-4覺得叫「詞元」或「標記」比較好,你覺得呢?

參考連結:
[1]https://www.reddit.com/r/ChatGPT/comments/13xxehx/chatgpt_is_unable_to_reverse_words/
[2]https://help.openai.com/en/articles/4936856-what-are-tokens-and-how-to-count-them
[3]https://openai.com /pricing
以上是吳恩達ChatGPT課爆火:AI放棄了倒寫單詞,但理解了整個世界的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

AI Hentai Generator
免費產生 AI 無盡。

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)
熱門話題



 centos關機命令行
Apr 14, 2025 pm 09:12 PM
centos關機命令行
Apr 14, 2025 pm 09:12 PM
CentOS 關機命令為 shutdown,語法為 shutdown [選項] 時間 [信息]。選項包括:-h 立即停止系統;-P 關機後關電源;-r 重新啟動;-t 等待時間。時間可指定為立即 (now)、分鐘數 ( minutes) 或特定時間 (hh:mm)。可添加信息在系統消息中顯示。
 如何檢查CentOS HDFS配置
Apr 14, 2025 pm 07:21 PM
如何檢查CentOS HDFS配置
Apr 14, 2025 pm 07:21 PM
檢查CentOS系統中HDFS配置的完整指南本文將指導您如何有效地檢查CentOS系統上HDFS的配置和運行狀態。以下步驟將幫助您全面了解HDFS的設置和運行情況。驗證Hadoop環境變量:首先,確認Hadoop環境變量已正確設置。在終端執行以下命令,驗證Hadoop是否已正確安裝並配置:hadoopversion檢查HDFS配置文件:HDFS的核心配置文件位於/etc/hadoop/conf/目錄下,其中core-site.xml和hdfs-site.xml至關重要。使用
 CentOS上GitLab的備份方法有哪些
Apr 14, 2025 pm 05:33 PM
CentOS上GitLab的備份方法有哪些
Apr 14, 2025 pm 05:33 PM
CentOS系統下GitLab的備份與恢復策略為了保障數據安全和可恢復性,CentOS上的GitLab提供了多種備份方法。本文將詳細介紹幾種常見的備份方法、配置參數以及恢復流程,幫助您建立完善的GitLab備份與恢復策略。一、手動備份利用gitlab-rakegitlab:backup:create命令即可執行手動備份。此命令會備份GitLab倉庫、數據庫、用戶、用戶組、密鑰和權限等關鍵信息。默認備份文件存儲於/var/opt/gitlab/backups目錄,您可通過修改/etc/gitlab
 CentOS上PyTorch的GPU支持情況如何
Apr 14, 2025 pm 06:48 PM
CentOS上PyTorch的GPU支持情況如何
Apr 14, 2025 pm 06:48 PM
在CentOS系統上啟用PyTorchGPU加速,需要安裝CUDA、cuDNN以及PyTorch的GPU版本。以下步驟將引導您完成這一過程:CUDA和cuDNN安裝確定CUDA版本兼容性:使用nvidia-smi命令查看您的NVIDIA顯卡支持的CUDA版本。例如,您的MX450顯卡可能支持CUDA11.1或更高版本。下載並安裝CUDAToolkit:訪問NVIDIACUDAToolkit官網,根據您顯卡支持的最高CUDA版本下載並安裝相應的版本。安裝cuDNN庫:前
 docker原理詳解
Apr 14, 2025 pm 11:57 PM
docker原理詳解
Apr 14, 2025 pm 11:57 PM
Docker利用Linux內核特性,提供高效、隔離的應用運行環境。其工作原理如下:1. 鏡像作為只讀模板,包含運行應用所需的一切;2. 聯合文件系統(UnionFS)層疊多個文件系統,只存儲差異部分,節省空間並加快速度;3. 守護進程管理鏡像和容器,客戶端用於交互;4. Namespaces和cgroups實現容器隔離和資源限制;5. 多種網絡模式支持容器互聯。理解這些核心概念,才能更好地利用Docker。
 centos安裝mysql
Apr 14, 2025 pm 08:09 PM
centos安裝mysql
Apr 14, 2025 pm 08:09 PM
在 CentOS 上安裝 MySQL 涉及以下步驟:添加合適的 MySQL yum 源。執行 yum install mysql-server 命令以安裝 MySQL 服務器。使用 mysql_secure_installation 命令進行安全設置,例如設置 root 用戶密碼。根據需要自定義 MySQL 配置文件。調整 MySQL 參數和優化數據庫以提升性能。
 CentOS下GitLab的日誌如何查看
Apr 14, 2025 pm 06:18 PM
CentOS下GitLab的日誌如何查看
Apr 14, 2025 pm 06:18 PM
CentOS系統下查看GitLab日誌的完整指南本文將指導您如何查看CentOS系統中GitLab的各種日誌,包括主要日誌、異常日誌以及其他相關日誌。請注意,日誌文件路徑可能因GitLab版本和安裝方式而異,若以下路徑不存在,請檢查GitLab安裝目錄及配置文件。一、查看GitLab主要日誌使用以下命令查看GitLabRails應用程序的主要日誌文件:命令:sudocat/var/log/gitlab/gitlab-rails/production.log此命令會顯示produc
 CentOS上PyTorch的分佈式訓練如何操作
Apr 14, 2025 pm 06:36 PM
CentOS上PyTorch的分佈式訓練如何操作
Apr 14, 2025 pm 06:36 PM
在CentOS系統上進行PyTorch分佈式訓練,需要按照以下步驟操作:PyTorch安裝:前提是CentOS系統已安裝Python和pip。根據您的CUDA版本,從PyTorch官網獲取合適的安裝命令。對於僅需CPU的訓練,可以使用以下命令:pipinstalltorchtorchvisiontorchaudio如需GPU支持,請確保已安裝對應版本的CUDA和cuDNN,並使用相應的PyTorch版本進行安裝。分佈式環境配置:分佈式訓練通常需要多台機器或單機多GPU。所
