
前段時間,Meta 發布「分割一切(SAM)」AI 模型,可以為任何圖像或影片中的任何物體產生mask,讓電腦視覺(CV)領域研究者驚呼:「CV 不存在了」。之後,CV 領域掀起了一陣「二創」狂潮,一些工作陸續在分割的基礎上結合目標檢測、影像生成等功能,但大部分研究是基於靜態影像的。
現在,一項稱為「追蹤一切」的新研究為動態影片中的運動估計提出了新方法,能夠準確、完整地追蹤物體的運動軌跡。

#該研究由康乃爾大學、Google研究院和UC柏克萊的研究者共同完成。他們共同提出了一種完整且全局一致的運動表徵 OmniMotion,並提出一種新的測試時(test-time)最佳化方法,對影片中每個像素進行準確、完整的運動估計。

有網友在推特上轉發了這項研究,僅一天時間就收穫了3500 的點讚量,研究內容大受好評。

從該研究發布的demo 看,運動追蹤的效果非常好,例如追蹤跳躍袋鼠的運動軌跡:

蕩鞦韆的運動曲線:

還能互動式查看運動追蹤情況:

#即使物件被遮蔽也能追蹤運動軌跡,如狗在跑動的過程中被樹遮擋:

#在電腦視覺領域,常用的運動估計方法有兩種:稀疏特徵追蹤和密集光流。但這兩種方法各有缺點,稀疏特徵追蹤不能建模所有像素的運動;密集光流無法長時間捕捉運動軌跡。
該研究提出的 OmniMotion 使用 quasi-3D 規範體積來表徵視頻,並透過局部空間和規範空間之間的雙射(bijection)對每個像素進行追蹤。這種表徵能夠確保全局一致性,即使在物體被遮蔽的情況下也能進行運動追踪,並對相機和物體運動的任何組合進行建模。該研究透過實驗顯示所提方法大大優於現有 SOTA 方法。
該研究將幀的集合與成對的噪聲運動估計(例如光流場)作為輸入,以形成整個視頻的完整、全局一致的運動表徵。然後,該研究添加了一個優化過程,使其可以用任何幀中的任何像素查詢來表徵,以在整個影片中產生平滑、準確的運動軌跡。值得注意的是,該方法可以識別畫面中的點何時被遮擋,甚至可以穿過遮擋追蹤點。
OmniMotion 表徵
#傳統的運動估計方法(例如成對光流),當物件被遮蔽時會失去對物體的追蹤。為了在遮蔽的情況下也能提供準確、一致的運動軌跡,研究提出全局運動表徵 OmniMotion。
該研究試圖在沒有顯式動態 3D 重建的情況下準確追蹤真實世界的運動。 OmniMotion 表徵將影片中的場景表示為規範的 3D 體積,透過局部規範雙射(local-canonical bijection)映射成每個影格中的局部體積。局部規範雙射被參數化為神經網絡,並在不分離兩者的情況下捕捉相機和場景運動。基於此種方法,影片可以被視為來自固定靜態相機局部體積的渲染結果。
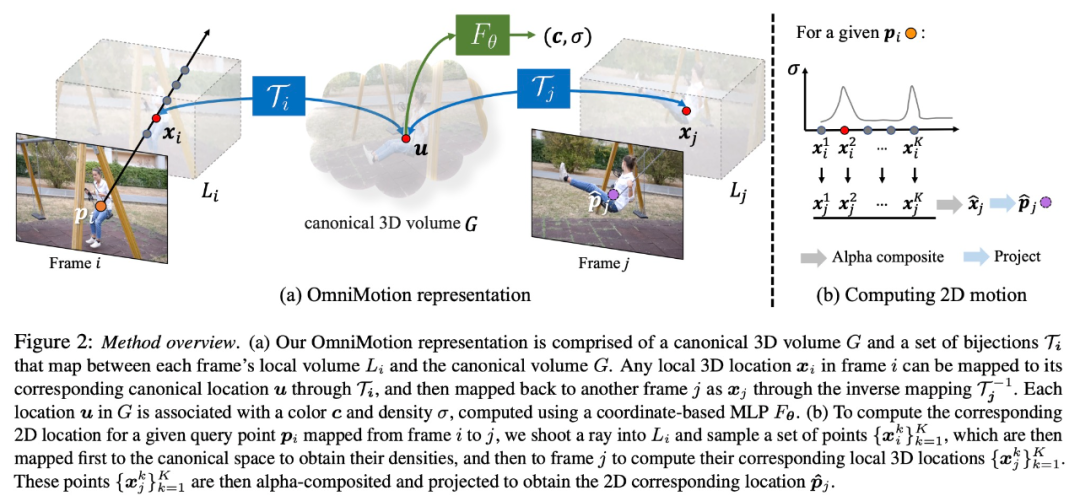
由於 OmniMotion 沒有明確區分相機和場景運動,所以形成的表徵不是物理上準確的 3D 場景重建。因此,該研究稱其為 quasi-3D 表徵。
OmniMotion 保留了投影到每個像素的所有場景點的信息,以及它們的相對深度順序,這讓畫面中的點即使暫時被遮擋,也能對其進行追踪。

量化比較
##量化比較
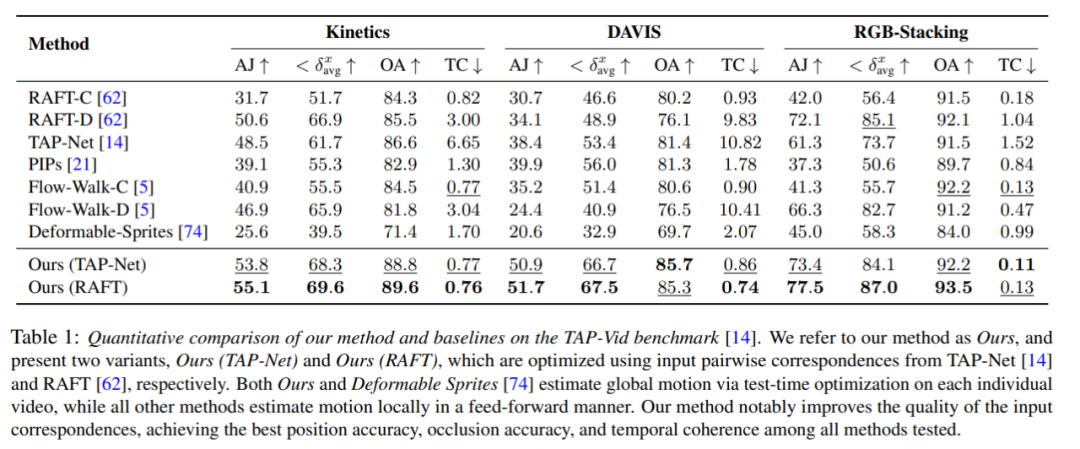
#研究者將提出的方法與TAP-Vid 基準進行比較,結果如表1 所示。可以看出,在不同的資料集上,他們的方法始終能達到最佳的位置準確性、遮蔽準確性和時序一致性。他們的方法可以很好地處理來自 RAFT 和 TAP-Net 的不同的成對對應輸入,並且在這兩種基準方法上提供了一致的改進。
#定性比較

消融實驗與分析
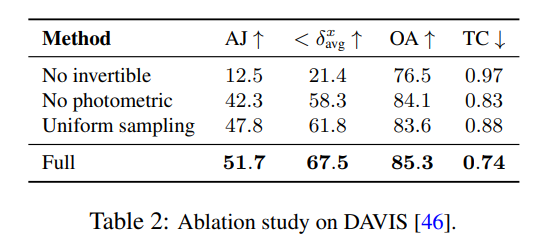

需要注意的是,這些圖並不對應於物理深度,然而,它們展示了僅使用光度和光流訊號時,新方法能夠有效地確定不同表面之間的相對順序,這對於在遮擋中進行追蹤至關重要。更多的消融實驗和分析結果可以在補充資料中找到。
以上是隨時隨地,追蹤每個像素,連遮蔽都不怕的「追蹤一切」視訊演算法來了的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















