

精準推薦的秘術:阿里解耦域適應無偏召回模型詳解


一、場景介紹
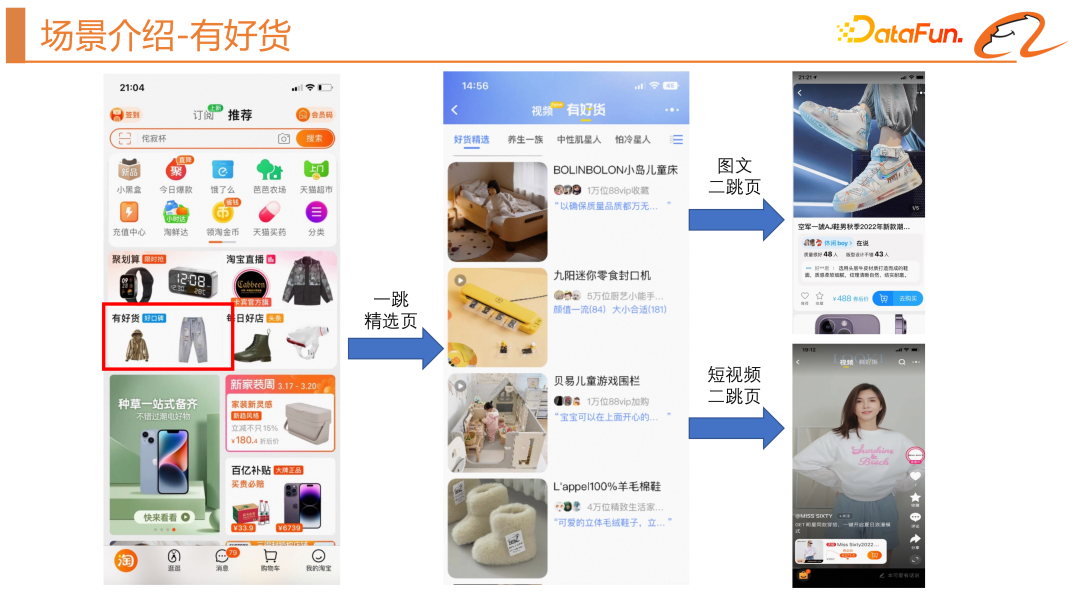
首先來介紹一下本文涉及的場景— 「有好貨」場景。它的位置是在淘寶首頁的四宮格,分為一跳精選頁和二跳承接頁。承接頁主要有兩種形式,一種是圖文的承接頁,另一種是短視頻的承接頁。這個場景的目標主要是為使用者提供滿意的好貨,帶動 GMV 的成長,從而進一步撬動達人的供給。
二、流行度偏差是什麼,為什麼
#接下來進入本文的重點,流行偏差。流行度偏差是什麼?為什麼會產生流行度偏差?
1、流行度偏差是什麼
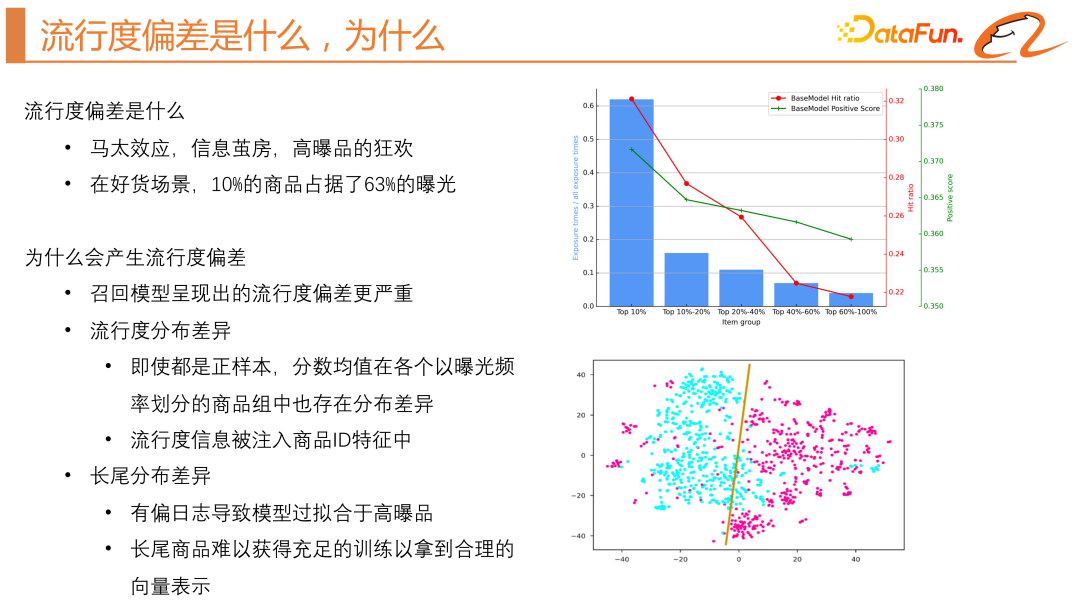
#流行度偏差有很多別名,例如馬太效應、資訊繭房,直觀來講它是高爆品的狂歡,越熱門的商品,越容易曝光。這會導致優質的長尾商品或達人創作的新商品沒有曝光的機會。其危害主要有兩點,第一點是使用者的個人化不足,第二點是達人創作的新商品得不到足夠的曝光,使得達人參與感降低,因此我們希望緩解流行度偏差。
從上圖右邊的藍色長條圖可以看出,曝光top10% 的商品在某一天中佔據了63% 的曝光,這證明在有好貨的場景下馬太效應是非常嚴重的。
2、為什麼會產生流行偏差
接下來我們去歸因為什麼會產生流行偏差。首先,需要闡明我們為什麼會在召回截斷做緩解流行度偏差的工作。排序模型擬合的是商品的 CTR,它的訓練樣本包含正樣本和負樣本,CTR 越高的商品越容易獲得曝光。但在召回階段,我們通常會採用雙塔模型,它的負樣本通常會透過兩種方式產生,第一種是全域隨機負採樣,第二種是batch 內負採樣,batch 內負採樣是將同一個batch 取正樣本的其它曝光日誌當作負樣本,所以它在一定程度上可以緩解馬太效應。但是,透過實驗我們發現,全域負採樣實際的線上效率型效果會更好。不過,推薦系統中的全域隨機負採樣可能導致流行度偏差,因為它只為模型提供了正回饋。這種偏差可能歸因於流行度分佈差異和先驗知識幹擾,即使用者傾向於點擊更受歡迎的物品。因此,模型可能會優先推薦熱門物品,而不考慮它們的相關性。
我們也分析了流行度分佈差異,如上圖右邊綠線所示,透過將商品依照曝光頻率分組並計算每組的正樣本平均分,發現即使所有樣本都是正樣本,平均分數也隨曝光頻率的下降而下降。建議系統模型訓練時存在流行度分佈差異與長尾分佈差異。模型會傾向於把流行度資訊注入到商品的 ID 特徵中,導致流行度分佈差異。高爆品所獲得的訓練次數遠大於長尾商品,使得模型過度擬合於高爆品,長尾商品難以得到充足訓練和合理向量表示。如上圖右邊的 TSN 圖所示,藍點表示高曝商品的商品向量,而紅點表示長尾商品的商品向量,顯示出分佈上的顯著差異。而且如上圖右邊的紅線所示,hit ratio 也會隨著曝光數的降低而降低。所以,我們把流行度偏差的產生歸因於流行度分佈差異和長尾分佈差異。
三、流行度偏差目前解決方案
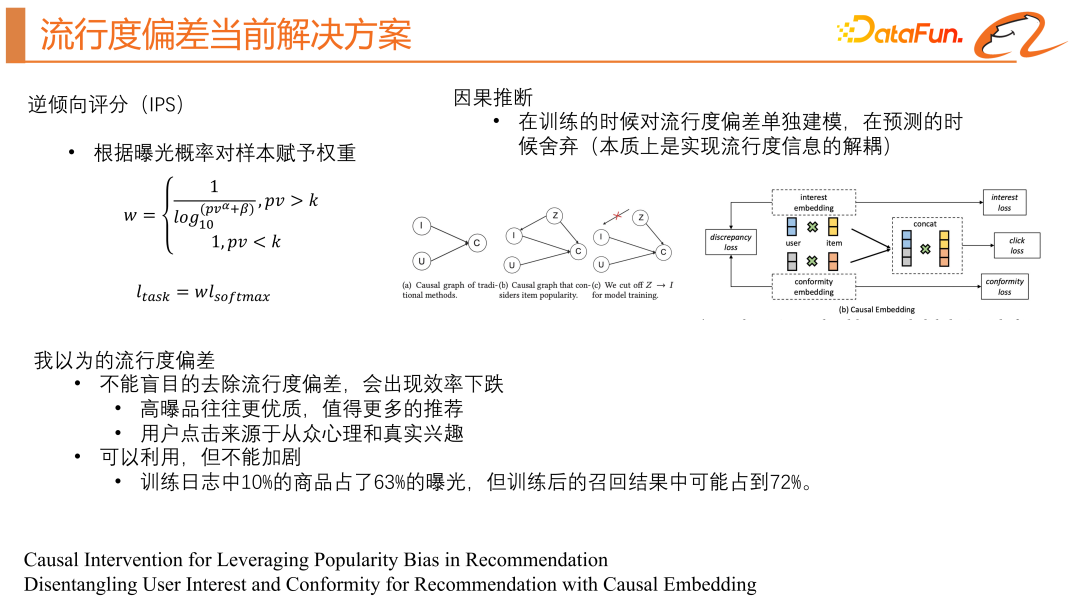
#目前業界的解決者案主要包括兩種,分別為逆傾向評分(IPS)和因果推論。
1、逆傾向評分(IPS)
#通俗來講就是將主任務損失函數中高曝光機率商品的權重調低以避免過度關注高曝光機率商品,從而可以更平均地關注整個正樣本分佈。但是,這種方法需要事先預測曝光機率,這種預測是不穩定的,容易失效或波動較大。
2、因果推論
#我們需要建立一個因果圖,i 代表商品特徵,u 代表用戶特徵,c 代表點擊機率,這張圖就表示給模型輸入使用者特徵和商品特徵,預測點擊率。如果我們把流行度偏差也考慮到這個模型中,用 z 來代表,它不僅會影響點擊率,還會影響商品的特徵表示 i,因果推斷的方法是嘗試去阻斷 z 對 i 的影響。
比較簡單的方法是利用商品的一些統計特徵單獨得到一個bias 塔,此時模型會輸出兩個分,一個是真實的點擊率,另一個是商品的流行度分,在線上預測的時候會將商品的流行度分去掉,實現流行度偏差的解耦。
第二種方法是將使用者點擊歸因為兩類,一類是從眾興趣,一類是真實興趣,分別建構樣本聯合訓練。相當於得到兩個模型,一個模型去得到使用者從眾的興趣分,一個模型去得到使用者真實的興趣分。因果推論其實也存在問題,它解決了流行度分佈差異,但無法解決長尾商品缺乏訓練資料的問題。目前的解決方案傾向於消除流行度偏見,但這對於需要「馬太效應」來生存的建議系統可能並不總是有益的。所以,我們建議不要完全去除推薦系統中的流行度偏差,因為流行的項目通常更優質,用戶也有從眾心理和真實興趣兩種心理,完全去除流行度偏差會影響用戶從眾興趣的滿足。應合理利用流行度偏差,不加劇偏差。
四、CD2AN 基本架構
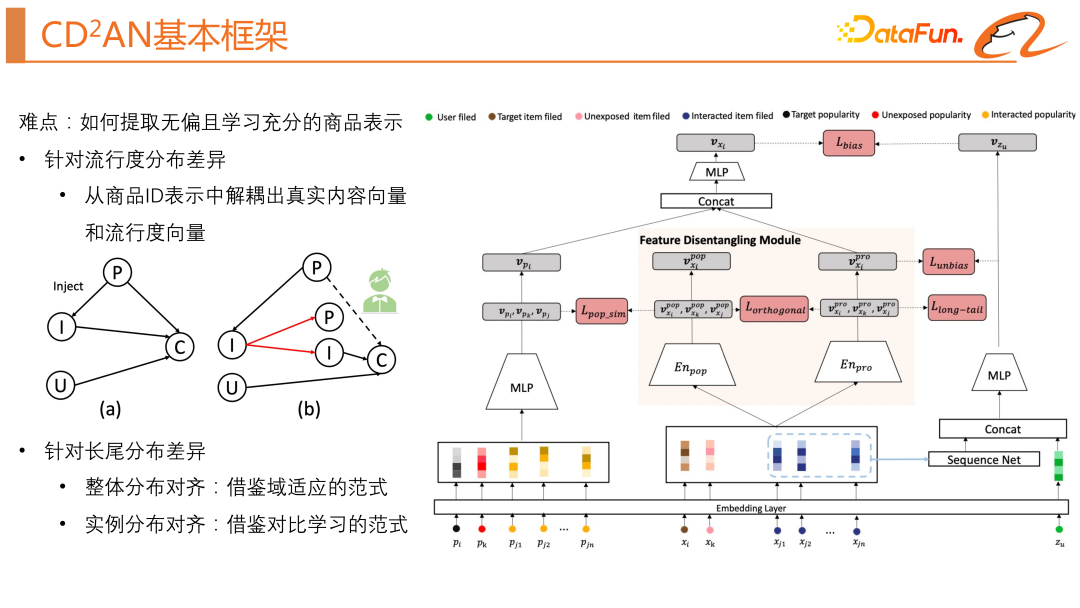
我們這次探索的工作就是如何合理地利用流行度偏差,要想合理地利用流行度偏差,需要解決一個困難:「如何提取無偏且學習充分的商品表示?」針對流行度分佈差異,我們需要從商品ID 解耦出真實內容向量和流行度向量。針對長尾分佈差異,我們借鑒了域適應的範式將整體分佈對齊,並借鑒了對比學習的範式將實例分佈對齊。
先來介紹 base 模型的基本架構,base 模型其實就是一個經典的雙塔模型。接下來詳細介紹下我們是如何解決前面提到的兩個問題的(流行度分佈差異和長尾分佈差異)。
1、特徵解耦模組緩解流行度分佈差異
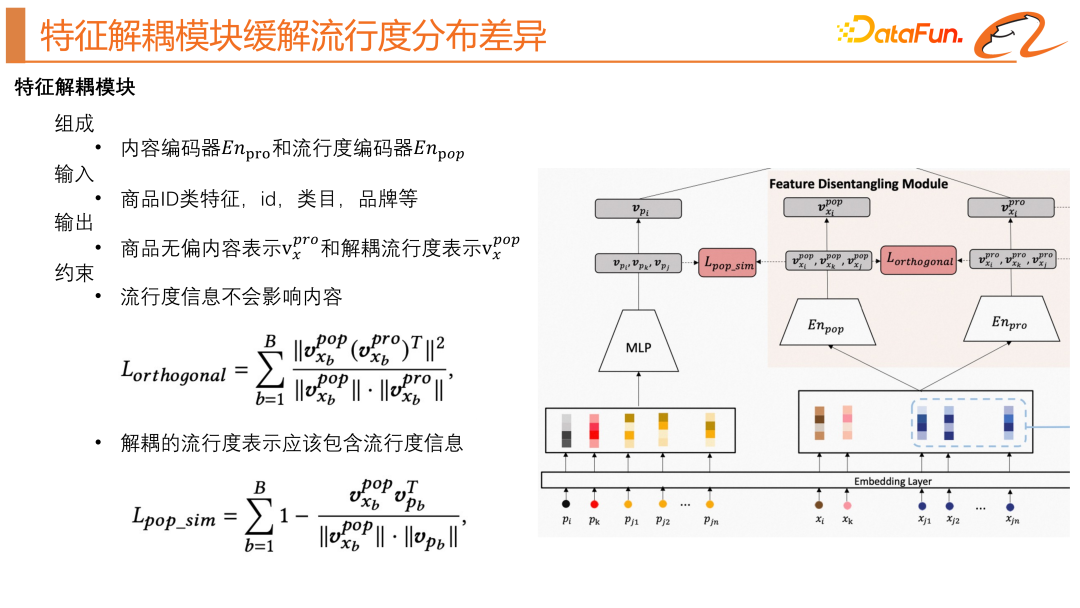
特徵解耦模組是本文針對推薦系統中的流行度偏差問題所提出的解決方案。此模組透過將物品向量表示中的流行度資訊與屬性資訊分開來,從而減輕流行度對物品向量表示的影響。具體地,該模組包括流行度編碼器和屬性編碼器,透過多層感知器的組合學習得到每個物品的屬性和流行度向量表示。這個模組的輸入是物品的屬性特徵,例如物品 ID、物品類目、品牌等,如上圖模型結構中的右邊部分所示。這裡會有兩個約束,包括正交正則化和流行度相似度正則化,旨在將流行度資訊與物品屬性資訊分開。其中,透過流行度相似度正則化,模組被鼓勵將嵌入物品屬性的流行度資訊與真實流行度資訊對齊,而透過正交正則化,模組被鼓勵在編碼中保留不同的訊息,從而實現分離流行度資訊和物品屬性資訊的目標。
我們還需要一個學習真實流行度的模組,如上圖模型結構中的左邊部分所示,它的輸入主要就是商品的統計特徵,然後經過一個MLP 得到真實的流行度表示。
2、正規化緩解分佈差異
接下來,我們想要解決長尾分佈差異的問題。
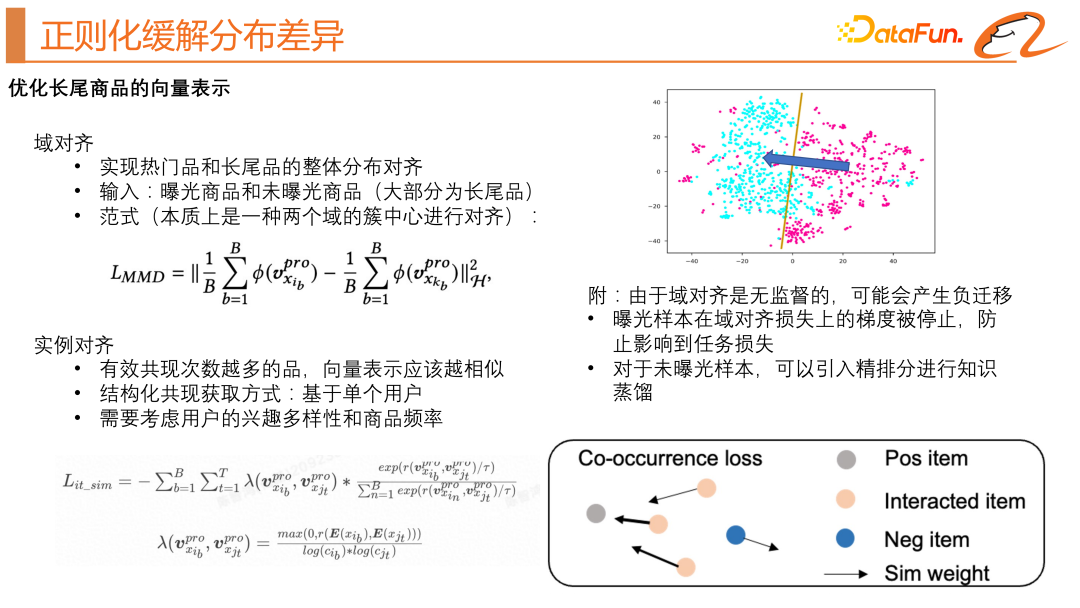
我們借鑒了遷移學習的思想,實現熱門商品和長尾商品的分佈對齊。我們在原始的雙塔模型中,引入了一個未曝光商品,使用了MMD 的損失函數(如上圖左上所示),這個損失函數希望熱門商品域和長尾商品域的簇中心盡可能靠近,如上圖右上示意圖所示。由於這種域對齊是無監督的,可能會產生負遷移,我們做瞭如下優化:曝光樣本在域對齊損失上的梯度被停止,防止影響到任務損失;對於未曝光樣本,引入精排分進行知識蒸餾。
我們也藉鑒了實例對齊的思想,希望可以學習得到更好的商品向量表示,主要思想就是有效共現次數越多的商品,向量表示越相似。這裡的難點是如何去構造 pair。在使用者有過往行為的商品序列中,天然存在這樣的 pair。以一個使用者舉例,一個樣本包含了一個使用者的行為序列和目標商品,那麼目標商品和使用者行為序列中的每個商品就能構成共現的 pair。我們在經典的對比學習的損失函數的基礎上也考慮了使用者的興趣多樣性和商品頻率,具體的損失函數公式可見上圖中左下部分。
我們可以看一個直觀的示意圖,如上圖中右下所示,灰色的點是目標商品,橙色的點是用戶的行為序列,藍色的點是我們隨機負採樣得到的負樣本。我們希望藉用對比學習的方法去約束使用者行為序列中每個商品都和目標商品靠近。
3、有偏無偏聯合訓練
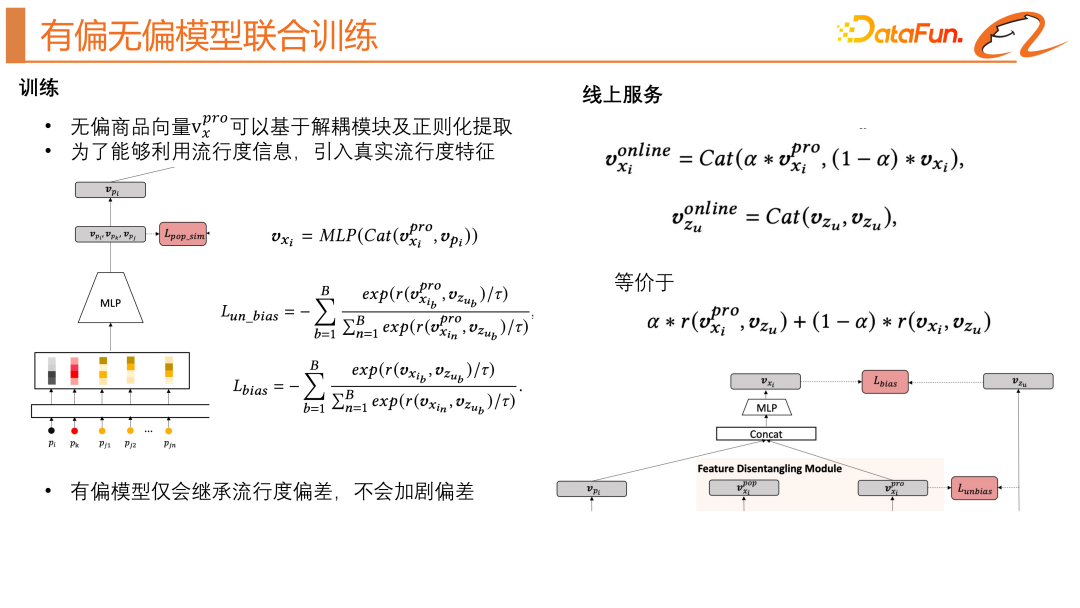
以上模組有效地得到了商品的無偏內容表示和解耦的流行度表示,我們應該怎樣去應用呢?我們利用了無偏模型和有偏模型聯合訓練的方式,無偏商品向量可以基於解耦模組及正則化提取,為了能夠利用流行度信息,我們還引入了流行度特徵,有偏模型只會繼承流行度偏差,不會加劇偏差。線上服務部分,如上圖右邊所示,我們將無偏的商品表示和有偏的商品表示透過參數α 融合起來得到線上的商品表示,這樣即可透過使用者向量來召回商品,這個α 是調節召回關注流行度資訊的程度。
#4、離線及線上實驗
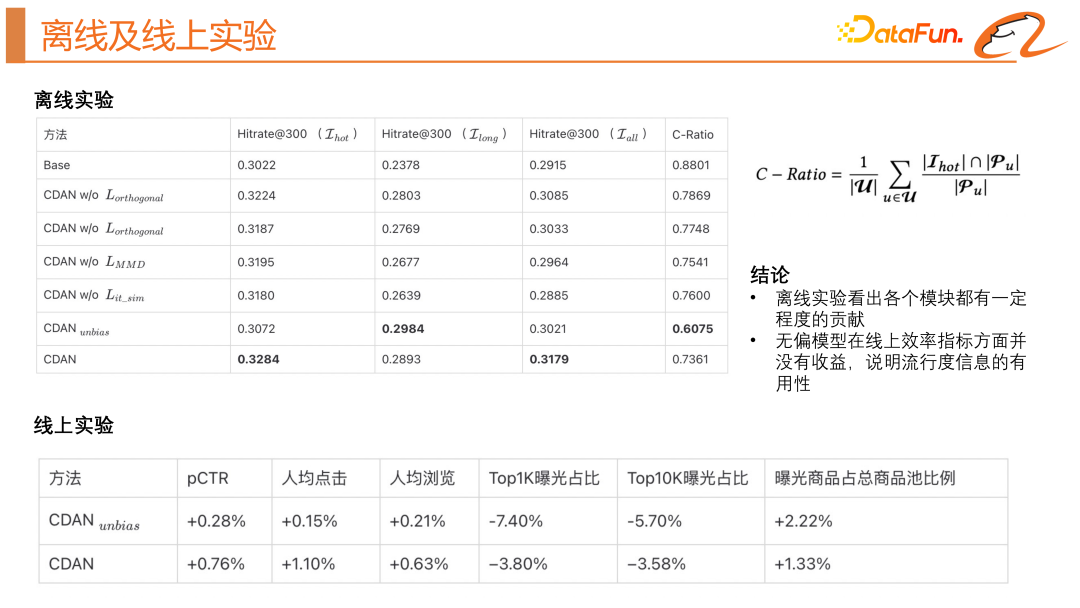
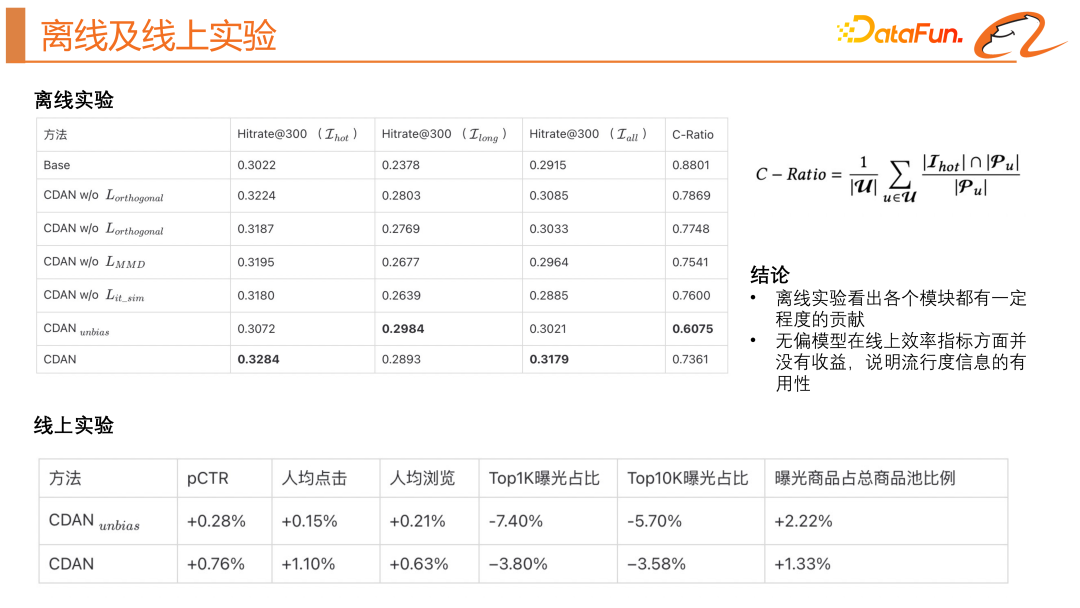
#上圖中展示了這個模型離線及線上的效果。在離線實驗中,我們引入了 C-Ratio 的指標,來衡量召回結果中有多少商品是高曝光商品。透過離線實驗我們可以看出各個模組都有一定程度的貢獻。無偏模型在線上效率指標方面並沒有收益,說明流行度資訊是有用的,我們還是需要使用有偏模型去利用流行度資訊。
最後,我們對模型結果做了視覺化的展示。我們發現新的模型結構的確可以將高爆商品和長尾商品的分佈記性對齊,解耦出來的流行度表示向量和商品無偏的內容表示幾乎是沒有交集的,並且同類目的商品能有更緊密的聯繫,透過對α 的調整,可以讓模型有方向地去擬合使用者的從眾興趣和真實興趣。
今天的分享論文標題是《Co-training Disentangled Domain Adaptation Network for Leveraging Popularity Bias in Recommenders》。
五、問答環節
Q1:未曝光樣本是怎麼加入到樣本中的?A1:離線產生的,針對一條樣本,我們可以拿到目標正樣本及對應的類別目,然後離線地隨機採樣若干個和目標正樣本相同類目的商品,掛載到訓練樣本中。
Q2:引入同類的未曝光樣本,會不會增加學習難度?A2:引入的未曝光樣本是沒有標籤的,是透過無監督的方式來進行分佈對齊,可能會存在負遷移的情況,我們用了兩個技巧來解決這個問題:曝光樣本在域對齊損失上的梯度被停止,防止影響到任務損失;對於未曝光樣本,可以引入精排分進行知識蒸餾。
Q3:未曝光樣本取得精排分成本會不會很高?
###A3:離線對樣本用精排模型打一遍分,作為特徵來使用,表現還好。 ###############Q4:未曝光樣本是進精排未曝光的樣本嗎? ###############A4:不是,這樣大機率還是高爆品,我們使用的是全域同類目下隨機取樣的結果。 ##########以上是精準推薦的秘術:阿里解耦域適應無偏召回模型詳解的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 如何使用Go語言和Redis實現推薦系統
Oct 27, 2023 pm 12:54 PM
如何使用Go語言和Redis實現推薦系統
Oct 27, 2023 pm 12:54 PM
如何使用Go語言和Redis實現推薦系統推薦系統是現代網路平台中重要的一環,它幫助使用者發現和獲取感興趣的資訊。而Go語言和Redis是兩個非常流行的工具,它們在實現推薦系統的過程中能夠發揮重要作用。本文將介紹如何使用Go語言和Redis來實作一個簡單的推薦系統,並提供具體的程式碼範例。 Redis是一個開源的記憶體資料庫,它提供了鍵值對的儲存接口,並支援多種數據
 應用實例:使用go-micro 建置微服務推薦系統
Jun 18, 2023 pm 12:43 PM
應用實例:使用go-micro 建置微服務推薦系統
Jun 18, 2023 pm 12:43 PM
隨著網路應用的普及,微服務架構成為目前較受歡迎的架構方式。其中,微服務架構的關鍵在於將應用程式拆分為不同的服務,透過RPC方式進行通信,實現鬆散耦合的服務架構。在本文中,我們將結合實際案例,介紹如何使用go-micro建構一個微服務推薦系統。一、什麼是微服務推薦系統微服務推薦系統是一種基於微服務架構的推薦系統,它將推薦系統中的不同模組(如特徵工程、分類
 利用Java實現的推薦系統演算法與應用
Jun 19, 2023 am 09:06 AM
利用Java實現的推薦系統演算法與應用
Jun 19, 2023 am 09:06 AM
隨著網路技術的不斷發展和普及,推薦系統作為一種重要的資訊過濾技術,越來越受到廣泛的應用和關注。在實作推薦系統演算法方面,Java作為一種快速、可靠的程式語言,已被廣泛應用。本文將介紹利用Java實現的推薦系統演算法和應用,並著重介紹三種常見的推薦系統演算法:基於使用者的協同過濾演算法、基於物品的協同過濾演算法和基於內容的推薦演算法。基於用戶的協同過濾演算法是基於用戶的協同過
 精準推薦的秘術:阿里解耦域適應無偏召回模型詳解
Jun 05, 2023 am 08:55 AM
精準推薦的秘術:阿里解耦域適應無偏召回模型詳解
Jun 05, 2023 am 08:55 AM
一、場景介紹首先來介紹本文涉及的場景—「有好貨」場景。它的位置是在淘寶首頁的四宮格,分為一跳精選頁和二跳承接頁。承接頁主要有兩種形式,一種是圖文的承接頁,另一種是短視頻的承接頁。這個場景的目標主要是為使用者提供滿意的好貨,帶動GMV的成長,從而進一步撬動達人的供給。二、流行度偏差是什麼,為什麼接下來進入本文的重點,流行度偏差。流行度偏差是什麼?為什麼會產生流行度偏差? 1.流行度偏差是什麼流行度偏差有很多別名,例如馬太效應、資訊繭房,直觀來講它是高爆品的狂歡,越熱門的商品,越容易曝光。這會導致
 Go語言如何實現雲端搜尋和推薦系統?
May 16, 2023 pm 11:21 PM
Go語言如何實現雲端搜尋和推薦系統?
May 16, 2023 pm 11:21 PM
隨著雲端運算技術的不斷發展和普及,雲端搜尋和推薦系統也越來越得到了人們的青睞。而針對這項需求,Go語言也提供了很好的解決方案。在Go語言中,我們可以利用其高速的並發處理能力和豐富的標準庫來實現一個高效的雲端搜尋和推薦系統。以下將介紹Go語言如何實現這樣的系統。一、雲上搜尋首先,我們需要對搜尋的姿勢和原理進行了解。搜尋姿勢指的是搜尋引擎根據使用者輸入的關鍵字來配對頁面
 關於網易雲音樂冷啟動技術的推薦系統
Nov 14, 2023 am 08:14 AM
關於網易雲音樂冷啟動技術的推薦系統
Nov 14, 2023 am 08:14 AM
一、问题背景:冷启动建模的必要性和重要性作为一个内容平台,云音乐每天都会有大量的新内容上线。虽然相较于短视频等其他平台,云音乐平台的新内容数量相对较少,但实际数量可能远远超出大家的想象。同时,音乐内容与短视频、新闻、商品推荐又有着显著的不同。音乐的生命周期跨度极长,通常会以年为单位。有些歌曲可能在沉寂几个月、几年之后爆发,经典歌曲甚至可能经过十几年仍然有着极强的生命力。因此,对于音乐平台的推荐系统来说,发掘冷门、长尾的优质内容,并把它们推荐给合适的用户,相比其他类目的推荐显得更加重要冷门、长尾的
 因果糾偏法在螞蟻行銷推薦場景中的應用
Jan 13, 2024 pm 12:15 PM
因果糾偏法在螞蟻行銷推薦場景中的應用
Jan 13, 2024 pm 12:15 PM
一、因果糾偏的背景1、偏差的產生在推薦系統中,透過收集資料來訓練推薦模型,以向使用者推薦合適的物品。當使用者與推薦的物品互動時,收集的資料又會用於進一步訓練模型,形成一個閉環循環。然而,這個閉環中可能存在各種影響因素,導致誤差的產生。主要的誤差原因在於訓練模式所使用的數據大多是觀測數據,而非理想的訓練數據,受到曝光策略和使用者選擇等因素的影響。這種偏差的本質在於經驗風險估計的期望和真實理想風險估計的期望之間的差異。 2.常見的偏差推薦行銷系統裡面比較常見的偏差主要有以下三種:選擇性偏差:是由於使用者根
 PHP中的推薦系統與協同過濾技術
May 11, 2023 pm 12:21 PM
PHP中的推薦系統與協同過濾技術
May 11, 2023 pm 12:21 PM
隨著網路的快速發展,推薦系統變得越來越重要。推薦系統是一種用於預測使用者感興趣的物品的演算法。在網路應用程式中,推薦系統可以提供個人化建議和推薦,從而提高用戶滿意度和轉換率。 PHP是一種被廣泛應用於Web開發的程式語言。本文將探討PHP中的建議系統與協同過濾技術。推薦系統的原理推薦系統依賴機器學習演算法和資料分析,它透過對使用者歷史行為進行分析,預測
