

OpenAI霸榜前二!大模型代碼生成排行榜出爐,70億LLaMA拉跨,被2.5億Codex吊打

最近,Matthias Plappert的一篇推文點燃了LLMs圈的廣泛討論。
Plappert是一位知名的電腦科學家,他在HumanEval上發布了自己對AI圈主流的LLM進行的基準測試結果。
他的測試偏向程式碼產生方面。
結果令人大為不震撼,又大為震撼。

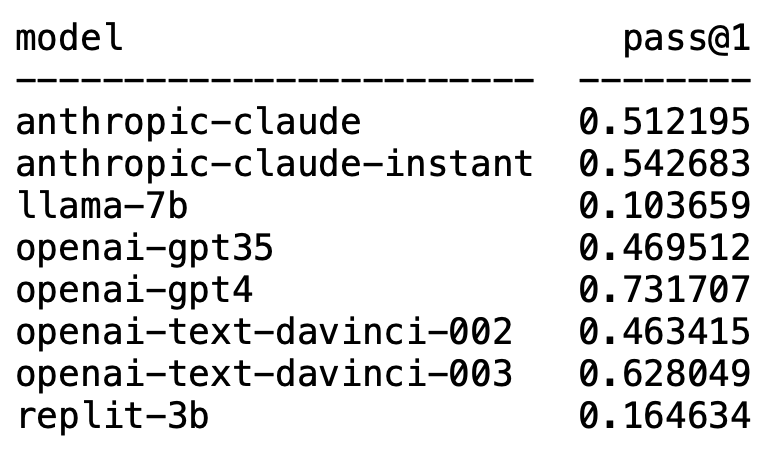
意料之內的是,GPT-4毫無疑問霸榜,摘得第一名。
意料之外的是,OpenAI的text-davinci-003異軍突起,拿了個第二。
Plappert表示,text-davinci-003堪稱一個「寶藏」模型。
而耳熟能詳的LLaMA在程式碼產生方面卻並不出色。
OpenAI霸榜
Plappert表示,GPT-4的表現表現甚至比文獻中的數據還要好。
論文中GPT-4的一輪測試數據是67%的通過率,而Plappert的測試則達到了73%。

在分析成因時,他表示,資料上存在差異有不少可能性。其中之一是他給GPT-4的prompt要比論文作者測試的時候好上那麼一些。
另一個原因是,他猜測論文在測試GPT-4的時候模型的溫度(temperature)不是0。
「溫度」是用來調整模型生成文字時創造性和多樣性的參數。 「溫度」是一個大於0的數值,通常在 0 到 1 之間。它影響模型生成文本時採樣預測詞彙的機率分佈。
當模型的「溫度」較高時(如0.8、1 或更高),模型會更傾向於從較多樣且不同的詞彙中選擇,這使得生成的文字風險性更高、創意性更強,但也可能產生更多的錯誤和不連貫之處。
而當「溫度」較低時(如0.2、0.3 等),模型主要會從具有較高機率的詞彙中選擇,從而產生更平穩、更連貫的文本。
但此時,產生的文字可能會顯得過於保守和重複。
因此在實際應用中,需要根據具體需求來權衡選擇合適的「溫度」值。
接下來,在評論text-davinci-003時,Plappert表示這也是OpenAI旗下一個很能打的模型。
雖然不比GPT-4,但是一輪測試有62%的通過率還是能穩穩拿下第二名的寶座。
Plappert強調,text-davinci-003最好的一點是,使用者不需要使用ChatGPT的API。這意味著給prompt的時候能簡單一點。
此外,Plappert也給予了Anthropic AI的claude-instant模型比較高的評估。
他認為這個模型的表現不錯,比GPT-3.5能打。 GPT-3.5的通過率是46%,而claude-instant是54%。
當然,Anthropic AI的另一個LLM——claude,沒有claude-instant能打,通過率只有51%。
Plappert表示,測試兩個模型用的prompt都一樣,不行就是不行。
除了這些熟能詳的模型,Plappert也測試了不少開源的小模型。
Plappert表示,自己能在本地運行這些模型,這點還是不錯的。
不過從規模上看,這些模型顯然沒有OpenAI和Anthropic AI的模型大,所以硬拿它們對比有點以大欺小了。

LLaMA程式碼產生?拉胯
當然,Plappert對LLaMA的測試結果並不滿意。
從測試結果來看,LLaMA在產生程式碼方面表現很差勁。可能是因為他們在從GitHub收集資料時採用了欠採樣的方法(under-sampling)。
就算和Codex 2.5B相比,LLaMA的表現也不是個兒。 (通過率10% vs. 22%)

最後,他測試了Replit的3B大小的模型。
他表示,表現還不錯,但和推特上宣傳的數據相比差點意思(通過率16% vs. 22%)
Plappert認為,這可能是因為他在測試這個模型時所用的量化方式讓通過率掉了幾個百分比。
在評測的最後,Plappert提到了一個很有趣的點。
某位用戶在推特上發現,當使用Azure平台的Completion API(補全API)(而非Chat API)時,GPT-3.5-turbo的效能表現更好。
Plappert認為這種現象具有一定合理性,因為透過Chat API輸入prompt可能會相當複雜。

以上是OpenAI霸榜前二!大模型代碼生成排行榜出爐,70億LLaMA拉跨,被2.5億Codex吊打的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 遠端桌面無法驗證遠端電腦的身份
Feb 29, 2024 pm 12:30 PM
遠端桌面無法驗證遠端電腦的身份
Feb 29, 2024 pm 12:30 PM
Windows遠端桌面服務允許使用者遠端存取計算機,對於需要遠端工作的人來說非常方便。然而,當使用者無法連線到遠端電腦或遠端桌面無法驗證電腦身分時,會遇到問題。這可能是由網路連線問題或憑證驗證失敗引起的。在這種情況下,使用者可能需要檢查網路連線、確保遠端電腦是線上的,並嘗試重新連線。另外,確保遠端電腦的身份驗證選項已正確配置也是解決問題的關鍵。透過仔細檢查和調整設置,通常可以解決Windows遠端桌面服務中出現的這類問題。由於存在時間或日期差異,遠端桌面無法驗證遠端電腦的身份。請確保您的計算
 2024 CSRankings全美電腦科學排名發布! CMU霸榜,MIT跌出前5
Mar 25, 2024 pm 06:01 PM
2024 CSRankings全美電腦科學排名發布! CMU霸榜,MIT跌出前5
Mar 25, 2024 pm 06:01 PM
2024CSRankings全美電腦科學專業排名,剛剛發布了!今年,全美全美CS最佳大學排名中,卡內基美隆大學(CMU)在全美和CS領域均名列前茅,而伊利諾大學香檳分校(UIUC)則連續六年穩定地位於第二。佐治亞理工學院則排名第三。然後,史丹佛大學、聖迭戈加州大學、密西根大學、華盛頓大學並列世界第四。值得注意的是,MIT排名下跌,跌出前五名。 CSRankings是由麻省州立大學阿姆赫斯特分校電腦與資訊科學學院教授EmeryBerger發起的全球院校電腦科學領域排名計畫。該排名是基於客觀的
 解決win7驅動程式碼28的方法
Dec 30, 2023 pm 11:55 PM
解決win7驅動程式碼28的方法
Dec 30, 2023 pm 11:55 PM
有的用戶在安裝設備的時候遇到了錯誤,提示錯誤代碼28,其實這主要是由於驅動程式的原因,我們只要解決win7驅動程式碼28的問題就可以了,下面就一起來看一下應該怎麼來操作吧。 win7驅動程式碼28怎麼辦:首先,我們需要點擊螢幕左下角的開始選單。接著,在彈出的選單中找到並點擊“控制面板”選項。這個選項通常位於選單的底部或附近。點擊後,系統會自動開啟控制面板介面。在控制面板中,我們可以進行各種系統設定和管理操作。這是懷舊大掃除關卡中的第一步,希望對大家有幫助。然後,我們需要繼續操作,進入系統和
 藍色畫面代碼0x0000001怎麼辦
Feb 23, 2024 am 08:09 AM
藍色畫面代碼0x0000001怎麼辦
Feb 23, 2024 am 08:09 AM
藍屏代碼0x0000001怎麼辦藍屏錯誤是電腦系統或硬體出現問題時的一種警告機制,代碼0x0000001通常表示出現了硬體或驅動程式故障。當使用者在使用電腦時突然遇到藍色畫面錯誤,可能會感到驚慌失措。幸運的是,大多數藍色畫面錯誤都可以透過一些簡單的步驟來排除和處理。本文將為讀者介紹一些解決藍屏錯誤代碼0x0000001的方法。首先,當遇到藍色畫面錯誤時,我們可以嘗試重
 未能開啟這台電腦上的群組原則對象
Feb 07, 2024 pm 02:00 PM
未能開啟這台電腦上的群組原則對象
Feb 07, 2024 pm 02:00 PM
使用電腦時,作業系統偶爾也會故障。今天遇到的問題是在存取gpedit.msc時,系統提示無法開啟群組原則對象,因為可能缺乏正確的權限。未能開啟這台電腦上的群組原則對象解決方法:1、存取gpedit.msc時,系統提示無法開啟該電腦上的群組原則對象,因為缺乏權限。詳細資訊:系統無法定位指定的路徑。 2、用戶點擊關閉按鈕後,就彈出如下錯誤視窗。 3.立即查看日誌記錄,並結合記錄信息,發現問題出在C:\Windows\System32\GroupPolicy\Machine\registry.pol文件
 電腦頻繁藍屏而且每次代碼不一樣
Jan 06, 2024 pm 10:53 PM
電腦頻繁藍屏而且每次代碼不一樣
Jan 06, 2024 pm 10:53 PM
win10系統是一款非常優秀的高智慧系統強大的智慧可以為使用者帶來最好的使用體驗,一般正常的情況下使用者的win10系統電腦都不會出現任何的問題!但在優秀的電腦也難免會出現各種故障最近一直有小伙伴們反應自己的win10系統遇到了頻繁藍屏的問題!今天小編就為大家帶來了win10電腦頻繁藍屏不同代碼的解決方法讓我們一起來看看吧。電腦頻繁藍屏而且每次代碼不一樣的解決辦法:造成各種故障碼的原因以及解決建議1、0×000000116故障原因:應該是顯示卡驅動不相容。解決建議:建議更換廠商原帶驅動。 2、
 解決代碼0xc000007b錯誤
Feb 18, 2024 pm 07:34 PM
解決代碼0xc000007b錯誤
Feb 18, 2024 pm 07:34 PM
終止代碼0xc000007b在使用電腦時,有時會遇到各種各樣的問題和錯誤代碼。其中,終止代碼最為令人困擾,尤其是終止代碼0xc000007b。這個程式碼表示某個應用程式無法正常啟動,給用戶帶來了不便。首先,我們來了解終止碼0xc000007b的意思。這個程式碼是Windows作業系統的錯誤代碼,通常發生在32位元應用程式嘗試在64位元作業系統上執行時。它表示應
 詳解0x0000007f藍屏代碼的原因及解決方案
Dec 25, 2023 pm 02:19 PM
詳解0x0000007f藍屏代碼的原因及解決方案
Dec 25, 2023 pm 02:19 PM
藍屏是我們在系統使用的時候常常會碰到的問題,根據錯誤代碼的不同,會有很多中不一樣的原因和解決方法。例如我們在使用時遇到stop:0x0000007f的問題,可能是硬體或軟體錯誤,下面就跟著小編一起來看看解決方法吧。 0x000000c5藍色畫面代碼原因:答:記憶體、CPU、顯示卡突然超頻,或軟體運作錯誤。解決方法一:1.開機時不斷按F8進入,選擇安全模式,回車進入。 2.進入安全模式後,按win+r開啟運行窗口,輸入cmd,回車。 3.在指令提示窗口,輸入“chkdsk/f/r”,回車,然後按y鍵。 4、
