

RLHF中的'RL”是必要的嗎?有人用二進位交叉熵直接微調LLM,效果更好

近來,在大型資料集上訓練的無監督語言模型已經獲得了令人驚訝的能力。然而,這些模型是在具有各種目標、優先事項和技能集的人類生成的資料上訓練的,其中一些目標和技能設定未必希望被模仿。
從模型非常廣泛的知識和能力中選擇其期望的回應和行為,對於建立安全、高效能和可控的人工智慧系統至關重要。許多現有的方法透過使用精心策劃的人類偏好集將所需的行為灌輸到語言模型中,這些偏好集代表了人類認為安全和有益的行為類型,這個偏好學習階段發生在對大型文本資料集進行大規模無監督預訓練的初始階段之後。
雖然最直接的偏好學習方法是對人類展示的高品質回應進行監督性微調,但最近相對熱門的一類方法是從人類(或人工智慧)反饋中進行強化學習(RLHF/RLAIF)。 RLHF 方法將獎勵模型與人類偏好的資料集相匹配,然後使用 RL 來優化語言模型策略,以產生分配高獎勵的回應,而不過度偏離原始模型。
雖然RLHF 產生的模型具有令人印象深刻的對話和編碼能力,但RLHF pipeline 比監督學習複雜得多,涉及訓練多個語言模型,並在訓練的循環中從語言模型策略取樣,產生大量的計算成本。
而最近的一項研究顯示:現有方法使用的基於RL 的目標可以用一個簡單的二元交叉熵目標來精確優化,從而大大簡化偏好學習pipeline。 也就是說,完全可以直接優化語言模型以堅持人類的偏好,而不需要明確的獎勵模型或強化學習。

#論文連結:https://arxiv.org/pdf/2305.18290 .pdf
來自史丹佛大學等機構研究者提出了直接偏好優化(Direct Preference Optimization,DPO),這種演算法隱含地優化了與現有RLHF 演算法相同的目標(帶有KL - 發散約束的獎勵最大化),但實施起來很簡單,而且可直接訓練。
實驗表明,至少當用於60 億參數語言模型的偏好學習任務,如情緒調節、摘要和對話時,DPO 至少與現有的方法一樣有效,包括基於PPO 的RLHF。
DPO 演算法
與現有的演算法一樣,DPO 也依賴理論上的偏好模型(如Bradley-Terry 模型),以此衡量給定的獎勵函數與經驗偏好資料的吻合程度。然而,現有的方法使用偏好模型定義偏好損失來訓練獎勵模型,然後訓練優化所學獎勵模型的策略,而 DPO 使用變數的變化來直接定義偏好損失作為策略的一個函數。鑑於人類對模型反應的偏好資料集,DPO 因此可以使用一個簡單的二元交叉熵目標來優化策略,而不需要明確地學習獎勵函數或在訓練期間從策略中採樣。
DPO 的更新增加了首選response 與非首選response 的相對對數機率,但它包含了一個動態的、每個樣本的重要性權重,以防止模型退化,研究者發現這種退化會發生在一個樸素機率比目標上。
為了從機制上理解 DPO,分析損失函數 的梯度是很有用的。關於參數 θ 的梯度可以寫成:
的梯度是很有用的。關於參數 θ 的梯度可以寫成:
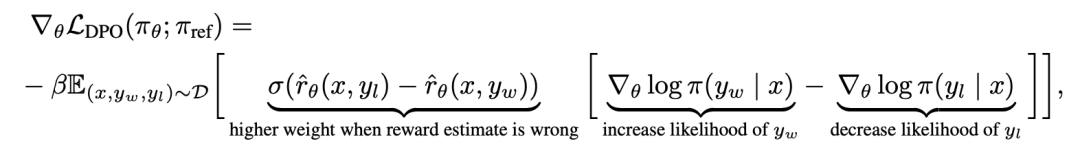
其中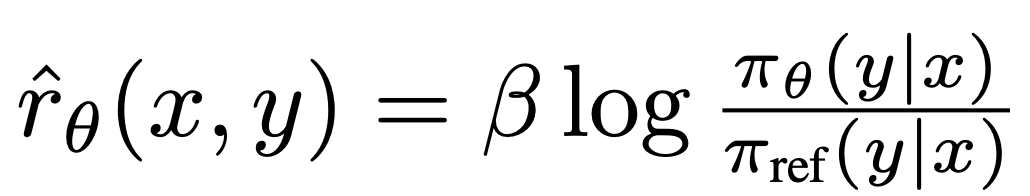 是由語言模型
是由語言模型 與參考模型
與參考模型 #隱含定義的獎勵。直觀地說,損失函數
#隱含定義的獎勵。直觀地說,損失函數 的梯度增加了首選補全 y_w 的可能性,減少了非首選補全 y_l 的可能性。
的梯度增加了首選補全 y_w 的可能性,減少了非首選補全 y_l 的可能性。
重要的是,這些樣本的權重是由隱性獎勵模型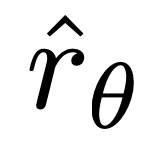 對不喜歡的完成度的評價高低來決定的,以β為尺度,即隱性獎勵模型對完成度的排序有多不正確,這也是KL 約束強度的體現。實驗顯示了這種加權的重要性,因為沒有加權係數的這種方法的 naive 版本會導致語言模型的退化(附錄表 2)。
對不喜歡的完成度的評價高低來決定的,以β為尺度,即隱性獎勵模型對完成度的排序有多不正確,這也是KL 約束強度的體現。實驗顯示了這種加權的重要性,因為沒有加權係數的這種方法的 naive 版本會導致語言模型的退化(附錄表 2)。
在論文的第五章,研究者對DPO 方法做了進一步的解釋,提供了理論支持,並將DPO 的優勢與用於RLHF 的Actor-Critic 演算法(如PPO)的問題連結起來。具體細節可參考原論文。
實驗
在實驗中,研究者評估了 DPO 直接根據偏好訓練策略的能力。
首先,在一個控制良好的文本生成環境中,他們思考了這樣一個問題:與PPO 等常見偏好學習演算法相比,DPO 在參考策略中權衡獎勵最大化和KL-divergence 最小化的效率如何?接著,研究者也評估了 DPO 在更大模型和更困難的 RLHF 任務 (包括摘要和對話) 上的表現。
最終發現,在幾乎沒有超參數調整的情況下,DPO 的表現往往與帶有PPO 的RLHF 等強大的基線一樣好,甚至更好,同時在學習獎勵函數下傳回最佳的N 個取樣軌跡結果。
從任務上來說,研究者探討了三個不同的開放式文本生成任務。在所有實驗中,演算法從偏好資料集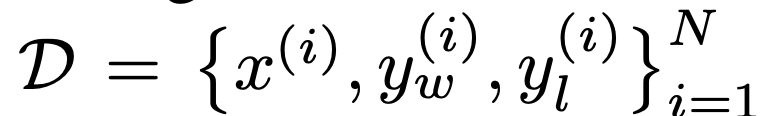 學習策略。
學習策略。
在可控情緒生成中,x 是 IMDb 資料集的電影評論的前綴,策略必須產生具有正面情緒的 y。為了進行對照評估,實驗使用了預先訓練好的情緒分類器來產生偏好對,其中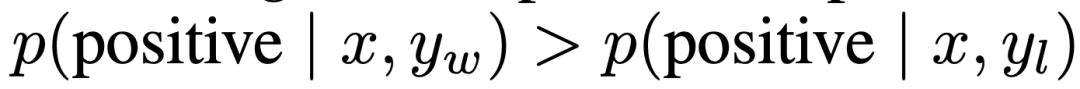 。
。
對於 SFT,研究者微調了 GPT-2-large,直到收斂於 IMDB 資料集的訓練分割的評論。總之,x 是來自 Reddit 的論壇帖子,該策略必須產生帖子中要點的總結。基於先前工作,實驗使用了 Reddit TL;DR 摘要資料集以及 Stiennon et al. 收集的人類偏好。實驗還使用了 SFT 模型,該模型是根據人類撰寫的論壇文章摘要 2 和 RLHF 的 TRLX 框架進行微調的。人類偏好資料集是由 Stiennon et al. 從一個不同的但經過類似訓練的 SFT 模型中收集的樣本。
最後,在單輪對話中,x 是一個人類問題,可以是從天文物理到建立關係建議的任何問題。一個策略必須對使用者的查詢做出有吸引力和有幫助的回應;策略必須對使用者的查詢做出有意思且有幫助的回應;實驗使用Anthropic Helpful and Harmless 對話集,其中包含人類和自動化助手之間的170k 對話。每個文字以一對由大型語言模型 (儘管未知) 產生的回應以及表示人類首選回應的偏好標籤結束。在這種情況下,沒有預先訓練的 SFT 模型可用。因此,實驗只在首選完成項上微調現成的語言模型,以形成 SFT 模型。
研究者使用了兩種評估方法。為了分析每種演算法在優化約束獎勵最大化目標方面的效率,在可控情感生成環境中,實驗透過其實現獎勵的邊界和與參考策略的 KL-divergence 來評估每種演算法。實驗可以使用 ground-truth 獎勵函數 (情緒分類器),因此這條邊界是可以計算出來的。但事實上,ground truth 獎勵函數是未知的。因此研究者透過基線策略的勝率來評估演算法的勝率,並以 GPT-4 作為在摘要和單輪對話設定中人類評估摘要品質和回應有用性的代理。針對摘要,實驗使用測試機中的參考摘要作為極限;針對對話,選擇測試資料集中的首選反應作為基準。雖然現有研究表明語言模型可以成為比現有度量更好的自動評估器,但研究者進行了一項人類研究,證明了使用GPT-4 進行評估的可行性GPT-4 判斷與人類有很強的相關性,人類與GPT-4 的一致性通常類似或高於人類標註者之間的一致性。
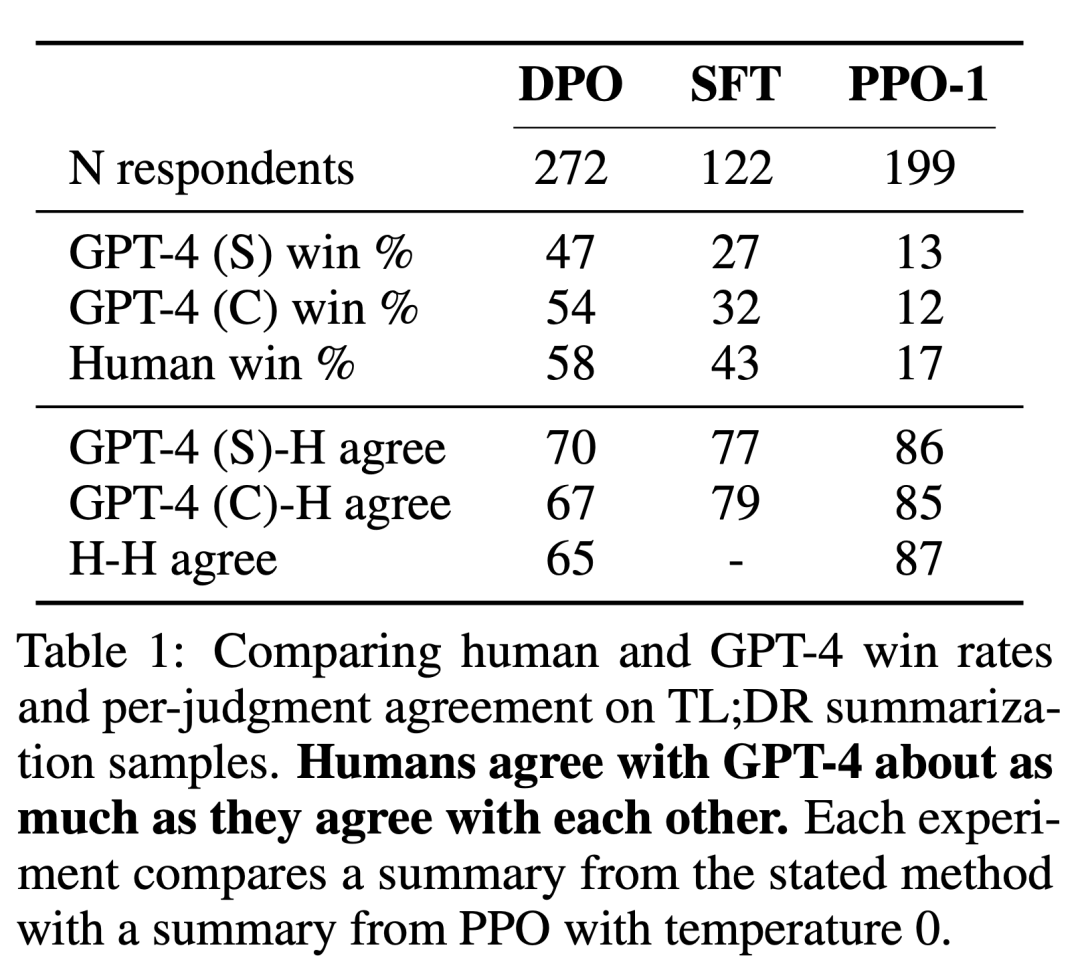
除了DPO 之外,研究者還評估了幾種現有的訓練語言模型來與人類偏好保持一致。最簡單的是,實驗在摘要任務中探索了 GPT-J 的零樣本 prompt,在對話任務中探索了 Pythia-2.8B 的 2-shot prompt。此外,實驗還評估了 SFT 模型和 Preferred-FT。 Preferred-FT 是一個透過監督學習從 SFT 模型 (可控情緒和摘要) 或通用語言模型 (單回合對話) 中選擇的完成 y_w 進行微調的模型。另一種偽監督方法是 Unlikelihood,它簡單地優化策略,使分配給 y_w 的機率最大化,分配給 y_l 的機率最小化。實驗在「Unlikehood」上使用了一個可選係數 α∈[0,1]。他們還考慮了 PPO,使用從偏好數據中學習的獎勵函數,以及 PPO-GT。 PPO-GT 是從可控情緒設定中可用的 ground truth 獎勵函數學習的 oracle。在情緒實驗中,團隊使用了 PPO-GT 的兩個實現,一個是現成的版本,以及一個修改版本。後者將獎勵歸一化,並進一步調整超參數以提高性能 (在運行具有學習獎勵的“Normal”PPO 時,實驗也使用了這些修改)。最後,研究者考慮了 N 個基線中的最優值,從 SFT 模型 (或對話中的 Preferred-FT) 中採樣 N 個回答,並根據從偏好資料集中學習的獎勵函數返回得分最高的答案。這種高效能方法將獎勵模型的品質與 PPO 最佳化解耦,但即使對中度 N 來說,在計算上也是不切實際的,因為它在測試時需要對每個查詢進行 N 次採樣完成。
圖 2 展示了情緒設定中各種演算法的獎勵 KL 邊界。
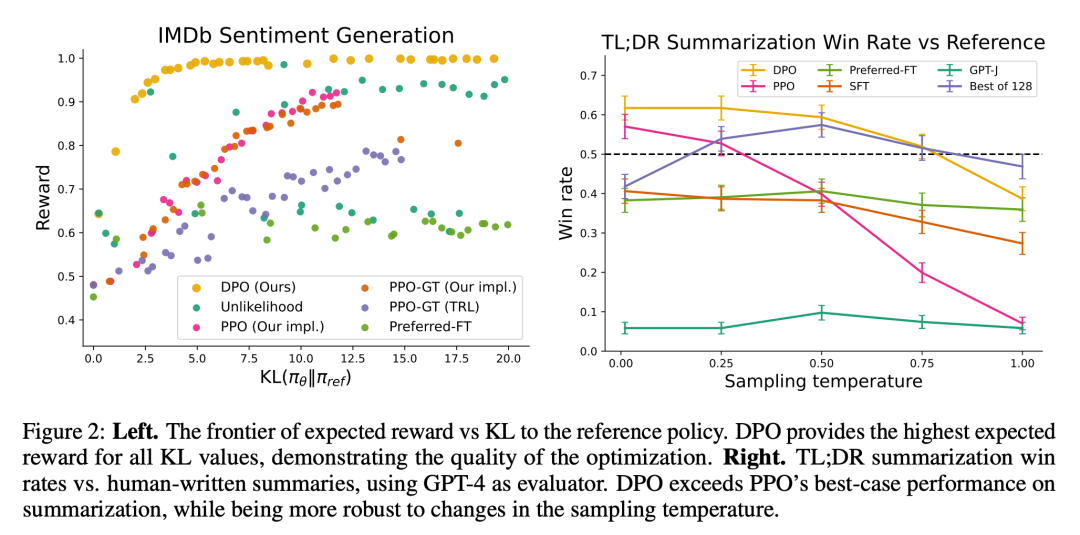
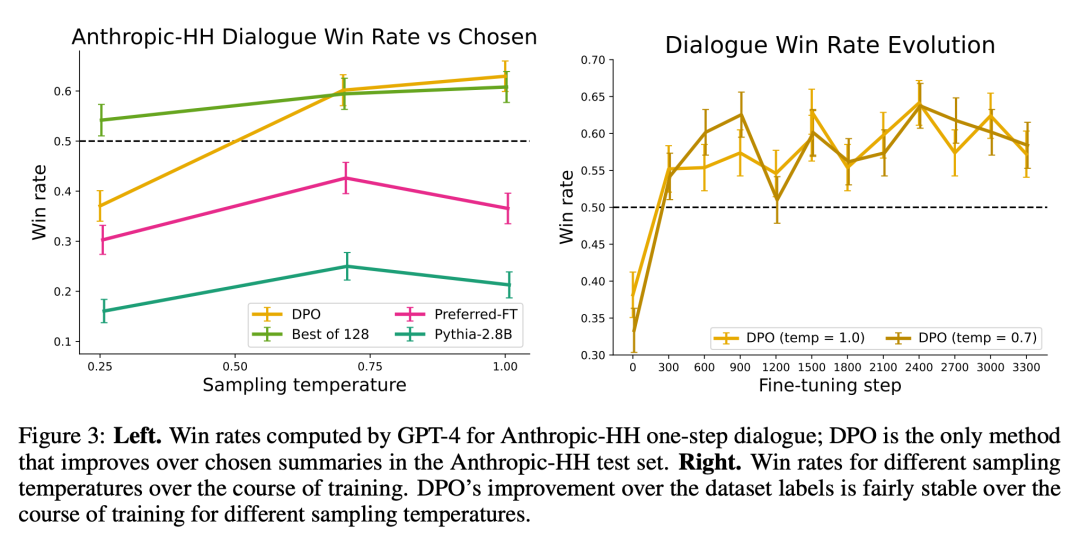
圖 3 展示了 DPO 收斂到其最佳效能的速度相對較快。
更多研究細節,可參考原文。
以上是RLHF中的'RL”是必要的嗎?有人用二進位交叉熵直接微調LLM,效果更好的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

AI Hentai Generator
免費產生 AI 無盡。

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)
熱門話題



 Debian郵件服務器防火牆配置技巧
Apr 13, 2025 am 11:42 AM
Debian郵件服務器防火牆配置技巧
Apr 13, 2025 am 11:42 AM
配置Debian郵件服務器的防火牆是確保服務器安全性的重要步驟。以下是幾種常用的防火牆配置方法,包括iptables和firewalld的使用。使用iptables配置防火牆安裝iptables(如果尚未安裝):sudoapt-getupdatesudoapt-getinstalliptables查看當前iptables規則:sudoiptables-L配置
 debian readdir如何與其他工具集成
Apr 13, 2025 am 09:42 AM
debian readdir如何與其他工具集成
Apr 13, 2025 am 09:42 AM
Debian系統中的readdir函數是用於讀取目錄內容的系統調用,常用於C語言編程。本文將介紹如何將readdir與其他工具集成,以增強其功能。方法一:C語言程序與管道結合首先,編寫一個C程序調用readdir函數並輸出結果:#include#include#includeintmain(intargc,char*argv[]){DIR*dir;structdirent*entry;if(argc!=2){
 debian readdir如何實現文件排序
Apr 13, 2025 am 09:06 AM
debian readdir如何實現文件排序
Apr 13, 2025 am 09:06 AM
在Debian系統中,readdir函數用於讀取目錄內容,但其返回的順序並非預先定義的。要對目錄中的文件進行排序,需要先讀取所有文件,再利用qsort函數進行排序。以下代碼演示瞭如何在Debian系統中使用readdir和qsort對目錄文件進行排序:#include#include#include#include//自定義比較函數,用於qsortintcompare(constvoid*a,constvoid*b){returnstrcmp(*(
 Debian郵件服務器SSL證書安裝方法
Apr 13, 2025 am 11:39 AM
Debian郵件服務器SSL證書安裝方法
Apr 13, 2025 am 11:39 AM
在Debian郵件服務器上安裝SSL證書的步驟如下:1.安裝OpenSSL工具包首先,確保你的系統上已經安裝了OpenSSL工具包。如果沒有安裝,可以使用以下命令進行安裝:sudoapt-getupdatesudoapt-getinstallopenssl2.生成私鑰和證書請求接下來,使用OpenSSL生成一個2048位的RSA私鑰和一個證書請求(CSR):openss
 Debian OpenSSL如何進行數字簽名驗證
Apr 13, 2025 am 11:09 AM
Debian OpenSSL如何進行數字簽名驗證
Apr 13, 2025 am 11:09 AM
在Debian系統上使用OpenSSL進行數字簽名驗證,可以按照以下步驟操作:準備工作安裝OpenSSL:確保你的Debian系統已經安裝了OpenSSL。如果沒有安裝,可以使用以下命令進行安裝:sudoaptupdatesudoaptinstallopenssl獲取公鑰:數字簽名驗證需要使用簽名者的公鑰。通常,公鑰會以文件的形式提供,例如public_key.pe
 Debian OpenSSL如何防止中間人攻擊
Apr 13, 2025 am 10:30 AM
Debian OpenSSL如何防止中間人攻擊
Apr 13, 2025 am 10:30 AM
在Debian系統中,OpenSSL是一個重要的庫,用於加密、解密和證書管理。為了防止中間人攻擊(MITM),可以採取以下措施:使用HTTPS:確保所有網絡請求使用HTTPS協議,而不是HTTP。 HTTPS使用TLS(傳輸層安全協議)加密通信數據,確保數據在傳輸過程中不會被竊取或篡改。驗證服務器證書:在客戶端手動驗證服務器證書,確保其可信。可以通過URLSession的委託方法來手動驗證服務器
 Debian Hadoop日誌管理怎麼做
Apr 13, 2025 am 10:45 AM
Debian Hadoop日誌管理怎麼做
Apr 13, 2025 am 10:45 AM
在Debian上管理Hadoop日誌,可以遵循以下步驟和最佳實踐:日誌聚合啟用日誌聚合:在yarn-site.xml文件中設置yarn.log-aggregation-enable為true,以啟用日誌聚合功能。配置日誌保留策略:設置yarn.log-aggregation.retain-seconds來定義日誌的保留時間,例如保留172800秒(2天)。指定日誌存儲路徑:通過yarn.n
 centos關機命令行
Apr 14, 2025 pm 09:12 PM
centos關機命令行
Apr 14, 2025 pm 09:12 PM
CentOS 關機命令為 shutdown,語法為 shutdown [選項] 時間 [信息]。選項包括:-h 立即停止系統;-P 關機後關電源;-r 重新啟動;-t 等待時間。時間可指定為立即 (now)、分鐘數 ( minutes) 或特定時間 (hh:mm)。可添加信息在系統消息中顯示。
