

500萬token巨獸,一次唸完全套「哈利波特」!比ChatGPT長1000多倍

記性差是目前主流大型語言模型的主要痛點,例如ChatGPT只能輸入4096個token(約3000個字),經常聊著聊著就忘了之前說什麼了,甚至都不夠讀一篇短篇小說的。
過短的輸入視窗也限制了語言模型的應用場景,例如給一篇科技論文(約1萬字)做摘要的時候,需要把文章手動切分後再輸入到模型中,不同章節之間關聯資訊就遺失了。
雖然GPT-4最長支援32000個token、升級後的Claude最高支援10萬token,但只能緩解腦容量不足的問題。
最近一家創業團隊Magic宣布即將發布LTM-1模式,最長支持500萬token,大約是50萬行程式碼或5000個文件,直接比Claude高50倍,基本上可以覆蓋大多數的儲存需求,這可真就量變產生質變了!
LTM-1的主要應用程式場景在於程式碼補全,例如可以產生更長、更複雜的程式碼建議。
還可以跨越多個檔案重複使用、合成資訊。
壞消息是,LTM-1的開發商Magic並沒有發布具體技術原理,只是說設計了一個全新的方法the Long-term Memory Network (LTM Net)。
但也有個好消息,2021年9月,DeepMind等機構的研究人員曾經提出一種名為∞-former 的模型,其中就包含了長期記憶(long- term memory,LTM)機制,理論上可以讓Transformer模型有無限長的記憶力,但目前並不清楚二者是否為相同技術,或改良版。

論文連結:https://arxiv.org/pdf/2109.00301.pdf
#開發團隊表示,雖然LTM Nets可以比GPT看到更多的上下文,但LTM-1模型的參數量比當下的sota模型小的多,所以智慧程度也更低,不過繼續提升模型規模應該可以提升LTM Nets的效能。
目前LTM-1已經開放alpha測試申請。

申請連結:https://www.php. cn/link/bbfb937a66597d9646ad992009aee405
LTM-1的開發商Magic創立於2022年,主要開發類似GitHub Copilot的產品,可以幫助軟體工程師編寫、審查、調試和修改程式碼,目標是為程式設計師打造一個AI同事,其主要競爭優勢就是模型可以讀取更長的程式碼。
Magic致力於公眾利益(public benefit),使命是建構和安全部署超過人類只能的AGI系統,目前還是一家只有10人的創業公司。

今年2月,Magic獲得由Alphabet旗下CapitalG領投的2,300萬美元A輪融資,投資人還包括GitHub前執行長和Copilot的聯合出品人Nat Friedman,目前公司總資金量已達2,800萬美元。
Magic的執行長兼共同創辦人Eric Steinberger本科畢業於劍橋大學電腦科學專業,曾在FAIR做過機器學習研究。

在創立Magic前,Steinberger也曾創立ClimateScience,以幫助全世界的兒童學習氣候變遷的影響。
無限記憶的Transformer
語言模型核心元件Transformer中註意力機制的設計,會導致每次增加輸入序列的長度時,時間複雜度都會呈二次方增長。
雖然已經有一些注意力機制的變體,例如稀疏注意力等降低演算法複雜度,不過其複雜度仍然與輸入長度有關,不能無限擴展。
∞-former中長期記憶(LTM)的Transformer模型可以將輸入序列擴展到無限的關鍵在是一個連續空間注意力框架,該框架用降低表徵粒度的方式提升記憶資訊單元的數量(基底函數)。
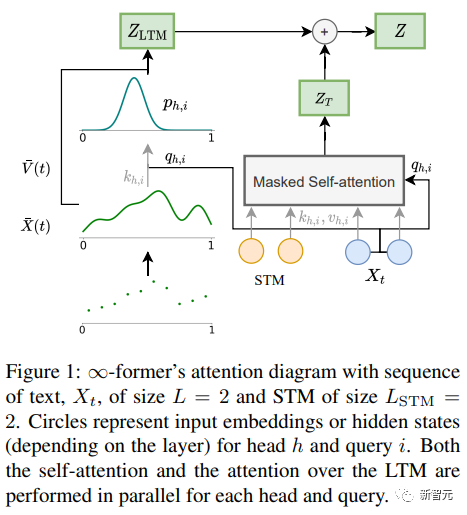
在框架中,輸入序列被表示為一個「連續訊號」,代表N個徑向基底函數( RBF)的線性組合,這樣一來,∞-former的注意力複雜度就降為了O(L^2 L × N),而原始Transformer的注意力複雜度為O(L×(L L_LTM)),其中L和L_LTM分別對應於Transformer輸入大小和長期記憶長度。
這種表示方法有兩個主要優點:
#1. 上下文可以用小於token數量的基底函數N來表示,減少了注意力的計算成本;
2. N可以是固定的,從而能夠在記憶中表示無限的上下文,並且不會增加註意力機制的複雜度。

當然,天下沒有免費的午餐,代價就是解析度的降低:使用較少數量基底函數時,會導致在將輸入序列表示為連續訊號時降低精度。
為了緩解解析度降低問題,研究人員引入了「黏性記憶」(sticky memories)的概念,將LTM訊號中的較大空間歸結為更頻繁存取的記憶區域,在LTM中創造了一個「永久性」的概念,使模型能夠更好地捕捉長時間的背景而不丟失相關信息,也是從大腦的長期電位和可塑性中得到了啟發。
實驗部分
為了驗證∞-former能否對長脈絡建模,研究者首先對一個合成任務進行實驗,即在一個長序列中按頻率對token進行排序;然後透過微調預訓練語言模型,對語言建模和基於文件的對話生成進行實驗。
排序
#輸入包含一個根據機率分佈(系統未知)取樣的token序列,目標是依照序列中頻率遞減順序產生token
#為了研究長期記憶是否被有效利用,以及Transformer是否只是透過對最近的標記進行建模來排序,研究人員將標記機率分佈設計為隨時間變化。
詞表中有20個token,分別以長度為4,000、8,000和16,000的序列進行實驗,Transformer-XL和compressive transformer作為對比基準模型。
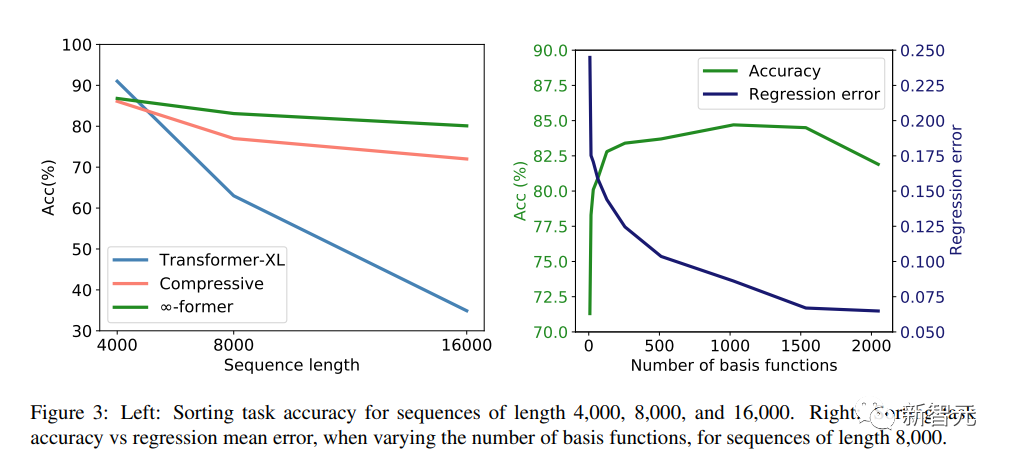
實驗結果可以看出,在短序列長度(4,000)的情況下,Transformer-XL實現了比其他模型略高的精度;但當序列長度增加時,其精度也迅速下降,不過對於∞-former來說,這種下降並不明顯,顯示其在對長序列進行建模時更有優勢。
語言建模
#為了了解長期記憶是否可以用來擴展預訓練的語言模型,研究人員在Wikitext103和PG-19的一個子集上對GPT-2 small進行了微調,包括大約2億個token。
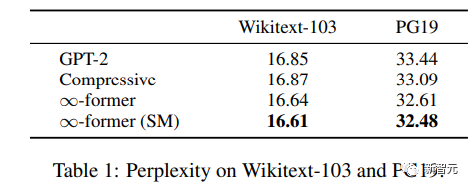
實驗結果可以看到,∞-former可以降低Wikitext-103和PG19的困惑度,並且∞- former在PG19資料集上獲得的改進更大,因為書籍比維基百科文章更依賴長期記憶。
基於文件對話
#在以文件為基礎的對話產生中,除了對話歷史之外,模型還可以獲得對話主題的文檔。
在CMU Document Grounded Conversation dataset(CMU-DoG)中,對話是關於電影的,並給出了電影的摘要作為輔助文件;考慮到對話包含多個不同的連續語篇,輔助文檔被分成多個部分。
為了評估長期記憶的有用性,研究人員只讓模型在對話開始前才能存取文件,使這項任務更具挑戰性。
在對GPT-2 small進行微調後,為了讓模型在記憶中保持整個文檔,使用一個N=512個基函數的連續LTM(∞-former)擴展GPT -2。
為了評估模型效果,使用perplexity、F1 score、Rouge-1和Rouge-L,以及Meteor指標。
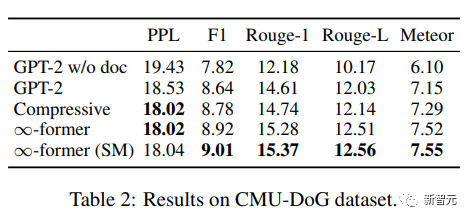
從結果來看,∞-former和compressive Transformer能夠產生更好的語料,雖然二者的困惑度基本上相同,但∞-former在其他指標上取得了更好的分數。
以上是500萬token巨獸,一次唸完全套「哈利波特」!比ChatGPT長1000多倍的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

AI Hentai Generator
免費產生 AI 無盡。

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)
熱門話題



 如何配置Debian Apache日誌格式
Apr 12, 2025 pm 11:30 PM
如何配置Debian Apache日誌格式
Apr 12, 2025 pm 11:30 PM
本文介紹如何在Debian系統上自定義Apache的日誌格式。以下步驟將指導您完成配置過程:第一步:訪問Apache配置文件Debian系統的Apache主配置文件通常位於/etc/apache2/apache2.conf或/etc/apache2/httpd.conf。使用以下命令以root權限打開配置文件:sudonano/etc/apache2/apache2.conf或sudonano/etc/apache2/httpd.conf第二步:定義自定義日誌格式找到或
 Tomcat日誌如何幫助排查內存洩漏
Apr 12, 2025 pm 11:42 PM
Tomcat日誌如何幫助排查內存洩漏
Apr 12, 2025 pm 11:42 PM
Tomcat日誌是診斷內存洩漏問題的關鍵。通過分析Tomcat日誌,您可以深入了解內存使用情況和垃圾回收(GC)行為,從而有效定位和解決內存洩漏。以下是如何利用Tomcat日誌排查內存洩漏:1.GC日誌分析首先,啟用詳細的GC日誌記錄。在Tomcat啟動參數中添加以下JVM選項:-XX: PrintGCDetails-XX: PrintGCDateStamps-Xloggc:gc.log這些參數會生成詳細的GC日誌(gc.log),包含GC類型、回收對像大小和時間等信息。分析gc.log
 debian readdir如何實現文件排序
Apr 13, 2025 am 09:06 AM
debian readdir如何實現文件排序
Apr 13, 2025 am 09:06 AM
在Debian系統中,readdir函數用於讀取目錄內容,但其返回的順序並非預先定義的。要對目錄中的文件進行排序,需要先讀取所有文件,再利用qsort函數進行排序。以下代碼演示瞭如何在Debian系統中使用readdir和qsort對目錄文件進行排序:#include#include#include#include//自定義比較函數,用於qsortintcompare(constvoid*a,constvoid*b){returnstrcmp(*(
 如何優化debian readdir的性能
Apr 13, 2025 am 08:48 AM
如何優化debian readdir的性能
Apr 13, 2025 am 08:48 AM
在Debian系統中,readdir系統調用用於讀取目錄內容。如果其性能表現不佳,可嘗試以下優化策略:精簡目錄文件數量:盡可能將大型目錄拆分成多個小型目錄,降低每次readdir調用處理的項目數量。啟用目錄內容緩存:構建緩存機制,定期或在目錄內容變更時更新緩存,減少對readdir的頻繁調用。內存緩存(如Memcached或Redis)或本地緩存(如文件或數據庫)均可考慮。採用高效數據結構:如果自行實現目錄遍歷,選擇更高效的數據結構(例如哈希表而非線性搜索)存儲和訪問目錄信
 Debian syslog如何配置防火牆規則
Apr 13, 2025 am 06:51 AM
Debian syslog如何配置防火牆規則
Apr 13, 2025 am 06:51 AM
本文介紹如何在Debian系統中使用iptables或ufw配置防火牆規則,並利用Syslog記錄防火牆活動。方法一:使用iptablesiptables是Debian系統中功能強大的命令行防火牆工具。查看現有規則:使用以下命令查看當前的iptables規則:sudoiptables-L-n-v允許特定IP訪問:例如,允許IP地址192.168.1.100訪問80端口:sudoiptables-AINPUT-ptcp--dport80-s192.16
 debian readdir如何與其他工具集成
Apr 13, 2025 am 09:42 AM
debian readdir如何與其他工具集成
Apr 13, 2025 am 09:42 AM
Debian系統中的readdir函數是用於讀取目錄內容的系統調用,常用於C語言編程。本文將介紹如何將readdir與其他工具集成,以增強其功能。方法一:C語言程序與管道結合首先,編寫一個C程序調用readdir函數並輸出結果:#include#include#includeintmain(intargc,char*argv[]){DIR*dir;structdirent*entry;if(argc!=2){
 Debian syslog如何學習
Apr 13, 2025 am 11:51 AM
Debian syslog如何學習
Apr 13, 2025 am 11:51 AM
本指南將指導您學習如何在Debian系統中使用Syslog。 Syslog是Linux系統中用於記錄系統和應用程序日誌消息的關鍵服務,它幫助管理員監控和分析系統活動,從而快速識別並解決問題。一、Syslog基礎知識Syslog的核心功能包括:集中收集和管理日誌消息;支持多種日誌輸出格式和目標位置(例如文件或網絡);提供實時日誌查看和過濾功能。二、安裝和配置Syslog(使用Rsyslog)Debian系統默認使用Rsyslog。您可以通過以下命令安裝:sudoaptupdatesud
 Debian Nginx日誌路徑在哪裡
Apr 12, 2025 pm 11:33 PM
Debian Nginx日誌路徑在哪裡
Apr 12, 2025 pm 11:33 PM
Debian系統中,Nginx的訪問日誌和錯誤日誌默認存儲位置如下:訪問日誌(accesslog):/var/log/nginx/access.log錯誤日誌(errorlog):/var/log/nginx/error.log以上路徑是標準DebianNginx安裝的默認配置。如果您在安裝過程中修改過日誌文件存放位置,請檢查您的Nginx配置文件(通常位於/etc/nginx/nginx.conf或/etc/nginx/sites-available/目錄下)。在配置文件中
