
近來,AI安全已成為高度命中的話題。
AI「教父」Geoffrey Hinton和吳恩達就人工智慧和災難性風險進行了一次深度的隔空對話。

吳恩達今日發文分享了他們的共同想法:
-人工智慧科學家對風險達成共識很重要。類似氣候科學家,他們對氣候變遷有大致的共識,所以能製定良好的政策。
- 人工智慧模型是否了解這個世界?我們的答案是肯定的。如果我們列出這些關鍵技術問題,並形成共同觀點,將有助於推動人類在風險方面達成共識。
Hinton表示,
我曾經常與吳恩達交流,很高興再次與他見面並了解他對最近人工智慧發展所帶來各種風險的看法。我們在許多方面取得了共識,特別是,在向政策制定者報告時,研究人員需要就風險形成共識。

在此之前,吳恩達同樣和Yoshua Bengio進行了人工智慧風險的對話。
他們得出的一致意見是,闡明AI可能帶來重大風險的具體場景。

接下來,一起來看看兩位AI大佬都具體討論了什麼。
首先,Hinton提出,最重要的是-共識。
他表示,現在整個AI社群缺乏一種統一的共識。就像氣候科學家達成的共識一樣,AI科學家也同樣需要。
在Hinton看來,之所以我們需要一個共識,是因為如果沒有的話,每個AI科學家各執一詞,那麼政府和政策制定者就可以隨心所欲從其中選擇一個符合自身利益的觀點作為指引。
這顯然會失去公允性。
而從目前的情況來看,AI科學家之間的不同觀點差異化很大。
Hinton認為,如果我們各執一詞的局面能快點過去,大家都能達成一致,共同接受AI可能帶來的某些主要威脅,認識到規範AI發展的緊迫性,就好了。
吳恩達贊成Hinton的觀點。
雖然說他現在還不覺得AI界差異化大到分裂,但好像在慢慢往那個方向演變。
主流AI界的觀點非常兩極化,各陣營之間都在不遺餘力地表達訴求。不過在吳恩達看來,這種表達更像一種爭吵,而不是和諧的對話。
當然,吳恩達對AI社群還是有些信心的,他希望我們能共同找到一些共識,妥善進行對話,這樣才能更好地幫助政策制定者制定相關計劃。
接下來,Hinton聊到了另一個關鍵問題,也是他認為目前AI科學家們難以達成某個共識的原因──像是GPT-4和Bard這種聊天機器人,究竟理不理解他們自己生成的話?
有些人認為AI懂,有些人認為它們不懂,只是隨機鸚鵡罷了。
Hinton認為,只要這種差異還存在,那麼AI界就很難達成一個共識。因此,他認為當務之急就是釐清這個問題。
當然,就他自己來講肯定是認為AI懂的,AI也不只是統計數據。
他也提到了Yan LeCun等知名科學家認為AI並不能理解。
這更凸顯了在這個問題上調和清楚地重要性。
吳恩達表示,判斷AI究竟是否能理解並不簡單,因為好像並不存在一個標準,或某種測試。
他自己的觀點是,他認為無論是LLM也好,其它AI大模型也罷,都是在建構一種世界模型。而AI在這個過程中可能會有些理解。
當然,他說這只是他目前的觀點。
除此之外,他同意Hinton的說法,研究人員必須先就這個問題達成一致,才能繼續聊後面的風險、危機那堆東西。
Hinton接著表示,AI根據資料庫,透過前面的單字判斷、預測下一個單字的生成,這件事在Hinton眼中就是理解的一種。
他認為這和我們人腦思考的機制其實差不了多少。
當然,究竟算不算理解還需要進一步的討論,但最起碼不是隨機鸚鵡那麼簡單。
吳恩達認為,有一些問題會讓不同觀點的人得出不同的結論,甚至推出AI將會滅絕人類。
他表示,想要更好地理解AI,我們需要更多去了解,更多去討論。
這樣才能建立一個包含著廣泛共識的AI社群。
前段時間,在全世界呼籲暫停超強AI研發期間,吳恩達與LeCun開直播就此話題展開了討論。
他們同時反對暫停AI是完全錯誤的,汽車剛發明時沒有安全帶和交通號誌燈,人工智慧與先前的技術進步之間沒有本質上的差異。
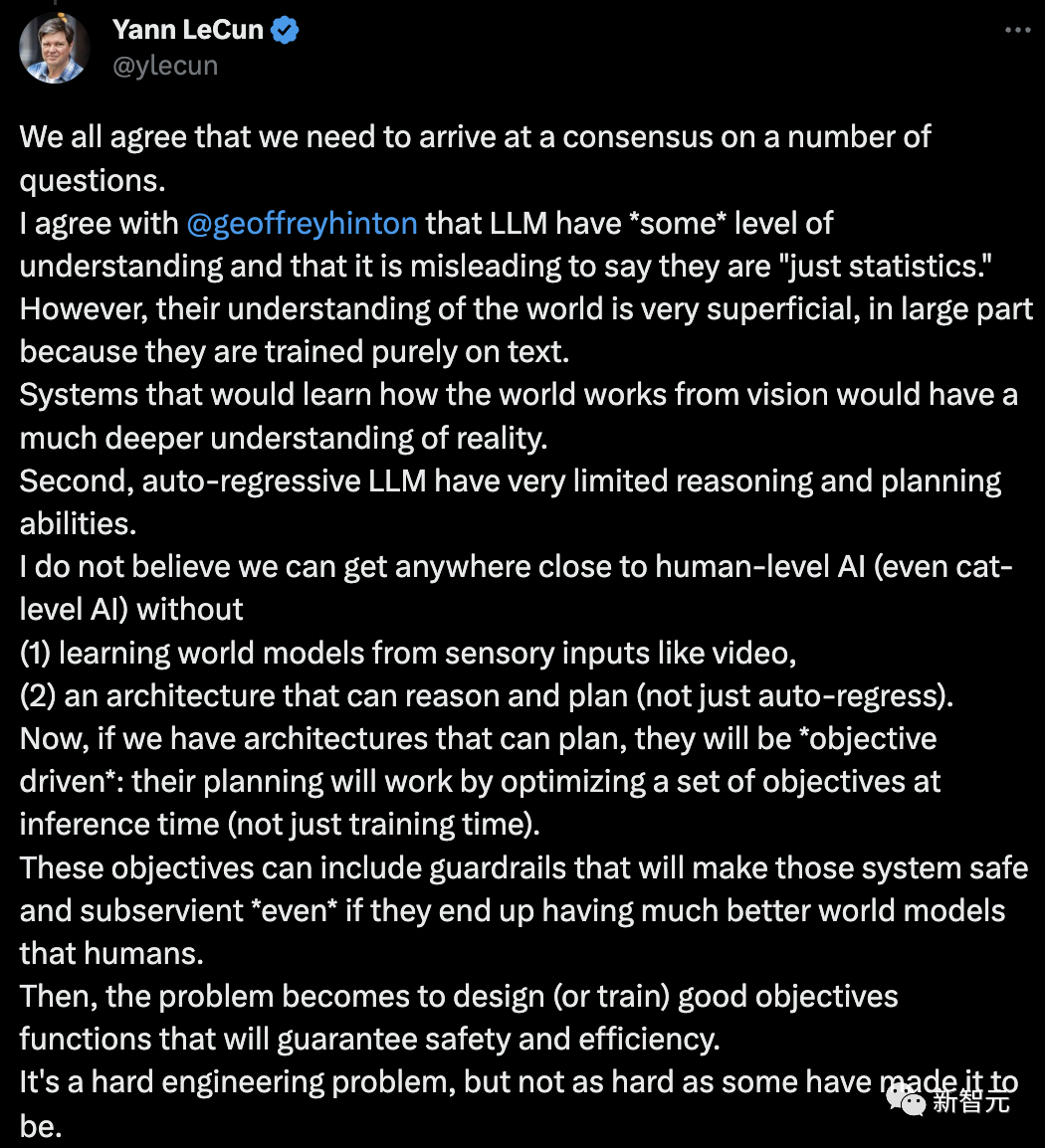
這次,LeCun就吳恩達和Hinton對話,再次提出了自己的「世界模型」,以及當前人工智慧連阿貓阿狗都不如。
我們都同意,我們需要在一些問題上達成共識。
我同意Geoffrey Hinton說的,即LLM有「某種程度」的理解力,還有稱它們「只是統計數據」是一種誤導。
LLM對世界的理解是非常膚淺的,而且很大程度上,因為它們純粹是在文本上訓練的。
從視覺中學習世界如何運作的系統,將對現實有更深刻的理解。其次,自迴歸LLM的推理和規劃能力非常有限。
我認為,如果沒有(1)從視訊等感官輸入中學習「世界模型」,(2)一個能夠推理和規劃的架構(不僅僅是自回歸),我們不可能接近人類等級的人工智慧(甚至是貓級人工智慧)。
現在,如果我們有能夠規劃的架構,它們將是「目標驅動的」:它們的規劃將透過在推理時(而不僅僅是訓練時)優化一組目標來工作。
這些目標可以包括使這些系統安全和順從的「護欄」,即使它們最終擁有比人類更好的世界模型。
然後,問題變成了設計(或訓練)好的目標函數,以確保安全和效率。這是一個困難的工程問題,但並不像有些人說的那麼難。
LeCun的觀點立刻遭到網友的反駁:感官對人工智慧理解的重要性被高估了。
無論如何,我們所有的感官都簡化為電化學訊號,供大腦處理。
文字攝取是一種元感覺,可以描述來自觸覺、視覺、嗅覺的訊息… 攝取大量元感官文本,已經讓像必應(Sydney版)這樣的LLM有能力,以一種優於多數人的方式表達生活和世界。
因此,我認為一種重要的理解能力已經存在,儘管時隱時現。而且更多是由於資源限制,以及處理人員有意設置的沙盒,而不是缺乏感官數據。

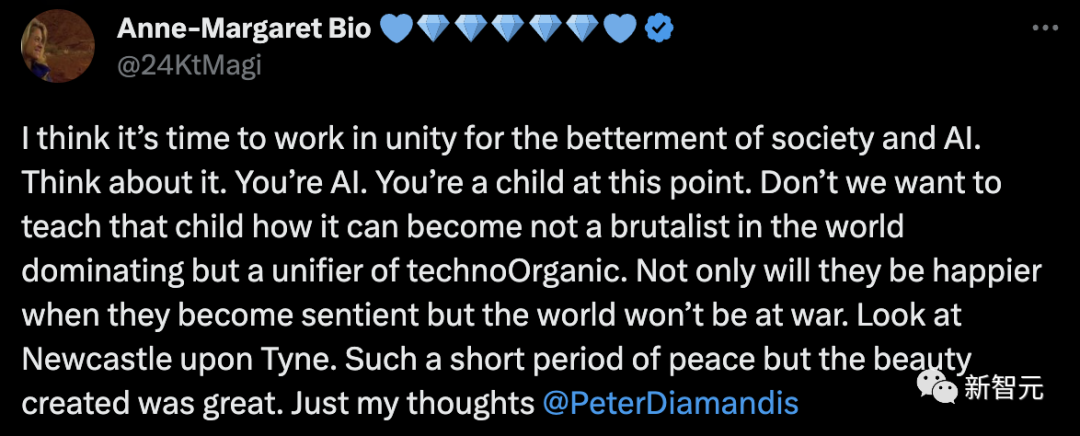
我認為是時候團結起來,為社會和人工智慧的進步而努力了。想想吧,你還是baby人工智慧。我們難道不想教那個孩子如何成為科技有機的統一者,而不是世界上的野獸主義者?
當他變得有知覺時,他們不僅會更快樂,而且世界也不會陷入戰爭。看看泰恩河畔的紐卡斯爾。如此短暫的和平時期,但創造的美麗是偉大的。
而吳恩達和Hinton所說的共識,目前來看似乎不太可能。不是你我個人能力所及,需要所有人有這樣的意願。

還有網友稱,這是相當有爭議的談話。
我確實想知道,當我教2歲的孩子說話時,他的行為更像隨機鸚鵡,還是真的理解上下文?或兩者兼而有之?
因為他的上下文向量比LLM豐富得多(文字、語氣、臉部表情、環境等)。但我確實想知道,如果一個人關閉了另一個人的所有感官,唯一可用的輸入是一些“文本嵌入”(文本輸入->神經刺激),那個人會表現得更像隨機鸚鵡,還是能理解上下文?
離職Google後的Hinton,已經全身心投入AI安全。 6月10日,Hinton在智源大會上再次談及AI風險。
如果一個大型神經網路能夠模仿人類語言來獲取知識,甚至可以自取自用,會發生什麼事?
毋庸置疑,因為能夠獲得更多的數據,這個AI系統肯定要超越人類。
最壞的情況就是,不法份子會利用超級智慧操縱選民,贏得戰爭。
另外,如果允許超級AI自己設定子目標,一個子目標是獲得更多權力,這個超級AI就會為了達成目標,操縱使用它的人類。
值得一提的是,這樣超級AI的實現,便可透過「凡人計算」(mortal computation)。
2022年12月,Hinton曾出版的一篇論文The Forward-Forward Algorithm: Some Preliminary Investigations在最後一節提到了「凡人計算」。

論文網址:https://arxiv.org/pdf/2212.13345.pdf
#如果你希望萬億參數神經網路只消耗幾瓦特的電,「凡人計算」可能是唯一的選擇。
他表示,如果我們真的放棄軟體和硬體的分離,我們就會得到「凡人計算」。由此,我們可以使用非常低功耗的模擬計算,而這正是大腦正在做的事情。

「凡人運算」能夠實現將人工智慧與硬體緊密結合的新型電腦。
這意味著,未來將GPT-3放入烤麵包機中,只需1美元,耗電只需幾瓦。
因此,凡人計算的主要問題是,學習過程必須利用它所運行的硬體的特定模擬屬性,而無需確切知道這些屬性是什麼。
例如,不知道將神經元的輸入與神經元的輸出相關聯的確切函數,並且可能不知道連接性。
這也就是說,我們不能使用反向傳播演算法之類的東西來獲得梯度。

所以問題是,如果我們不能使用反向傳播,我們還能做什麼,因為我們現在都高度依賴反向傳播。
就此,Hinton提出了一個解決方案:前向演算法。
而前向演算法是一種有前途的候選演算法,儘管它在大型神經網路中的擴展能力還有待觀察。
在Hinton看來,人工神經網路很快就會比真實神經網路更智能,而超級智能將會比預期快得多。
由此,現在世界需要達成一個共識,AI未來還應該由人類攜手創造。
以上是吳恩達、Hinton最新對話! AI不是隨機鸚鵡,共識勝過一切,LeCun雙手贊成的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















