

#引言:Stable Diffusion 展現了強大的視覺生成能力。然而,它們在產生具有空間、結構或幾何控制的圖像方面常常表現不足。 ControlNet [1] 和 T2I-adpater [2] 等工作實現針對不同模態的可控圖片生成,但能夠在單一統一的模型中適應各種視覺條件,仍然是一個未解決的挑戰。 UniControl 在單一的框架內合併了各種可控的條件到影像(C2I)任務。為了讓 UniControl 有能力處理多樣的視覺條件,作者引入了一個任務感知的 HyperNet 來調節下游的條件擴散模型,使其能夠同時適應不同的 C2I 任務。 UniControl 在九個不同的 C2I 任務上進行訓練,展示了強大的視覺生成能力和 zero-shot 泛化能力。作者已開源模型參數和推理程式碼,資料集和訓練程式碼也將盡快開源,歡迎大家交流使用。

#圖1: UniControl 模型由多個預訓練任務和zero-shot 任務組成
動機:現有的可控圖片產生模型都是針對單一的模態進行設計,然而Taskonomy [3] 等工作證明不同的視覺模態之間共享特徵和訊息,因此本文認為統一的多模態模型具有巨大的潛力。
解決:本文提出了 MOE-style Adapter 和 Task-aware HyperNet 來實現 UniControl 中的多模態條件產生能力。而作者建立了一個新的資料集 MultiGen-20M,包含 9 個任務,超過兩千萬個 image-condition-prompt 三元組,圖片尺寸≥512。
優點: 1) 更緊密的模型(1.4B #params, 5.78GB checkpoint),較少的參數實作多個tasks。 2) 更強大的視覺生成能力和控制的準確性。 3) 在從未見過的模態上的 zero-shot 泛化能力。
生成式基礎模型正在改變人工智慧在自然語言處理、電腦視覺、音訊處理和機器人控制等領域的互動方式。在自然語言處理中,像 InstructGPT 或 GPT-4 這樣的生成式基礎模型在各種任務上都表現優異,而這種多工處理能力是最吸引人的特性之一。此外,它們還可以進行 zero-shot 或 few-shot 的學習來處理未見過的任務。
然而,在視覺領域的生成模型中,這種多工處理能力並不突出。雖然文字描述提供了一種靈活的方式來控制生成的圖像的內容,但它們在提供像素級的空間、結構或幾何控制方面往往不足。最近熱門研究例如 ControlNet,T2I-adapter 可以增強 Stable Diffusion Model (SDM) 來實現精確的控制。然而,與可以由 CLIP 這樣的統一模組處理的語言提示不同,每個 ControlNet 模型只能處理其訓練過的特定模態。
為了克服先前工作的限制,本文提出了 UniControl,一個能同時處理語言和各種視覺條件的統一擴散模型。 UniControl 的統一設計可以享受到提高訓練和推理效率以及增強可控生成的優點。另一方面,UniControl 從不同視覺條件之間的固有連結中獲益,來增強每個條件的生成效果。
UniControl 的統一可控生成能力依賴兩個部分,一個是 "MOE-style Adapter",另一個是 "Task-aware HyperNet"。 MOE-style Adapter 有70K 左右的參數,可以從各種模態中學習低階特徵圖,Task-aware HyperNet 可以將任務指令作為自然語言提示輸入,並輸出任務embedding 嵌入下游的網路中,來調製下游模型的參數來適應不同模態的輸入。
該研究對UniControl 進行預訓練,以獲得多任務和zero-shot 學習的能力,包括五個類別的九個不同任務:邊緣(Canny, HED, Sketch) ,區域映射(Segmentation, Object Bound Box),骨架(Human Skeleton),幾何圖(Depth, Normal Surface) 和圖片編輯(Image Outpainting)。然後,該研究在 NVIDIA A100 硬體上訓練 UniControl 超過 5000 個 GPU 小時 (當前新模型仍在繼續訓練)。而 UniControl 展現出了新任務的 zero-shot 適應能力。
該研究的貢獻可以概括如下:
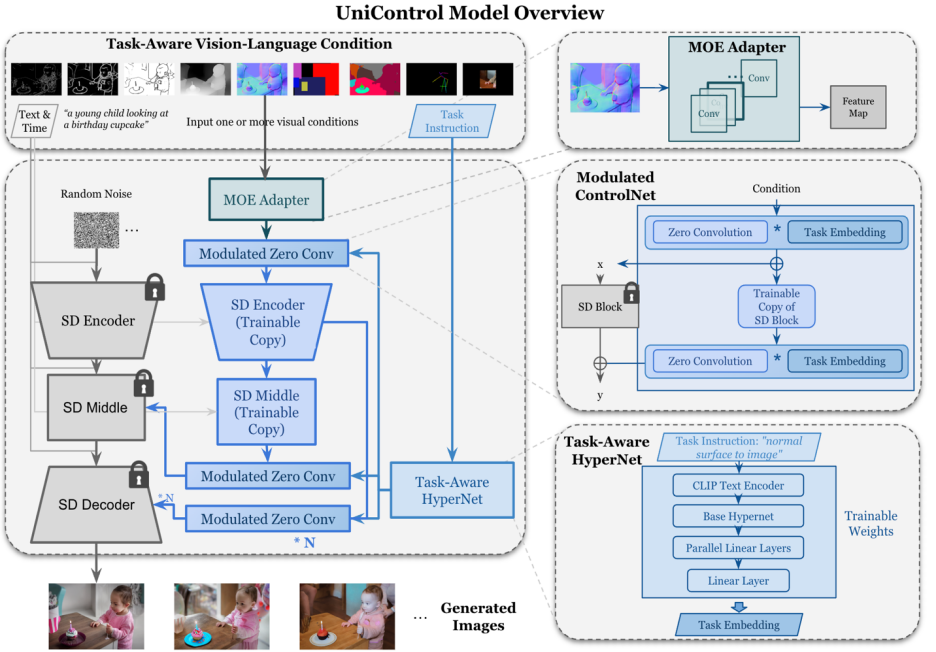
#圖2:模型結構。為了適應多個任務,研究設計了 MOE-style Adapter,每個任務大約有 70K 個參數,以及一個任務感知 Task-aware HyperNet(約 12M 參數)來調製 7 個零卷積層。這個結構允許在單一的模型中實現多任務功能,既保證了多任務的多樣性,也保留了底層的參數共享。相較於等效的堆疊的單任務模型(每個模型大約有 1.4B 參數),顯著地減少了模型的大小。
UniControl 模型設計確保了兩個性質:
1) 克服來自不同模態的低階特徵之間的不對齊。這有助於 UniControl 從所有任務中學習必要的和獨特的資訊。例如,當模型將分割圖作為視覺條件時,可能會忽略 3D 資訊。
2) 能夠跨任務學習元知識。這使得模型能夠理解任務之間的共享知識以及它們之間的差異。
為了提供這些屬性,模型引進了兩個新穎的模組:MOE-style Adapter 和 Task-aware HyperNet。
#########MOE-style Adapter 是一組卷積模組,每個Adapter 對應一個單獨的模態,靈感來自專家混合模型(MOE),用作UniControl 捕捉各種低階視覺條件的特徵。此適配器模組具有約 70K 的參數,計算效率極高。此後視覺特徵將送入統一的網路中處理。 ############Task-aware HyperNet 則是透過任務指令條件對 ControlNet 的零卷積模組進行調節。 HyperNet 首先將任務指令投影為 task embedding,然後研究者將 task embedding 注入到 ControlNet 的零卷積層中。這裡 task embedding 和零卷積層的捲積核矩陣尺寸是對應的。類似 StyleGAN [4],該研究直接將兩者相乘來調製卷積參數,調製後的捲積參數作為最終的捲積參數。因此每個 task 的調製後零卷積參數是不一樣的,這裡保證了模型對於每個模態的適應能力,除此之外,所有的權重是共享的。 ######不同於 SDM 或 ControlNet,這些模型的圖像生成條件是單一的語言提示,或如 canny 這樣的單一類型的視覺條件。 UniControl 需要處理不同任務的各種視覺條件,以及語言提示。因此 UniControl 的輸入包含四個部分: noise, text prompt, visual condition, task instruction。其中 task instruction 可以自然的根據 visual condition 的模態得到。

有了這樣產生的訓練配對,該研究採用 DDPM [5] 對模型進行訓練。

#圖6: 測試集視覺對比結果。測試資料來自於MSCOCO [6] 和Laion [7]
#與官方或本研究復現的ControlNet 對比結果如圖6 所示,更多結果請參考論文。
模型在以下兩個場景中測試zero-shot 能力:
混合任務泛化:研究考慮兩種不同的視覺條件作為UniControl 的輸入,一個是分割圖和人類骨骼的混合,並在文字提示中添加特定關鍵字"背景" 和"前景"。此外,該研究將混合任務指令重寫為結合的兩個任務的指令混合,例如 "分割圖和人類骨骼到影像"。
新任務泛化:UniControl 需要在新的未見過的視覺條件上產生可控制的圖像。為了實現這一點,基於未見過的和見過的預訓練任務之間的關係估計任務權重至關重要。任務權重可以透過手動分配或計算嵌入空間中的任務指令的相似度分數來估計。 MOE-style Adapter 可以與估計的任務權重線性組裝,以從新的未見過的視覺條件中提取淺層特徵。
視覺化的結果如圖 7 所示,更多結果請參考論文。

#圖7: UniControl 在Zero-shot tasks 上的視覺化結果
總的來說,UniControl 模型透過其控制的多樣性,為可控視覺生成提供了一個新的基礎模型。這種模型能夠為實現影像生成任務的更高層次的自主性和人類控制能力提供可能。該研究期待和更多的研究者討論和合作,以進一步推動這一領域的發展。
更多視覺效果
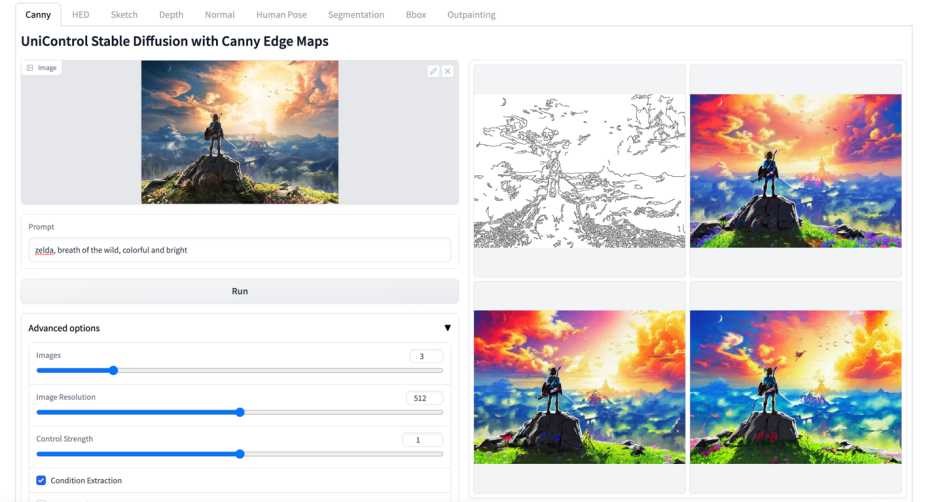
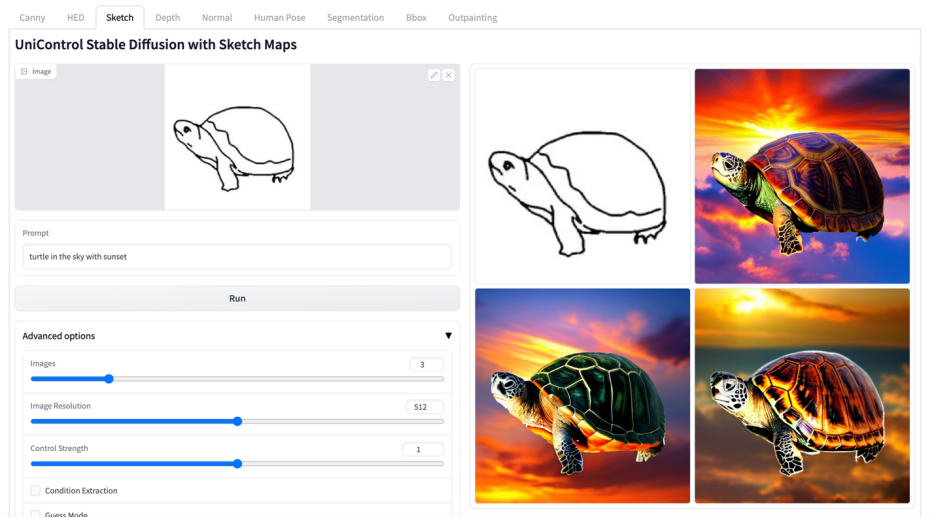
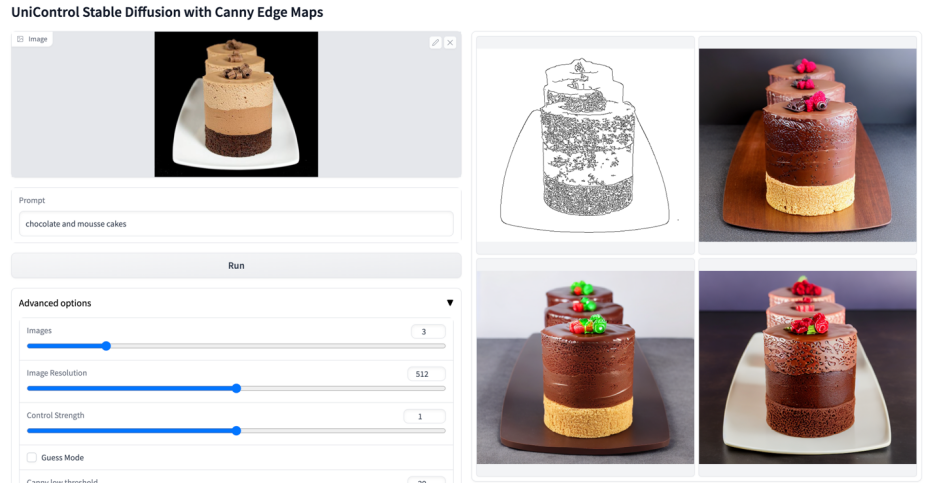
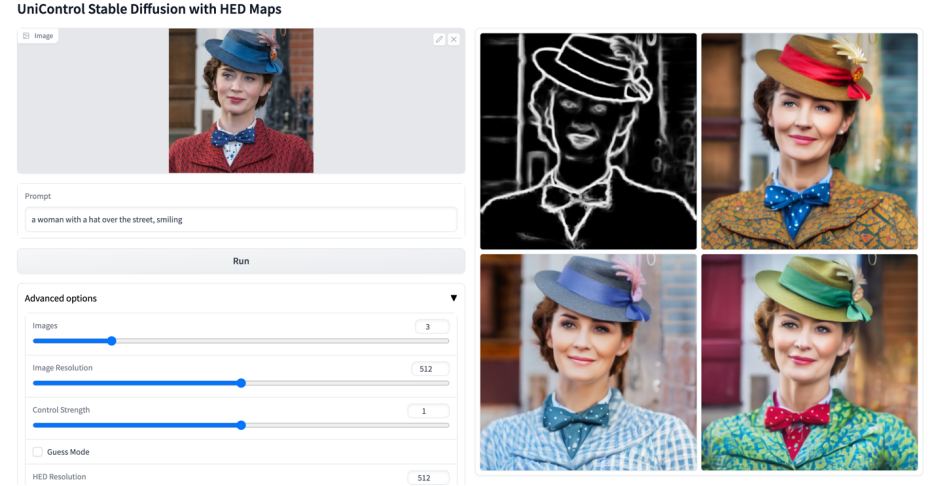
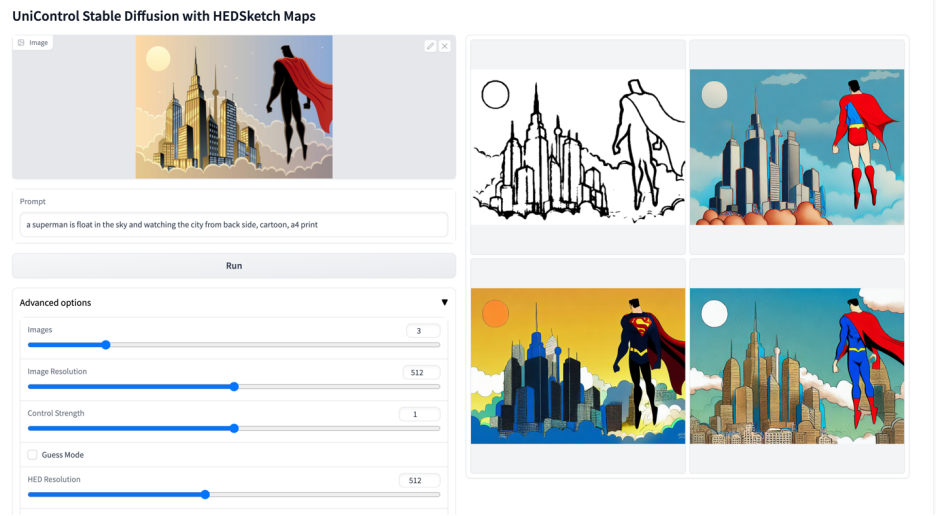
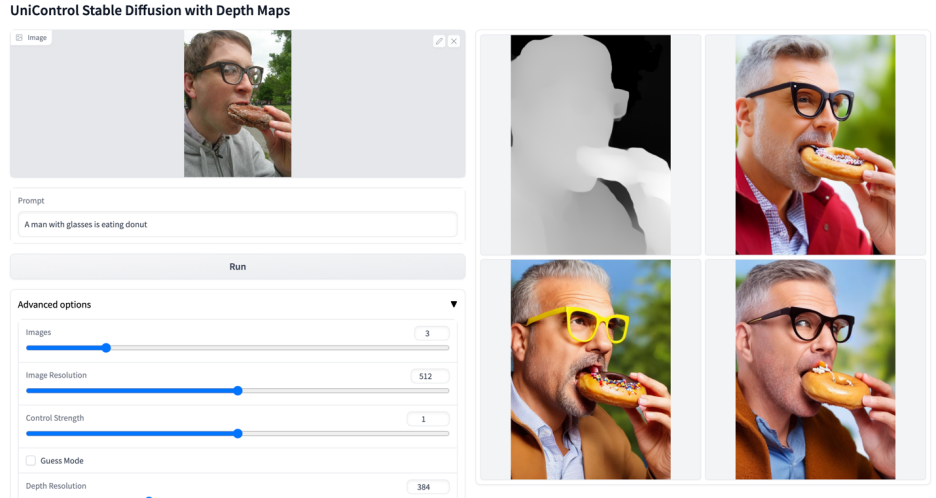
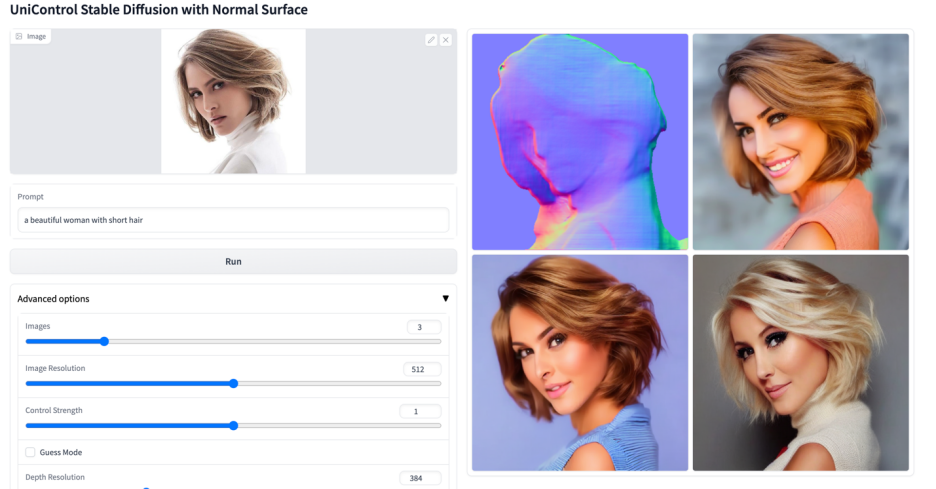
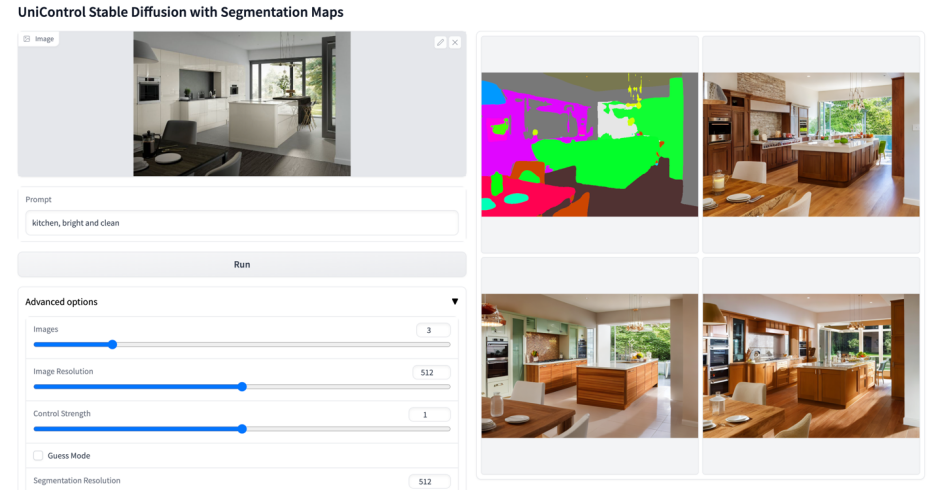
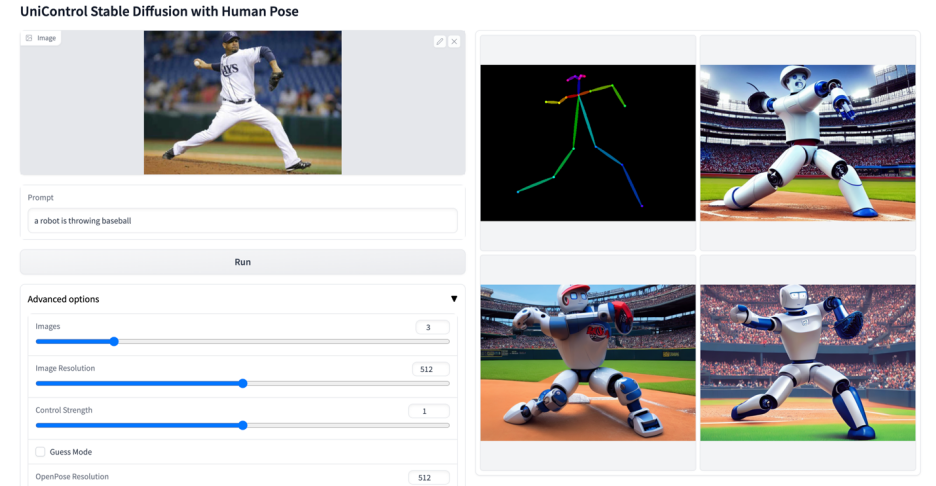
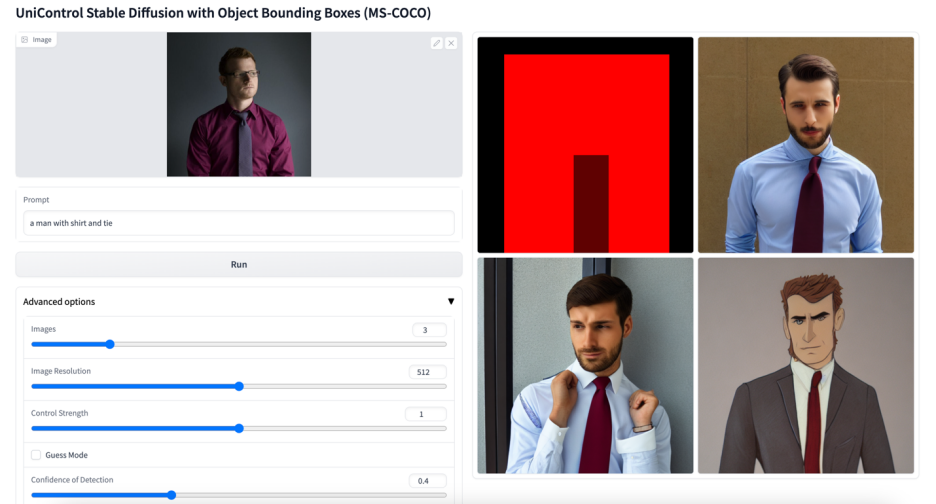
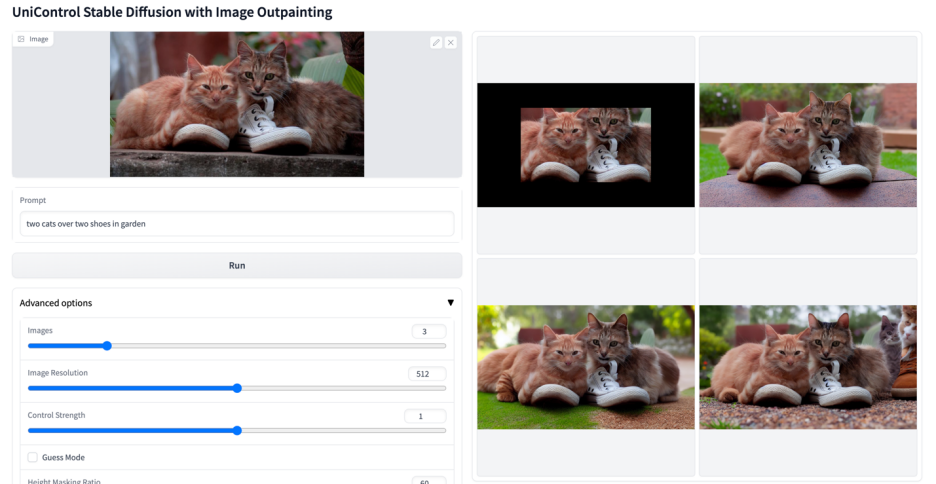
以上是多模態可控圖片產生統一模型來了,模型參數、推理程式碼全部開源的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















