
預訓練大語言模型(LLM)在特定任務上的表現不斷提高,隨之而來的是,假如prompt 指令得當,其可以更好的泛化到更多任務,很多人將這一現象歸功於訓練資料和參數的增多,然而最近的趨勢表明,研究者更多的集中在更小的模型上,不過這些模型是在更多資料上訓練而成,因而在推理時更容易使用。
舉例來說,參數量為 7B 的 LLaMA 在 1T token 上訓練完成,儘管平均表現略低於 GPT-3,但參數量是後者的 1/25。不僅如此,目前的壓縮技術還能將這些模型進一步壓縮,在維持效能的同時還能大幅減少記憶體需求。透過這樣的改進,性能良好的模型可以在終端用戶設備(如筆記本)上部署。
然而,這又面臨另一個挑戰,即想要將這些模型壓縮到足夠小的尺寸以適應這些設備,怎樣才能兼顧生成質量。研究表明,儘管壓縮後的模型產生的答案準確率還可以,但現有的 3-4 位元量化技術仍然會讓準確性降低。由於 LLM 生成是順序進行的,依賴先前生成的 token,小的相對誤差不斷累積並導致嚴重的輸出損壞。為了確保可靠的質量,關鍵是設計出低位寬的量化方法,與 16 位元模型相比不會降低預測性能。
然而,將每個參數量化到3-4 位元通常會導致中等程度、甚至是高等程度的準確率損失,特別是那些非常適合邊緣部署的1-10B參數範圍內的較小模型。
為了解決準確性問題,華盛頓大學、蘇黎世聯邦理工學院等機構的研究者提出了一種新的壓縮格式和量化技術SpQR(Sparse-Quantized Representation,稀疏- 量化表徵),首次實現了LLM 跨模型尺度的近無損壓縮,同時達到了與先前方法相似的壓縮水平。
SpQR 透過識別和隔離異常權重來工作,這些異常權重會導致特別大的量化誤差,研究者將它們以更高的精度存儲,同時將所有其他權重壓縮到3-4 位,在LLaMA 和Falcon LLMs 中實現了不到1% 的困惑度相對準確率損失。從而可以在單一 24GB 的消費級 GPU 上運行 33B 參數的 LLM,而不會有任何效能下降,同時還能提高 15% 的速度。
SpQR 演算法高效,既可以將權重編碼為其他格式,也可以在運行時進行有效地解碼。具體來說,該研究為 SpQR 提供了一種高效的 GPU 推理演算法,可以比 16 位元基線模型更快地進行推理,同時實現了超過 4 倍的記憶體壓縮收益。

該研究提出一種混合稀疏量化的新格式— 稀疏量化表徵(SpQR),可以將精確預訓練的LLM 壓縮到每個參數3-4 位,同時保持近乎無損。
具體來說,該研究將整個過程分為兩個步驟。第一步是異常值檢測:該研究首先孤立了異常值權重,並證明其量化會導致高誤差:異常值權重保持高精度,而其他權重以低精度(例如 3 位元的格式)儲存。然後,該研究以非常小的組大小實現分組量化(grouped quantization)的變體,並表明量化尺度本身可以被量化為 3 位表徵。
SpQR 大大減少了 LLM 的記憶體佔用,而不會降低準確性,同時與 16 位元推理相比,LLM 的生成速度快了 20%-30%。
此外,研究發現,權重矩陣中敏感權重的位置不是隨機的,而是具有特定的結構。為了在量化過程中突出顯示其結構,研究計算了每個權重的敏感度,並為 LLaMA-65B 模型可視化這些權重敏感度。下圖 2 描繪了 LLaMA-65B 最後一個自註意力層的輸出投影。
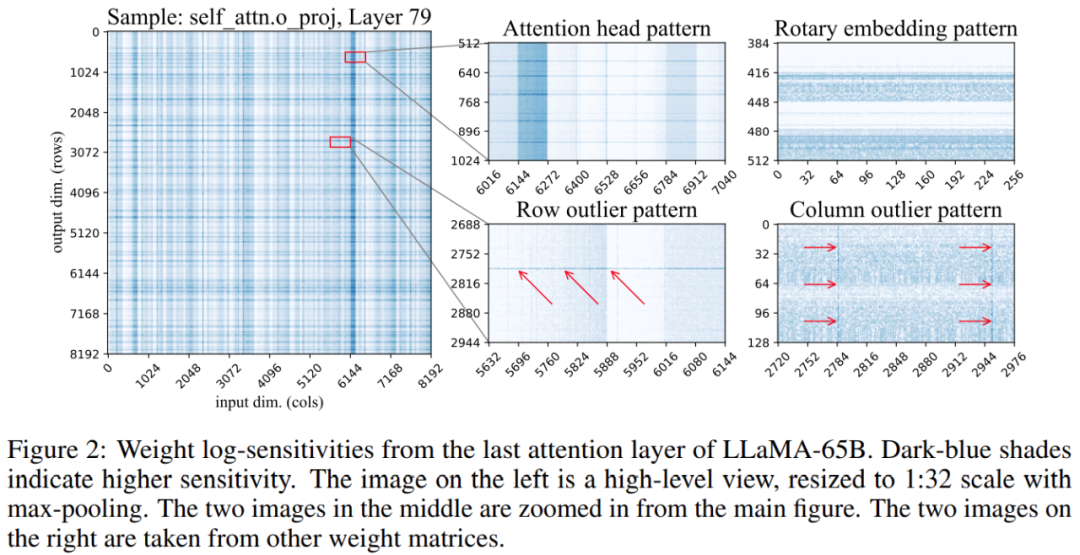
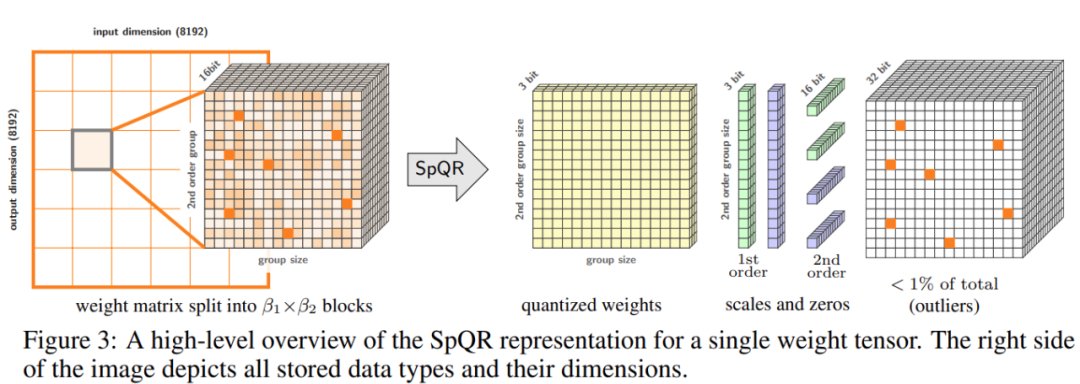
該研究對量化過程進行了兩個改變:一個用於捕捉小的敏感權重組,另一個用於捕捉單一的異常值。下圖3 為SpQR 的整體架構:
#下表為SpQR 量化演算法,左邊的程式碼片段描述了整個過程,右邊的程式碼片段包含了二級量化和尋找異常值的子程式:

##該研究將SpQR 與其他兩種量化方案進行了比較:GPTQ、RTN(rounding-to-nearest),並使用兩個指標來評估量化模型的表現。首先是困惑度的測量,所用資料集包括 WikiText2、 Penn Treebank 以及 C4;其次是在五個任務上的零樣本準確率:WinoGrande、PiQA、HellaSwag、ARC-easy、ARC-challenge。
主要結果。圖 1 結果顯示,在相似的模型大小下,SpQR 的表現明顯優於 GPTQ(以及相應的 RTN),特別是在較小的模型上。這種改進得益於 SpQR 實現了更多的壓縮,同時也減少了損失退化。
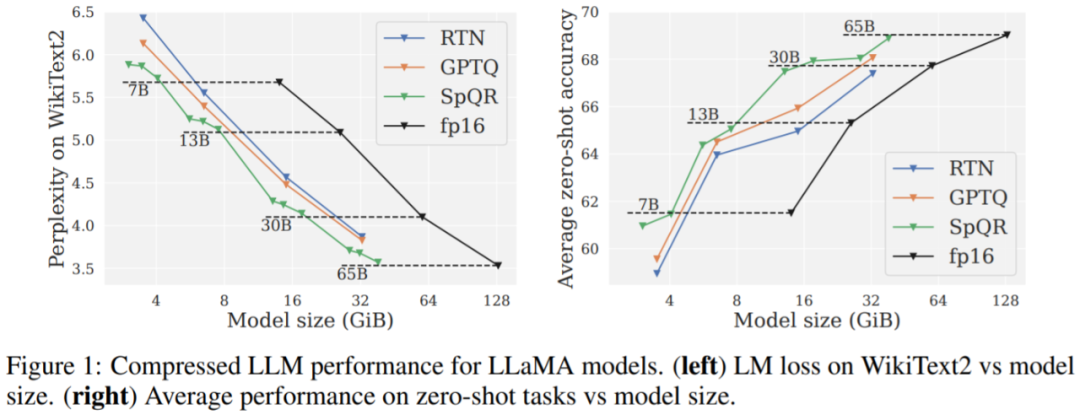
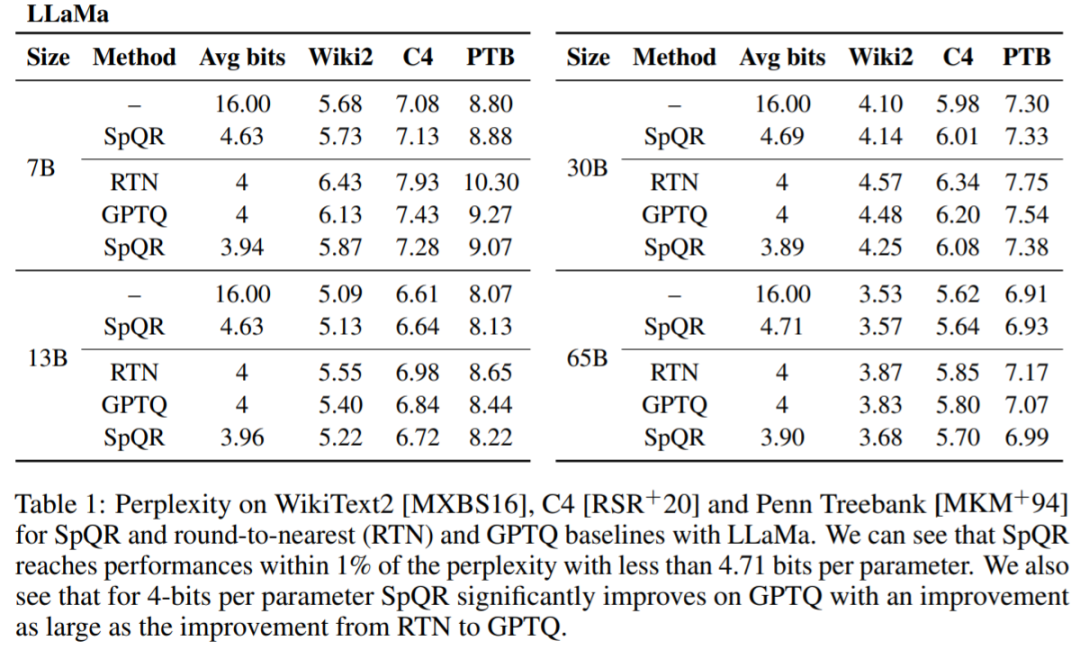
表 1、表 2 結果顯示,對於 4 位元量化,與 GPTQ 相比,SpQR 相對於 16 位元基線的誤差減半。
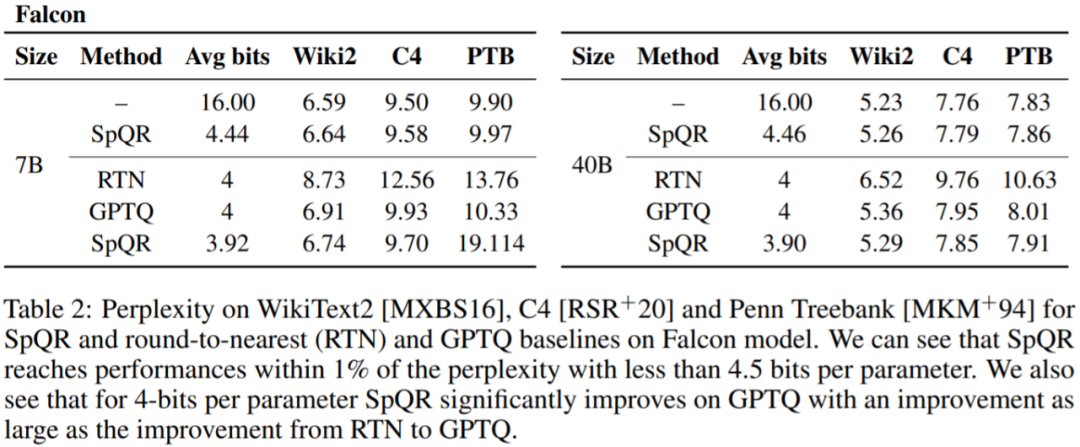
#表3 報告了LLaMA-65B 模型在不同資料集上的困惑度結果。
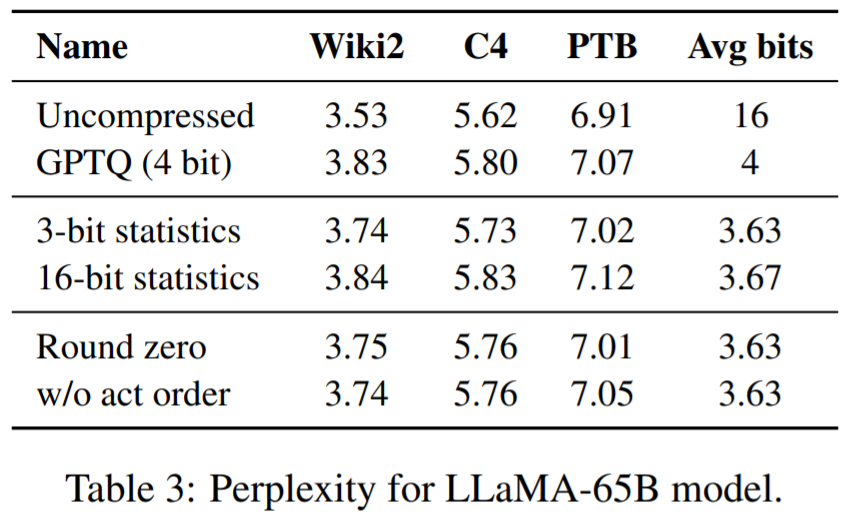
最後,研究評估了 SpQR 推理速度。該研究將專門設計的稀疏矩陣乘法演算法與 PyTorch(cuSPARSE)中實現的演算法進行了比較,結果如表 4 所示。可以看到,儘管 PyTorch 中的標準稀疏矩陣乘法並沒有比 16 位元推理更快,但本文專門設計的稀疏矩陣乘法演算法可以提高約 20-30% 的速度。

以上是將330億參數大模型「塞進」單一消費級GPU,加速15%、效能不減的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















