

Redis叢集實例分析

一、Why K8s
1、資源隔離
目前的Redis Cluster部署在實體機叢集上,為了提高資源利用率節省成本,多業務線的Redis群集都是混布的。由於沒有做CPU的資源隔離,經常出現某Redis節點CPU使用率過高導致其他Redis叢集的節點爭搶不到CPU資源造成時延抖動。因為不同的集群混布,這類問題很難快速定位,影響維運效率。 K8s容器化部署可以指定 CPU request 和 CPU limit ,在提高資源利用率的同時避免了資源爭搶。
2、自動化部署
目前Redis Cluster在實體機上的部署過程十分繁瑣,需要透過查看元資訊資料庫來尋找有剩餘資源的機器,手動修改很多設定檔再逐一部署節點,最後使用redis_trib工具建立集群,新集群的初始化工作經常需要一兩個小時。
K8s透過StatefulSet部署Redis集群,使用configmap管理設定文件,新集群部署時間只需要幾分鐘,大大提高了維運效率。
二、How K8s
客戶端透過LVS的VIP統一接入,透過Redis Proxy轉送服務請求到Redis Cluster叢集。這裡我們引入了Redis Proxy來轉發請求。
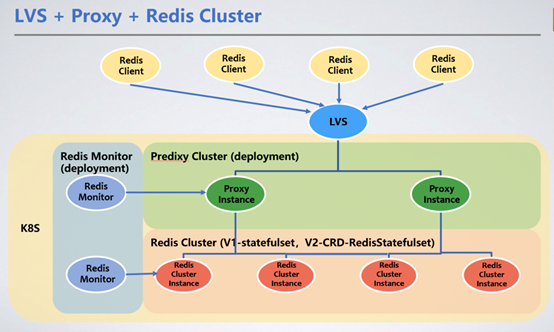
1、Redis Cluster部署方式
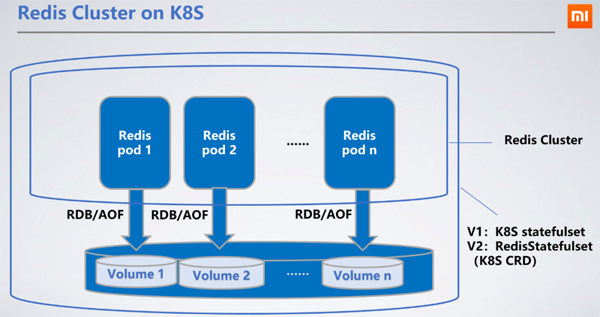
Redis部署為StatefulSet,作為有狀態的服務,選擇StatefulSet最為合理,可以將節點的RDB/AOF持久化到分散式儲存中。當節點重新啟動漂移到其他機器上時,可透過掛載的PVC(PersistentVolumeClaim)拿到原來的RDB/AOF來同步資料。
Ceph區塊服務是我們所選的持久化儲存PV(PersistentVolume)。 Ceph的讀寫效能較本地硬碟差,會導致讀寫延遲增加100~200毫秒。分散式儲存的讀寫延遲並沒有影響服務,因為Redis的RDB/AOF寫出是異步的。
2、Proxy選型
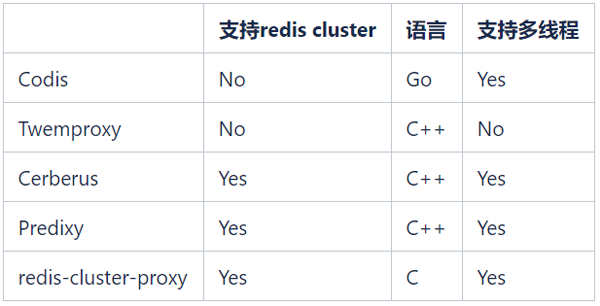
#開源的Redis Proxy很多,常見的開源Redis Proxy如下:
#我們希望能夠繼續使用Redis Cluster來管理Redis集群,所以Codis和Twemproxy不再考慮。 redis-cluster-proxy是Redis官方在6.0版推出的支援Redis Cluster協定的Proxy,但目前還沒有穩定版,暫時也無法大規模應用。
備選就只有Cerberus和Predixy兩種。以下是我們在K8s環境中對Cerberus和Predixy進行的效能測試結果:
#測試環境
測試工具: redis-benchmark
#Proxy CPU: 2 core
Client CPU: 2 core
Redis Cluster: 3 master nodes, 1 CPU per node
測試結果
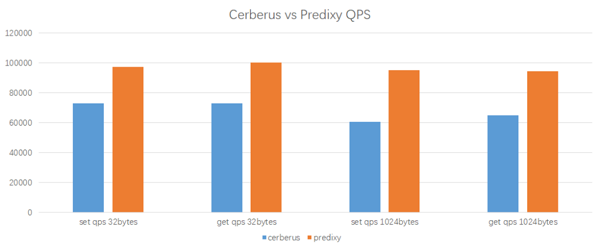
Predixy在相同的工作負載和配置下,能夠獲得更高的QPS,而其延遲也與Cerberus相當接近。綜合來看,Predixy比Cerberus的效能高33%~60%,且資料的key/value越大,Predixy優勢越明顯,所以最後我們選擇了Predixy。
為了適應業務和K8s環境,在上線前我們對Predixy做了大量的改動,增加了很多新的功能,例如動態切換後端Redis Cluster、黑白名單、異常操作審計等。
3、Proxy部署方式
由於其無狀態輕量化的部署特性,使用代理程式(Proxy)作為部署方式,經由負載平衡(LB)提供服務,能夠輕鬆地實現動態的擴容和縮容。同時,我們為Proxy開發了動態切換後端Redis Cluster的功能,可實現線上新增和切換Redis Cluster。
4、Proxy自動擴縮容方式
我們使用K8s原生的HPA(Horizontal Pod Autoscaler)來實作Proxy的動態擴縮容。當Proxy所有pod的平均CPU使用率超過一定閾值時,會自動觸發擴容,HPA會將Proxy的replica數加1,之後LVS就會偵測到新的Proxy pod並將一部分流量切過去。當CPU使用率超過規定的閾值後進行擴容,若仍未達到要求則會持續觸發擴容邏輯。但在擴容成功5分鐘內,不論CPU使用率降到多低,都不會觸發縮容邏輯,這樣就避免了頻繁的擴縮容對集群穩定性帶來的影響。
HPA可設定叢集的最少(MINPODS)和最多(MAXPODS)pod數量,叢集負載再低也不會縮容到MINPODS以下數量的pods。建議客戶自行判斷其實際業務狀況以確定MINPODS和MAXPODS的取值。
三、Why Proxy
1、Redis pod重啟可導致IP變化
使用Redis Cluster的Redis客戶端,都需要設定叢集的部分IP和Port,用於客戶端重新啟動時找出Redis Cluster的入口。對於實體機叢集部署的Redis節點,即便遇到執行個體重新啟動或機器重啟,IP和Port都可以保持不變,客戶端仍能找到Redis Cluster的拓樸。但部署在K8s上的Redis Cluster,pod重啟是不保證IP不變的(即便是重啟在原來的K8s node上),這樣客戶端重啟時,就可能會找不到Redis Cluster的入口。
透過在客戶端與Redis Cluster之間加上Proxy,就對客戶端屏蔽了Redis Cluster的訊息,Proxy可以動態感知Redis Cluster的拓樸變化,客戶端只需要將LVS的IP:Port作為入口,請求轉發到Proxy上,即可以像使用單機版Redis一樣使用Redis Cluster集群,而不需要Redis智慧型客戶端。
2、Redis處理連線負載高
在6.0版本之前,Redis都是單執行緒處理大部分任務的。當Redis節點的連接較高時,Redis需要消耗大量的CPU資源來處理這些連接,導致時延升高。有了Proxy之後,大量連接都在Proxy上,而Proxy跟Redis實例之間只保持很少的連接,這樣降低了Redis的負擔,避免了因為連接增加而導致的Redis時延升高。
3、叢集遷移切換需要應用重啟
在使用過程中,隨著業務的成長,Redis叢集的資料量會持續增加,當每個節點的資料量過高時,BGSAVE的時間會大大延長,降低叢集的可用性。同時QPS的增加也會導致每個節點的CPU使用率增加。這都需要增加擴容集群來解決。目前Redis Cluster的橫向擴展能力不是很好,原生的slots搬移方案效率很低。新增節點後,有些客戶端例如Lettuce,會因為安全機制無法辨識新節點。另外遷移時間也完全無法預估,遷移過程中遇到問題也無法回退。
目前實體機叢集的擴容方案是:
按需建立新叢集;
使用同步工具將資料從舊集群同步到新集群;
確認資料無誤後,跟業務溝通,重啟服務切換到新集群。
整個流程繁瑣且風險較大,還需要業務重新啟動服務。
有了Proxy層,可以將後端的建立、同步和切換叢集對客戶端屏蔽掉。新舊集群同步完成之後,向Proxy發送指令就可以將連線換到新集群,可以實現對客戶端完全無感知的集群擴縮容。
4、資料安全風險
Redis是透過AUTH來實現鑑權操作,客戶端直連Redis,密碼還是需要在客戶端保存。使用代理,客戶端只需要透過代理的密碼來存取Redis,而不必知道Redis的密碼。 Proxy也限制了FLUSHDB、CONFIG SET等操作,避免了客戶誤操作清空資料或修改Redis配置,大大提高了系統的安全性。
同時,Redis並沒有提供審計功能。我們已經在代理伺服器上新增了高風險操作的日誌記錄功能,不會影響整體效能的前提下,提供了稽核能力。
四、Proxy帶來的問題
#1、多一跳帶來的延遲
# Proxy在客戶端和Redis實例之間,客戶端存取Redis資料需要先存取Proxy再存取Redis節點,多了一跳,會導致時延增加。根據測試結果,增加一跳會導致延遲增加0.2~0.3ms,但通常對於業務來說這是可以接受的。
2、Pod漂移造成IP變化
在K8s上,代理(Proxy)透過部署(deployment)實現,因此同樣存在節點重啟導致IP變化的問題。我們K8s的LB方案可以感知Proxy的IP變化,動態的將LVS的流量切到重啟後的Proxy。
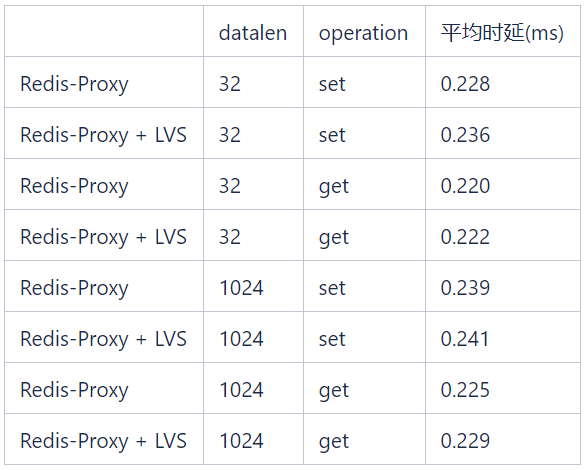
3、LVS帶來的時延
在下表所示的測試中,不同資料長度的get/set運算所引入的LVS時延都小於0.1 ms。
五、K8s帶來的好處
1、部署方便
透過維運平台呼叫K8s API部署集群,大大提高了維運效率。
2、解決連接埠管理問題
目前小米在實體機上部署Redis實例是透過連接埠來區分的,且下線的連接埠無法重複使用,也就是說整個公司每個Redis實例都有唯一的連接埠號碼。目前65535個連接埠已經用到了40000多,以現在的業務發展速度,將在兩年內耗盡連接埠資源。而透過K8s部署,每個Redis實例對應的K8s pod都有獨立的IP,不存在連接埠耗盡問題和複雜的管理問題。
3、降低客戶使用門檻
#對應用程式來說,只需要使用單機版的非智慧型客戶端連接VIP,降低了使用門檻,避免了繁瑣複雜的參數設定。應用程式無需自行處理Redis Cluster的拓撲,因為VIP和連接埠是靜態固定的。
4、提高客戶端效能
使用非智慧型客戶端還可以降低客戶端的負載,因為智慧型客戶端需要在客戶端對key進行hash以確定將請求傳送到哪個Redis節點,在QPS比較高的情況下會消耗客戶端機器的CPU資源。當然,為了讓客戶端應用遷移更容易,我們也讓Proxy支援了智慧型客戶端協定。
5、動態升級和擴縮容
Proxy支援動態添加切換Redis Cluster的功能,這樣Redis Cluster的叢集升級和擴容切換過程可以做到對業務端完全無感知。例如,業務方使用30個節點的Redis Cluster集群,由於業務量的增加,資料量和QPS都成長的很快,需要將集群規模擴充兩倍。如果在原有的實體機上擴容,需要以下流程:
協調資源,部署60個節點的新叢集;
手動設定遷移工具,將目前叢集的資料移轉到新叢集;
驗證資料無誤後,通知業務方修改Redis Cluster連線池拓撲,重新啟動服務。
雖然Redis Cluster支援線上擴容,但是擴容過程中slots搬移會對線上業務造成影響,同時遷移時間不可控,所以現階段很少採用這種方式,只有在資源嚴重不足時才會偶爾使用。
在新的K8s架構下,遷移過程如下:
# 透過API介面一鍵建立60個節點的新叢集;
同樣透過API介面一鍵建立叢集同步工具,將資料遷移到新叢集;
# 驗證資料無誤後,傳送指令新增指令至Proxy資訊並完成切換。
整個流程對業務端完全無感知。
叢集升級也很方便:如果業務方能接受一定的延遲毛刺,可以在低峰值時透過StatefulSet滾動升級的方式來實現;如果業務對延遲有要求,可以透過建立新叢集遷移數據的方式來實現。
6、提高服務穩定性和資源利用率
利用K8s自帶的資源隔離功能,讓不同類型的應用程式可以混合部署。這不僅可以提高資源利用率,還能確保服務的穩定性。
六、遇到的問題
1、Pod重啟導致資料遺失
K8s的pod碰到問題重開機時,由於重開機速度過快,會在Redis Cluster叢集發現並切割主前將pod重新啟動。如果pod上的Redis是slave,不會造成什麼影響。但如果Redis是master,且沒有AOF,重啟後原先記憶體的資料都被清空,Redis會reload之前儲存的RDB文件,但是RDB檔案並不是即時的資料。之後slave也會跟著把自己的資料同步成之前的RDB檔案中的資料鏡像,會造成部分資料遺失。
在部署StatefulSet時,Pod名稱會遵循一定的命名格式,包含固定的編號,因此StatefulSet是一種有狀態服務。我們在初始化Redis Cluster時,將相鄰編號的pod設定為主從關係。重啟pod時,透過pod名稱確定它的slave,在重啟pod前向從節點發送cluster failover指令,強制將活著的從節點切主。這樣在重啟後,該節點會自動以從節點方式加入叢集。
LVS映射時延
Proxy的pod是透過LVS實現負載平衡的,LVS對後端IP:Port的對應生效有一定的時延,Proxy節點突然下線會導致部分連線遺失。為了最小化Proxy運維對業務的影響,我們已在Proxy的部署模板中添加了以下選項:
lifecycle: preStop: exec: command: - sleep - "171"
對於正常的Proxy pod下線,例如集群縮容、滾動更新Proxy版本以及其它K8s可控的pod下線,在pod下線前會發訊息給LVS並等待171秒,這段時間足夠LVS將這個pod的流量逐漸切到其他pod上,對業務無感知。
2、K8s StatefulSet無法滿足Redis Cluster部署要求
K8s原生的StatefulSet無法完全滿足Redis Cluster部署的要求:
#在Redis Cluster中,不能將具有主備關係的節點部署在同一台機器上。這個很好理解,如果該機器宕機,會導致這個資料分片不可用。
2)Redis Cluster不允許叢集超過一半的主節點失效,因為如果超過一半主節點失效,就無法有足夠的節點投票來滿足gossip協定的要求。因為Redis Cluster的主備是可能隨時切換的,我們無法避免同一個機器上的所有節點都是主節點這種情況,所以在部署時不能允許集群中超過1/4的節點部署在同一台機器上。
為了滿足上面的要求,原生StatefulSet可以透過 anti-affinity 功能來確保相同叢集在同一台機器上只部署一個節點,但是這樣機器利用率很低。
因此我們開發了基於StatefulSet的CRD:RedisStatefulSet,會採用多種策略部署Redis節點。在RedisStatefulSet中加入了一些用於管理Redis的功能。這些我們將會在其他文章中繼續詳細探討。
七、總結
數十個Redis集群已經在K8s上部署並運行了六個月以上,這些集群涉及到集團內部的多個業務。由於K8s的快速部署和故障遷移能力,這些叢集的運維工作量比實體機上的Redis叢集低很多,穩定性也得到了充分的驗證。
在維運過程中我們也遇到了不少問題,文章中提到的許多功能都是根據實際需求提煉出來的。在接下來的過程中,仍需要逐步解決許多問題,以提升資源利用效率和服務品質。
1、混布Vs. 獨立部署
物理機的Redis實例是獨立部署的,單一實體機上部署的都是Redis實例,這樣有利於管理,但是資源利用率並不高。 Redis實例使用了CPU、記憶體和網路IO,但儲存空間基本上都是浪費的。在K8s上部署Redis實例,其所在的機器上可能也會部署其他任意類型的服務,這樣雖然可以提高機器的利用率,但是對於Redis這樣的可用性和時延要求都很高的服務來說,如果因為機器記憶體不足而被驅逐,是不能接受的。這就需要維運人員監控所有部署了Redis實例的機器內存,一旦內存不足,就切主和遷移節點,但這樣又增加運維的工作量。
如果混合部署中還有其他高網路吞吐量的應用程序,那麼也可能會對Redis服務產生負面影響。雖然K8s的anti-affinity功能可以將Redis實例選擇性地部署到沒有這類應用的機器上,但是在機器資源緊張時,還是無法避免這種情況。
2、Redis Cluster管理
Redis Cluster是一個P2P無中心節點的叢集架構,依賴gossip協定傳播協同自動化修復叢集的狀態,節點上下線和網路問題都可能導致Redis Cluster的部分節點狀態出現問題,例如會在叢集拓撲中出現failed或handshake狀態的節點,甚至是腦裂。對這個異常狀態,我們可以在Redis CRD上增加更多的功能來逐步解決,進一步提高維運效率。
3、稽核與安全性
Redis僅提供了Auth密碼認證保護功能,缺乏權限管理,因此安全性相對較低。透過Proxy,我們可以透過密碼區分客戶端類型,管理員和一般使用者使用不同的密碼登錄,可執行的操作權限也不同,這樣就可以實現權限管理和操作審計等功能。
4、支援多Redis Cluster
單一Redis Cluster由於gossip協定的限制,橫向擴展能力有限,叢集規模在300個節點時,節點選主這類拓樸變更的效率就明顯降低。同時,由於單一Redis實例的容量不宜過高,單一Redis Cluster也很難支援TB以上的資料規模。透過Proxy,我們可以對key做邏輯分片,這樣單一Proxy就可以接入多個Redis Cluster,從客戶端的視角來看,就等於接入了一個能夠支援更大資料規模的Redis叢集。
以上是Redis叢集實例分析的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 redis集群模式怎麼搭建
Apr 10, 2025 pm 10:15 PM
redis集群模式怎麼搭建
Apr 10, 2025 pm 10:15 PM
Redis集群模式通過分片將Redis實例部署到多個服務器,提高可擴展性和可用性。搭建步驟如下:創建奇數個Redis實例,端口不同;創建3個sentinel實例,監控Redis實例並進行故障轉移;配置sentinel配置文件,添加監控Redis實例信息和故障轉移設置;配置Redis實例配置文件,啟用集群模式並指定集群信息文件路徑;創建nodes.conf文件,包含各Redis實例的信息;啟動集群,執行create命令創建集群並指定副本數量;登錄集群執行CLUSTER INFO命令驗證集群狀態;使
 redis數據怎麼清空
Apr 10, 2025 pm 10:06 PM
redis數據怎麼清空
Apr 10, 2025 pm 10:06 PM
如何清空 Redis 數據:使用 FLUSHALL 命令清除所有鍵值。使用 FLUSHDB 命令清除當前選定數據庫的鍵值。使用 SELECT 切換數據庫,再使用 FLUSHDB 清除多個數據庫。使用 DEL 命令刪除特定鍵。使用 redis-cli 工具清空數據。
 redis怎麼讀取隊列
Apr 10, 2025 pm 10:12 PM
redis怎麼讀取隊列
Apr 10, 2025 pm 10:12 PM
要從 Redis 讀取隊列,需要獲取隊列名稱、使用 LPOP 命令讀取元素,並處理空隊列。具體步驟如下:獲取隊列名稱:以 "queue:" 前綴命名,如 "queue:my-queue"。使用 LPOP 命令:從隊列頭部彈出元素並返回其值,如 LPOP queue:my-queue。處理空隊列:如果隊列為空,LPOP 返回 nil,可先檢查隊列是否存在再讀取元素。
 redis指令怎麼用
Apr 10, 2025 pm 08:45 PM
redis指令怎麼用
Apr 10, 2025 pm 08:45 PM
使用 Redis 指令需要以下步驟:打開 Redis 客戶端。輸入指令(動詞 鍵 值)。提供所需參數(因指令而異)。按 Enter 執行指令。 Redis 返迴響應,指示操作結果(通常為 OK 或 -ERR)。
 centos redis如何配置Lua腳本執行時間
Apr 14, 2025 pm 02:12 PM
centos redis如何配置Lua腳本執行時間
Apr 14, 2025 pm 02:12 PM
在CentOS系統上,您可以通過修改Redis配置文件或使用Redis命令來限制Lua腳本的執行時間,從而防止惡意腳本佔用過多資源。方法一:修改Redis配置文件定位Redis配置文件:Redis配置文件通常位於/etc/redis/redis.conf。編輯配置文件:使用文本編輯器(例如vi或nano)打開配置文件:sudovi/etc/redis/redis.conf設置Lua腳本執行時間限制:在配置文件中添加或修改以下行,設置Lua腳本的最大執行時間(單位:毫秒)
 redis怎麼使用鎖
Apr 10, 2025 pm 08:39 PM
redis怎麼使用鎖
Apr 10, 2025 pm 08:39 PM
使用Redis進行鎖操作需要通過SETNX命令獲取鎖,然後使用EXPIRE命令設置過期時間。具體步驟為:(1) 使用SETNX命令嘗試設置一個鍵值對;(2) 使用EXPIRE命令為鎖設置過期時間;(3) 當不再需要鎖時,使用DEL命令刪除該鎖。
 redis命令行怎麼用
Apr 10, 2025 pm 10:18 PM
redis命令行怎麼用
Apr 10, 2025 pm 10:18 PM
使用 Redis 命令行工具 (redis-cli) 可通過以下步驟管理和操作 Redis:連接到服務器,指定地址和端口。使用命令名稱和參數向服務器發送命令。使用 HELP 命令查看特定命令的幫助信息。使用 QUIT 命令退出命令行工具。
 redis過期策略怎麼設置
Apr 10, 2025 pm 10:03 PM
redis過期策略怎麼設置
Apr 10, 2025 pm 10:03 PM
Redis數據過期策略有兩種:定期刪除:定期掃描刪除過期鍵,可通過 expired-time-cap-remove-count、expired-time-cap-remove-delay 參數設置。惰性刪除:僅在讀取或寫入鍵時檢查刪除過期鍵,可通過 lazyfree-lazy-eviction、lazyfree-lazy-expire、lazyfree-lazy-user-del 參數設置。
