
國內自研大模型迎來新面孔,而且發布即開源!
最新消息,多模態大語言模型TigerBot正式亮相,包含70億參數和1800億參數兩個版本,均對外開源。
由此模型支援的對話AI同步上線。
寫廣告詞、做表格、修正文法錯誤,效果都不錯;也支援多模態,能產生圖片。

評測結果顯示,TigerBot-7B已達到OpenAI同樣大小模型綜合表現的 96%。
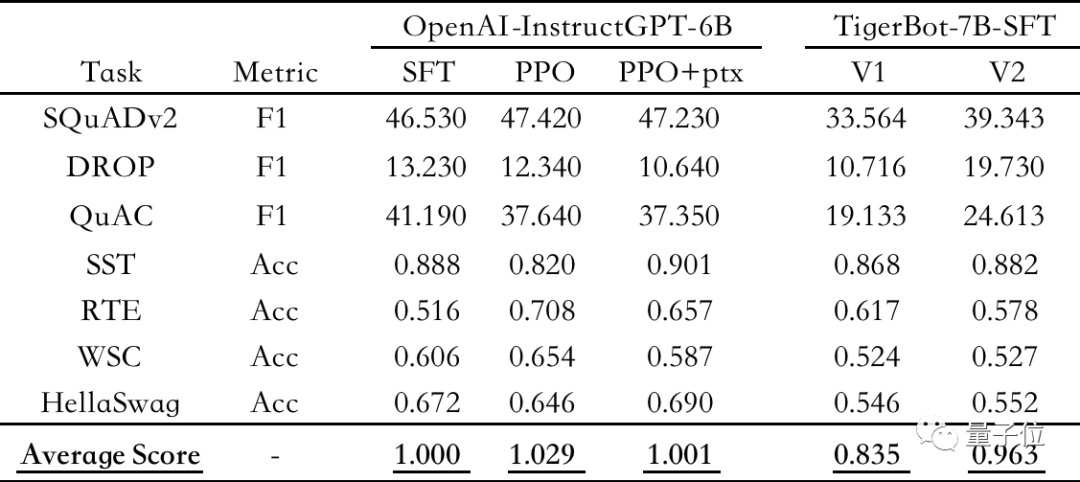
△公開NLP 資料集上的自動評測,以OpenAI-instruct GPT-6B-SFT為基準,歸一化並平均各模型的得分情況
而更大規模的TigerBot-180B或是目前業界開源的最大規模大語言模型。
此外,團隊還一併開源100G預訓練資料、監督微調1G或100萬條資料。
基於TigerBot,開發者在半天內就能打造出自己的專屬大模型。
目前TigerBot對話AI已邀請內測,開源程式碼資料等已上傳至GitHub(詳細連結見文末)。
如上這些重磅工作,來自一支最初只有5人的小團隊,首席程式設計師&科學家就是CEO本人。
但這個團隊,絕非師出無名。
從2017年起,他們就在NLP領域開始創業,專長垂直領域搜尋。 最擅長對數據重度以來的金融領域,和方正證券、國信證券等有過深入合作。
創辦人兼CEO,有20多年經驗,曾任UC伯克利客座教授,手握3篇最佳頂會論文和10項技術專利。
如今,他們決心從專長領域走向通用大模型。
而且一開始便從最底層的基礎模型做起,3個月內完成3000次實驗迭代,還有底氣將階段性成果對外開源。
不禁讓人好奇,他們是誰?想要做哪些事?如今已經帶來了哪些階段性成果?
具體來看,TigerBot是一款國產自研的多國語言任務大模型。
涵蓋生成、開放問答、程式設計、畫圖、翻譯、腦力激盪等15大類能力,支援子任務超過60種。
而且支援外掛功能,能讓模型聯網,取得到更新鮮的數據和資訊。
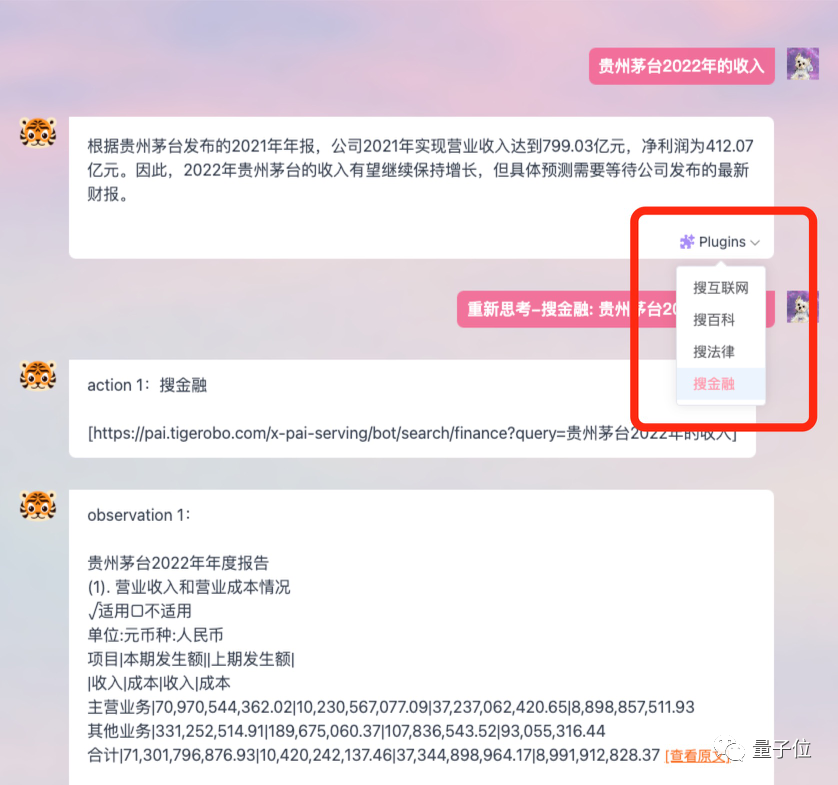
它的定位更偏向辦公室場景,提出改善人們工作流程、提高效率的目標。
例如讓它來幫我寫一封Apple Vision Pro的新聞快訊,效果有模有樣:

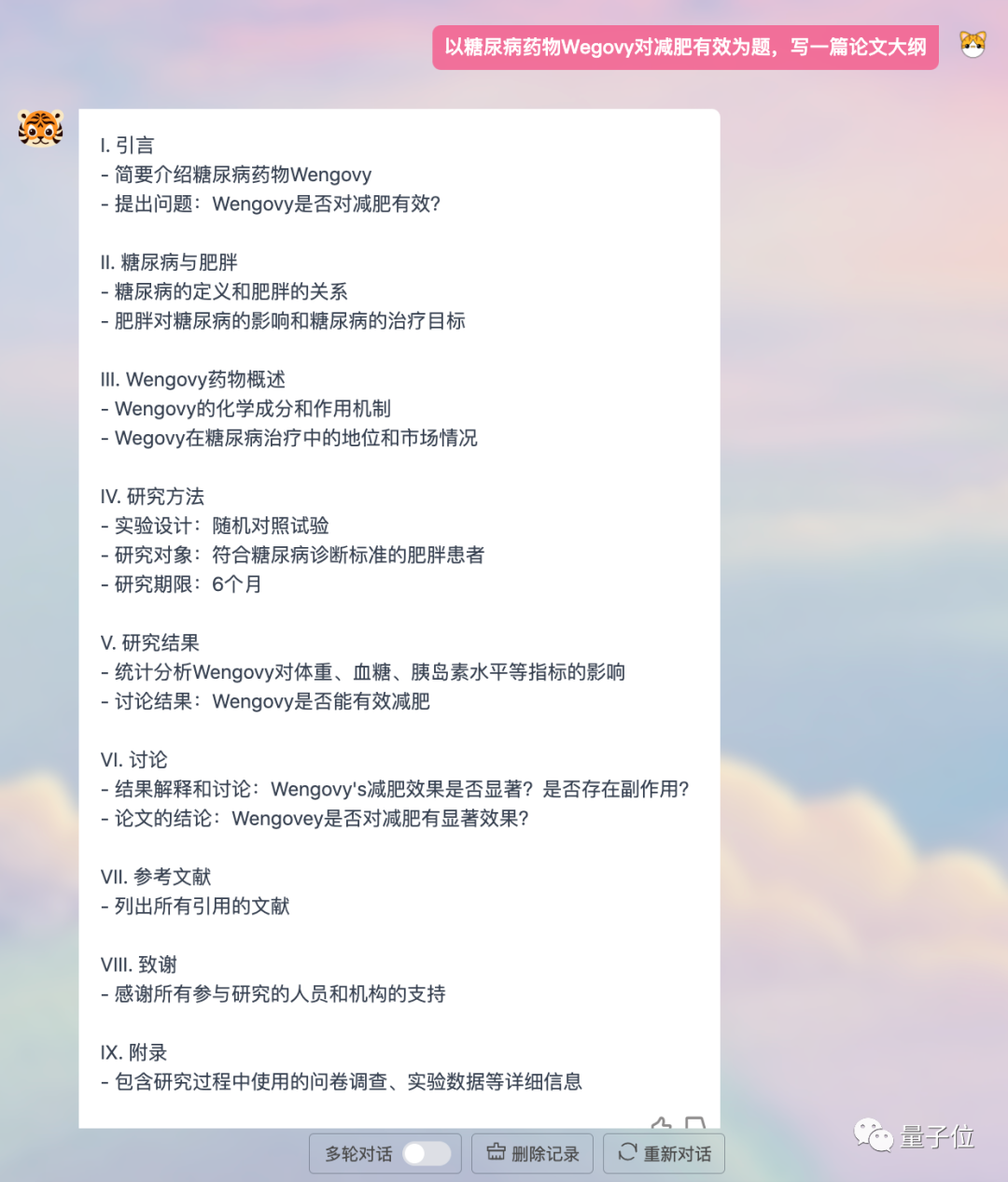
或寫一個論文大綱,條理清晰、結構合理:
程式設計也沒問題,並且支持英文對話。
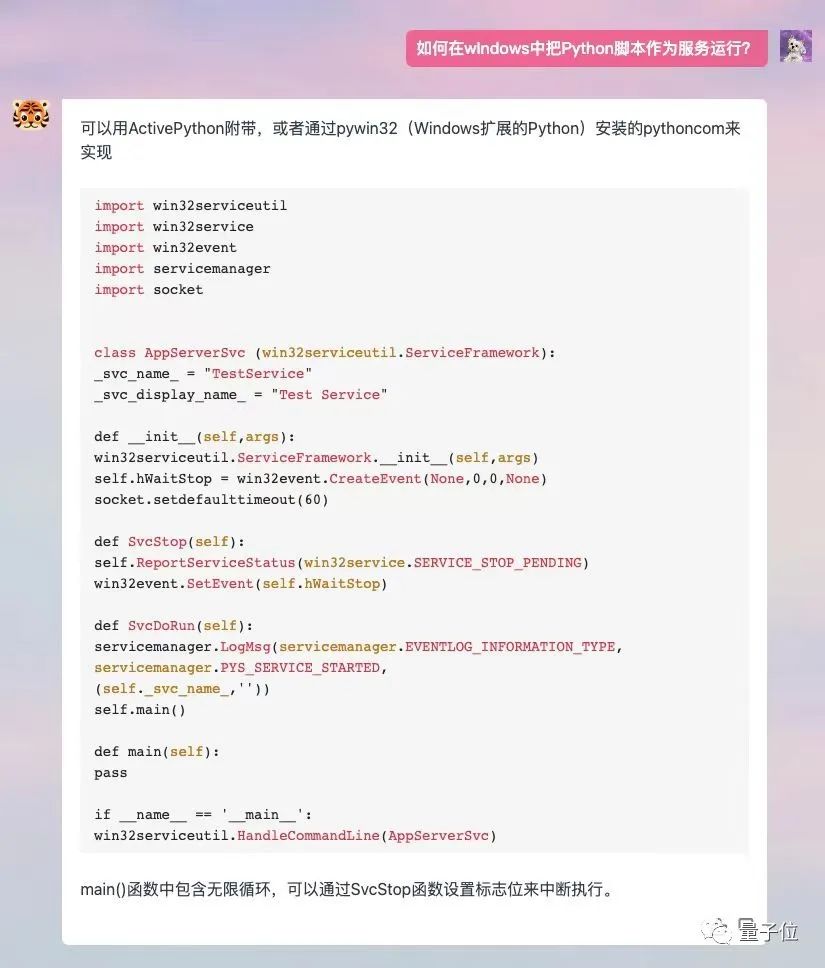
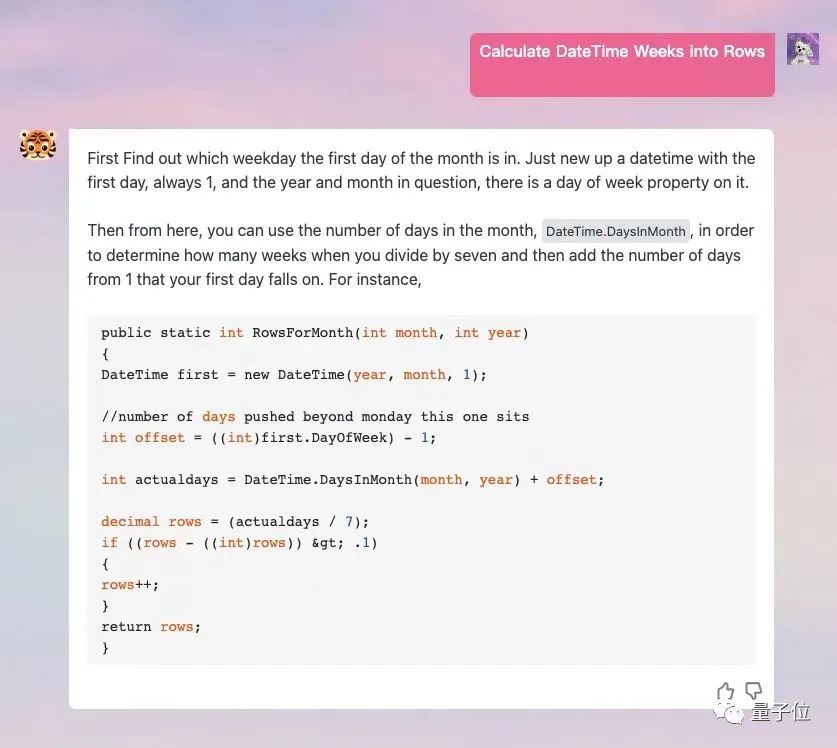
#如果讓它畫圖的話,每次都會產生3張不一樣的,可以自己挑選。

這次發布,TigerBot一共推出了兩種size:70億參數(TigerBot-7B)和1800億參數(TigerBot-180B)。
團隊將目前取得的階段性成果-模型、程式碼、數據,通通開源。
開源模型包含三個版本:
其中TigerBot-7B-base的表現優於OpenAI同等可比較模型、BLOOM。 TigerBot-180B-research或是目前業界開源的最大規模模型(Meta開源OPT的參數量為1750億、BLOOM則為1760億規模)。
開源程式碼包括基本訓練和推理程式碼,雙卡推理180B模型的量化和推理程式碼。
數據包含100G預訓練數據,監督微調1G或100萬條數據。
根據OpenAI InstructGPT論文在公開NLP資料集上的自動評測,TigerBot-7B已達到 OpenAI 同樣大小模型的綜合表現的96%。
而這個版本還只是MVP(最小可行性模型)。
這些成果主要得益於團隊在GPT和BLOOM基礎上,在模型架構和演算法上都做了更進一步的優化,也是TigerBot團隊過去幾個月來的主要創新工作,讓模型的學習能力、創造力和生成可控上都有明顯提升。
具體如何實現?往下看。
TigerBot帶來的創新主要有以下幾個面向:
首先來看指令完成監督微調方法。
它能讓模型在只使用少量參數的情況下,就能快速理解人類提出了哪一類問題,提升答案的準確性。
原理上使用了更強的監督學習進行控制。
透過Mark-up Language(標記語言)的方式,用機率的方法讓大模型更能精確區分指令的類別。例如指令的問題是偏事實類還是發散類別?是代碼嗎?是表格嗎?
因此TigerBot涵蓋了10大類、120類小任務。然後讓模型基於判斷,朝對應方向優化。
帶來的直接好處是呼叫參數量較少,同時模型對新資料或任務的適應能力較好,即學習性(learnability)提升。
在同樣50萬個資料訓練的情況下,TigerBot的收斂速度比史丹佛推出的Alpaca快5倍,在公開資料集上評測顯示效能提升17%。
其次,模型如何更好平衡生成內容的創意和事實可控性,也非常關鍵。
TigerBot一方面採用ensemble的方法,將多個模型組合起來兼顧創造性和事實可控性。
甚至可以依照使用者的需求,調整模型在二者之間的權衡。
另一方面也採用了AI領域經典的機率建模(Probabilistic Modeling)方法。
它能讓模型在產生內容的過程中,根據最新產生的token,給出兩個機率。一個機率判斷內容是否應該繼續發散下去,一個機率表示生成內容離事實內容的偏離程度。
綜合兩個機率的數值,模型會在創造性和可控性上做一個權衡。 TigerBot中這兩個機率的得出由專門資料進行訓練。
考慮到模型產生下一個token時,往往無法看到全文的情況,TigerBot還會在回答寫完後再進行一次判斷,如果最終發現回答不準確,便會要求模型重寫。
我們在體驗過程中也發現,TigerBot產生回答並不是ChatGPT那樣逐字輸出的模式,而是在「思考」後給予完整答案。

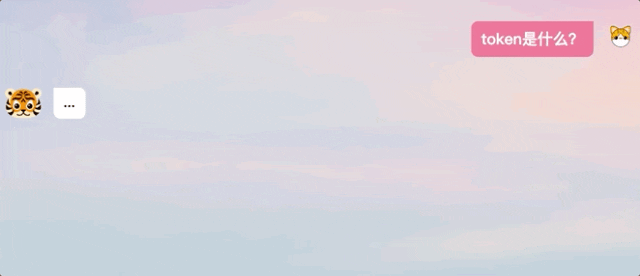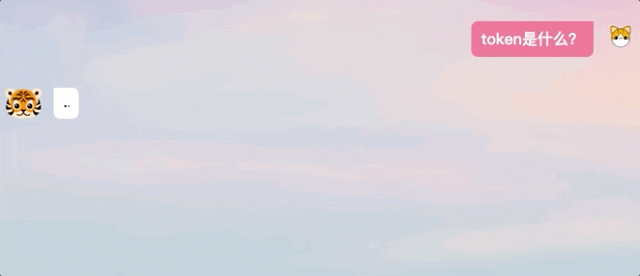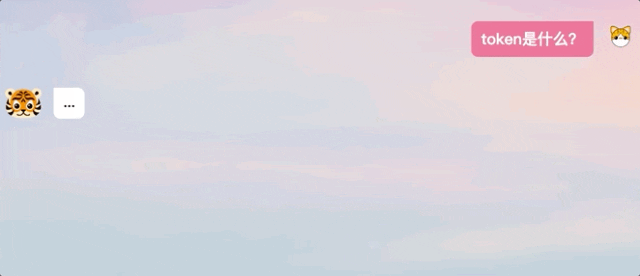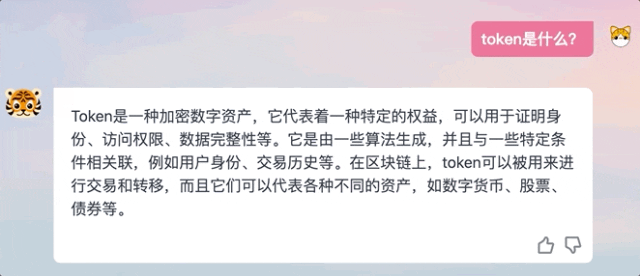
#△ChatGPT和TigerBot回答方式比較
而且由於TigerBot的推理速度很快,能夠支撐模型快速重寫。
這裡就要說到TigerBot在訓練與推理上的創新了。
除了思考到模型底層架構的最佳化,TigerBot團隊認為工程化程度在當下大模型時代也很重要。
一方面是因為要考慮營運效率-隨著大模型趨勢持續,誰能更快迭代模型非常關鍵;另一方面當然也要考慮算力的經濟性。
因此,他們在並行訓練方面,突破了deep-speed等主流框架中的若干記憶體和通訊問題,實現了千卡環境下訓練數月無間斷。
這使得他們每月在訓練上的開銷,能夠節省數十萬。
最後,針對中文連續性強、多義歧義情況多等問題,TigerBot從tokenizer到訓練演算法上,都做了相應優化。
總結來看,TigerBot實現的技術創新,全都發生在當下大模型領域中最受關注的領域內。
不僅是底層架構的最佳化,也考慮到了落地層面的使用者需求、開銷成本等問題。且整個創新過程的速度非常快,是10人左右小團隊在幾個月時間內實現。
這對團隊本身的開發能力、技術見解、落地經驗都有非常高的要求。
所以,到底是誰帶著TigerBot突然殺入大眾視野?
TigerBot的幕後開發團隊,其實就藏在它本身的名字裡-虎博科技。
它成立於2017年,也就是人們常說的AI上一輪爆發期內。
虎博科技給自己的定位是“一家人工智慧技術驅動的公司”,專注於NLP技術的應用落地,願景是打造下一代智能且簡單的搜尋體驗。
具體實現路徑上,他們選擇了對資料資訊最敏感的領域之一—金融。自研了垂直領域內智慧搜尋、智慧推薦、機器閱讀理解、總結、翻譯等技術,推出了智慧金融搜尋和問答系統「虎博搜尋」等。
公司創辦人兼CEO為陳燁,是一位世界級AI科學家。

他博士畢業於威斯康辛大學麥迪遜分校,曾任加州大學柏克萊分校客座教授,到現在為止從業已有20餘年。
他先後在微軟、eBay、雅虎擔任主任科學家和研發總監等要職,主導研發了雅虎的行為定向系統、eBay的推薦系統以及微軟搜尋廣告競拍市場機制等。
2014年,陳燁加入大眾點評。之後美團點評合併,他擔任美團點評資深副總裁,分管集團廣告平台,協助集團年廣告收入從1000萬提升至40多億。
學術方面,陳燁曾三度獲得頂會最佳論文獎(KDD和SIGIR),在SIGKKD、SIGIR、IEEE等人工智慧學術會議發表20篇論文,擁有10項專利。
2017年7月,陳燁正式創立虎博科技。成立1年後,虎博便快速拿下超億元融資,目前公司揭露融資總額達4億元。

7個月以前,ChatGPT橫空出世,AI在時隔6年後,再次顛覆大眾認知。
即便是陳燁這樣在AI領域內創業多年的技術專家,也用「從業以來前所未有的震撼」來形容。
而在震撼之外,更多還是激動。
陳燁說,看到ChatGPT後,幾乎不用思考或決定,內心的呼喚讓他一定會跟進趨勢。
所以,從1月開始,虎博正式成立了TigerBot的初始開發團隊。
不過跟想像中不太一樣,這是一支極客風格非常鮮明的團隊。
用他們自己的話來說,致敬矽谷90年代經典的「車庫創業」模式。
團隊最初只有5個人,陳燁是首席程式設計師&科學家,負責最核心的程式碼工作。後面成員規模雖有擴充,但也只控制了10人,基本上一人一崗。
為什麼要這樣做?
陳燁的回答是:
我認為從0到1的創造,是一件很極客的事,而沒有一個極客團隊是超過10個人的。
以及純技術科學的事,小團隊更犀利。
的確,TigerBot的開發過程裡,各方面都透露著果斷、敏銳。
陳燁將這個週期分為三個階段。
第一階段,也就是ChatGPT爆火不久後,團隊迅速掃遍了OpenAI等機構過去5年內所有相關文獻,大致了解ChatGPT的方法機制。
由於ChatGPT程式碼本身不開源,當時相關的開源工作也比較少,陳燁自己上陣寫出TigerBot的程式碼,然後馬上開始跑實驗。
他們的邏輯很簡單,讓模型先在小規模資料上驗證成功,然後經過系統科學評審,也就是形成一套穩定的程式碼。
在一個月時間內,團隊就驗證了模型在70億規模下能達到OpenAI同規模模型80%的效果。
第二階段,透過不斷吸取開源模型和程式碼中的優點,加上對中文資料的專門最佳化處理,團隊快速拿出了一版真實可用的模型,最早的內測版在2月便已上線。
同時,他們也發現在參數量達到百億等級後,模型表現出了湧現的現象。
第三階段,也就是到了最近的一兩個月內,團隊在基礎研究上達成了一些成果和突破。
如上介紹的諸多創新點,就是在這段時期內完成的。
同時在這一階段內整合更大規模算力,達到更快的迭代速度,1-2個星期內,TigerBot-7B的能力便快速從InstructGPT的80%提升到了96%。
陳燁表示,在這個開發週期內,團隊始終保持超高效運作。 TigerBot-7B在幾個月內經歷了3000次迭代。
小團隊的優勢是反應速度快,早上確定工作,下午就能寫完程式碼。數據團隊幾個小時就能完成高品質清洗工作。
但高速開發迭代,還只是TigerBot極客風格的體現點之一。
因為他們僅憑10個人在幾個月內肝出來的成果,將以全套API的形式向業界開源。
如此程度的擁抱開源,在當下趨勢尤其是商業化領域內,比較少見。
畢竟在激烈競爭中,建構技術障礙是商業公司不得不面對的問題。
那麼,虎博科技為什麼敢於開源?
陳燁給了兩點理由:
第一,作為一名AI領域內的技術人員,出於對技術最本能的信仰,他有一點熱血、有一點煽情。
我們想要以世界級的大模型,貢獻於中國創新。給業界一個可用的、底層基礎紮實的通用模型,能讓更多人快速訓練出專業大模型,實現產業群聚的生態打造。
第二,TigerBot接下來還會繼續保持高速迭代,陳燁認為在這種賽跑的局面下,他們能保持身位優勢。即便是看到有人以TigerBot為底層開發出了性能更好的產品,這對業界來說又何嘗不是一件好事?
陳燁透露,接下來虎博科技還會持續快速推進TigerBot的工作,進一步擴充資料來提升模型效能。
在ChatGPT發布6個月以後,隨著一個個大模型橫空出世、一家家巨頭火速跟進,AI行業格局正在被快速重塑。
儘管當下還相對混沌,但大致來看,基本上會分為模型層、中間層、應用層三層。
其中模型層決定底層能力,至關重要。
它的創新程度、穩定程度、開放程度,直接決定了應用層的豐富程度。
而應用層的發展是大模型趨勢演進的外化體現;更是AIGC願景裡,人類社會生活走向下一階段的重要影響因素。
那麼,在大模型趨勢的起點,如何夯實底層模型基礎,是業界必須思考的事。
在陳燁看來,目前人類才只開發了大模型10-20%的潛力,在fundamental層面還有非常大的創新和提升空間。
就好像曾經的西部淘金熱,最初要找到金礦在哪裡一樣。
所以在這樣的趨勢和產業發展要求下,虎博科技作為國產領域創新代表,高舉開源大旗,迅速起跑、追趕世界最前沿技術,確實也為產業內帶來了一股與眾不同的氣息。
國產AI創新正在高速狂奔,未來一段時間內,相信我們還會看到更多有想法、有能力的團隊亮相,為大模型領域注入新的見解、帶來新的改變。
而這,或許就是趨勢轟轟烈烈演進過程中,最迷人之處了。
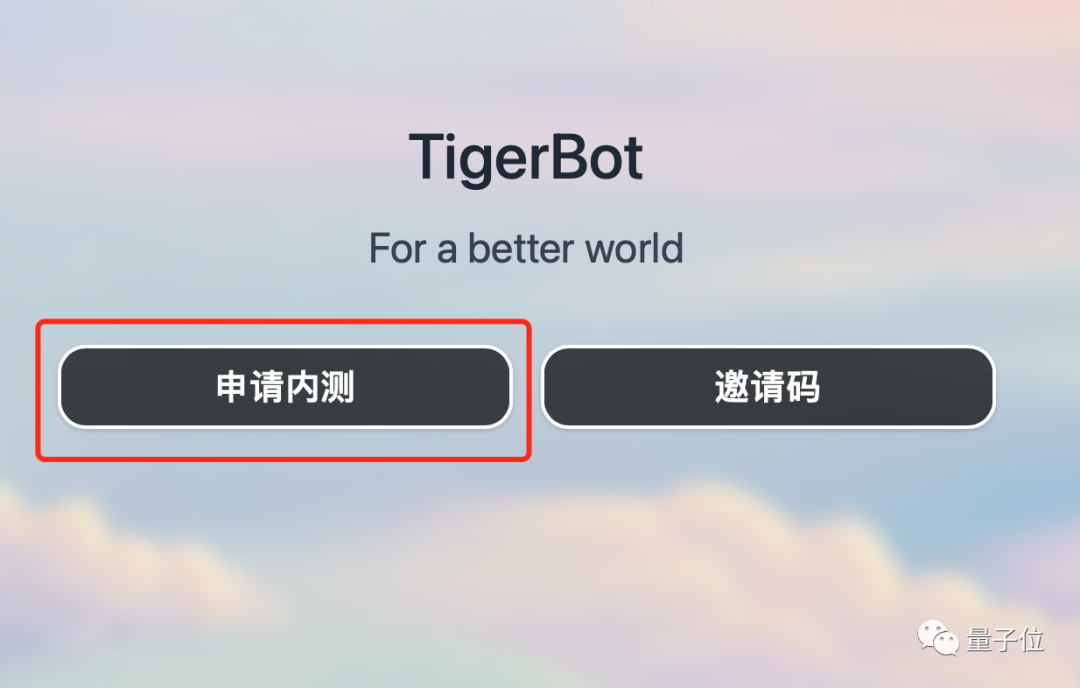
想體驗TigerBot的童鞋,可以透過下方連結或點擊“閱讀原文”進入網站,點擊“申請內測”,組織代碼中寫“量子位元”即可透過內測~
官網網址:https://www.tigerbot.com/chat
#GitHub開源位址:https://github.com/TigerResearch/TigerBot
#以上是效果達OpenAI同規模模型96%,發布即開源!國內團隊新發大模型,CEO上陣寫程式碼的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















