

三維點雲的開放世界理解,分類、檢索、字幕和圖像生成樣行

輸入一張搖椅和一匹馬的立體形狀,能得到什麼?


#木推車加馬?得到馬車和電動馬;香蕉加帆船?得到香蕉帆船;蛋加躺椅?得到雞蛋椅。
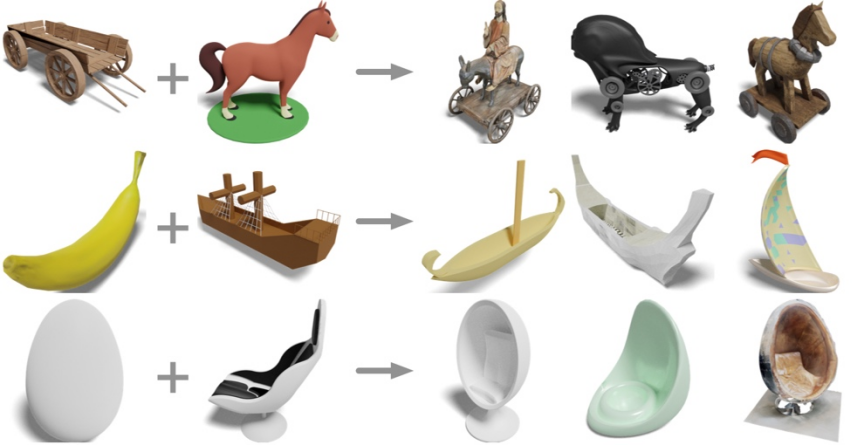
來自UCSD、上海交大、高通團隊的研究者提出最新三維表示模型OpenShape,讓三維形狀的開放世界理解成為可能。
- 論文網址:https://arxiv.org/pdf/2305.10764.pdf
- #專案首頁:https://colin97.github.io/OpenShape/
- #互動demo: https://huggingface.co/spaces/OpenShape/openshape-demo
- #程式碼位址:https://github.com/Colin97/OpenShape_code
透過在多模態資料(點雲- 文字- 影像)上學習三維點雲的原生編碼器,OpenShape 建構了一個三維形狀的表示空間,並與CLIP 的文字和影像空間進行了對齊。由於大規模、多樣的三維預訓練,OpenShape 首次實現三維形狀的開放世界理解,支持零樣本三維形狀分類、多模態三維形狀檢索(文本/ 圖像/ 點雲輸入)、三維點雲的字幕生成和基於三維點雲的圖像生成等跨模態任務。
三維形狀零樣本分類
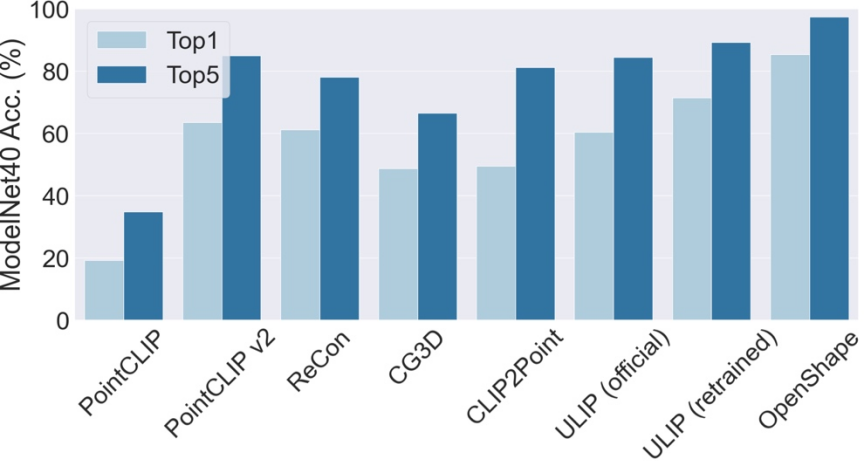
#OpenShape 支援零樣本三維形狀分類。無需額外訓練或微調,OpenShape 在常用的ModelNet40 基準(包含40 個常見類別)上達到了85.3% 的top1 準確率,超過現有零樣本方法24 個百分點,並首次實現與部分全監督方法相當的性能。
OpenShape 在 ModelNet40 上的 top3 和 top5 準確率則分別達到了 96.5% 和 98.0%。
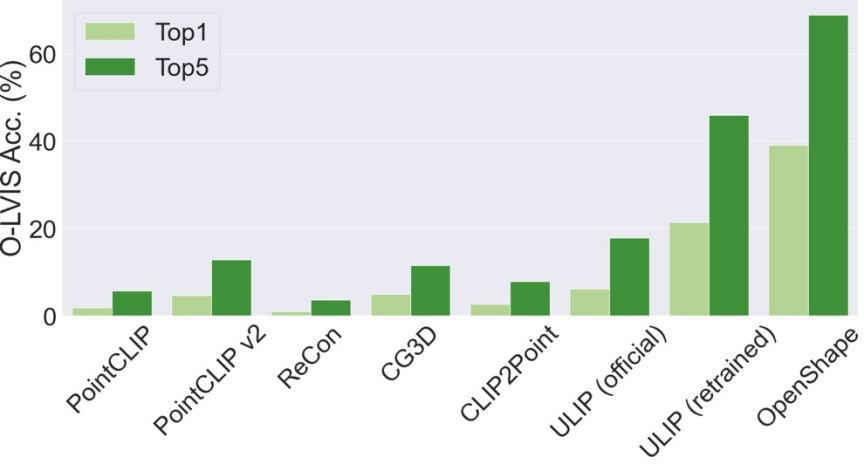
與現有方法主要局限於少數常見物件類別不同,OpenShape 能夠對廣泛的開放世界類別進行分類。在 Objaverse-LVIS 基準上(包含 1156 個物件類別),OpenShape 實現了 46.8% 的 top1 準確率,遠超現有零樣本方法最高只有 6.2% 的準確率。這些結果顯示 OpenShape 具備有效辨識開放世界三維形狀的能力。
多模態三維形狀檢索
透過 OpenShape 的多模態表示,使用者可以對影像、文字或點雲輸入進行三維形狀檢索。研究透過計算輸入表示和三維形狀表示之間的餘弦相似度並尋找 kNN,來從整合資料集中檢索三維形狀。

#圖片輸入的三維形狀檢索
上圖展示了輸入圖片和兩個檢索到的三維形狀。

文字輸入的三維形狀檢索
上圖展示了輸入文字和檢索到的三維形狀。 OpenShape 學到了廣泛的視覺和語義概念,從而支援細粒度的子類別(前兩行)和屬性控制(後兩行,如顏色,形狀,風格及其組合)。

是三維點雲輸入的三維形狀檢索
上圖展示了輸入的三維點雲和兩個檢索到的三維形狀。

#雙輸入的三維形狀檢索
上圖將兩個三維形狀作為輸入,並使用它們的OpenShape 表示來檢索同時最接近兩個輸入的三維形狀。檢索到的形狀巧妙地結合了來自兩個輸入形狀的語義和幾何元素。
基於三維形狀的文字和圖像產生
由於OpenShape 的三維形狀表示與CLIP 的圖像和文字表示空間進行了對齊,因此它們可以與很多基於CLIP 的衍生模型進行結合,從而支援各種跨模態應用。

是三維點雲的字幕產生
透過與現成的圖像字幕模型(ClipCap)結合,OpenShape 實現了三維點雲的字幕生成。

基於三維點雲的圖像產生
透過與現成的文字到圖像的擴散模型(Stable unCLIP)結合,OpenShape 實現了基於三維點雲的圖像生成(支援可選的文本提示)。

#更多的基於三維點雲的圖片產生範例
訓練細節
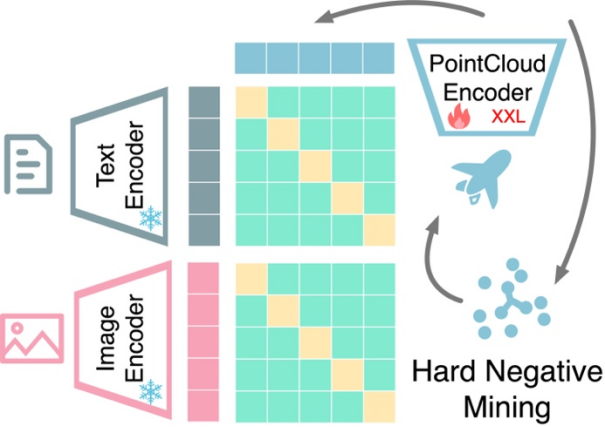
基於對比學習的多模態表示對齊:OpenShape 訓練了一個三維原生編碼器,它將三維點雲作為輸入,來提取三維形狀的表示。繼先前的工作,研究利用多模態對比學習來與 CLIP 的圖像和文字表示空間進行對齊。與先前的工作不同,OpenShape 旨在學習更通用和可擴展的聯合表示空間。研究的重點主要在於擴大三維表示學習的規模和應對相應的挑戰,從而真正實現開放世界下的三維形狀理解。
集成多个三维形状数据集:由于训练数据的规模和多样性在学习大规模三维形状表示中起着至关重要的作用,因此研究集成了四个当前最大的公开三维数据集进行训练。如下图所示,研究的训练数据包含了 87.6 万个训练形状。在这四个数据集中,ShapeNetCore、3D-FUTURE 和 ABO 包含经过人工验证的高质量三维形状,但仅涵盖有限数量的形状和数十个类别。Objaverse 数据集是最近发布的三维数据集,包含显著更多的三维形状并涵盖更多样的物体类别。然而 Objaverse 中的形状主要由网络用户上传,未经人工验证,因此质量参差不齐,分布极不平衡,需要进一步处理。

文本过滤和丰富:研究发现仅在三维形状和二维图像之间应用对比学习不足以推动三维形状和文本空间的对齐,即使在对大规模数据集进行训练时也是如此。研究推测这是由于 CLIP 的语言和图像表示空间中固有的领域差距引起的。因此,研究需要显式地将三维形状与文本进行对齐。然而来自原始三维数据集的文本标注通常面临着缺失、错误、或内容粗略单一等问题。为此,本文提出了三种策略来对文本进行过滤和丰富,从而提高文本标注的质量:使用 GPT-4 对文本进行过滤、对三维模型的二维渲染图进行字幕生成和图像检索。
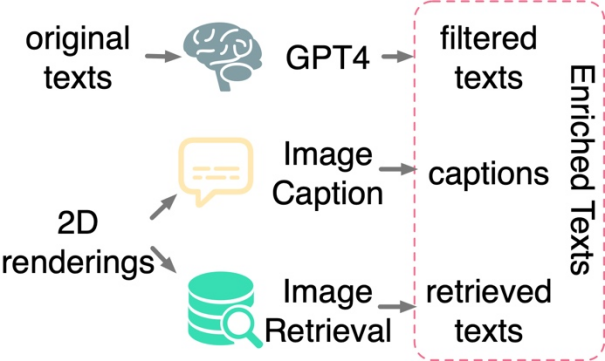
研究提出了三种策略来自动过滤和丰富原始数据集中的嘈杂文本。
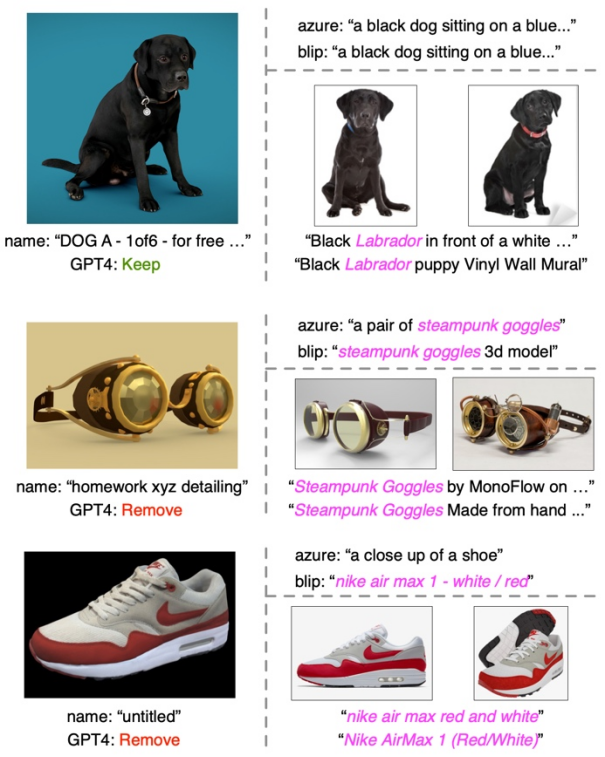
文本过滤和丰富示例
在每个示例中,左侧部分展示了缩略图、原始形状名称和 GPT-4 的过滤结果。右上部分展示来来自两个字幕模型的图像字幕,而右下部分显示检索到的图像及其相应的文本。
扩大三维骨干网络。由于先前关于三维点云学习的工作主要针对像 ShapeNet 这样的小规模三维数据集, 这些骨干网络可能不能直接适用于我们的大规模的三维训练,需要相应地扩大骨干网络的规模。研究发现在不同大小的数据集上进行训练,不同的三维骨干网络表现出不同的行为和可扩展性。其中基于 Transformer 的 PointBERT 和基于三维卷积的 SparseConv 表现出更强大的性能和可扩展性,因而选择他们作为三维骨干网络。
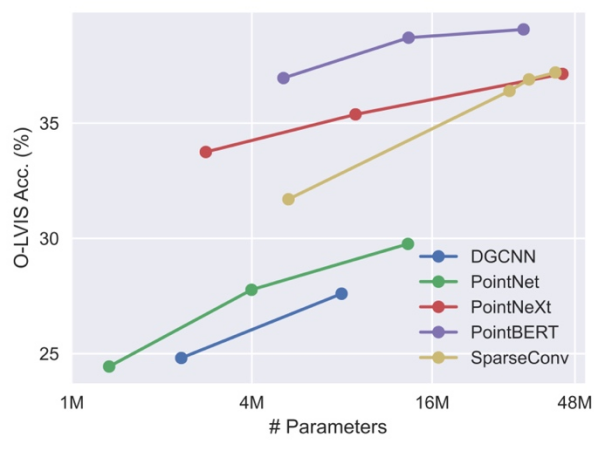
在集成数据集上扩展三维骨干模型的大小时,不同骨干网络的性能和可扩展性比较。
困难负例挖掘:该研究的集成数据集表现出高度的类别不平衡。一些常见的类别,比如建筑,可能占据了数万个形状,而许多其他类别,比如海象和钱包,只有几十个甚至更少的形状,代表性不足。因此,当随机构建批次进行对比学习时,来自两个容易混淆的类别(例如苹果和樱桃)的形状不太可能出现在同一批次中被对比。为此,本文提出了一种离线的困难负例挖掘策略,以提高训练效率和性能。
欢迎到 HuggingFace 上尝试交互 demo。
以上是三維點雲的開放世界理解,分類、檢索、字幕和圖像生成樣行的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

AI Hentai Generator
免費產生 AI 無盡。

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)
熱門話題



 centos關機命令行
Apr 14, 2025 pm 09:12 PM
centos關機命令行
Apr 14, 2025 pm 09:12 PM
CentOS 關機命令為 shutdown,語法為 shutdown [選項] 時間 [信息]。選項包括:-h 立即停止系統;-P 關機後關電源;-r 重新啟動;-t 等待時間。時間可指定為立即 (now)、分鐘數 ( minutes) 或特定時間 (hh:mm)。可添加信息在系統消息中顯示。
 如何檢查CentOS HDFS配置
Apr 14, 2025 pm 07:21 PM
如何檢查CentOS HDFS配置
Apr 14, 2025 pm 07:21 PM
檢查CentOS系統中HDFS配置的完整指南本文將指導您如何有效地檢查CentOS系統上HDFS的配置和運行狀態。以下步驟將幫助您全面了解HDFS的設置和運行情況。驗證Hadoop環境變量:首先,確認Hadoop環境變量已正確設置。在終端執行以下命令,驗證Hadoop是否已正確安裝並配置:hadoopversion檢查HDFS配置文件:HDFS的核心配置文件位於/etc/hadoop/conf/目錄下,其中core-site.xml和hdfs-site.xml至關重要。使用
 CentOS上GitLab的備份方法有哪些
Apr 14, 2025 pm 05:33 PM
CentOS上GitLab的備份方法有哪些
Apr 14, 2025 pm 05:33 PM
CentOS系統下GitLab的備份與恢復策略為了保障數據安全和可恢復性,CentOS上的GitLab提供了多種備份方法。本文將詳細介紹幾種常見的備份方法、配置參數以及恢復流程,幫助您建立完善的GitLab備份與恢復策略。一、手動備份利用gitlab-rakegitlab:backup:create命令即可執行手動備份。此命令會備份GitLab倉庫、數據庫、用戶、用戶組、密鑰和權限等關鍵信息。默認備份文件存儲於/var/opt/gitlab/backups目錄,您可通過修改/etc/gitlab
 CentOS上PyTorch的GPU支持情況如何
Apr 14, 2025 pm 06:48 PM
CentOS上PyTorch的GPU支持情況如何
Apr 14, 2025 pm 06:48 PM
在CentOS系統上啟用PyTorchGPU加速,需要安裝CUDA、cuDNN以及PyTorch的GPU版本。以下步驟將引導您完成這一過程:CUDA和cuDNN安裝確定CUDA版本兼容性:使用nvidia-smi命令查看您的NVIDIA顯卡支持的CUDA版本。例如,您的MX450顯卡可能支持CUDA11.1或更高版本。下載並安裝CUDAToolkit:訪問NVIDIACUDAToolkit官網,根據您顯卡支持的最高CUDA版本下載並安裝相應的版本。安裝cuDNN庫:前
 docker原理詳解
Apr 14, 2025 pm 11:57 PM
docker原理詳解
Apr 14, 2025 pm 11:57 PM
Docker利用Linux內核特性,提供高效、隔離的應用運行環境。其工作原理如下:1. 鏡像作為只讀模板,包含運行應用所需的一切;2. 聯合文件系統(UnionFS)層疊多個文件系統,只存儲差異部分,節省空間並加快速度;3. 守護進程管理鏡像和容器,客戶端用於交互;4. Namespaces和cgroups實現容器隔離和資源限制;5. 多種網絡模式支持容器互聯。理解這些核心概念,才能更好地利用Docker。
 centos安裝mysql
Apr 14, 2025 pm 08:09 PM
centos安裝mysql
Apr 14, 2025 pm 08:09 PM
在 CentOS 上安裝 MySQL 涉及以下步驟:添加合適的 MySQL yum 源。執行 yum install mysql-server 命令以安裝 MySQL 服務器。使用 mysql_secure_installation 命令進行安全設置,例如設置 root 用戶密碼。根據需要自定義 MySQL 配置文件。調整 MySQL 參數和優化數據庫以提升性能。
 CentOS下GitLab的日誌如何查看
Apr 14, 2025 pm 06:18 PM
CentOS下GitLab的日誌如何查看
Apr 14, 2025 pm 06:18 PM
CentOS系統下查看GitLab日誌的完整指南本文將指導您如何查看CentOS系統中GitLab的各種日誌,包括主要日誌、異常日誌以及其他相關日誌。請注意,日誌文件路徑可能因GitLab版本和安裝方式而異,若以下路徑不存在,請檢查GitLab安裝目錄及配置文件。一、查看GitLab主要日誌使用以下命令查看GitLabRails應用程序的主要日誌文件:命令:sudocat/var/log/gitlab/gitlab-rails/production.log此命令會顯示produc
 CentOS上PyTorch的分佈式訓練如何操作
Apr 14, 2025 pm 06:36 PM
CentOS上PyTorch的分佈式訓練如何操作
Apr 14, 2025 pm 06:36 PM
在CentOS系統上進行PyTorch分佈式訓練,需要按照以下步驟操作:PyTorch安裝:前提是CentOS系統已安裝Python和pip。根據您的CUDA版本,從PyTorch官網獲取合適的安裝命令。對於僅需CPU的訓練,可以使用以下命令:pipinstalltorchtorchvisiontorchaudio如需GPU支持,請確保已安裝對應版本的CUDA和cuDNN,並使用相應的PyTorch版本進行安裝。分佈式環境配置:分佈式訓練通常需要多台機器或單機多GPU。所
